
训练集对遥感图像超分辨率下自动目标识别影响的研究
2021-03-22 04:26王晟全
重庆理工大学学报(自然科学) 2021年2期
王 艳,李 昂,王晟全
(1.南京理工大学 a.紫金学院;b.电子工程与光电技术学院,南京 210023;2.南京邮电大学 通信学院,南京 210003)
遥感成像技术的迅猛发展催生了大量遥感图像的产生。遥感图像在国民经济建设的众多领域中有着特殊的优势,例如战场态势监控、城市交通以及矿物、陆地植被、惰性气体和人工材料的探测与识别等[1]。自动目标识别(ATR)是计算机自动完成目标捕捉并分类的过程[2-4]。该过程涉及图像滤波、图像增强、图像分割、图像变换、特征提取、特征选择、图像匹配等多个方向的专业知识[5-6]。本文以船舶为目标,在遥感图像中实现船舶的自动目标识别。遥感图像中的船舶属于小目标,对遥感图像进行小目标识别并非容易的事情,原因在于遥感图像的空间分辨率较低,针对普通图像的自动识别算法无法直接应用于遥感图像。因此在对船舶进行识别之前,需要完成图像超分辨率(SISR),即将低分辨率图像映射到高分辨率图像[7-9],该技术可以在不改变物理成像设备的限制下,获取更高分辨率的图像,在遥感图像处理方面得到了应用[10-12],可以提高遥感图像的空间分辨率、自动识别的准确率。下面分别介绍ATR和SISR的发展现状。
随着深度学习的巨大进展,基于卷积神经网络(convolution neural network,CNN)的自动目标识别算法取得巨大进步。相比于传统方法,目标识别性能得到巨大提升,特别是在复杂场景的自动目标识别方面。Wagner等[13]利用CNN提取数据特征,将得到的特征数据送入到可训练的SVM分类器中进行分类。Zeiler等[14]使用迁移学习解决了深度学习应用于SAR目标识别时数据不足的问题。Chen等[15]用卷积层替换CNN中的全连接层,降低了过拟合风险。Deng等[16]通过在损失函数中添加欧式距离限制(euclidean distance restriction),使类与类之间的特征更具有可分性。
