
基于迁移CNN的江淮持续性强降水环流分型
2021-03-11 03:30蔡金圻谭桂容牛若芸
应用气象学报 2021年2期
蔡金圻 谭桂容* 牛若芸
1)(南京信息工程大学气象灾害教育部重点实验室/气候与环境变化国际合作联合实验室/气象灾害预报预警与评估协同创新中心, 南京 210044)2)(国家气象中心, 北京 100081)
引 言
我国地理位置特殊,受青藏高原热力与动力作用影响显著,是复杂的季风气候区域[1-2]。江淮地处雨量丰沛的南方和干旱少雨的北方过渡地带,降水的年际和季节变率大,影响因素复杂。在全球气候变暖背景下,近50年我国降水强度普遍趋于增加,而降水日数除西北地区外其他大部分地区显著减少[3],局地持续性暴雨事件主要发生在江南和华南地区,以6月为最多[4]。20世纪80年代后全国暴雨极端事件除华北外其他地区均呈频数增加、强度增大的特点[5],给国民经济、社会发展以及人民生活带来巨大损失及影响。
受夏季风影响,我国旱涝降水与雨带位置密切相关,而雨带位置又与背景环流场密不可分[6-7]。大尺度环流异常、阻塞高压等系统的作用引起干冷、暖湿空气交汇是发生极端强降水的重要原因[8-12]。马岚等[13]利用卫星资料进行辐射亮度温度(TBB)反演计算,分析得出季风爆发并与北方南下冷空气的结合是造成我国东南部地区出现大范围长时间强降水的必要条件。Chen等[14]研究发现,中高纬地区主要存在两种影响中国极端降水的环流型,即两脊一槽型和一槽一脊型;低纬度地区有3条低层季风环流将水汽输送至中国。暴雨区主要位于200 hPa高空急流入口区右侧,南亚高压北缘和中纬度脊前辐散气流中[15]。江淮地区强降水发生次数多,持续时间长,与西太平洋副热带高压的稳定控制有密切关系[4]。极端强降水不是单一环流发生发展的结果,而是对流层高、中、低不同层次多个关键系统相互配置、共同影响形成的[14,16]。许多学者通过讨论环流与降水的关系,将关键区环流相似方法运用到降水预报中[17-21]。谭桂容等[22]将场相似方法运用到江淮地区强降水环流场分型及期降水预报中,结果表明:不同时效得到的强降水发生日环流与实测环流相关显著,且在独立预报试验中,该方法在3 d 以上大到暴雨的预报效果优于模式。Zhou等[23]利用带有权重的余弦相似方法建立基于关键影响系统的模拟模型(key influential systems based analog model,KISAM)并对持续性强降水进行预测,结果表明:KISAM较模式直接预报(direct model output,DMO)能够更早识别持续性极端降水且预测位置和强度更准确,尤其是3 d以上的预报。
人工神经网络很早就被应用到气象领域[24-25],如降水分类预报,孙照渤等[26]根据雨型与前期(冬季)环流和海温关系,利用人工神经网络方法对我国夏季的雨型进行模拟预报,建立分类预报模型。随着深度学习的发展,卷积神经网络(convolutional neural networks,CNN)具有适用性强、泛化能力强、全局优化训练参数少等优点[27],相较于传统的图像分类方法,不再需要人工对目标图像进行特征描述和提取,而是通过网络自主地从训练样本中学习特征,近年也被逐渐应用到天气预报及气候预测上。