
随机森林算法在新疆物种丰富度影响因素研究中的应用
2021-03-17 07:21李光一李海萍万华伟李利平中国人民大学环境学院北京100872贵州省生态气象和卫星遥感中心贵州贵阳550002生态环境部卫星环境应用中心北京10009中国科学院空天信息创新研究院北京10009
中国环境科学 2021年2期
李光一,李海萍,万华伟,李利平 (1.中国人民大学环境学院,北京 100872;2.贵州省生态气象和卫星遥感中心,贵州贵阳 550002;.生态环境部卫星环境应用中心,北京 10009;.中国科学院空天信息创新研究院,北京 10009)
新疆独特的地理环境和丰富的生态系统,孕育了众多的珍稀动植物.2015 年发布的《中国生物多样性保护优先区域范围》[1]中的35 个优先区域中新疆有阿尔泰山、天山-准格尔盆地、塔里木河流域、羌塘-三江源和库姆塔格5 个.2016 年又新建了霍城四爪陆龟和伊犁小叶白蜡2 个国家级自然保护区.现有记载显示,新疆有鸟类319 种,哺乳类79 种,其中37 种为我国特有,29 种为世界特有[2-3].
1949 年以来我国人口膨胀、耕地扩张带来了水资源、草地和天然林减少,而沙地却持续扩张,生境的剧烈变化使物种丰富度不断下降.据统计,新疆野生动物数量已不足20 世纪70 年代的25%,在《中国生物多样性红色名录-脊椎动物卷》中新疆有近危103 种、易危44 种、濒危40 种、极危12 种、区域灭绝2 种,野外灭绝2 种[4],野生双峰驼、新疆北鲵等国家一类保护动物种群数量减少至濒临灭绝.生物多样性降低使地区生态平衡、生态安全受到严重威胁.因此,研究影响物种丰富度的环境因子对维护新疆生物多样性具有重要理论意义.
有关物种丰富度与环境因子的关系研究中,基于统计回归的研究最普遍,刘路平[5]采用SPSS 软件对山东省鸟类物种丰富度与环境因子的关系进行了相关和多元线性回归分析.刘澈等[6]在研究中国鸟类物种丰富度与环境因子的关系时,采用Origin Pro 8 以及SPSS 进行主成分分析,得到了更精简的影响因子组合.田凯[7]采用Pearson 线性相关分析研究武汉西北部野生脊椎动物主要类群的丰富度与环境因子的关系.沈梦伟等[8]利用R 和SAM 软件,基于最小二乘法建立一元线性回归模型,考察了气候因子对两栖动物物种丰富度的解释能力,并根据AIC 信息量准则筛选出最优模型及其所包含的变量.
由于地理环境的空间异质性及相互依存性,单纯运用统计方法或建立单一的回归模型并不能很好地解释物种丰富度和环境因子的关系,GIS 技术则被广泛地应用于生物多样性领域[9].同时,随机森林等新算法被逐步引入,该方法在评估环境因子对研究对象的重要性方面具有明显优势[9],Lopatin等[10]基于随机森林算法识别出模拟维管植物物种丰富度最重要的3 个环境变量,其结果与生态学理论一致.李紫晶[11]利用随机森林模型筛选了影响草原和旱生灌丛生物多样性、群落生物量重要的环境因子,并通过拟合模型分析了环境因素对二者的影响.有鉴于此,本文将提取新疆草地、林地、耕地作为研究区,充分利用长时间序列遥感产品的快速更新与优化这一优势,基于多种遥感参量及环境因素,通过对比随机森林和探索性回归分析结果,探讨新疆地区鸟类与哺乳动物多样性与其影响因素间的关系,以期为该地区的生物多样性保护提供科学的决策依据.
1 数据与方法
1.1 数据
1.1.1 物种分布数据 新疆地区鸟类和哺乳动物物种分布数据源于李利平等人的研究成果,该数据根据《新疆鸟类名录》[2]和《新疆哺乳类(兽纲)名录》[3]中的物种实际分布范围,经数字化并投影转换到WGS-84 大地坐标系中得到10km×10km 物种分布矢量数据,见图1.属性表包括网格中心坐标、面积及鸟类与哺乳动物的种数和科数等专题信息,如表1.由于后续分析采用的数据结构为栅格数据,故将物种分布矢量数据转换为栅格格式.