SISR是低分辨率图像映射到高分辨率图像的过程,比任何缩放算法的保真度都高,如图1所示。SISR可以有效提高图像的空间分辨率,因此可以减少对更大、更昂贵的卫星摄像机的需求。SISR的核心是尝试将低分辨率图像映射到高分辨率图像,如图2所示。SISR分为3类:基于插值、基于模型和基于判别学习的方法,其中基于判别学习的方法最为主流[17]。基于判别学习的算法利用CNN对于大量的图像训练数据集进行训练,学习LR图像和HR图像之间的映射关系,从而能够对输LR图像进行有效超分辨重构。Michal等[18]测试了用于训练SR网络的下采样方法,使用DIV2K图像测试了SRResNet和FSRCNN,通过不同的下采样方法显示了不同的图像质量得分。Kim等[19]提出一个深度的超分辨网络模型VDSR(very deep super-resolution),采用了20个卷积层。Kim等通过实验验证了采用更深网络模型能够带来更好的重建效果,但也会对收敛速度产生很大影响。
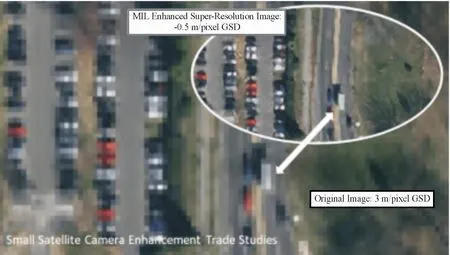
图1 SR提高空间分辨率的效果图

图2 SISR示意图
本文采用超分辨复原生成对抗网络(SRGAN),在包括测试船舶本体的多个训练集中进行训练,多个训练集包括农业、城市、杂乱场景、石油、港口和船舶本体,然后采用AlexNet网络进行分类检测,最后采用RetinaNet网络进行目标识别。本文主要研究了训练集对SISR、超分辨率下目标识别的影响,目前相关研究较少。实验表明,和不包含测试本体的训练集相比,包含测试本体的训练集,SISR后的图像更加真实,超分辨率下的目标识别准确率更高。
1 超分辨率下目标自动识别算法
1.1 SRGAN网络
SRGAN的目的在于将一个低分辨率的图片转化为一个高分辨率的图片[20]。SRGAN是基于GAN方法进行训练,包括一个生成器和一个判别器,判别器的主体使用VGG19,生成器是一连串的Residual block连接,同时在模型后部也加入了subpixel模块,借鉴了文献[21]的Subpixel Network思想,让图片在最后的网络层增加分辨率,提升分辨率的同时,减少计算资源的消耗。