陈程[28]参考ConvLSTM(convolutional long short-term memory)结构提出一种结合卷积神经网络和GRU(gated recurrent unit)的ConvGRU(convolutional gated recurrent unit)模型,将雷达回波数据作为输入应用于降水短时临近预报。Ham等[29]采用深度学习方法的统计预测模型可以得出有效期长达1年半的ENSO预测,还可以更好地预测海面温度的精细空间分布。Liu等[30]将深度学习应用于气候极端事件检测,开发了深度卷积神经网络分类系统,在检测极端事件(热带气旋、大气河流和天气锋)方面准确率达到89%~99%。He等[31]提出残差神经网络(residual networks,ResNet),通过在卷积网络中引入残差单元,解决加深网络深度的过程中出现的退化问题。残差网络相比于传统卷积网络,具有更易优化、参数更少的优点。残差网络在图像分类上效果好,而在此之前的关键区环流相似方法主要通过相似系数实现。因此,本文选取江淮(26°~36°N,110°~123°E)作为研究区域,利用余弦相似系数(COS)、相似量(R)以及网络深度为18层的残差神经网络(ResNet18)3种方法对全国持续性强降水个例日进行客观分型,比较各方法的分型效果,并建立强降水分型模型库,为进一步的强降水预报提供参考。
1 资料和方法
1.1 资 料
本文所用资料包括:1981—2018年NCEP/NCAR全球再分析逐日位势高度场(水平分辨率为2.5°×2.5°),1981—2018年全国区域持续性强降水过程历史个例数据集,国家气象中心提供的1981—2018年我国2474个国家级地面气象站逐日降水量。
1981—2018年全国区域持续性强降水历史个例数据集是牛若芸等[32]以天气过程为单元,采用长序列加密观测的降水量资料和客观识别与主观分析相结合,建立的中国95°E以东地区及各子区内的区域性暴雨过程个例谱,该数据集具有时间序列长、主客观相结合、充分考虑气象资料统计日界等优点。具体判识方法:①基于逐日累计降水量格点资料,逐时次客观识别出成片暴雨(大雨)区(日累积降水量达到暴雨(大雨)以上量级(大于50 mm(25 mm))的格点数不低于15个且相连成片)。相连成片指该区域内的每个格点都至少有另一个格点与之相连(含对角相连)。②以成片暴雨区出现时间为基点,绘制其前后邻近时段(各3~7 d)不同层次天气分析图并叠加对应时刻日累积降水量和成片暴雨(大雨)区;依据天气学原理,主观考察、分析暴雨过程及其影响系统的演变历程,“同一次天气过程中,任一时次出现成片暴雨区即可记为一次区域性暴雨过程”。以“首次(末次)出现成片大雨区的日累积降水量起始时刻(终止时刻)”为该次区域性暴雨过程起始时刻(终止时刻)。
基于各地行政区划和天气气候特征,将中国95°E以东地区分为6个子区,建立各子区区域性暴雨过程个例谱。
1.2 方 法
本文采用经验正交分解(EOF)对持续性强降水历史个例集中6个子区之一的江淮地区极端持续性强降水个例进行分析,提取江淮地区强降水典型模态,以500 hPa典型模态环流场作为建立分型模型和环流客观分型的基础。
基于典型模态环流场,对所有持续性强降水个例进行环流客观分型。用于比较的分型方法有3种:
①采用余弦相似系数(COS)进行计算,任意两个样本xj和xk看作m维空间的两个向量,则余弦相似系数就是这两个向量夹角的余弦,用cosθjk表示为
(1)
式(1)中,j,k=1,2,…,n。cosθjk=1,表示xj和xk互相平行,方向相同,完全相似。cosθjk=-1,表示xj和xk互相平行但方向相反,完全不相似。
②采用相似量(R)[33-34]进行计算,表达式为
(2)
式(2)中,0≤Rij≤1。当Rij=1时,表示两个样本最为相似;当Rij=0时,表示不相似。
③采用经过迁移学习的残差神经网络模型(下文简称迁移CNN)[31]进行计算。残差网络通过拟合残差映射达到网络训练的目的。本文采用的是深度为18层的残差网络,即卷积层和全连接层,不包括池化层和BN(batch normalization)层。网络中的卷积层均由残差学习单元堆叠而成,在一个单元中,假设原始映射为H(x),残差网络拟合的映射为F(x)=H(x)-x。残差单元的输出H(x)=F(x)+x分为两部分,一部分由网络的输入x经过直连路径恒等映射得到,另一部分由残差F(x)经过网络训练得到。
由于样本量较少,为了尽量避免训练过程中发生过拟合,使网络更快收敛,采用迁移学习的方法进行训练。所谓迁移学习就是将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中,可有效解决目标领域或问题中仅有少量样本的学习问题。相关研究表明:在小规模图像数据集上,运用迁移学习方法与直接在目标数据集上训练模型相比,图像识别准确率提高,模型鲁棒性增强[35]。
采用合成分析、相关分析等方法比较以上3种分型方法在客观分型以及独立样本分型上的优劣。
本文客观分型采用1981—2015年资料,独立样本检验采用2016—2018年资料。
2 江淮地区持续性强降水的典型模态
为了提取强降水典型模态,得到用于迁移CNN训练及测试样本库资料,这里选择1981—2015年夏季发生在江淮地区的72个极端持续性强降水个例(共296 d,去掉重复日期) 进行EOF分解,极端持续性强降水过程能够更好地体现江淮强降水特征,在一定程度上确保各降水类型的典型性和准确性。根据方差贡献率得到EOF分解的主要模态(图1)。由图1可见,第1模态呈江淮降水全区一致的变化趋势,降水大值中心位于江淮中部略偏南;第2模态呈南北反向的空间分布;第3模态呈中部与南北反向变化的趋势。这3个模态分别约解释总方差的25.8%,10.9%和7.1%。取标准化时间系数大于1的个例日作为该模态对应的基本降水类型(每个个例日只属于一种类型),并按照3个模态时间系数分别选出83 d,79 d 和53 d个例日(共215 d)并对其降水和环流场进行合成,得到江淮强降水的典型模态降水分布(图2)及环流场,作为进一步客观分型的基础。
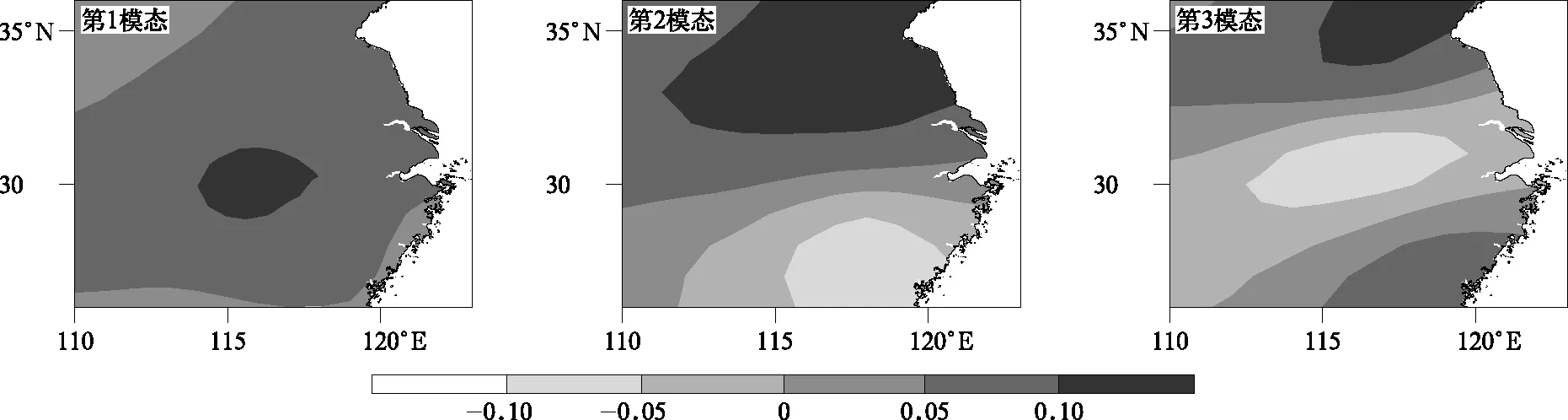
图1 江淮地区持续性强降水个例EOF分解的前3个模态Fig.1 Three leading EOF models of persistent heavy rain in Jianghuai Region

