
卷积神经网络RLeNet加速器设计
2021-03-22 02:56康磊李慧郑豪威李鑫
电脑知识与技术 2021年6期
康磊 李慧 郑豪威 李鑫

摘要:针对卷积神经网络(CNN)对运算的需求,现场可编程逻辑门阵列(FPGA)可以充分挖掘CNN内部并行计算的特性,提高运算速度。因此,本文基于FPGA开发平台,从模型优化、参数优化,硬件加速以及手写体数字识别四个方面对CNN的FPGA加速及应用进行研究。提出一种数字识别网络RLeNet,并对网络进行参数优化,卷积运算加速采用脉冲阵列与加法树结合的硬件结构实现,同时使用并行技术和流水线技术优化加速,并使用microblaze IP通过中断控制CNN加速器IP接收串口发送的图片数据进行预测,输出结果。最后在Xilinx Nexys 4 DDR:Artix-7开发板上实现了MNIST数据集手写体数字识别预测过程,当系统时钟为200MHz时,预测一张图片的时间为36.47us。
关键词:CNN;FPGA;RLeNet;MNIST;手写体数字识别
中图分类号:TP389.1 文献标识码: A
文章编号:1009-3044(2021)06-0016-04
Abstract: In response to the requirement of convolutional neural network (CNN) for multiplication and accu-mulation operations, Field Programmable Logic Gate Array (FPGA) can fully tap the characteristics of parallel computing within CNN and increase the speed of operation. Therefore, based on the FPGA development platform, this article studies the FPGA acceleration and application of CNN from four aspects: model optimization, parameter optimization, hardware acceleration, and handwritten digit recognition. Propose a digital recognition network RLeNet, and optimize the parameters of the network. Convolution operation acceleration use a hardware structure combining pulse array and addition tree,parallel technology,pipeline technology, and microblaze IP is used to control the CNN accelerator through interrupts. The IP receives the picture data sent by the serial port for prediction and outputs the result. Finally, on the Xilinx Nexys 4 DDR: Artix-7 development board, the MNIST data set handwritten digit recognition and prediction process is implemented. When the system clock is 200MHz, the time to predict a picture is 36.47us.
Key words: CNN; FPGA; RLeNet; MNIST; handwritten digit recognition
1 引言
CNN作为一种典型的深度学习神经网络结构,受到自然视觉认知机制启发而来[1],在视频处理、人脸识别、语音识别和自然语言处理等很多方面都表现得非常出色[2-3]。但CNN需要大量的计算,在这样的背景下,FPGA 似乎是一种非常理想的選择,同GPU相比,FPGA 不仅拥有数据并行的特点,还拥有流水线并行的特点[4]。目前很多研究者对FPGA加速进行了研究,例如Yu-Hsin Chen提出的Eyeriss高效可配置卷积神经网络[5],中科院Temam教授和陈教授合作的机器学习加速器DianNao[6],以及google的TPU[7]等。本文在已有加速器的基础上,进行了数据优化、加入流水线技术实现卷积神经网络的加速,并使用开发板自带microblaze通过中断控制CNN加速IP输出预测结果。
2 系统总体介绍
2.1 RLeNet模型结构
