
QoS 数据驱动的Web 服务发现方法研究
2021-03-17 07:41孙瑨一
科学技术创新 2021年5期
孙瑨一
(华北电力大学,北京102206)
1 概述
随着服务计算技术的不断发展,面向服务的体系结构(SOA)已成为一个重要的研究热点。SOA 是一种能够有效组织和利用分布式资源的体系结构,具有松耦合、动态性和可重用等特点。其接口和协议开放、系统实现灵活等优点,使SOA 可以作为未来各行业业务应用的实现方式。Web 服务是面向服务体系结构的实现方法之一。它的服务相互独立,并且独立于服务实现技术,可以同时接受多个请求并返回多个响应。大多数Web 服务是用Web 服务定义语言(WSDL)描述的,这是一种语法级描述[1]。它描述了Web 服务可以执行的操作、与Web 服务交互时的消息类型以及基于XML 语言的信息交换的物理端口等内容。Web 服务通常发布在服务注册中心的注册目录中。服务发现的过程即为将用户请求中的关键字与服务目录中的关键字进行比较,找到满足用户需求的服务。
服务质量(QoS)是指Web 服务的能力,目前它已经成为Web 服务实用性的一个重要标准,用来区分不同层次的服务,例如服务的响应时间、最大并发量、访问量等指标。QoS 为服务发现提供了可靠的依据,是服务发现的重要组成部分。
2 研究现状
Web 服务发现算法的发展可以分为三个阶段。初始发现算法主要是基于关键字匹配,通过贪婪算法、蚁群算法等启发式算法对存储服务图进行搜索。此发现方法简单且易于部署。然而,这种发现方法缺乏语义描述,召回率低,不能满足Web 服务快速发展的需要。在此基础上,一些研究者通过本体语义的方式提高了服务发现算法的查全率和查准率[2]。但这种方法也有很大的缺点:本体库必须由专业的专家来构建,这将消耗大量的人力物力,从而导致缺乏一个国际公认的标准本体库。之后,一些研究者利用数据挖掘技术从Web 服务描述文档中提取语义内容,并取得了一些研究成果。例如一些基于服务描述文本的聚类方法等。
同时,随着Web 服务的发展,越来越多的服务能够满足相同用户的需求。在服务发现过程中,不仅要求所选择的服务满足用户的功能需求,还要考虑非功能性的服务质量(QoS)需求。基于QoS 的Web 服务发现技术引起了众多研究者的关注,特别是如何从具有不同QoS 属性的高动态服务中,以有效的策略或方法在短时间内为用户选择可靠的服务,已成为服务选择领域的一个重要研究热点。
一般来说,从机器学习的角度研究可见Web 服务的发现方法是一个重要的研究方向:将Web 服务的WSDL 文档视为一种特殊的结构化文档,介绍了自然语言处理领域中的特征提取和聚类技术,提出了一种LDA 的服务发现方法,并通过GRU 网络对QoS 数据进行处理,最终为用户返回准确且可信的结果。这些研究内容为服务发现的研究提供了一些新的思路和方法。
3 方法实现
本文提出了一种QoS 数据驱动的Web 服务发现方法。该方法将Web 服务的WSDL 文档中的服务描述和Web 服务的QoS数据分别进行处理。如图1 所示:

图1 方法流程图
3.1 基于隐含狄利克雷分布(LDA)的服务聚类模型
主题模型是一种通过非监督学习的方式对含有语义信息的文本集进行聚类的统计模型,起主要被用于自然语言处理中的语义分析和文本挖掘。隐含狄利克雷分布(LDA)是一种基于贝叶斯模型的被广泛使用的主题模型,它将每篇文档视做一组无序单词组成的集合,并为每篇文档生成属于每个主题的概率分布。
本文提出的一种基于隐含狄利克雷分布(LDA)的服务聚类模型,将WSDL 文档中的服务描述部分视为一种特殊的结构化文档,用户对目标Web 服务的描述同样视为一个文档。通过该模型将这些文档根据功能进行聚类,同类中的Web 服务总是为一类功能描述相近、功能相似的服务。因此,与用户对目标Web服务描述相似度最高的若干个Web 服务,即可视为能够用户所需功能的Web 服务。
服务聚类过程的实现主要通过Python 中sklearn 工具包实现。其主要参数如表1 所示:
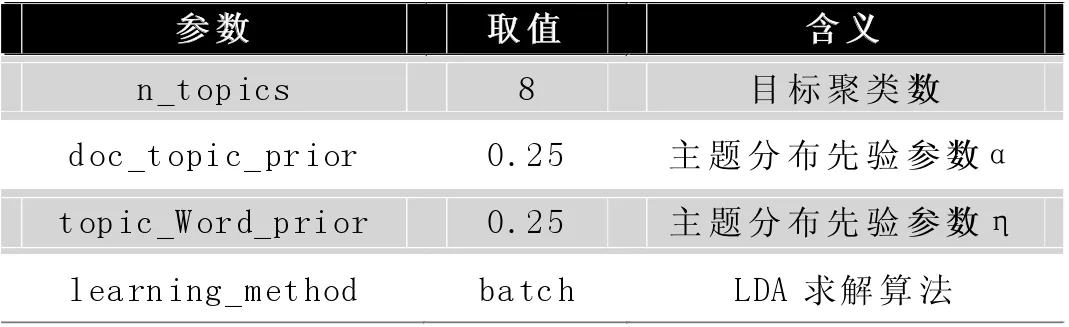
表1 LDA 模型参数设置