图1 新疆鸟类与哺乳动物物种种数矢量网格Fig.1 Vector data of bird and mammal species in Xinjiang

表1 物种丰富度属性表数据项示例Table 1 Examples of data in the species richness attribute table
1.1.2 植被数据 大多数鸟类和哺乳动物偏向生活在有植被覆盖的区域,故本文重点研究草地、林地和耕地等生境.因目前的植被指数已有大约40 多种,而归一化植被指数(NDVI)、增强型植被指数(EVI)是最能直接反映植被覆盖的遥感信息,除此之外本文还增加了叶面积指数(LAI)、光合有效辐射吸收比(FAPAR)和净初级生产力(NPP)等能够间接反映植被生长状态的因子,且这些因子不仅能够直接反映动物生境中植被群落在自然环境条件下的生产能力,表征陆地生态系统的质量状况,而且是判定生态系统碳源/汇和调节生态过程的主要因子.
NDVI 和NPP 源于中国科学院资源环境科学数据中心云平台(http://www.resdc.cn/Default.aspx),NDVI 是对SPOT/VEGETATION 采用最大值合成法生成的1998 年以来的月度数据.NPP 是基于光能利用率模型GLM_PEM 计算得到的2000~2010 年年度数据,空间分辨率均为1km.
EVI 来自美国国家航空航天局(NASA)LP DAAC 数据集中2001~2010 年MODIS/Terra 数据产品MOD13A3,为月度1km 空间分辨率3 级正弦曲线投影产品.
LAI 和FAPAR 源于国家地球系统科学数据中心(http://www.geodata.cn)平台中GLASS 全球陆表特征参量产品LAI_modis 和FAPAR_modis 数据集,时、空分辨率为8d 和1km.
1.1.3 地形和气候数据 全世界生存高度最高的哺乳动物牦牛多在3000~5000m 的高寒地区生活,爬高极限可达6400m[12-13],可见海拔高度也是重要的生境因素之一,本文数字高程模型(DEM)为雷达地形测绘SRTM(Shuttle Radar Topography Mission)90m 分辨率的数据.
气候是动物生境选择的重要因素,如骆驼的特殊生理结构使其具有很强的蓄水能力并适应在炽热的沙漠中行走[14],全球变暖使得鸟类的地理分布范围向高纬度高海拔迁移[15-17].因此,本文选取温度和降水作为生境的气候因子,将资源环境数据云平台的气象站点监测数据通过空间插值处理成2001~2010 年年均气温和年降水量连续分布数据.
1.1.4 辅助数据 人类对物种丰富度具有正向影响和负面影响两种,正向影响体现在人类所建立的自然保护区对物种多样性的促进作用,负面影响则通过对土地的开发利用而破坏物种栖息地产生.两类数据中,自然保护区点位源于相关资料和文献整理,2010 年1km 土地利用/土地覆盖变化数据源自中科院中国土地利用遥感监测数据库,均作为辅助数据对物种丰富度空间分布作解释说明.
1.2 方法
1.2.1 趋势分析法 植被生长是长时间的累积过程,依据一个时间点的数据进行评价的结果不够准确,通过长时间序列数据得到特定时间段内的综合植被生长状态显然更接近实际.夏季是植被的生长季,也是动植物种群最丰富的时期,已有相关研究表明,夏季(7~9 月)的遥感植被参数累积量能很好地代表新疆地区植被的空间分布格局,且与物种数量相关性最高[18-19].因此采用最大值合成法计算长时间序列的年夏季累积量,公式如下:
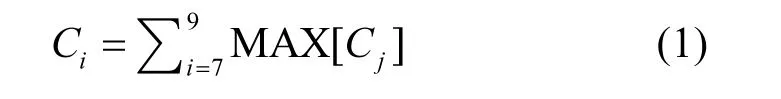
式中:Ci表示i 年夏季累积量,MAX[Cj]为第j 月内的月最大值.通过采用k 值趋势分析法,逐像元对植被覆盖的时间序列变化趋势进行分析[20].公式为:

式中:n 为研究期年数,变化率k>0.001 表示改善趋势,-0.001≤k≤0.001 表示基本不变,k<-0.001 表示退化趋势.
1.2.2 随机森林法(Random Forest, RF) 20 世纪80 年代Breiman 等[21]基于bagging 的思想提出了分类树的算法,通过数据的多次分类与回归,计算量得到降低.2001 年Breiman 把分类树组合成随机森林,通过自助法(bootstrap)重采样技术,从原始训练样本集N 中,多次且有放回地随机抽取n 个样本,生成新的决策树训练样本集,再根据上述步骤生成m 棵决策树并建立随机森林,新的分类结果由分类树的投票数所得分数决定,其实质是对决策树算法的改进[22].
作为一种新兴且高度灵活的机器学习算法,RF 无需降维即能处理高维空间数据集,除了拟合变量间的关系外,对数据量纲和共线也不敏感,无需进行归一化、诊断、剔除等操作,而是将所有解释变量全部输入,通过比较某个变量在加入噪声前后的模型OOB(袋外数据)拟合误差来判定该变量的重要性及其对模型的影响,若OOB 误差下降大,说明该变量对模型贡献也大,即重要性较高[23-24].模型最初主要通过R 语言中的随机森林包实现[25],2019 年ArcGIS Pro 在其2.3 版本中增加了此功能模块,既可对采样点数据建模,也可对矢量或栅格数据建模,通过加入相应的栅格或矢量变量可直接获得预测结果的空间分布,比在编程中实现更加便捷、高效.
1.2.3 探索性回归分析(Exploratory regression analysis, ERA)20 世纪 30 年代瑞典心理学家Thurstone[26]提出多因子分析理论,并在《心智向量》中系统阐述了多元分析的数学理论和逻辑基础.因子分析分为验证性和探索性两类,探索性回归分析能对输入的候选变量间所有可能模型进行评估,以寻找能最好解释因变量的OLS 模型.建模前对所有因子进行共线性诊断,诊断报告中方差膨胀因子值(VIF)用于度量变量的冗余度,并判断不削弱模型解释力时要剔除的变量;冲突值表示变量间的信息重叠度,0 表示无信息冗余;协变量表示与因变量线性相关并和其他自变量存在信息冗余的变量,应予以剔除或控制.若两个以上的VIF 值超过5.0,则根据VIF 值和冲突值大小剔除一个变量并重新建立OLS,直到冗余消失.因此基于以上参数剔除冗余变量,并对剩余变量进行空间关系建模,既简化了模型又提高了精度.同时,还可根据AIC 信息量准则衡量模型的拟合优度及复杂性,从而筛选出更精确的关系模型,经精度检验和综合分析,生成标准残差报告以验证结果的精度并得出结论.以上过程在ArcGIS Pro中实现.
2 结果与讨论
2.1 环境因子的时空特征分析
2.1.1 植被因子的时空特征 从土地利用中提取植被覆盖区,基于最大值合成法得到各植被因子逐年夏季累积值,运用k 值趋势分析法,得到各植被因子的空间变化及统计结果见图2 和表2.