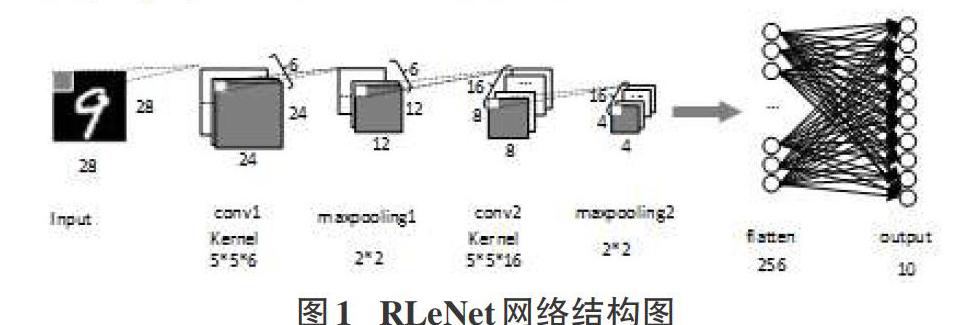
RLeNet模型是在LeNet-5[8]模型的基础上进行改进得到的,LeNet-5模型共8层,包括卷积层1(C1),池化层1(P1),卷积层2(C2),池化层2(P2),平压层(F1),全连接层1(D1),全连接层2(D2),输出层(Output)。本文对模型进行如下改进:将LeNet-5的D1层,D2层删除,只保留Output输出层,改进后的模型命名为RLeNet(Reduced LeNet-5),改进后的模型共有6层,包括卷积层1(C1),池化层1(P1),卷积层2(C2),池化层2(P2),平压层(F1),输出层(Output)。RLeNet的模型结构如图1所示。
表1为LeNet-5、RLeNet模型各层参数量对比。其中,LeNet-5的D1层、D2层共有41004个float32数据,约占总数据44426个float32(177.8KB)的92.3%。改进后的模型RLeNet共有5142个float32数据(20.6KB),模型参数数据量由原来的177.8KB降低到20.6KB。模型使用Keras框架 [9],模型训练完成后,准确率为98.5%,和LeNet-5的精确度98.7%相比,模型精确度几乎没有降低,但是模型参数数据量减少为原来的11.6%。
2.2 系统硬件结构
CNN加速器IP的硬件结构如图2所示。整个系统由CPU,中断,CNN加速器IP和UART串口模块组成。系统工作流程为:CPU通过按键中断接收CNN加速器IP使信号,当CPU接收到该使能信号后,等待串口发送的图片数据,然后将接收到的图片数据送入Block_ram,CNN加速器IP从Block_ram中读取图片,进行卷积运算。运算完成后,将运算结果返回给CPU,CPU将结果通过LED灯显示。其中,CNN加速器IP完成图片的预测,它主要包括卷积模块,池化模块,全连接模块,输入输出模块。CNN加速器IP工作流程是:首先由控制器发出控制信号,从数据寄存器读取输入和权重数据分别放入移位寄存器和权重Buffer,将数据和权重分别从移位寄存器和权重Buffer读出,送入乘加模块进行卷积运算。卷积运算完成之后,将卷积结果送入池化层进行池化运算,池化运算的结果送入特征图Buffer,两次卷积池化后,将数据进行平压,最后进行全连接运算,输出图片的预测结果。
3 数据输入
3.1 数据类型转换
相比于浮点运算,FPGA在做定点运算会消耗更少的资源,同时有更高的性能[10]。因此,本文将RLeNet模型参数将float32的模型参数左移13位并保存为int16类型参数,存入.coe格式文件中。输入数据为28*28的灰度图片,将输入数据转为uint8并保存为.txt格式文件。
3.2 串口数据输入
数据输入分为两部分,图片数据输入和权重数据输入。权重数据输入直接存入片上的block_ram中,图片数据通过uart_ctrl模块控制串口将上位机发送的数据存储到片上的block_ram中。图片数据发送主要包括uart和uart_ctrl以及数据存储三个模块。图片数据发送模块结构如图3所示:
3.3 数据处理
图片数据通过串口发送到block_ram中后,CNN IP将数据从block_ram中读入shift_ram,将串行输入转为并行输出,获取卷积运算的输入滑窗。
卷积运算的输入滑窗大小和卷积核大小相同,滑动顺序是:从图像左上角开始,从左到右每次滑动一个单元,在滑窗到达输入的最右端时,滑窗从上到下滑动一个单元,再次从最左端开始,每次向右滑动一个单元,最后滑动窗后到达图像右下角结束[11]。图4为本文卷积运算的输入,其中灰色部分是第一个5*5输入滑窗。黑色箭头表示滑窗滑动顺序。
为了硬件实现卷积运算的滑动窗口,本文使用shift_ram生成卷积滑窗像素矩阵。将存放图片数据的block_ram和4个28*9bit的Shift_ram (Shift_ram1、Shift_ram2、Shift_ram3、Shift_ram4)以图5方式连接。从block_ram中读图片数据进入Shift_ram,装满后,输出Out_0,Out_1,Out_2,Out_3,Out_4的值为1、29、57、85、113和图5中灰色卷积滑窗的第一列数据相同(粗黑框圈出),然后将这五个数据存储到5*5寄存器中的最右边一列。
下个CLK,Shift_ram4移除数据1,数据逐个移动后,得到图6中的Out1_0,Out1_1,Out1_2,Out1_3,Out1_4的值为2、30、58、86、114和图5中灰色卷积滑窗的第二列数据相同(虚线框圈出)。将上一个CLK获取的存在5*5寄存器中的五个输出左移,再将当前CLK五个输出存储到5*5寄存器中的最右边一列。五个时钟周期后,得到5*5的卷积输入窗口。之后每个CLK,移除5*5寄存器最左边一列数据,获得下一个卷积输入滑窗。
