
基于数据挖掘的耙吸式挖泥船行为辨识方法
2021-03-11 02:01庄素婕刘克中马天明戴文伯陈新华
中国航海 2021年4期
庄素婕, 杨 星,3, 刘克中,3, 马天明, 戴文伯, 陈新华
(1.武汉理工大学 航运学院, 湖北 武汉 430063; 2.武汉理工大学 安全科学与应急管理学院, 湖北 武汉 430063; 3.湖北省内河航运技术重点实验室, 湖北 武汉 430063;4.中交疏浚技术装备国家工程研究中心有限公司,上海 201306)
耙吸式挖泥船是中大型自航、自载式挖泥船,因其广泛的适应性和经济性成为当今疏浚界的主力施工船舶[1]。在工程中,岸上监管人员通过工作日志了解挖泥船实际施工效果,由于人工填报存在较大误差且具有滞后性,日志数据无法满足岸上监管的需求[2-3],因而从船舶轨迹数据中挖掘船舶行为规律对于耙吸式挖泥船施工效率优化具有重要意义。
耙吸式挖泥船的行为辨识存在较大困难。首先,船舶的行为模式转换过于频繁,耙吸式挖泥船通常会在一个指定的施工区域内重复多个工作周期完成疏浚任务,一个完整工作周期需在空载航行、挖泥作业、满载航行以及抛泥作业中转换4次行为模式。其次,AIS航行状态数据的缺失加大了行为辨识的难度。船舶自动识别系统的强制安装要求使海量轨迹数据的获取成为可能,然而绝大多数挖泥船在AIS使用中存在问题[4]。AIS规范操作要求挖泥船正常航行时的航行状态为“机动船在航”,在挖泥、抛泥作业时,航行状态需更改为“操纵能力受限制”,意味着挖泥作业时船舶状态需要在“机动船在航—操纵能力受限制—机动船在航”之间来回切换。实际操作中,操作人员一般将进入挖泥区域到所有挖泥作业结束的整个流程设定为“操纵能力受限制”,人为疏忽导致输入AIS的航行状态信息与实际情况不匹配。
随着数据挖掘技术的不断发展,国内外学者对船舶行为的研究逐渐从模型驱动转变为数据驱动[5]。朱飞祥等[6]通过关联规则算法挖掘整个海域船舶行为模式,为降低轨迹数据复杂度,采用地理网格技术划分水域。Kraus等[7]针对AIS数据的位置特征和行为特征,使用随机森林算法实现船舶类型的有效识别。王立林等[8]根据轨迹数据特性,设计了基于多尺度卷积的行为识别网络。Vespe等人[9]对渔船速度建立高斯混合模型达到捕鱼行为辨识的效果。以上方法在快速、高效地挖掘船舶行为方面取得了一定成果,但是对数据集的要求较高,需要有大量的先验数据进行模型训练,而且随着移动对象数据量的增长,这些方法的计算量将大幅提升[10]。
