
基于最优邻居引导萤火虫移动的粒子滤波算法
2021-03-23 23:11卢敏陈菘张敏
江西理工大学学报 2021年1期
卢敏 , 陈菘 , 张敏 ,2
(1. 江西理工大学理学院,江西 赣州 341000;2. 嘉兴学院数理与信息工程学院,浙江 嘉兴 314001)
0 引 言
二战时期,Von Neumann 提出了蒙特卡罗方法(Monte Carlo Method),该方法的主要思想是从概率分布中随机抽样并用这些抽样值来近似表示原分布[1]。 贝叶斯估计结合先验概率函数与观测似然函数,利用贝叶斯公式来求解估计问题[2]。粒子滤波算法使用递归贝叶斯估计和蒙特卡罗方法实现了对估计问题的求解,将系统状态的处理转化成序列的估计问题[3]。 由于粒子滤波算法可以处理任意状态空间描述的模型[4],因此获得了广泛的应用。除用于估计问题外,粒子滤波算法在视觉跟踪、航空导航、通信与信号处理、手势识别、故障检查等[5-8]领域也发挥着重要作用。
粒子滤波算法需要从后验分布中抽样,并用这些抽样值求解后验分布的期望、 方差等数字特征。但通常情况是不知道分布函数的具体解析式,无法直接采样,为此引入了提议分布。 提议分布形式已知且与分布函数近似,对提议分布的采样间接实现了对后验分布的采样。最优提议分布融入了当前观测数据,但实际采样中无法实现,因此用状态转移函数作为次优提议分布。次优提议分布导致了粒子退化问题(Particles Degeneracy)[9],当似然函数位于先验概率分布尾部时,退化问题更为严重。 粒子退化现象产生了大量低权重粒子,低权重粒子无助于后验分布的估计,浪费了大量的计算时间。 退化现象的存在使得少量粒子无法保证估计的精度,需要采集更多粒子实现对状态的估计。 Douceta 通过数学方法证明了若干轮迭代后粒子退化现象发生的必然性[10],在自举滤波器[11](Bootstrap Filter)提出以后,退化问题得以解决。 自举滤波器根据权值大小复制粒子,用大权值粒子替换小权值粒子。 这种机制导致粒子种类锐减,出现了粒子多样性缺失的新问题。
解决粒子多样性缺失的方法有改进重采样算法或改进提议分布[12]。 蔡登禹等用遗传算法替代了粒子滤波的重采样过程,结合变异、交叉等步骤,提高了滤波的精度[13]。 但是这种方法参数较多,参数的设置有很强的随机性。张威虎等将粒子群优化算法引入到粒子滤波过程中,通过蝴蝶个体香味浓度的高低和吸引半径引导种群向最优个体附近移动[14],该算法运行时间较短,跟踪误差较小,但存在个体被多次吸引和移动的问题。本文将萤火虫算法引入到粒子滤波中,把粒子比作萤火虫个体,粒子的权值比作萤火虫发光的亮度。 为避免文献[14]粒子在最优个体值附近震荡的问题,本文引入递减函数[15],该函数使吸引度随着迭代次数的增加而不断减小。由于萤火虫算法中每个萤火虫都要与其他萤火虫个体进行对比,亮度低于其他个体时均需要进行移动寻优操作,当种群数目过多时影响算法的运行效率与收敛速度。 