图2 根据时间系数合成的江淮地区典型模态降水分布Fig.2 Composite rainfall of typical mode patterns from EOF time coefficient in Jianghuai Region
3 江淮地区强降水客观分型
3.1 迁移CNN
应用第2章分析得到的3种模态个例日83 d,79 d和53 d共215 d进行训练,训练集的损失函数和准确率在训练开始后很快收敛,但从测试集结果看,损失函数基本保持不变,无下降趋势,准确率同样在57%左右振荡,无升高趋势,说明模型在训练过程中很可能发生过拟合,从而导致在测试集效果不理想(图3a和图3b)。为了避免过拟合发生,在模型训练过程中加入迁移学习的方法,并通过增加样本进一步提高模型泛化能力,将1981—2015年全国1009个持续性强降水个例共3179 d(去掉重复日期)投影到典型模态[36],并按照第2章时间系数的标准又选取169 d,共384个样本。

图3 迁移CNN训练集与测试集的损失函数和准确率(a)增加训练样本前损失函数,(b)增加训练样本前准确率,(c)增加训练样本后损失函数,(d)增加训练样本后准确率Fig.3 The loss and accuracy of training dataset and test dataset of the transfer learning CNN model(a)the loss before adding training samples,(b)the accuracy before adding training samples,(c)the loss after adding training samples,(d)the accuracy after adding training samples
本文在对迁移CNN进行训练时,迁移学习应用包含两个部分(图4) :第1部分是通过在正式训练前加入预训练模型实现参数的迁移,预训练模型的训练样本即为下文3次迁移训练中第1次所用的284 d,加载基于ImageNet数据集训练的ResNet18模型,冻结卷积层参数,只更新全连接层的参数,这样预训练模型既保留了良好的图像特征提取及特征学习的能力,又能够适用于特定的任务或问题。在正式训练时直接加载预训练模型的参数,而不使用随机初始化的参数,使网络能够更快地收敛。第2部分主要在于3次训练过程,即将训练样本中随机挑选的90 d分为3部分,分次投入模型进行训练,第1次训练投入的样本量为284 d,结束后保留模型训练得到的相应参数值,带入到下一次训练,作为模型训练时的初值;第2次训练增加30 d,即训练样本量达314 d,同理,将第2次训练之后的结果又带入第3次训练中;第3次训练再增加30 d使训练样本量达到344 d,模型训练结束保留相应参数,并统计各型输出最小值(阈值),测试集样本量均为40 d。从增加样本后的训练结果(图3c和图3d)看,测试集损失函数逐渐下降,准确率逐渐上升,与之前相比有较大提高,迁移CNN和R分型、COS分型在测试集上的准确率分别为85%和70%,77.5%。

图4 迁移CNN的训练流程Fig.4 Frame of training of transfer learning CNN model
3.2 持续性强降水环流客观分型