综上所述,以上方法对先验数据要求较高,并不适用于航行状态数据缺失的耙吸式挖泥船行为辨识。针对行为模式转换频繁,以及AIS先验数据缺失问题,结合耙吸式挖泥船作业特征,提出一种无监督船舶行为辨识方法。
1 耙吸式挖泥船工作状态分析
耙吸式挖泥船是一种装备有耙头挖掘机具和水力吸泥装置的大型自航、装仓式挖泥船[11],其一个完整工作周期由四个过程组成,如图1所示。首先船舶空载航行至指定挖泥区域,然后在该航段来回挖泥。挖泥作业时其对地航速的选择与土质有关,淤泥或软土容易被耙吸,对地航速一般在2 kn左右,土质为较高塑性粘土、亚粘土、密实细沙时,一般为3~4 kn[12];在维持30~60 min挖泥作业后泥舱装满,船舶满载航行至抛泥区卸泥,然后空载返回至挖泥区域开始新一轮的工作。

图1 工作过程示意图
耙吸式挖泥船施工作业时其航速遵循周期性变化规律,如图2所示,每个周期由abcd四个部分组成。a、c片段分别为空载和满载航行状态,此时船舶航速维持在10 kn以上;b片段反映了船舶挖泥作业时的速度特点,船舶航速在较长一段时间内保持在2~5 kn,与抛泥作业(d片段)相比,挖泥行为的平均航速更高,持续时间更长。耙吸式挖泥船的速度特征表明:① 耙吸式挖泥船工作时的行为模式是频繁转换的,每个工作周期转换4次;② 平均航速可用于区分航行行为与作业行为,空载航行与满载航行的平均航速明显高于挖泥和抛泥作业;③ 作业持续时长可用于区分挖泥行为与抛泥行为,每一次挖泥作业的持续时间都显著大于抛泥作业。

图2 耙吸式挖泥船航速变化图
耙吸式挖泥船在指定区域内往返施工作业使其挖泥区域轨迹明显较其他区域密集,然而在实际轨迹路线中,几乎所有区域的轨迹都呈现出重叠往复的特征,如图3所示。虽然c中的轨迹密度明显高于a、b两处,但只能粗略判断船舶在该处进行了挖泥作业,因为c处的轨迹都是由正常航行与挖泥作业共同造成的,因而传统的基于密度的DBSCAN聚类方法无法应用于耙吸式挖泥船的行为辨识。

图3 耙吸式挖泥船轨迹图
结合以上特征,将耙吸式挖泥船整个作业过程中的行为划分为三类:正常航行行为、挖泥行为、抛泥行为。不同行为特点如图4所示。
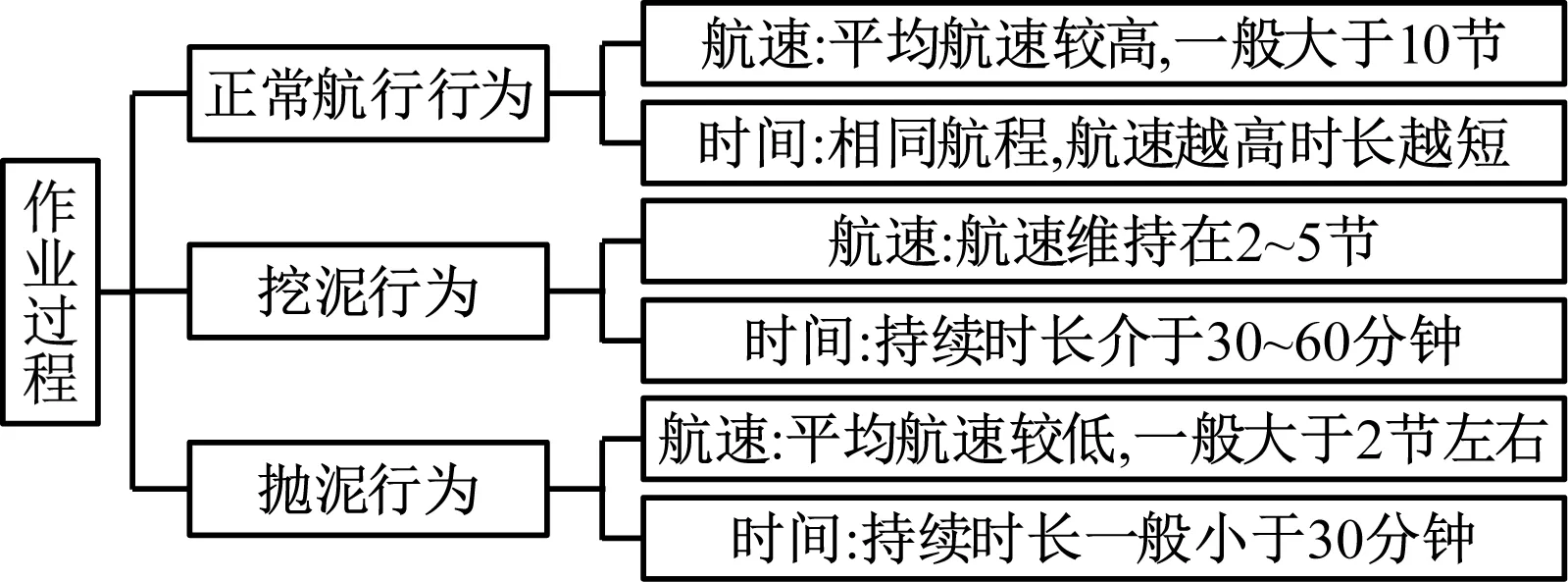
图4 作业过程航速及时间特征
2 耙吸式挖泥船行为辨识方法
2.1 算法思想