为减少算法的复杂度,本文利用最优邻居引导萤火虫个体的移动。设置半径参数将萤火虫种群进行划分,个体向所属种群中亮度最高的萤火虫移动完成位置更新,不同种群的个体再向最优种群的最亮个体移动并分布在最亮个体周围。此操作加快了迭代寻优的速度并保证了萤火虫种群的多样性,种群的多样性提高了滤波的准确度。 最后实验验证本文改进的算法在跟踪误差、跟踪精度方面优于粒子滤波算法。
1 粒子滤波模型
1.1 模型分析
非线性系统的状态模型可以用式(1)和式(2)表示:
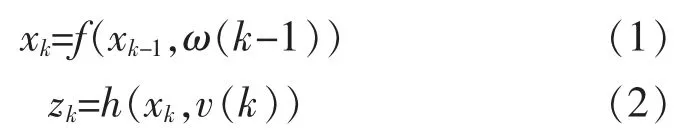
其中,xk与zk分别表示k 时刻的状态量与观测量;ω 与v 分别表示过程噪声和测量噪声;f 与h 分别表示状态转移函数与测量函数。 图1 是式(1)和式(2)的状态空间模型。
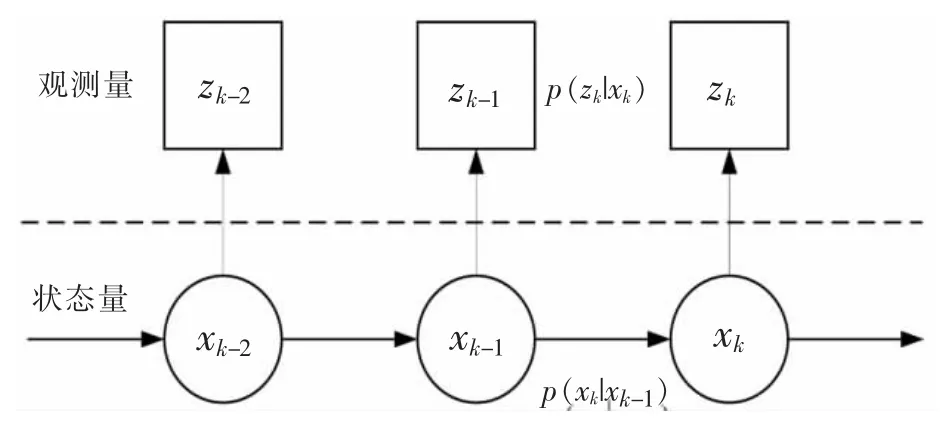
图1 状态空间模型
由图1 可以看出: ①状态 xk与状态xk-1相关,与 xk-2,xk-3,…等状态不相关。 ②zk与状态 xk有关,与 zk-1,zk-2,…不相关,与 xk-1,xk-2,…也不相关。
在 k-1 时刻,p(x0∶k-1|z1∶k-1)已知,根据式(1),并利用 Chapman-Kolmogorov 方程,由 p(xk-1|z1∶k-1)得到 p(xk|z1∶k-1):
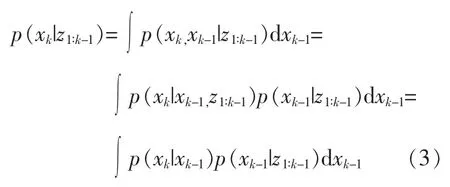
当最新时刻观测值到来时,利用最新时刻的观测值 zk修正 p(xk|z1∶k-1)。
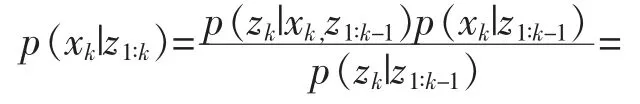
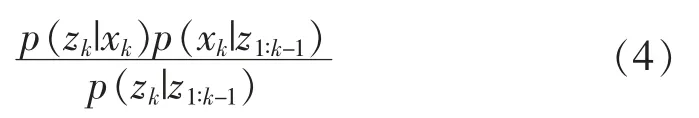
其中,p(zk|z1∶k-1)为归一化常数。
引入提议分布后,权重更新公式为:
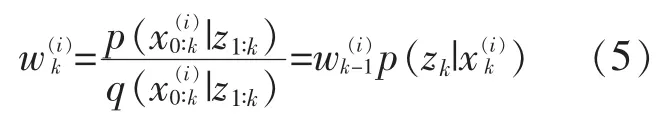
通过从提议分布中采样获得样本, 并根据式(5)计算样本权重即实现了粒子滤波算法。图2 为粒子滤波过程的示意图。
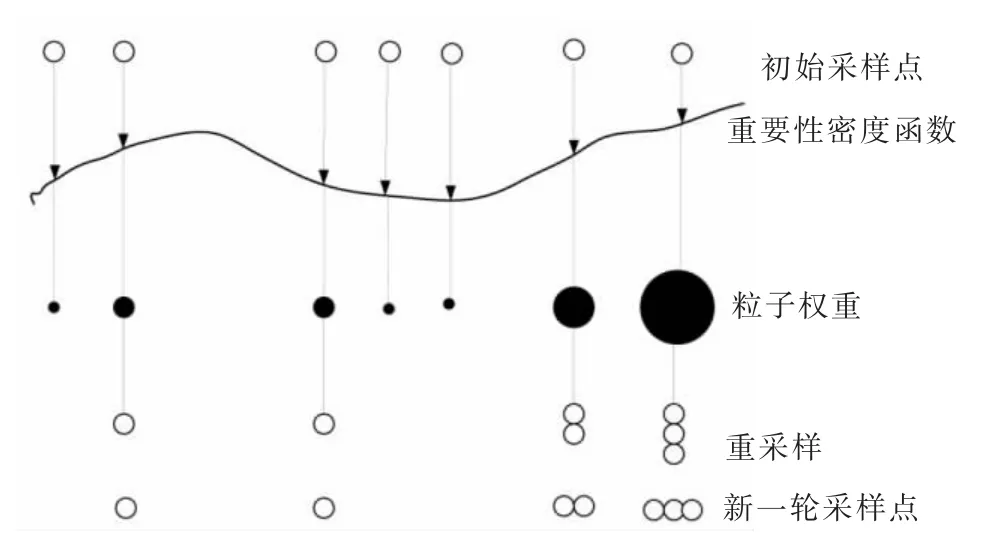
图2 粒子滤波过程
1.2 重采样算法
重采样基于逆变换的思想,粒子归一化权值与总权值的比例关系决定了粒子被复制的概率。目前常采用的重采样算法有多项式重采样、残差重采样和系统重采样[16]。 用式(6)衡量有效粒子数退化的程度:
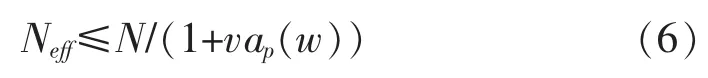
其中,vap(w)是所有粒子权重的方差。
式(6)计算复杂,通常采用另一种形式来近似表示:
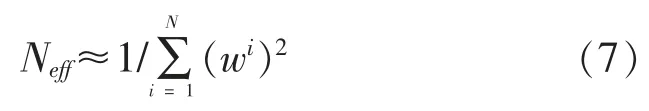
