
一种基于HiveSQL的增加任务并行度与建立中间表组合的优化查询方法
2021-03-14 00:50郑灵逸李擎
现代计算机 2021年36期
郑灵逸,李擎
(1.北京信息科技大学自动化学院,北京 100192;2.高动态导航技术北京市重点实验室,北京 100192)
0 引言
在如今的大数据时代[1],大数据的处理和查询越来越成为研究的重点和技术攻克的难关,其中主要的问题在于数据量级庞大并且数据每日更新,一方面很难对如此大量的数据做到有效的管理,另一方面也很难从数据量为Pb[2]的数据中得到所需要的数据。MySql 作为一种最流行的关系型数据库,它有着查询效率高、数据准确且无数据重复的特点,在数据量为Gb的数据处理场景当中被广泛使用。然而,在大数据处理场景之下[3],MySql存在明显的缺点,MySql在使用大量存储过程中每个连接的内存使用量将会大大增加,由于MySql 不允许调试存储的特点,使得开发和维护存储过程都较为困难。为了能够更好存储和处理Pb 级别的数据量,从大数据应用场景下提取所需要的数据,许多学者将Hadoop生态系统下的Hive数据库作为大数据场景下的存储和处理工具,并将SQL 作为Hive的查询工具。Hadoop 是一个开发和运行处理大数据的软件平台,是Apache 的一个用Java 语言实现的开源软件框架,实现通过大量计算机组成的集群对海量数据进行分布式计算。Hadoop 的核心是HDFS[4]、MapReduce 和YARN,这使得它具有可靠、高效、可伸缩的特点[5]。Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,是一种可以存储、查询和分析存储在Hadoop 中的大规模数据的工具。Hive 数据库由于其具有提供类SQL 查询语言HQL[6]、为超大数据集设计了计算和扩展能力[7]以及提供统一的元数据管理等优点,是其他大数据处理技术无法比拟的。其工作原理是把编写的SQL 语句进行解析,翻译成MapReduce 代码,然后在Hadoop 上执行[8]。因此,可以使用Hive 解决大数据场景下数据存储、处理和查询的问题。
一些学者发现在Hadoop平台上用Hive处理大数据时,在数据量超过Pb并且SQL查询语句冗长同时所需要的指标查询过多[9]的情况下,仍然会出现数据处理查询时间过长的问题。针对这一现象,马铁[10]提出了一种专为大规模数据处理而设计的快速通用的计算引擎Spark,不同于Hadoop MapReduce的是在Spark当中任务的中间输出结果可以保存在内存当中[11],由于这一特性,Spark在大数据场景下表现出来具有更快更高效的特性。但是Spark 本身没有自己的存储与Meta 库两种最核心的东西,需要依赖HDFS 和Hive 的相关功能[12],虽然SparkSQL 是非常具有潜力的,但目前来说仍然是以Hive Meta 库作为元数据管理HDFS 作为数据存储,并且Spark 本身的SQL 解析器不如Hive 同时由于Spark 是基于内存的特性导致建立在Spark 之上的大数据计算集群的成本会大大增加[13],因此从考虑成本和性能稳定性的角度出发,Spark仍然有许多不足之处。由于在大数据处理和查询时小文件会造成资源的多度占用以及影响查询效率,有的学者提出采用Sequence⁃File 作为表存储格式,而不用TextFile,在一定程度上可以减少小文件的个数,有的学者也提出采用JVM重用机制,该方式是Hadoop中调优参数的内容,对于小文件特别多的场景或者Task 特别多的场景这种调优方式对Hive 的性能有很大的帮助,在这类场景下的大数据执行时间都很短。