DBSCAN算法是由Ester[13]提出的一种基于密度的聚类方法,该方法将高密度区域划分为一类,并可以在带有“噪声”的空间数据中发现任意形状的聚簇。耙吸式挖泥船因其轨迹路径过于密集,无法直接通过空间密度区分不同行为,如图5所示,在空间结构上,每一处的轨迹点都是密集的,因此,时空维度的DBSCAN算法无法直接应用于船舶行为辨识。
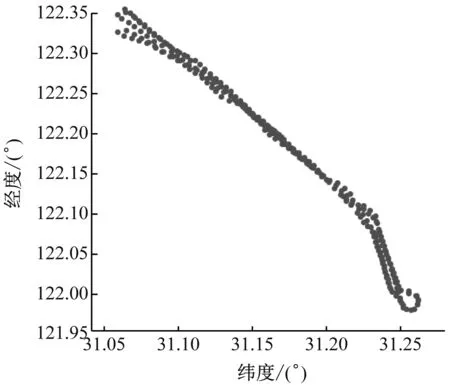
图5 轨迹空间结构分布图
结合其航速的周期性特征,将空间坐标转换为时间—航速坐标,如图6所示,可以发现航速在时间序列上也具有“密度”的性质。与空间结构上的密度聚类不同,航速是在时间序列上的变化,不能以邻域半径内的最小点数作为聚合标准,应考虑单位时间邻域半径内的最小轨迹长度。因此借鉴DBSCAN算法的原理,在时间序列上将航速密集区域划分为一个簇,从而提取整条单轨迹中具有相同航速特征的子轨迹。

图6 航速在时间序列上的分布图
2.2 低速轨迹聚类
Palma等人[14]最早发现速度在密度方面的性质,提出CB-SMoT(Clustering-based Stops and Moves of Trajectories)算法,用于发现轨迹中的低速区域。该方法对DBSCAN算法进行改进,以最小时间MinT代替使区域密集的最小点数,两点轨迹上的距离之和ε代替直线距离,ε与MinT之比就是各个邻域的最大平均速度。通过增大MinT参数,所提取轨迹的平均速度就会降低。该方法的相关定义如下。
定义1:令p=(x,y,t),x,y为该点经纬度,t为该时刻时间戳。
定义2:点pk的ε邻域为pi的集合:
LNε(pk)=
(1)
式中:ε为起始点与轨迹上相邻点之间的最大距离;d(pi,pi+1)表示pi与pi+1的轨迹距离,pk的邻域由两侧相邻点间距离之和不超过ε的轨迹子段构成。
定义3:如果p的邻域满足:
|tn-tm|≫MinT
则点p=(xp,yp,tp)称为轨迹的核心点。其中MinT是使区域密集的最小时间,n是LNε(p)的最后一个点,m是第一个点(邻域按时间排序)。
定义4:如果q∈LNε(pk)并且p是关于ε和MinT的核心点,则点q可以直接密度可达点p。
定义5:如果存在链q0,q1,q2,…,qN,且qN=p,pk+1是从pk关于ε和MinT直接密度可达的,则点q0从点p相对于ε和MinT密度可达。