图2 2001~2010 年植被覆盖地区植被因子变化空间特征Fig.2 Spatial characteristics of vegetation factor changes in vegetation covered areas from 2001 to 2010

表2 2001~2010 年各植被因子变化统计(%)Table 2 Variation of vegetation factors from 2001 to 2010(%)
各植被因子的综合变化率显示,改善区域主要在天山北坡、塔里木盆地西部绿洲以及南部山地.植被生长主要受水分和热量影响,天山以北的准噶尔盆地未完全封闭,气流进入形成地形雨,而南部的塔里木盆地被天山和昆仑山包围而闭合,因而天山北坡降水多于南坡且植被条件易于改善,而南坡则因水分缺乏而不利森林生长.塔克拉玛干沙漠附近人工绿洲面积有所增加,植被以改善和基本不变为主.
阿尔泰山区、伊犁河附近、天山西段、塔城等地区植被呈退化趋势.相关研究表明,北疆准噶尔盆地内部的古尔班通古特沙漠中,固定半固定沙丘活化面积不断扩大,沙漠边缘的流沙不断向绿洲扩展27].南疆各植被因子的变化差异明显,总体上红色退化区域较少,以基本不变和改善为主,说明生态环境保持良好,这与其他学者监测的新疆植被动态变化结果比较一致[20].
可见,2001~2010 年间大部分的植被覆盖区NDVI 和EVI 均有变化,或改善或退化,无变化的区域极少,LAI 以退化和基本不变为主,而FAPAR、NPP则三种变化普遍存在.北部与西北部虽资源丰富且自然保护区较多,但众多的特色产业和旅游业等人类活动干扰也较强,植被退化趋势明显.西南部的帕米尔高原-昆仑山区,FAPAR 与NPP 以改善和基本不变为主,LAI 值却有所降低,同一区域不同因子呈反向变化,进一步说明单因子不能很好地解释自然生境的变化趋势.
2.1.2 地形和气候特征 新疆高差较大,常用的高程划分标准难以详细表达其内部的地形差异,因此本文参考有关新疆地形特征的研究结果进行划分28],见图3(a).此外,将无植被区设为空值(Null),提取植被覆盖区域的年降水量(MAP)和年均气温(MAT),结果见图3(b)和3(c).

图3 新疆海拔分区以及植被覆盖区域2010 年年降水量与年均温空间分布Fig.3 Landform zoning and distribution of annual precipitation and average temperature in vegetation covered areas in 2010 of Xinjiang
可以看出,新疆地势复杂,空间差异显著,南疆高于北疆,西部高于东部.塔里木盆地、准噶尔盆地和吐鲁番盆地地势较低.三大山脉中阿尔泰山相对较低,天山部分山段海拔超过4000m,昆仑山大部分为4000m以上[29].由于海拔和气温及降水的高相关性,气温和降水的空间差异也十分显著,降水量北疆多于南疆,西部多于东部,山区多于盆地,盆地区由外向内干旱高温加剧,南疆气温高于北疆,盆地高于山区[30].

图4 新疆地区自然保护区与人类活动Fig.4 Natural reserves and human activities in Xinjiang
2.1.3 人类活动空间特征 将现有15 个国家级和29 个自治区级自然保护区视为人类活动的正向影响区,将城镇、居民点和其他建设用地作为负面影响区,得到人类活动的空间分布,见图4.
国家级自然保护区集中分布在西北部的北屯、塔城和伊犁等地,自治区级则比较分散.人类活动区域很小,且北疆多于南疆,人类活动集中的区域一般保护区也较少,两者仅有部分重叠.
2.2 基于随机森林法的环境因子重要性评估
2.2.1 随机森林的棵数 为保证模型精度,建模前要判 定构建森林的最佳决策树棵数.对于每个决策树模型,假设训练样本的特征数为m(本研究为8个环境因子),每次分类时根据信息增益选择最好的特征进行分裂.每棵决策树的生成都需要自助采样,余下 1/3 的数据未被选中,称为袋外数据(OOB,out-of-ag),OOB 误差斜率越小则表明决策树棵数越理想,因此根据OOB 误差确定最佳决策树棵数,分别在草地、林地和耕地生境中建模,结果见图5.
鸟类和哺乳动物在草地和耕地生境中,误差变化有一定规律,决策树在600 棵左右趋于平稳,林地生境中,鸟类和哺乳类动物分别在700 棵和500 棵左右趋于稳定.