将均方误差(MSE)的感知损失lSR表示为内容损失lSXR和对抗性损失成分lSGRen的加权和,如式(1)所示:


像素方式的MSE损失lSRMSE计算方法如式(2)所示:将VGG损函数失定义为重建图像GθG(ILR)x,y特征表示与参考图像IHR之间的欧氏距离,如式(3)所示:
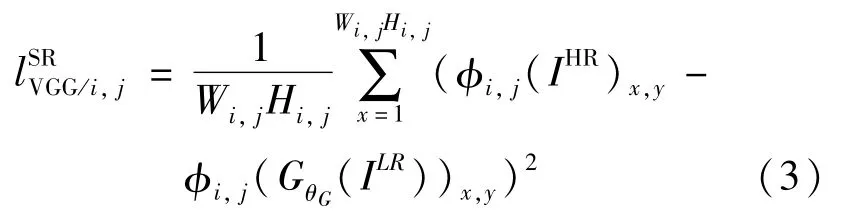
其中,φi,j表示从VGG-19网络的第j层卷积(激活后)的第i个最大池化层之前获取的特征图;Wi,j和Hi,j是VGG网络中对应特征图的维数。
生成损失lSRGEN是基于所有训练样本上鉴别器GθC(ISR)的概率定义,如式(4)所示:
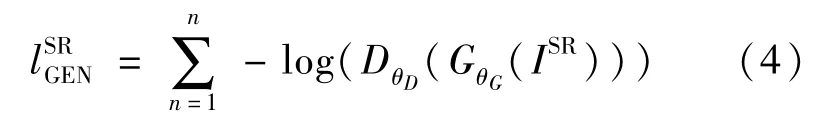
DθD(GθG(ILR))定义为重建图像GθG(ILR)是自然HR图像的概率。为了更好的梯度表现,使用-log DθD(GθG(ILR))最小化生成损耗函数,而不是log[1-DθD(GθG(ILR))]。
SRGAN结构如图3所示,其中每个卷积层指示了相应的内核大小(k)、特征图数量(n)和步幅(s)。
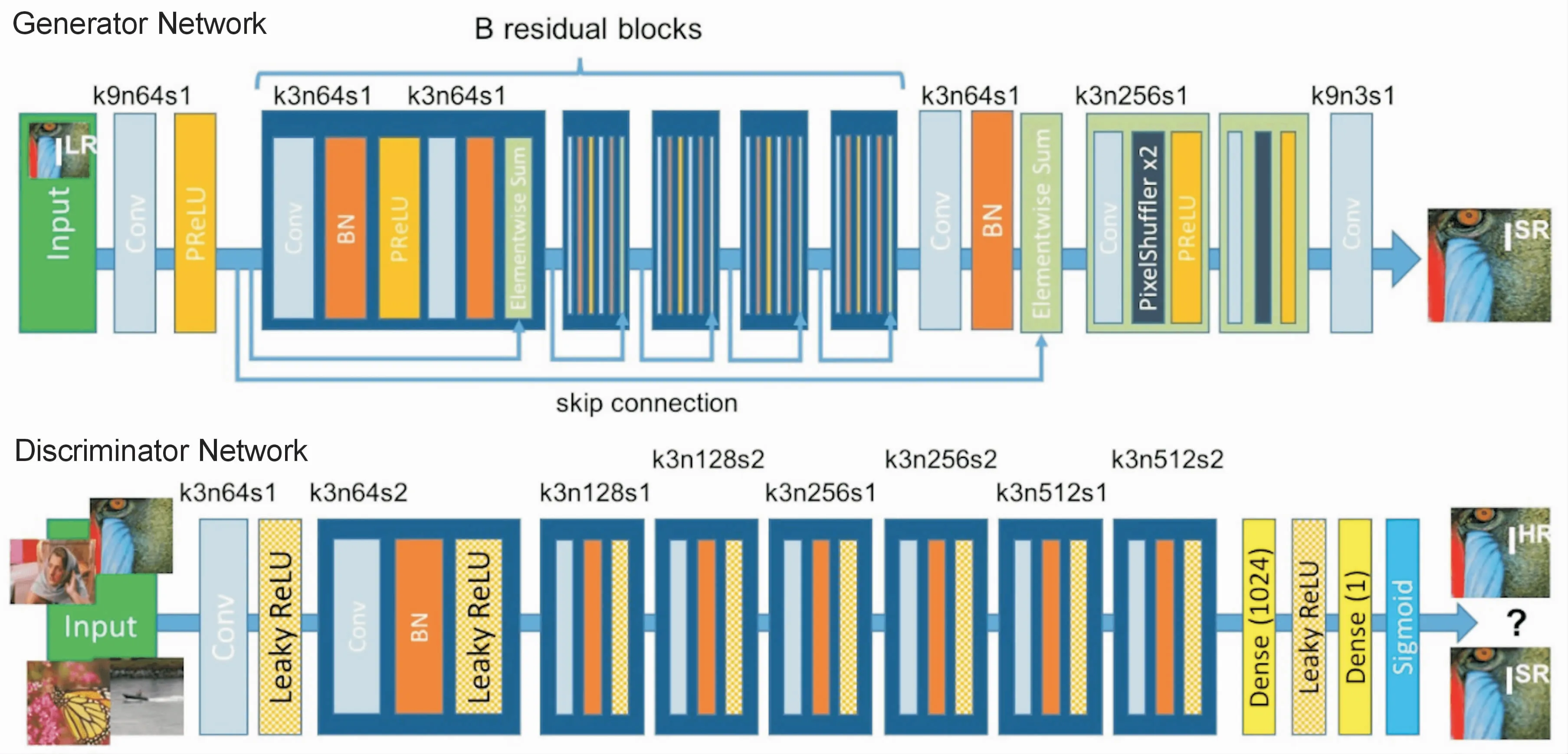
图3 生成器和鉴别器网络的体系结构示意图
1.2 分类网络
在后续的分类检测中,本文采用AlexNet[22]网络作为分类网络的基本框架,前5层为卷积层,然后是全连接层,最后一层是分类层Softmax。传统网络常用的激励函数Sigmoid和tanh函数被取代为修正线性单元ReLU,同时为了减轻过拟合问题,采用了dropout方法,可以有效提高正确率,整体框架如图4所示。
对于80 px和320 px的输入,使用深度均为64,内核大小为3×3的2D卷积层,并激活ReLU,然后再进行大小为2×2的2D最大池化层,直到获得80×80的特征空间。然后,我们改为使用深度为32的Conv2D,然后使用大小为2×2的Maxpool2D,以实现38×38的潜在空间。最后,应用速率为0.30的滤除层,把特征过滤出来,添加大小为30 mm的密集层、速率为0.30的退出层、输出为2类的Softmax,其中,损失是分类交叉熵,优化器是默认的Keras Adadelta。