定义6:如果存在点o,使得点p和q是从o关于ε和MinT密度可达,那p和q是关于ε和MinT密度相连的。
下面以图7的聚类过程介绍CB-SMoT算法流程。第一步,任意选取起始点P,生成P的ε邻域。图中轨迹段1、2、3的长度之和与轨迹段4、5的长度之和小于ε,即d(p4,p5)+d(p5,p6)+d(p6,p)≤ε且d(p,p8)+d(p8,p9)≤ε,得到P的ε邻域为{p4,p5,p6,p,p8,p9}。第二步,判定P是否为核心点。如果轨迹段1~5的持续时间之和大于MinT,即
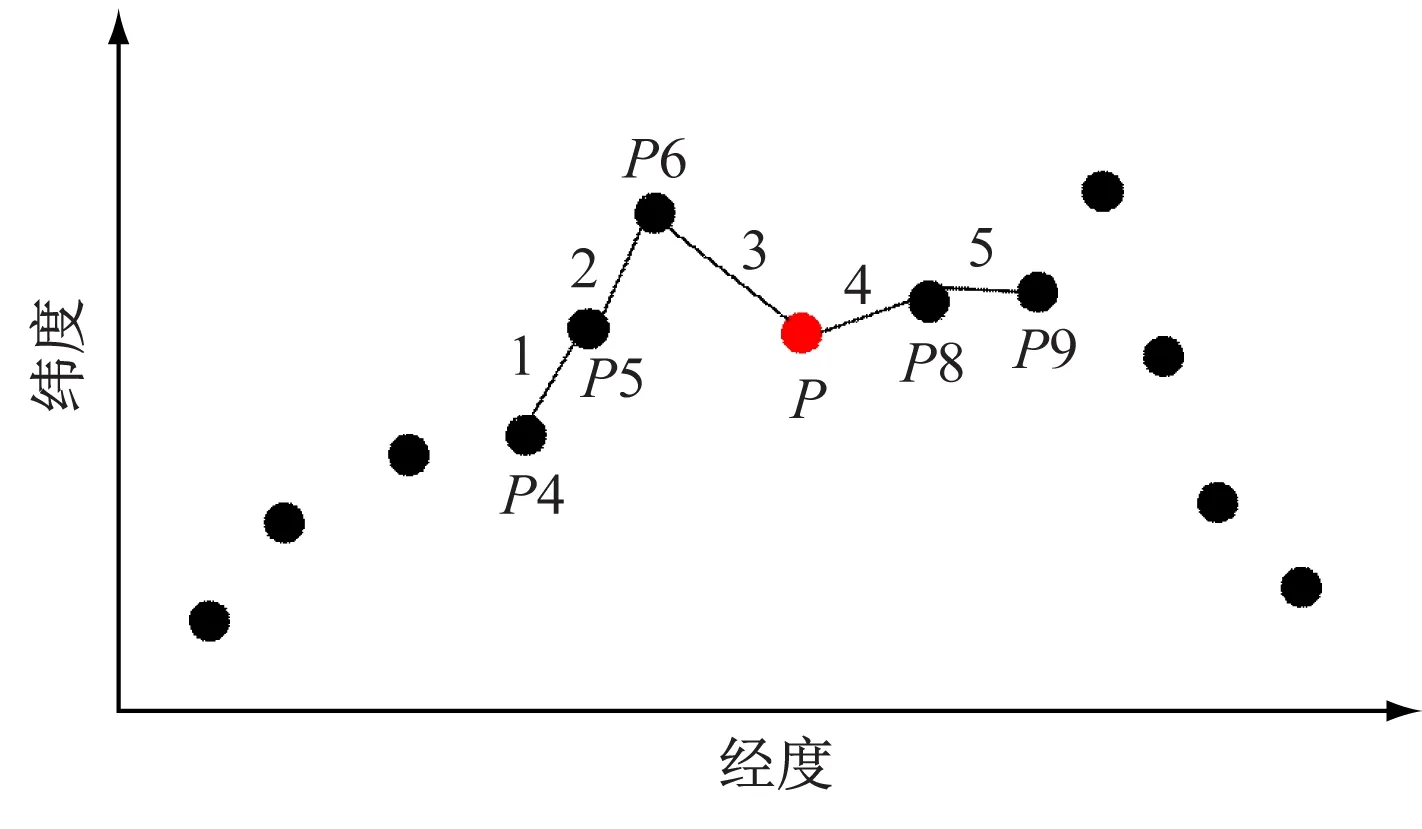
图7 CB-SMoT聚类过程示意图
|t9-t4|≫MinT,那么点P为核心点,生成簇C并将P邻域内所有点放入。第三步,扩展簇C。取C中未标记点,通过定义4~6对簇C进行扩展,遍历所有轨迹点。
2.3 多模式同步聚类方法
CB-SMoT算法能够高效识别低速轨迹,但是它的局限性在于只在速度低于给定阈值的轨迹段生成聚类,在图6中,CB-SMoT算法只在大圆处生成聚类,无法发现小圆处高密度区域;而且CB-SMoT算法每次运行只能识别一种具有相同速度特征的轨迹,对于不同的阈值,算法需运行多次。
在此基础上,对CB-SMoT算法进行改进:
1) 在核心点判别上,对MinT参数进行区间划分,使算法能够辨识任意区间的具有相同速度特征的轨迹。那么定义3将变为
MinTn-1≫|tn-tm|≫MinTn
(2)
2) 在聚类流程中添加核心点类别判别过程,通过邻域平均航速判断该轨迹段所属行为类别,实现多模式同步聚类。
多模式同步聚类方法的基本思想是:首先,检验每一个对象与相邻轨迹点之间的时间间隔是否小于用户给定的阈值,若小于阈值就认为这个对象周围足够密集,判定该点为核心点。然后,根据核心点邻域的时长对这条子轨迹进行分类,时长越长,表明该段轨迹平均航速越低。最后,对核心邻域进行扩展,得到不同行为模式的聚类结果。多模式同步聚类方法流程见图8。
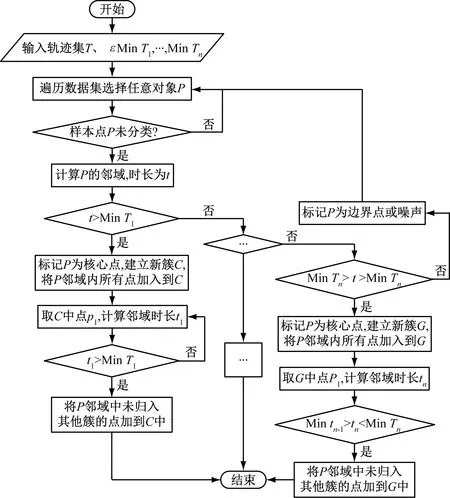
图8 多模式同步聚类方法流程图
通过上述过程,遍历完所有的轨迹点对象,最终类C…G确定下来,并且分别对应不同行为模式,如图9所示。图中用户共设置了3种模式,模式3的平均航速最低,说明该模式对应的最小持续时间阈值minT最大,模式2的平均航速最高,对应的minT最小。行为辨识方法按照用户设定的类别将簇划分为n类,每一类中包含平均速度符合阈值条件的所有子轨迹。对聚类所得子轨迹进行筛选,若轨迹持续时长|tn-tm|大于该模式的最大持续时长,则在轨迹两端去掉一个速度较大的点直到持续时间满足条件;若|tn-tm|小于该模式的最小持续时长,则舍弃该轨迹。经过轨迹筛选可得模式识别最终结果。