图5 袋外数据(OOB)误差随决策树棵数的变化Fig.5 OOB changes with decision tree
2.2.2 环境因子重要性评估 将鸟类与哺乳动物物种丰富度作为因变量,输入8 个环境解释变量,在ArcGIS Pro 中运行随机森林分类与回归模块,生成不同生境中各环境因子的重要性排序,见图6.
鸟类在草地与耕地生境中各因子的重要性差异较大,在林地中则较小,这与鸟类更偏好森林生境有关.三种生境中DEM 的重要性排序均较高,说明鸟类飞行高度对其生境选择十分重要,在草地生境中最高为38.38%,远高于其他因子,表明新疆的草地分布高度与鸟类多样性密切相关.耕地生境中,年均温最重要,叶面积指数影响最小,除气候和地形外,各植被因子的重要性基本一致,表明耕地已成为鸟类重要的生境,能够为其提供丰富的食物来源.

图6 不同生境中影响鸟类(左)与哺乳动物(右)丰富度的环境因子重要性排序Fig.6 The importance of determinants affecting the birds (left) and mammals (right) species richness in different habitats
对于哺乳动物,各因子在三种生境中的作用差异显著,气候和地形在三种生境中的重要性均较高,以年均温为最高,说明气候对哺乳动物的生境选择十分重要.草地生境中的年均温最重要,年降水量次之,净初级生产力重要性最低.林地生境中,EVI 有所提高,NPP 仍然最低,说明植被覆盖度比净初级生产力对哺乳动物更重要.耕地生境中,年均温度影响最大,叶面积指数最小,与鸟类相似的是,各植被因子的重要性也相对均匀,表明哺乳动物在耕地生境中更看重气候而非植被生长情况.
2.3 物种丰富度与环境因子的探索性回归分析
2.3.1 环境因子的多重共线性诊断 以物种丰富度为因变量,输入全部环境因子后得到不同生境中的共线性诊断结果,见表3.

表3 不同生境中的多重共线性诊断结果Table 3 Multicollinearity diagnosis results in different habitats
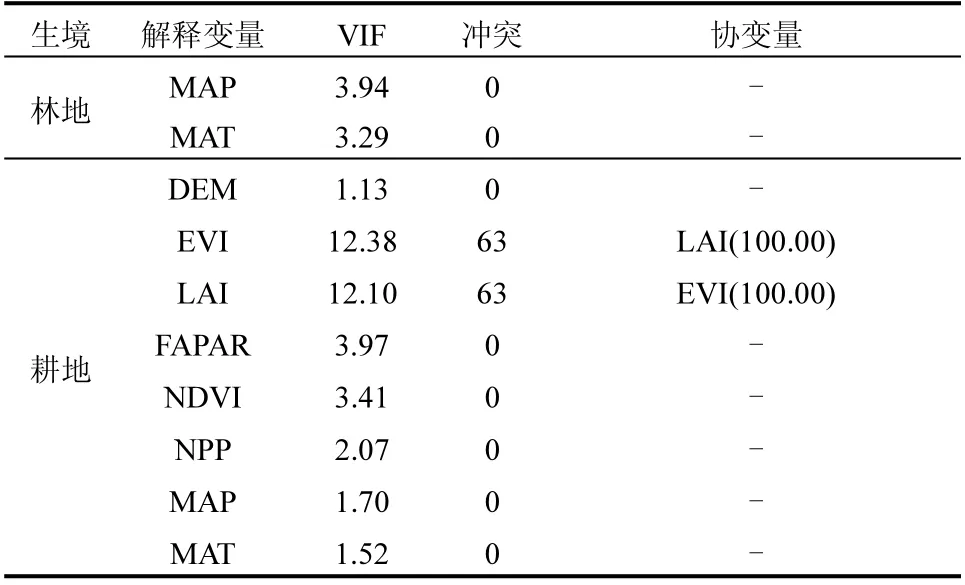
续表3
若两个以上的VIF 值超过5.0,则根据VIF 值和冲突值大小剔除一个变量并重新建立模型,直到冗余消失.由表3 可见,草地和林地生境中,EVI、LAI 和NDVI 都产生了协变量,存在多重共线性,根据VIF 和冲突值依次剔除EVI 和LAI,剩余6 个解释因子.耕地生境中,EVI 与LAI 存在共线性,故将EVI 剔除.
2.3.2 物种丰富度与环境因子的关系模型 多重共线处理后,对基于保留因子所建立的所有模型,依据AIC 信息量准则进一步筛选出不同生境中的最优解释模型,结果见表4.
可见,三种生境中鸟类和哺乳动物的最优模型及其影响因子均不同,由此也证明分别建立回归模型的必要性.所有最优模型的解释力均在50%以上,耕地对于鸟类、林地对于哺乳动物的模型解释力最高,分别为69.9%和68.9%.
鸟类的三种生境模型均保留了FAPAR,说明植被生长状态与能量转换能力对鸟类多样性十分重要.草地中的鸟类受飞行高度限制,海拔是主要影响因子,NPP 次之.林地生境模型仅MAT、NPP 和FAPAR 三个变量,说明森林的温度调节、植被覆盖和能量转换对鸟类丰富度具有重要意义.耕地因其作物种植而吸引鸟类栖息,故NPP 最具解释力.此外,在草地和耕地生境中,年均温的解释能力均为负值,说明这两类生境中温度越高,鸟类丰富度越低.
有别于鸟类,哺乳动物的三种生境模型均保留了MAT、MAP 和DEM 三个变量,说明气候和地形是哺乳动物多样性的重要环境因子,且气候的解释力最强.草地和耕地生境中年均温的解释力最强,林地因其所具有的温度调节作用,年降水量的解释力最强,且NPP 未被保留,说明植被的能量转换能力弱于其他因素的影响,NDVI 的保留说明植被覆盖度对哺乳动物丰富度的影响更大.