这样获取输入滑窗会产生无用的滑窗,在移除数据为25至30时,五个ClK内读取的分别是序号为26,27,28,29,30为首地址的列,但在实际卷积过程中,滑窗右端到达序号为28的列时,滑窗会向下移动,直接读取以29,30,31,32,33为首的列。在卷积完成后,需要将这些无用数据删除。
4 卷积模块实现
4.1 单个乘单元(Mul)硬件实现
卷积运算的单个乘法模块Mul如图7所示,将输入数据Input_x和权重Weight进行乘运算,运算结果Output_y保存在寄存器中,同时,输入数据Intput_x向下传输。
4.2 卷积运算(Conv)硬件实现
本文卷积运算模块如图8所示,首先将Weight数据放入Mul单元,然后将5*5的输入数据Input_x送入25个并行Mul单元,下一个CLK,将运算结果送入加法树,一个CLK后输出加法器运算结果。加法树共分为五级,第1级共有13个加法器,将25个乘法器结果和一个bias分别送入13个加法器。第2级将第1级计算结果送入6个加法器(余下1个后面算),以此类推,第5级将第4级结果送入加法器,得到最后的结果。
4.3 乘加模块并行运算设计
本文乘加模块并行运算设计是同一个输入滑窗和多个卷积核进行并行计算,输出多个卷积运算结果。本文卷积层2将12*12输入和16个卷积核同时进行并行运算,输出运算结果,卷积模块并行设计硬件结构如图9所示。
5 池化模块设计
5.1 池化模块输入
卷积运算完成后,将其运算結果保存到存储器中。由于卷积运算的卷积核有多个channel,需要将卷积运算多个channel的结果进行累加求和,作为池化模块的输入。
5.2 池化运算硬件实现
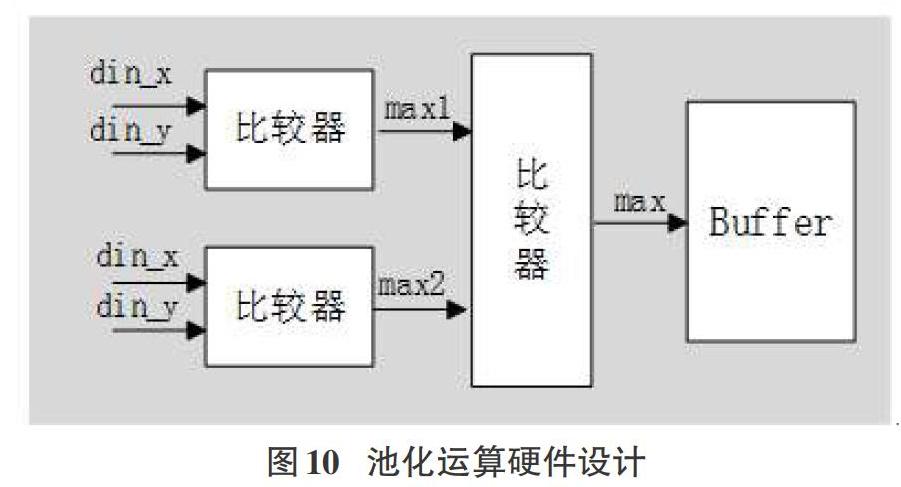
在得到池化运算输入后,进行池化运算。本文采用步长为2的最大池化。在2*2的滑窗内获取最大值。首先,通过地址获取池化窗口的输入,以池化1为例,卷积运算可以获得24*28的卷积结果并存储在寄存器中。那么第一次池化运算的输入的窗口为地址0,地址1(0+1),地址28(0+28),地址29(0+29)中的数据。第二次卷积运算输入滑窗数据为存储器中数据地址2,地址3(2+1),地址30(2+28),地址31(2+29)中的数据。另外,由于卷积运算输出为24*28,实际卷积层1的输出应为24*24,在池化运算时,无用数据不需要进行池化运算,在输入行地址大于24时,行地址等于0,列地址加56(向下移两列)。
在获取输入滑窗后,通过三次两两比较得到2*2滑窗内的最大值。如图10所示,首先比较din_x和din_y,得到max1和max2,之后比较max1和max2大小,输出较大数max。之后,滑窗向右移动两个单元,获取下个滑窗中的最大值。
池化运算并行接收多个卷积运算的结果,将结果累加,之后并行进行池化运算。
6 全连接模块设计
全连接模块的实现采用乘加运算,全连接模块输入为平压层的输出,输出为10个数字的预测结果。全连接模块的运算是输入和权重进行乘累加运算,获取一个数字预测结果的输出,循环十次之后,输出十个手写体数字的预测结果。硬件设计将输入数据和权重数据放入乘法器,获取乘运算结果,然后和之前的结果进行累加,获取数字预测结果。
7 实验结果
本设计是在Vivado ISE下使用Verilog HDL进行开发,使用Xilinx公司的Nexys 4 DDR : Artix-7开发板进行测试,主频为0.2GHz。CPU环境为CORE i7 10th四核处理器,主频为3.9GHz。 GPU型号为Tesla P 100,主频为1.4GHz。本文采用MNIST数据集手写体数字为输入数据,数据为28*28的单通道灰度图片。
本文将浮点输入和权重改为9位定点后,模型用1000张图片进行测试,检验模型准确度,最终测试结果,共有5张数据预测不正确,准确率达到99.5%。在200MHz的CLK下,一张图片在卷积层1做浮点运算的时间为9.1us做定点运算的时间为1.58us,速度提高了约6倍。
表2为不同平台下,CNN运行的时间及能耗对比[12]。CPU运算时间是在python环境下执行模型预测函数,得到预测12000张图片的时间,再算出预测一张图片时间,同理得GPU平台图片预测时间。FPGA平台上的运算时间是采用CNN加速器IP运算得到的预测时间,由表2可知,在CPU平台上,卷积网络运行时间约为在FPGA平台运行时间的2倍。而在GPU平台上,卷积网络的功耗比在FPGA平台多4倍。
CNN IP加速后,片上寄存器使用了20974个,LUT as logic使用了53123个,LUT as memory使用了2742个,block_ram使用了48.5个。系统资源消耗较高。
8 结语
研究了手写体数字识别的CNN的FPGA实现,提出了一种基于数据优化及多级并行流水结构的CNN加速器,并将其作为外设,将数据。通过资源复用、并行计算和流水线技术,来对卷积运算进行加速。最后实验结果表明,系统的运算速度以及资源利用率得到提高,系统预测一张图片约为36us,其计算速度是CPU的2倍,而系统的能耗是GPU的1/4。但系统的LUTs资源占用较多,可以通过其他优化方式降低系统资源占用率。