迁移CNN模型建好后,将分型日相应环流场资料输入模型,得到相应的输出,当输出最大值不小于阈值则得到相应的降水类型,否则为3种降水之外的类型(图5)。迁移CNN和R分型、COS分型3种方法入选各型的阈值分别为0.995,0.777和0.871。对1981—2015年全国持续性强降水个例共3179 d进行客观分型,得到Ⅰ型、Ⅱ型、Ⅲ型分别为724 d,364 d和297 d共1385 d。需要说明的是,这里3179 d是全国区域的持续性强降水个例,并非江淮地区持续性强降水个例,所以其中有很多不属于本文所列3种降水类型。为了比较迁移CNN的分型效果,分别应用R分型、COS分型方法对样本进行分型,分别得到3种降水类型个例日为595 d,301 d,489 d和602 d,337 d,446 d。

图5 迁移CNN分型Fig.5 Frame of pattern classification of the transfer learning CNN model
图6为1981—2015年3种方法客观分型后得到的3类强降水的合成分布。由图6可见,3种方法得到各型强降水的空间分布与EOF典型模态(图2)类似,只是强度稍弱。从降水分布看,3种方法Ⅰ型强降水的中心位置较典型模态均略向南偏移;迁移CNN分型得到的Ⅱ型强降水中心与典型模态对应更好,而COS分型得到的强降水中心位置向南偏移;由迁移CNN分型得到的Ⅲ型强降水的空间分布明显表现出南北多、中间少的降水空间分布特征,而R分型和COS分型得到的降水在江淮北部的中心不明显。总体而言,迁移CNN分型得出的强降水空间分布与典型模态更为接近。表1为3种方法与典型模态之间各型强降水的相关系数,3种方法各型降水合成场平均与图2典型模态降水的相关系数(平均场相关)均达到0.05显著性水平,在各型所有个例日与图2中相应典型模态降水模态相关系数的显著性检验中,迁移CNN和R分型、COS分型达到0.05显著性水平的个例日分别为1082 d,1018 d,1022 d,这些个例日相关系数的平均即为个例日相关,可以发现迁移CNN得到的各型强降水平均场和个例日的相关系数均高于R分型和COS分型的结果,说明由迁移CNN分型得到的各型个例日的降水分布更符合典型模态的特征,迁移CNN分型效果更好。

图6 迁移CNN,R分型和COS分型得到的江淮地区强降水分布Fig.6 Composite heavy rain patterns in Jianghuai Region by the transfer learning CNN model,R typing and COS typing

表1 迁移CNN,R分型和COS分型得到的各型与典型模态强降水之间的相关系数Table 1 The correlation coefficients between the transfer learning CNN model,R typing,COS typing and heavy rainfall of typical mode patterns
从500 hPa环流场的演变特征看,3种方法的分型结果类似(图略)。图7为3种方法各型高度场之间的方差,可以看到各时效迁移CNN分型的方差均高于R分型和COS分型,而R分型和COS分型的方差基本相同,说明由迁移CNN得到的各型高度场之间差异更加明显,迁移CNN能更好地区分不同强降水类型的环流场。