表4 基于AIC 准则得到的物种丰富度解释模型Table 4 Interpretation model of species richness based on AIC
2.4 物种丰富度影响因子的综合评估
将随机森林(RF)的因子重要性排序与探索性回归分析(ERA)筛选的变量及最优解释模型进行对比,以综合评估影响鸟类和哺乳动物丰富度的重要因子,三种生境中各因子的对比见表5.
鸟类在三种生境的模型中除NPP 外,其余因子的模型解释力与RF 的重要性排序一致,表明保留因子的解释力与重要性排序的差异可接受.NPP 和FAPAR 的重要性排序不靠前,但在回归模型中均被保留,表明NPP 是鸟类物种丰富度差异的重要影响因素.草地生境中,海拔既是鸟类生境选择的重要变量又是模型解释力最强的变量,是影响鸟类丰富度的重要因子,这与生态学中鸟类栖息环境的海拔高度取决于其飞行高度的能力是一致的,不同的海拔高度适宜生存的鸟类种群及其数量不同,高海拔环境尤其是低氧与高寒迫使该区域鸟类具有较强的携氧与能量代谢能力,以应对缺氧环境,并在低温环境中维持正常生命活动[31-33].林地生境中,回归模型未保留DEM,年均温是最具解释力的变量,两种结果完全相反,说明林地的海拔高度对鸟类生存固然重要,但其内部的温度差异更能解释其中的鸟类丰富度.由于人类活动的乱砍乱伐,导致栖息地破碎化,全世界4000 多个物种的统计显示,大约一半的物种正在经历生存区域的变化,向上并向两极移动,以适应全球变暖的趋势,然而向高海拔高纬度迁徙的鸟类需要寻找适宜自己生存的温度环境,在高海拔林地的高寒环境中,生存的鸟类必须具备较强的耐寒能力,故森林内部的温度是鸟类生境选择的重要因素[33-34].耕地模型中保留了前5 个因子,最具解释力的是NPP,说明植被的能量创造力是表征耕地质量好坏的典型特征值,直接影响鸟类是否选择在其中生存.