LDA 求解算法,即learning_method 取值为batch 而非online,是由于实验所使用的样本量较小,batch 方法即可满足需求。
3.2 基于循环门单元网络(GRU)的服务发现算法
GRU 是循环神经网络(RNN)的一种,和长短期神经网络(LSTM)一样,是为了解决长期记忆和反向传播中的梯度等问题而提出的。相比与LSTM,GRU 能够在保证训练结果可信度不降低的情况下,大幅提高了训练效率。
本文提出了一种基于循环门单元网络(GRU)的服务发现算法,目的是从服务聚类过程中返回的若干个满足用户功能需求的服务中发现最可信的Web 服务返回给用户。QoS 数据是从服务器网关中截取的一段时序性数列。QoS 数据有很多可选指标,例如可以从某Web 的响应时间判断,更快的响应速度代表该服务有更高的质量。综合考虑,本文共选取了4 个服务质量指标,并加权得出综合服务质量指数,如表2 所示:
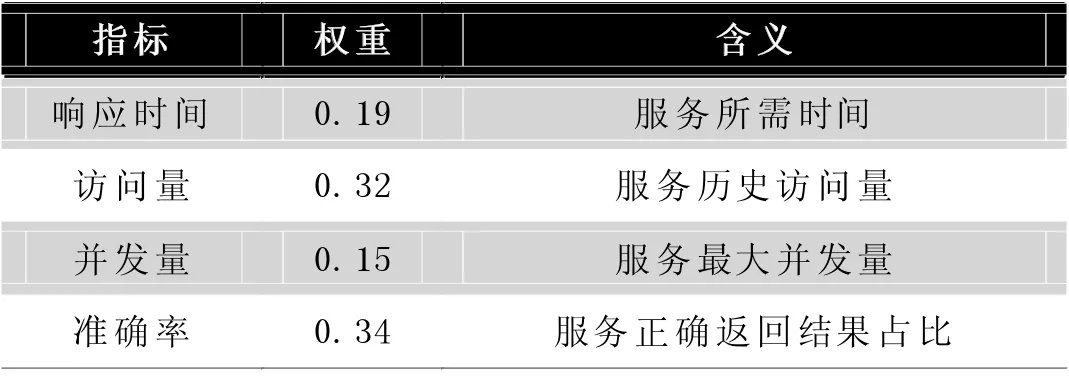
表2 服务质量指标及权重
通过对原始QoS 数据进行归一化、加权后,即可得到该服务随时间的历史综合服务质量指数序列。通过GRU 网络对序列数据进行处理,神经网络模型会将其中蕴含的时序信息进行记忆,最终返回给用户当前时刻,调用该服务的综合服务质量指数,从而进一步提高服务发现的可信度。
4 实验设计与结果
本文分别从服务聚类模型和服务发现算法两部分分别进行了实验设计验证。
针对服务聚类模型,为验证服务聚类模型的可信度,本文从新浪微博“#疫情#”话题中通过selenium 自动化控制模块,爬取了3800 条微博内容作为测试集。实验将整个数据集分为A组(900 条文本)、B 组(1400 条文本)和C 组(1500 条文本),通过三组对照实验,消除误差,从而验证模型可行性。从聚类结果的pyLDAvis 视图可以看出,该组内所有文本被成功分为了8类,符合模型预设参数,但是存在部分簇重叠现象。轮廓系数是一种常用的评价聚类结果的参数,其取值范围为[-1,1]。对聚类结果计算轮廓系数为:A 组0.53,B 组0.44,C 组0.52。从轮廓系数可以看出,该聚类模型具有较好的聚类效果,但存在簇重叠现象,有进一步改进的空间。
针对服务发现算法,为了验证GRU 网络的可行性,本文使用 了 RNN 循 环 网 络 中 经 典 的 公 开 数 据 集international-airline-passengers。GRU 网络运行结果如图2:
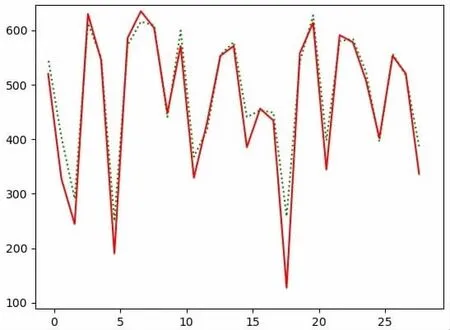
图2 GRU 网络运行结果
图2 中绿色虚线为数据集中的真实数据,红色实线为GRU网络模拟结果。从图2 可以看出,本文构建的GRU 网络具有较高的可信度。
5 结论
如何通过分类的思想提高服务发现的效率,在Web 服务的相关研究中是非常重要的。本文提出的QoS 数据驱动的Web 服务发现方法将服务描述文档视为一种特殊的结构化文本,通过LDA 模型将服务聚类,并通过GRU 网络模型处理QoS 数据,从而完成了整个服务发现的流程。服务聚类的实验结果表明,该方法相较早期语法级服务发现方法,更加注重了语义信息,在实验环境有较好的结果。在此基础上,通过GRU 网络处理QoS 数据,使得最终服务发现结果包含了QoS 数据中的时序性数据。但是,该方法仍有不足之处,以上的实验结果均是由模拟数据集得出,在真实环境的应用中,该方法面对真实的服务数据仍需要调整参数和优化模型结构。在以后的工作中,我们将继续进行相关研究,探索该方法的优化及改进。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
健康护理(2022年3期)2022-05-26
中国典型病例大全(2022年13期)2022-05-10
锦州医科大学报(2022年2期)2022-05-07
中国新闻周刊(2021年26期)2021-07-27
计算机应用与软件(2021年7期)2021-07-16
电脑爱好者(2021年9期)2021-05-12
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
科技传播(2019年23期)2020-01-18