3.3 不一致型个例
为了进一步比较迁移CNN和R分型、COS分型的效果,根据1981-2015年3种方法客观分型结果,选取至少两种方法分型结果不一致的个例日共240 d进行比较。分别对不同方法各型降水及环流进行合成,并计算降水相关系数及各型与降水典型模态500 hPa高度场的方差进行比较。图8给出3种方法各型与典型模态环流场的方差,发现迁移CNN的方差在Ⅰ型超前4~10 d,Ⅱ型超前0~3 d,Ⅲ型超前0~4 d,略大于R分型和COS分型,总体而言3种方法的方差差别不大,数值接近。但从降水相关系数(表2)看,不论平均场相关,还是个例日相关,迁移CNN的结果均明显高于R分型和COS分型,3种方法分别有204 d,174 d,178 d个例日与典型模态的相关系数达到0.05显著性水平。迁移CNN分型得到的各型的降水平均场相关系数分别为0.88,0.98和0.98,均达到0.05显著性水平,个例日相关系数分别为0.35,0.24和0.47。在R分型和COS分型的结果中,除Ⅱ型强降水的平均场相关系数相对较高外,其余数值均小于0.1,COS分型的Ⅰ型降水合成场甚至为小于-0.5的负相关,R分型的Ⅰ型和Ⅲ型、COS分型的Ⅲ型均未达到0.05显著性水平。从降水的空间分布(图9)也可以发现,只有迁移CNN能非常显著地表现出江淮地区3种强降水类型的分布特征;而R分型、COS分型的结果只有Ⅱ型的特征相对符合,Ⅰ型的形态分布与典型模态中的Ⅲ型相近,但北方的降水中心位置又与典型模态相差较大,R分型、COS分型得到的Ⅲ型仅1个中心,不似典型模态的双中心形态分布。结合对环流以及降水的分析可见,迁移CNN分型效果明显优于R分型和COS分型。
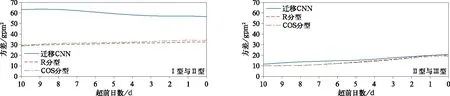
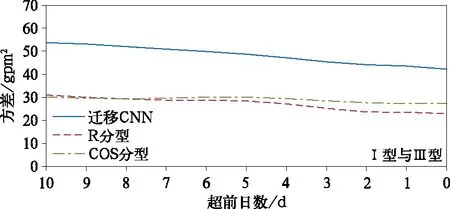
图7 迁移CNN,R分型和COS分型得到的各型500 hPa高度场的方差Fig.7 The variance between 500 hPa geopotential height fields of different rainfall types of transfer learning CNN model,R typing and COS typing
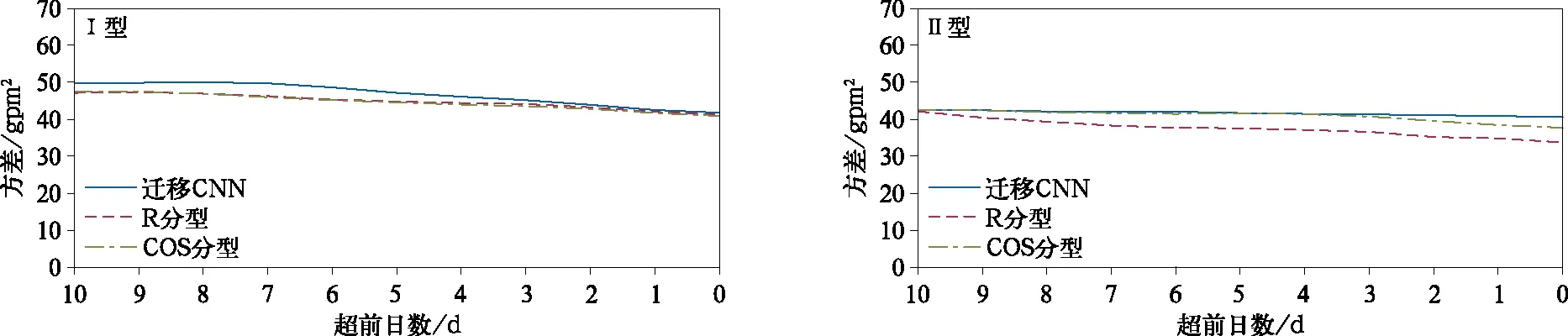
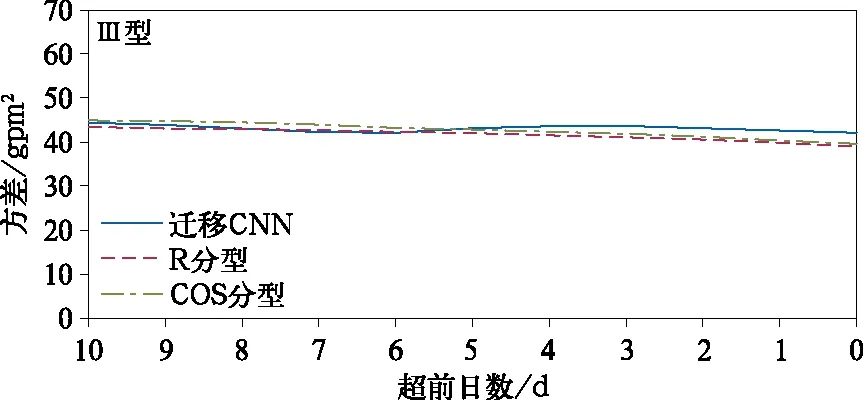
图8 个例日样本中迁移CNN,R分型和COS分型得到的各型与典型模态500 hPa高度场的方差Fig.8 The variance of geopotential height field at 500 hPa between transfer learning CNN model,R typing,COS typing and typical mode patterns in samples
3.4 独立样本分型