图9 改进算法结果示意图
2.4 效率指标计算
效率指标计算通过行网格化处理挖泥子轨迹,量化挖泥区域面积、挖泥时长以及挖泥轨迹总长度。采用均匀网格划分方法,将经纬度划分成等宽的区间,因为单位面积区域被挖泥子轨迹穿越的频数越高,则该区域是挖泥区域内一部分的可能性越大,所以对穿越频数较高的网格聚类即可得到挖泥区域。
包含n个高频网格的挖泥区域面积S的计算公式为
S=n×S单位网格
(3)
即单位网格面积与网格数的乘积。
每个高频网格内包含m个轨迹片段,pki表示第k个网格内的第i个轨迹点,则施工时长Time计算公式为
(4)
式中,t(pi,pj)为两点间时间间隔。
挖泥轨迹总长度L计算公式为
(5)
3 挖泥船行为辨识实例及应用
为了验证模型的可行性,选取MMSI编号为“412678000”的耙吸式挖泥船真实AIS数据进行验证,删除明显超过合理值的数据,包括错误的船位、速度等,采用三次样条插值方法[15]修复轨迹点,经预处理后数据包含24 518个轨迹点(已剔除速度为零的轨迹点),为该船2016年7月20日至2016年9月26日的航行数据。期间该船轨迹的经度跨度为0.721°,纬度跨度为0.321°,样本轨迹点分布如图10所示。

图10 轨迹点分布图
通过挖泥船行为辨识模型对该数据进行处理,反复进行实验,当ε=0.5 n mile、minT1=1 200 s、minT2=600 s、minT3=450 s、minT4=180 s时聚类结果比较理想,minT1设置抛泥行为平均速度小于1.5 kn,minT2、minT3设置挖泥行为平均速度介于3~4 kn,minT4设置航行行为平均速度大于10 kn。实验共提取到抛泥子轨迹93条,挖泥子轨迹653条,航行子轨迹879条,如图11所示。其中蓝色轨迹为提取到的挖泥行为,可以发现挖泥区域非常集中,抛泥行为所在区域与挖泥区域距离较远且比较集中,与实际情况相符。图12为三种行为在速度维度的部分聚类结果图,可以看到每种行为之间具有明显的分割距离,辨识效果较好。

图11 行为模式辨识结果

图12 速度维度辨识结果