但不管是SequenceFile 方法还是JVM 重用机制都只是针对小文件过多场景下的优化方法,对于多数情况下的大数据处理问题仍然是在数据量极大且所需要提取出的数据指标过多的场景中进行计算查询操作,所以根本的问题并没有得到一个很好的解决。因此本文提出采用增加复杂SQL 的任务并行度、提高集群利用效率和建立中间表的方法。在传统的Hadoop大数据生态系统基础上,采用基于Hive 数据库的编写SQL 的大数据查询方法,利用MapReduce 的可以并行执行的特性[14],即将一个复杂的SQL 任务拆分为多个并行执行,不仅可以将一个复杂冗长的SQL 代码细分为多个,使得每一个代码块的分工更加明确,还可以使计算查询结果一目了然方便阅读。另外,对于多个并行的SQL 任务有重复查询某几个相同的数据指标时,采用建立中间表的方法,也可以大大降低查询复杂度和查询时间。
1 基于Hadoop大数据生态系统的Hive数据库
Hadoop 是一个开发和运行处理大规模数据的软件平台,是Apache 的一个用Java 语言实现的开源软件框架,实现通过大量计算机组成的集群对海量数据进行分布式计算。Hadoop 的核心是HDFS和MapReduce以及YARN。

图1 hadoop核心架构
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,用于在低成本的通用硬件上运行。HDFS 简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序[15]。MapReduce 源自于Google 的MapReduce 论文,它是一种计算模型,用以进行大数据量的计算。其中Map 对数据集上的独立元素进行指定的操作,生成键值对形式中间结果。Reduce 则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce 这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。YARN 是一种新的Hadoop 资源管理器,它是一个通用资源管理系统,可谓上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
虽然Hadoop 框架是为大数据处理而设计的,但是如果直接使用Hadoop将面临学习成本过高以及MapReduce 实现复杂查询逻辑开发难度太大的问题。因此基于Hive 具有可扩展、高延展、高容错以及操作接口采用类SQL 语法提供快速开发能力的特性。将Hive 作为大数据处理计算和查询的工具是非常适合的。
2 大数据的计算处理和性能查询优化
本案例中,以某品牌手机浏览器当中推送文章为背景,获取与手机浏览器信息流中文章相关的数据,本文的hive 大数据处理计算和查询是基于四张大数据库中的表进行,分别是o2o_ne⁃whome_log_info 信息流用户日志表、newhome_valid_user_day 有效用户中间表、dwm_dvc_ne⁃whome_device_dura_di 停留时长中间表、 ne⁃whome_mcc_new_expose_imei_day 新用户表,总数据量在1Pb 左右。从1Pb 的数据中查询出信息流DAU、有效用户数、有效用户占比、用户次留、加权内容曝光量等18个指标。