图4 AlexNet整体框架示意图
1.3 目标识别网络
本文采用了文献[23]基于Focal Loss的RetinaNet作为识别网络。RetinaNet在识别领域有着重要的地位。Focal loss是一种改进了的交叉熵CE(cross-entropy)loss,但是它在原有的CE loss上乘了使得易检测目标对模型训练贡献削弱的指数式,从而成功地解决了在目标检测时,正负样本区域极不平衡、而目标检测loss易被大批量负样本影响的问题,改进后的bias:b=-αlog((1-π)/π),其中α可以控制bias的值,使之能够根据实际的情况,取得相应的值,使其预测图像目标的准确性上升。
2 实验
2.1 训练集
为了避免数据集中的相机伪影变化太多,训练图像需使用单个长焦距镜的照片。为此,采用了Planet公司0.8m Visual Skysat卫星采集的图像。SkySat卫星是美国Planet公司发展的高频成像对地观测小卫星星座,主要用于获取时序图像,并服务于高分辨率遥感大数据的应用。如图5所示,单个图像的可视化效果和RGB直方图,以及5种训练集(农业、城市、杂乱场景、石油和港口)中每种训练集的直方图平均值。
2.2 测试集
测试集采用来自Kaggle Shipsnet竞赛的图像,示例图像如图6所示。这些图像来自Planet的Planetscope卫星(3.0 m),其中包含加利福尼亚州的旧金山湾和圣佩德罗湾地区图像。与训练集的图像相似,这些图像也是Planet视觉分类中的场景,这意味着它们也经过了锐化、正射和颜色校正的RGB。但是,与训练集不同,测试集中的场景已被平铺为80 px×80 px的正方形。就数据集中的类别而言,只有全幅船被分类为船,所有其他图像均归类为“无船”。测试集包含4 000张图像,其中1 000张图像被分类为船。
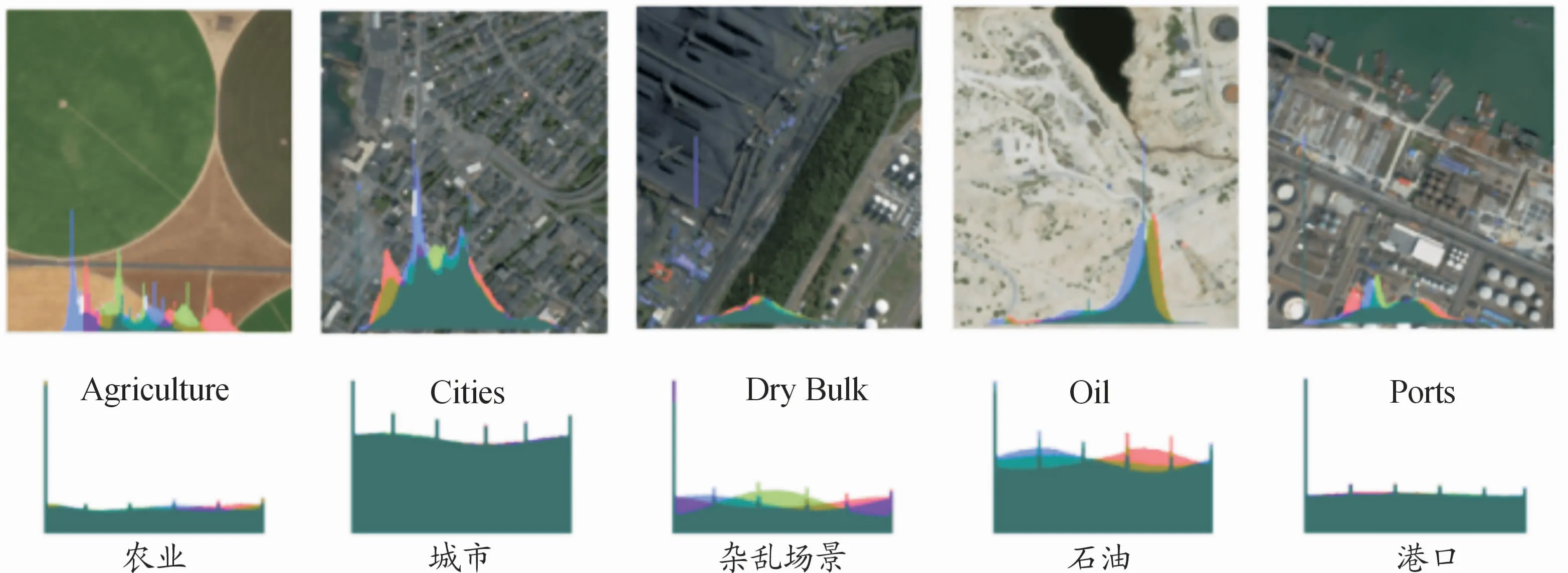
图5 土地利用类别的示例图像和RGB直方图

图6 来自Kaggle Shipsnet竞赛的图像
2.3 模型训练和SRGAN