通过网格化处理辨识得到的挖泥行为,筛选出挖泥子轨迹多次穿越的网格,然后对所有网格进行量化处理,得到粗略疏浚面积11.11平方海里,疏浚时长为22天12小时6分钟,挖泥子轨迹总长度为1 412.27 n mile。
为比较算法优劣,对改进的多模式同步聚类算法与CB-SMoT算法进行比较,以该船工作日志中的数据作为真实结果检验算法准确率,结果如表1所示。
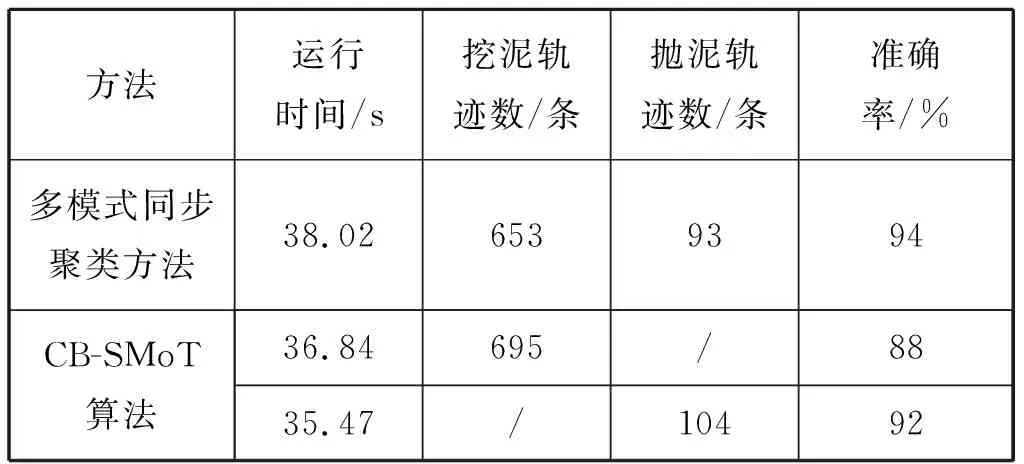
表1 两种算法对比
从表1中可以看出,多模式同步聚类方法在38.02 s完成挖泥和抛泥行为提取,CB-SMoT算法共用了72.31 s,多模式同步聚类方法在挖掘轨迹数量方面劣于传统的CB-SMoT算法,但是在运行速度和准确度方面皆优于CB-SMoT算法。这是因为多模式同步聚类方法在CB-SMoT基础上对子轨迹进行筛选及分类,在增加少量复杂度的代价下大幅度提高模式识别速率以及准确率。
由于每条耙吸式挖泥船的性能以及疏浚任务不同,在使用行为辨识模型时需要对数据进行调参,不断调整ε、minT阈值,得到最佳的模式识别准确率,在此基础上计算得到的挖泥效率指标也会更加准确。
4 结 语
耙吸式挖泥行为辨识存在较大难度,在AIS数据航行状态缺失条件下,设计并实现了耙吸式挖泥船不同行为的高效辨识方法。总结了耙吸式挖泥船施工作业时航速的周期性变化规律,定义正常航行、挖泥、抛泥三种行为;对CB-SMoT算法进行改进,划分阈值区间,实现多模式同步聚类;最后网格化处理挖泥轨迹,提出粗略估计挖泥效率指标的新方法。应用结果表明,多模式聚类方法能够高效处理复杂轨迹,耙吸式挖泥船行为辨识准确率可达到94%。该方法对疏浚作业的监管具有实际指导意义,可为船舶交通流特征提取、船舶异常行为检测等提供借鉴。
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
水上消防(2022年1期)2022-06-16
中国水运(2020年7期)2020-11-06
河南科技(2019年2期)2019-09-10
舰船科学技术(2018年7期)2018-07-25
中国港湾建设(2017年11期)2017-12-19
工业设计(2016年7期)2016-05-04
设备管理与维修(2016年5期)2016-03-16
舰船科学技术(2016年1期)2016-02-27
船海工程(2015年4期)2016-01-05