为了进一步验证迁移CNN在客观分型上的优势,运用3种方法对2016—2018年共1096 d进行客观分型。这里是针对2016—2018年所有日进行分型,而非针对持续性强降水个例集的日数进行分型。首先根据当日环流及阈值判断该日是否属于区域强降水相关的3种类型环流。当方法输出小于阈值,表明为非3种类型的强降水环流,否则根据输出判定当日环流类型。将1096 d个例日的500 hPa环流场输入迁移CNN模型,得到相应的输出结果,并依据阈值得到Ⅰ型、Ⅱ型、Ⅲ型降水个例日分别为117 d,63 d,55 d共235 d。同样,应用R分型和COS分型得到各型分别为68 d,56 d,59 d共183 d和92 d,66 d,57 d共215 d。在试验中,随机选取130 d无降水的500 hPa环流场输入迁移CNN模型,发现其输出结果均小于阈值0.995,即不属于3种降水类型中的任何一种,符合实际情况。对3种方法各型个例日进行比较,得到各型迁移CNN和R分型、COS分型方法结果均相同的个例日分别为27 d,13 d,8 d共48 d,将相同部分的个例日剔除,计算剩余个例日的各型与典型模态降水相关系数(表3),可以发现迁移CNN各型的平均场相关及个例日相关均高于R分型、COS分型(3种方法平均场相关均达到0.05显著性水平,通过检验的个例日分别为140 d,85 d,108 d),迁移CNN和COS分型的Ⅲ型平均场相关相对Ⅰ型、Ⅱ型较小,且COS分型出现负值,而R分型的Ⅱ型平均场相关明显小于迁移CNN和COS分型。在3种方法的分型结果中,分别有115 d,90 d,96 d包含在2016—2018年的77个持续性强降水个例中。由于历史个例集为区域持续性强降水个例,对持续日数有要求,所以用于各方法分型的个例日存在不属于持续性强降水的个例日。通过对历史强降水个例集外迁移CNN分型得到的各型降水合成可见,江淮区域内存在较大的降水,且其分布型跟图1和图2中的降水分布相似,由此可见迁移CNN对于非持续性的强降水环流型也存在一定的分辨能力。
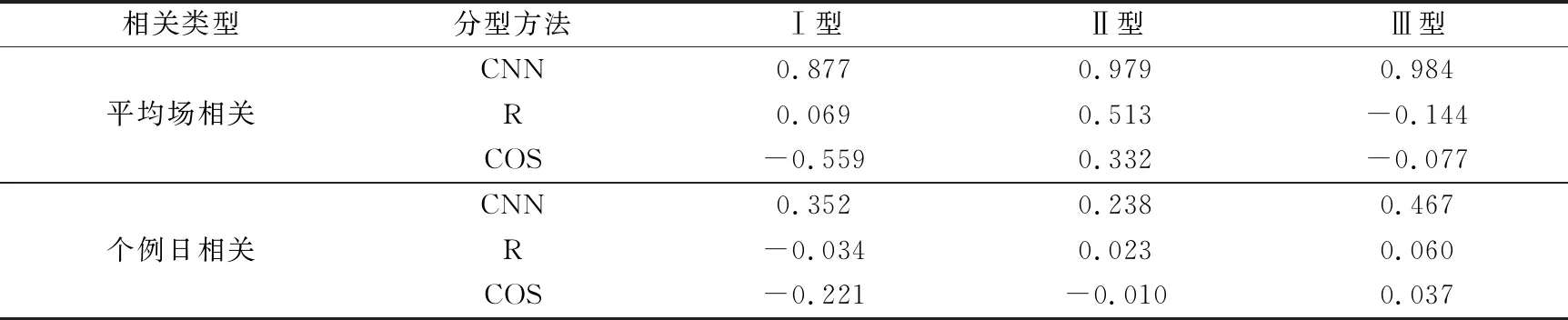
表2 个例日样本中迁移CNN,R分型和COS分型得到的各型与典型模态强降水之间的相关系数Table 2 The correlation coefficients between the transfer learning CNN model,R typing,COS typing and heavy rainfall of typical mode patterns in samples

图9 个例日样本中迁移CNN,R分型和COS分型3种方法得到的江淮地区强降水分布Fig.9 Composite heavy rain patterns in Jianghuai Region by the transfer learning CNN model,R typing and COS typing in samples
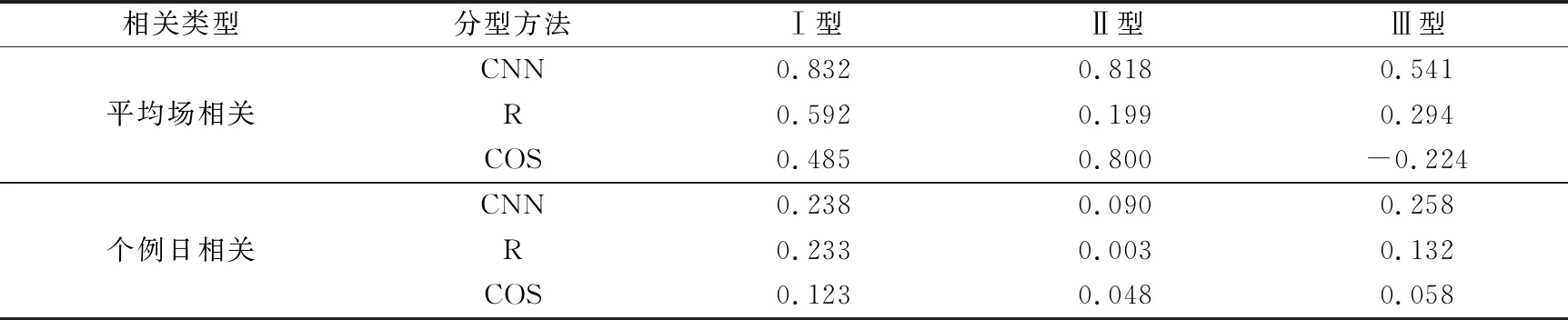
表3 不同部分样本中迁移CNN,R分型和COS分型得到的各型与典型模态强降水之间的相关系数Table 3 The correlation coefficients between transfer learning CNN model,R typing,COS typing and heavy rainfall of typical mode patterns in samples of different part