在农业、城市、杂乱场景、石油、港口和船舶本体这6个测试集训练了6个SRGAN,每个SRGAN均训练了10 000次,每批次20个。目标检测和分类检测在Intel i7-7700HQ 2.8 GHz上运行,每组图片大约需要30 min。
使用所需分辨率的所有图像后,可以设置SRGAN网络,加载数据后,需要先采样以获得LR图像。再次使用双3次滤波器对图像进行下采样,以减少采样方法对结果的影响,通过GAN运行数据之前将-1和1之间的所有像素值标准化。
SRGAN在包括农业、城市、杂乱场景、石油、港口和船舶本体这6个训练集中进行训练。每个SRGAN运行的船舶图片如图7所示。对于船舶图像,由农业、港口训练的SRGAN产生的图像色彩偏暗,由城市、杂乱场景训练的SRGAN产生的图像色彩偏亮,由石油训练的SRGAN在船舶的船体产生了黑色的人工痕迹,由船舶本体训练的SRGAN产生的图像色彩最亮、效果最好。
在训练了SRGAN之后,判别出一些流行的卫星图像样本的缩减样本,如:Xview(0.3 m)、Pleides(0.5 m)、Quickbird(0.65 m)、Triplesat(0.8 m)和Ikonos(1 m)。不同种类的训练集SRGAN对测试集产生的影响如表1所示,船舶本体和其他训练集相比,PSNR和SSIM这2个指标均表现最好。这表明针对本体图像需要进行定制训练。原因在于超分辨复原的训练是无监督学习,结果具有随机性,但是也与本身的图像显著性特征有关。

图7 SRGAN运行的船舶图片
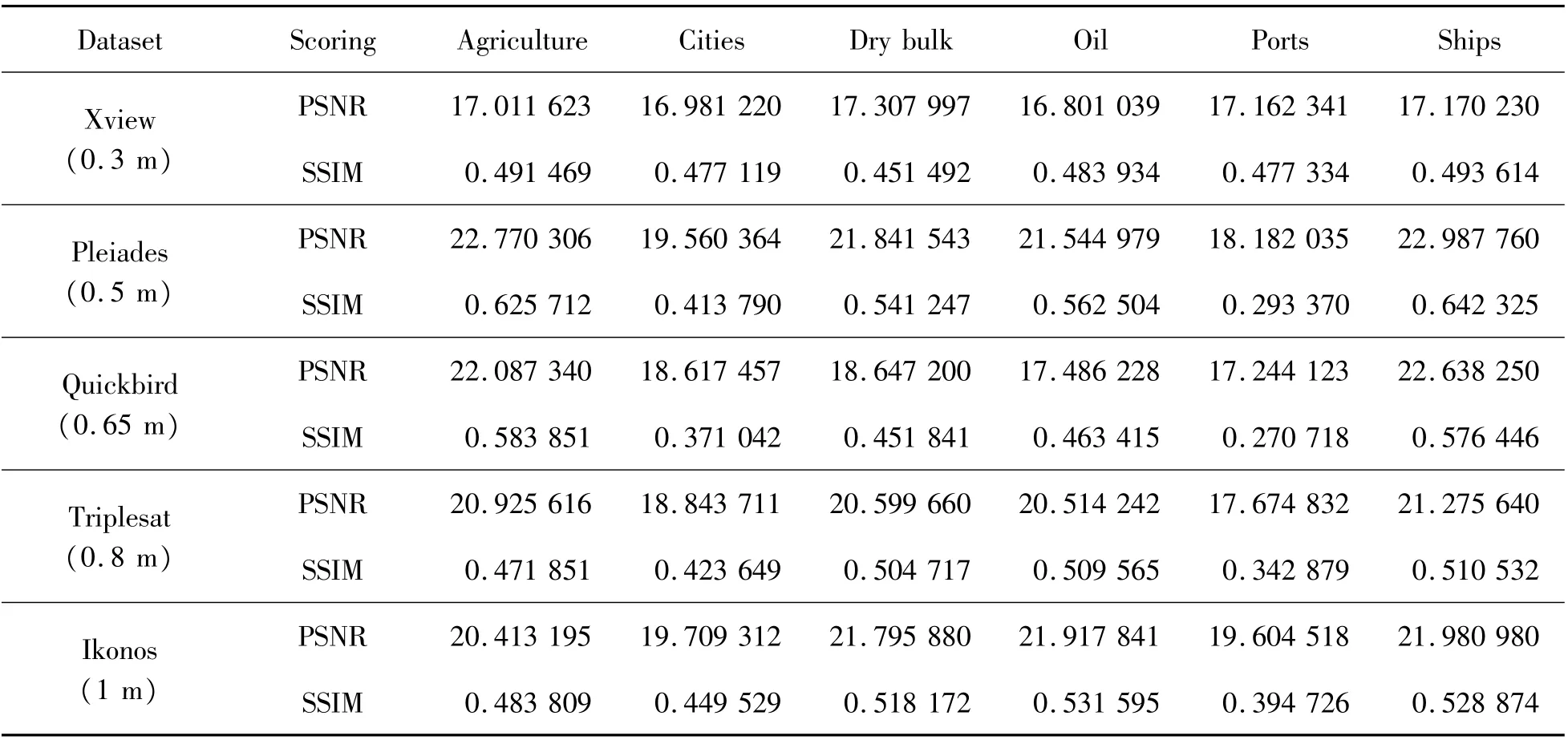
表1 SRGAN应用于不同图像的结果
2.4 目标识别
在目标识别过程中,采用了前文提到的Alex-Net网络和RetinaNet算法,图像的固定分辨率似乎并不能从增强中获益很多,并且显示出对基于尺寸的分辨率变化的敏感性。xView对比例敏感度的一个示例是在较高的分辨率下,同一张图像可以错误地检测出汽车的建筑物,而在较低的分辨率下,则可以将汽车误认为是游艇。总体而言,对于未更改的xView图像的基础模型,最佳验证mAP为300个历时(3 d)后为0.16,对应的训练mAP为0.30。