表5 不同生境中影响物种丰富度的因子对比Table 5 Comparison of factors affecting species richness in different habitats
对于哺乳动物,RF 重要性前三的MAT、MAP和DEM 也均保留在回归模型中,说明气候和海拔是影响哺乳动物丰富度的重要因子.草地生境中,回归模型筛选出的DEM 和NDVI 解释力与RF 的重要性排序变换了位次,其余因子排序未变.林地生境中出现MAP 和MAT 的解释能力排序交换.耕地与草地生境中的回归模型相似,保留的DEM 和NPP 的重要性排序与回归模型也发生交换,但两种方法均显示了年均温、年降水量和海拔高度是哺乳动物丰富度差异的重要解释因子.这意味着在全球气候变暖的大背景下,气候变化改变着动物的栖息环境,并在全国乃至全球范围内重新分配物种,导致许多物种濒临灭绝.
2.5 模型精度检验
2.5.1 随机森林模型的精度 ArcGIS Pro 建模时即会生成训练数据和验证数据的精度报告,除标准误差(SE)外,还生成判定假设检验结果的P 值,以及表示模型拟合程度的R2,R2越接近1 说明回归直线对观测值的拟合程度越好,越接近0 表示越差,精度评价结果见表6.
可见,基于前述决策树棵数建立的模型中,在P值小于0.01的情况下,R2均大于0.7,表示模型拟合程度很好,SE 均小于0.1,表示误差在可接受范围内,实验结果具有显著统计学意义.

表6 鸟类和哺乳动物在不同生境下的随机森林模型精度验证Table 6 Accuracy verification of random forest models of birds and mammals in different habitats
2.5.2 探索性回归关系模型检验 残差是对实际观察值与回归估计值差异程度的一种评价,若某一实验点的标准化残差(SR)落在(-2,2)区间以外,表示可在95%置信度下将其判为异常实验点,也就是说当大约95%的标准化残差在(-2,2)区间以内,误差项基本服从正态分布,研究结果可信度较高.分别计算并绘制鸟类和哺乳动物在三种生境中的残差图,见图7.

图7 鸟类(上)与哺乳动物(下)三种生境模型的标准残差Fig.7 Standard residual of models in three habitat for birds (top) and mammals (bottom)
鸟类和哺乳动物在草地生境中的残差均值小于众数,标准残差图呈峰值右偏的负偏态分布.鸟类在耕地生境中,存在两个残差众数,标准残差呈双峰分布.各模型的标准残差在(-2,2)区间外的异常试验点均低于5%,且残差项基本服从标准正态分布,说明所建回归模型的误差可接受.
3 结语
本研究通过建立随机森林的重要性评估模型和探索性回归模型,可以在多个影响新疆地区鸟类与哺乳动物物种丰富度的因素中识别出较重要的因子,不仅充实了生物多样性研究方法,也提升了研究精度.水域不仅能够为动物提供良好的适宜环境,也能提供必要的机体能量,针对新疆地域辽阔、地貌类型多样的特点,在今后的研究中可考虑水体面积对物种丰富度空间分布的影响,采用空间格网化后的栅格数据,提取植被覆盖区的各项环境因子,可深入分析鸟类和哺乳动物在不同生境中的多样性差异及主要影响因子.由于不同数据的空间尺度不同,本文在进行多源数据融合的同时,将环境因子数据进行了重采样的升尺度变换,平滑了空间差异性,从而降低了数据精度,虽然对于鸟类和哺乳动物在种数层面的差异研究仍然比较有效,但势必对研究结论产生一定影响.因此,在不同尺度层面上,对物种丰富度进行相关研究,探讨尺度变换对结果精度的影响值得后续深入研究.
猜你喜欢
学与玩(2022年9期)2022-10-31
落叶果树(2021年6期)2021-02-12
文苑(2020年12期)2020-04-13
小太阳画报(2019年1期)2019-06-11
小学科学(学生版)(2018年5期)2018-06-15
奇妙博物馆(2018年12期)2018-04-25
奇妙博物馆(2018年12期)2018-04-25
小学生必读(低年级版)(2017年5期)2017-08-12
体育科技(2016年2期)2016-02-28
西华师范大学学报(自然科学版)(2015年3期)2015-02-27