4 结论与讨论
本文运用EOF分解方法对1981—2015年夏季江淮地区72个极端持续性强降水个例进行分析并提取江淮强降水及环流场典型模态,然后运用迁移CNN和R分型、COS分型3种方法对1981—2015年所有个例进行客观分型,通过合成分析、个例分析比较不同方法在客观分型上的优劣,并对2016—2018年个例进行独立检验。主要结论如下:
1) 提取典型模态环流及降水分布。从江淮持续性强降水模型库中选取72个典型个例进行EOF分解,提炼出江淮强降水典型模态环流场和降水分布。将个例日降水投影到降水典型模态得到相应的时间系数,由时间系数确定训练和测试集样本。
2) 建立江淮持续性强降水迁移CNN分型模型。运用3次迁移学习训练建立迁移CNN分型模型,在模型测试集分型中,迁移CNN和R分型,COS分型的准确率分别为85%,70%,77.5%,以迁移CNN分型准确率最高。
3) 利用3种方法对1981—2015年所有持续性强降水个例客观分型结果的统计分析表明:迁移CNN分型效果较好。迁移CNN得到的各型高度场间方差最大,对各型所有样本以及不一致样本的分析表明:各型与典型模态降水间的相关系数远高于R分型、COS分型方法,且不一致型样本中,迁移CNN分型得到的各型降水分布具有明显典型模态强降水的特征,但R分型、COS分型的型降水除Ⅱ型外几乎与典型模态相反。在2016—2018年独立样本客观分型中,迁移CNN方法得到各型与典型模态降水的相关系数高于R分型、COS分型,迁移CNN具有一定分型优势,且对于非持续性强降水环流型也存在一定的分辨能力。
本文运用迁移CNN,根据关键区域500 hPa 高度场特征,对1981—2015年所有持续性强降水个例进行客观分型,并对2016—2018年逐日环流样本进行独立检验,结果表明该方法相较于传统相似系数存在一定的优越性。在此分型基础上可得到江淮持续性强降水对应的前期到同期不同层次环流演变,建立天气学概念模型;同时,可进一步结合模式产品,实现模式对江淮持续性强降水预报的订正等[37]。但以往的研究表明:江淮地区持续性强降水在发生发展过程中同时受到多层次不同关键系统的影响,除500 hPa中高纬度阻塞高压、西风槽、低纬度西太平洋副热带高压等之外,还有如高空西风急流、南亚高压、低空急流等高低空不同系统的影响,若是将不同层次关键影响因子加入到迁移CNN中,有望进一步提高分型效果,完善区域历史强降水模型库。本文以江淮持续性强降水事件为例实施迁移CNN分型,该方法也可应用到其他天气事件的分类诊断与预报中。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
经济与管理(2020年4期)2020-12-28
中华养生保健(2020年7期)2020-11-16
成都信息工程大学学报(2019年4期)2019-11-04
新闻传播(2018年13期)2018-08-29
成都信息工程大学学报(2017年2期)2017-11-09
高原山地气象研究(2016年2期)2016-11-10
西藏科技(2016年8期)2016-09-26
高原山地气象研究(2016年3期)2016-02-28
西藏科技(2015年3期)2015-09-26