2.1 数据计算查询框架设计
在本案例中,根据指标需求设计出单个任务执行的计算框架。首先从数据源的四张表中根据指标需求编写出相应代码,将求得的指标导入到自己创建的Hive表中,最后进入Hive表查看指标结果。
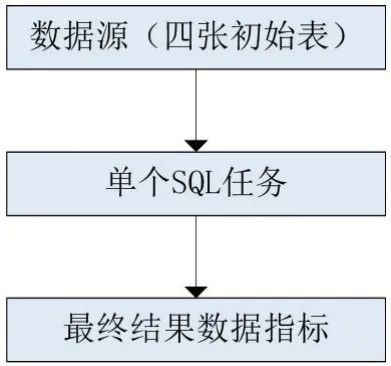
图2 单任务执行计算框架
在Hive 数据仓库中以上述四张源数据表作为基础,根据所需要求的18个数据指标,编写相应的SQL 操作代码,最后将所得到的数据指标进行输出打印。
整个数据处理时长为:
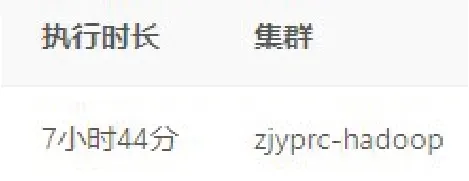
虽然最终能够查询出相应的指标结果,但是从执行时长来看,数据处理计算的时间过长,需要进行相应的优化。
2.2 增加sql的任务并行度优化方法
当单个查询SQL 执行时,集群只会分配单个任务资源进行数据的计算处理。因此,可以将一个复杂的SQL 拆分为多个SQL,即将单一任务转换为多个任务并行执行。当集群处于资源队列未满的情况时,这种方法也可以提高集群的利用效率。
本案例采用的策略是根据数据源的四张表将单个复杂的SQL 语句拆分为四个SQL 语句,即将原本单独执行的任务转变为四个任务并行执行。即
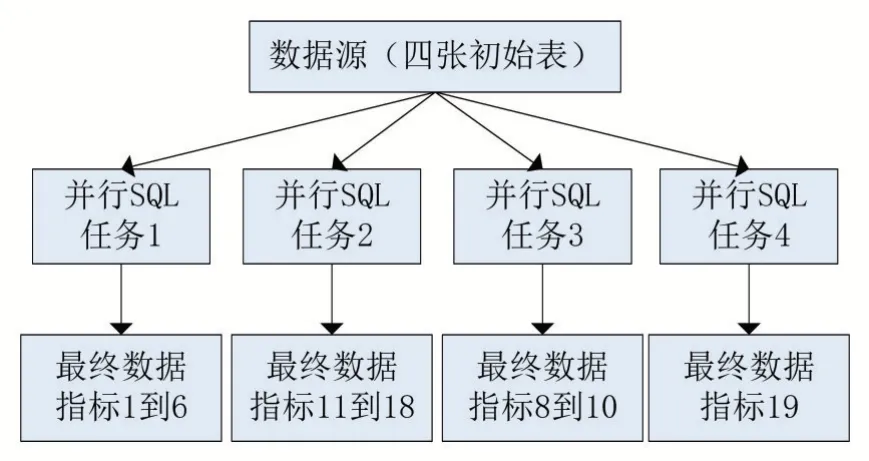
图3 多任务执行计算框架
整个数据处理时长为:

数据并行计算处理相较于之前的执行单个SQL 任务时长缩短60%,同时也提高了集群的利用效率。
2.3 建立中间表的优化方法
为了能够进一步缩短数据计算处理时长,设计了建立中间表的优化方法。针对某一个计算处理多个指标的SQL,通过聚合SQL 中相同的代码块提取出中间指标建立中间表,这种方法减少了代码冗余量的同时也缩短了任务执行时长。
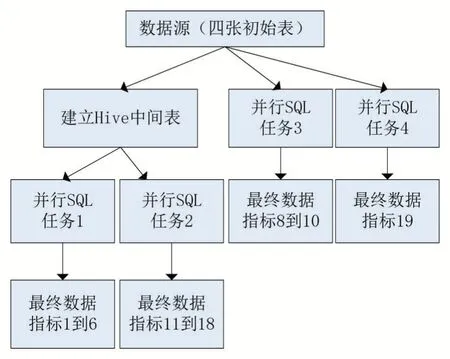
图4 多任务组合中间表计算框架
整个数据处理时长为

通过在任务并行计算的基础之上采用建立中间表的方式,相较于之前只通过任务并行优化的方式执行时长上缩短了25%,对比之前没有采取任何优化措施的执行方式时长上缩短了70%。
3 结语
该大数据计算处理优化方法采用增加任务并行度与建立中间表组合的方式,通过MapReduce进行数据计算。利用MapReduce 的执行特点,增加任务并行度提高集群使用效率,同时根据SQL的执行特性建立中间表,也大大降低了数据计算的时长。通过实验得出采用增加任务并行度融合建立中间表的方法相较于仅采用增加任务并行度的方法在计算时间上减少了30%,相较于不做任何优化处理的方式时间上减少了78%,并且提高了集群的使用效率,同时也能够很好的保证最后得到需要的数据。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
心理学报(2022年4期)2022-04-12
科技创新导报(2021年33期)2021-04-17
电脑爱好者(2020年19期)2020-10-20
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
软件导刊(2018年3期)2018-03-26
电子技术与软件工程(2016年24期)2017-02-23
知识就是力量(2017年2期)2017-01-21
科技与创新(2014年11期)2014-08-21