不同训练集下的识别评价指标如表2所示,其中TP是实际为正例、预测为正例的比例,FP是实际为负例、预测为正例的比例,识别精确率Precision=TP/(TP+FP)。从表2可见,在不同的训练集情况下SRGAN中有明显的差异,包含测试船舶本体的训练集,目标识别的精确率最高,达到了98.79%,可以满足实际的识别应用需求。
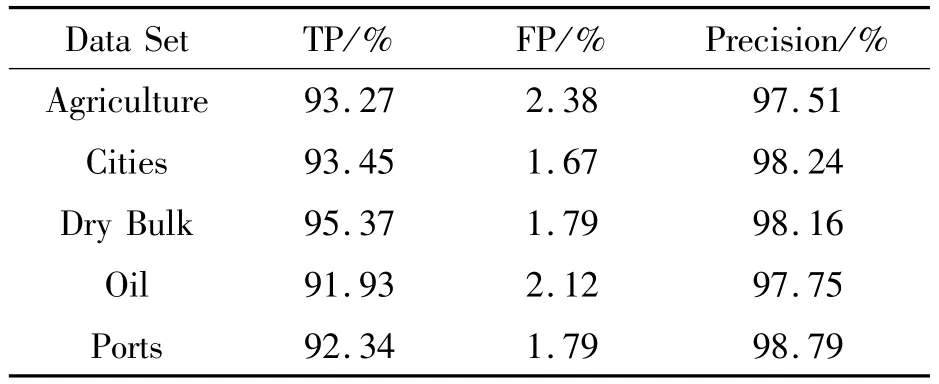
表2 不同训练集下的识别评价指标
2.5 附加实验
本文算法对飞机目标进行识别和准确性的测试效果图如图8所示,图中绿色框表示标签位置、蓝色表示测试结果、红色表示误检的目标,准确率比较理想。但是在不同特征尺度下的飞机还是不能特别正确的标识,当飞机分辨率较低时,有一定的误检率和漏检率。因此对遥感图像中的飞机进行识别之前,引入SISR算法是非常必要的,该算法可以将低分辨率图像映射到高分辨率图像。SRGAN处理过的google遥感图像训练损失率Loss比较理想,如图9所示。

图8 对遥感机场的检测实验
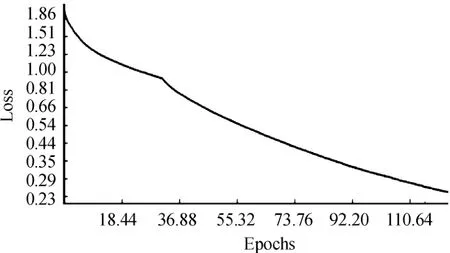
图9 SRGAN处理过的google遥感图像训练损失率Loss
3 结论
当训练不同的图像集时,在SRGAN网络之间可以看到明显的差异。这突显了定制训练集需求的重要性。在农业、城市、杂乱场景、石油、港口和船舶本体这6类训练集中进行SRGAN训练,然后采用AlexNet网络进行分类检测;最后采用RetinaNet网络进行目标识别。实验表明:在同一个船舶测试集中,受过测试本体图像训练的识别效果最好,精确率最高。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
哈哈画报(2021年10期)2021-02-28
电子制作(2019年13期)2020-01-14
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
制造业自动化(2017年2期)2017-03-20
成都信息工程大学学报(2017年6期)2017-03-16