参考文献:
[1] Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, L., Wang, G. and Cai, J., [J].2015. Re-cent advances in convolutional neural networks. arXiv preprint arXiv:1512.07108.
[2] Chen Y H , Emer J , Sze V . Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks[C]// International Symposium on Computer Architecture (ISCA). IEEE Computer Society, 2016..
[3] Chen T , Du Z , Sun N , et al. DianNao: a small-footprint high-throughput accelerator for ubiquitous ma-chine-learning[C]// International Conference on Architectural Support for Programming Languages & Operating Systems. ACM, 2014.
[4] MONREALE A, PINELLI F, TRASARTI R, et al. WhereN-ext: a location predictor on trajectory pattern min-ing[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, Jun 28-Jul 1, 2009. New York: ACM, 2009: 637-646.
[5] Kumar S , Bitorff V , Chen D , et al. Scale MLPerf-0.6 models on Google TPU-v3 Pods[J]. 2019.
[6] 蹇强,张培勇,王雪洁.一种可配置的CNN协加速器的FPGA实现方法[J].电子学报,2019,47(7):1525-1531.
[7] Han X , Zhou D , Wang S , et al. CNN-MERP: An FPGA-based memory-efficient reconfigurable processor for forward and backward propagation of convolutional neural networks[C]// 2016 IEEE 34th International Conference on Computer Design (ICCD). IEEE, 2016.
[8] Zhang C, Li P, Sun G, et al. Optimizing fpga-based accelerator design for deep convolutional neural networks[C] Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, 2015: 161-170.
[9] Cavigelli L , Magno M , Benini L . Accelerating real-time embedded scene labeling with convolutional networks[J]. 2015:1-6.
[10] Chen Y H , Krishna T , Emer J S , et al. Eyeriss: An Ener-gy-Efficient Reconfigurable Accelerator for Deep Convolu-tional Neural Networks[C]// Solid-state Circuits Conference. IEEE, 2016.
[11] Qiu J , Wang J , Yao S , et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network[C]// Pro-ceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, 2016.2001 March.
[12] 傅思揚,陈华,郁发新.基于RISC-V的卷积神经网络处理器设计与实现[J].微电子学与计算机,2020,37(4):49-54.
【通联编辑:梁书】