其中,wi是粒子的归一化权值。 完全退化情况下权重值完全集中在某个粒子上,此时Neff值为1。最佳情况是所有粒子权重值相等 (重采样后所有粒子权重值相等,为 1/N),此时 Neff=N。 使用式(7)来衡量粒子退化的程度,当有效粒子数小于设定的阈值时需要进行重采样。 重采样过程如下:首先产生一个[0,1]之间均匀分布的随机数ui,然后计算粒子的累计权值概率之和时,则粒子xm被选中复制一次,重复N 次获得所需的样本数。
2 群智能优化理论
2.1 萤火虫算法
群智能算法 (Swarm Intelligence Algorithm)属于自然启发式算法,可以更好地解决大规模复杂非线性问题。 该算法主要模拟了昆虫、鸟群等动物的聚集行为,群体中的成员通过协同操作不断优化搜寻的方向从而达到求最优解的目的。目前常见的群智能算法有蚁群算法、蛙跳算法和萤火虫算法等。
萤火虫算法有2 个版本,firefly 算法和glowworm算法[17]。 效果类似、功能相近,本文采用 firefly 算法。 在firefly 算法中,萤火虫依靠自身所发光的亮度与对其他萤火虫个体的吸引度大小完成位置更新。 亮度与吸引度均与距离有关, 随着距离的增加亮度与吸引度均减小。 位置更新的原则是亮度低的萤火虫会被亮度高的萤火虫吸引,亮度公式定义如下:

其中,L0表示个体自身的亮度;γ∈[0.1,2]为光强系数,γ;rij表示距离,公式如下:
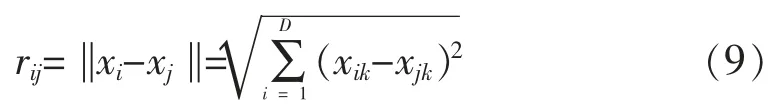
萤火虫之间的吸引度βij定义为:

其中,β0为萤火虫的最大吸引度,通常取[0.8,1]。
位置更新公式定义如下:
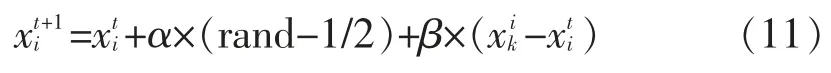
其中,rand 是介于 0 到 1 间的随机数;α 是步长因子;β 是式(10)中计算得到的相对吸引度。
2.2 改进算法
由式(8)和式(10)可知,萤火虫的亮度和吸引度大小与距离负相关。迭代前期萤火虫个体间距离远,吸引度小,导致位置更新步骤中移动的距离短,需要进行多次迭代才能移动到最优个体附近。迭代后期萤火虫个体间距离近,相互间的吸引度增大导致每次移动的距离大,容易出现在最优值附近反复震荡的问题。 另一方面,粒子滤波过程中次优提议分布 p(xk|xk-1)忽略了最新时刻的观测值数据,导致了粒子退化现象的产生。因此本文主要从以下三个方面对萤火虫算法进行改进:
1) 在萤火虫相对亮度的计算公式中引入最新的观测值数据。 修改后的亮度计算公式如下:
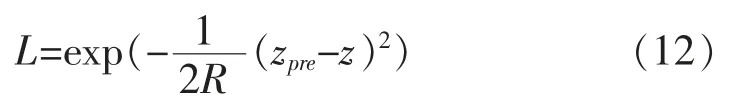
其中,R 表示测量噪声方差;zpre表示由式(1)得到的预测值;z 表示由式(2)得到的观测值。 L 值越大说明该萤火虫个体亮度高,位置优,对应的粒子权值大,越接近真实的位置。
2)在萤火虫吸引公式中引入递减函数δ,该函数控制吸引度的更新。 迭代初期δ 值应比较大,加强算法的全局搜索能力,有利于低亮度的萤火虫个体迅速收敛到高亮度个体附近。迭代后期δ 值应比较小,提高算法的局部搜索能力,避免低亮度萤火虫个体在高亮度萤火虫个体附近反复震荡,无法收敛。 基于上述思路,δ 函数设置如下所示:

其中,k 为迭代次数, 一般设置为30 到100 之间,改进后的吸引度公式如式(14)所示:
3)当萤火虫种群规模N 很大时,个体在迭代寻优的过程中需要与其他萤火虫个体两两比较然后进行移动。这个比较过程增加了运算的复杂度,为此本文使用最优邻居引导萤火虫个体的移动,有效减少了移动的次数。 用图3 中的圆形表示每个萤火虫个体,空心圆形代表比中心萤火虫亮度低的萤火虫个体,实心圆形代表比中心萤火虫亮度高的萤火虫个体,黑色实心圆形是亮度最高的萤火虫个体。
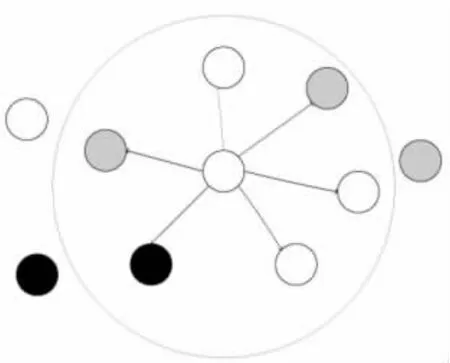
图3 最优邻居吸引模型
首先需要确定中心萤火虫的半径,计算过程如下:

式(15)通过计算中心萤火虫与其余萤火虫距离的平均值得到萤火虫i 的半径,然后计算所有萤火虫个体 j(j≠i)与萤火虫 i 的距离 dij。 如果 dij≤rand×diave,那么 j 确定为中心萤火虫 i 的邻居,不满足式 (15), 则该萤火虫个体不是中心萤火虫的邻居。 以下分两种情况讨论:
情况1:萤火虫i 不存在邻居时,即中心萤火虫为远离群体的独立个体,此时i 直接向全局最优处的萤火虫个体进行移动。 公式如下:
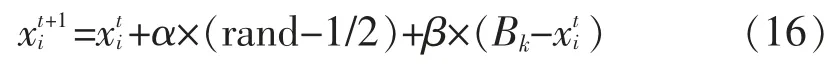
式(16)中: β 为吸引度大小,可由式(14)计算得到;Bk为全局最优萤火虫个体的位置。
情况2:萤火虫i 存在邻居时,由式(12)分别确定萤火虫i 和其邻居萤火虫的亮度,并找出亮度最优的个体。 若萤火虫i 比所有邻居萤火虫亮度都高,说明该萤火虫个体权重大,此轮过程不进行移动。 若邻居萤火虫存在最亮个体,则萤火虫i 依据式(17)向最优邻居进行移动:
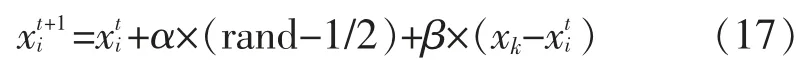
式(17)中:xk为邻居中最亮萤火虫个体的位置。
综上,本文改进后的粒子滤波算法流程如下:

3 算法仿真
3.1 非线性方程模型及参数设置
实验环境如下:硬件配置为Intel i7 处理器,8 GB内存,软件配置为Matlab R2016b。
本实验相关参数设置如下:粒子数目为60,跟踪时长T 为50,步长因子α 为常数,本文取0.3。最大吸引度β0为0.9,迭代次数k 为50。 初始种群个体满足均值为0.1,方差为2 的高斯分布,量测噪声与过程噪声服从均值为0, 方差为1 的高斯分布。实验中所采用的非线性状态模型与量测模型来自文献[18],如式(18)和式(19)所示:
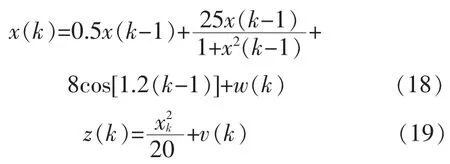
式(18)和式(19)是一个非线性非高斯方程,后验分布具有多个峰值。 x(k)与 z(k)分别表示 k 时刻的状态值与量测值,wk与vk是均值为0,方差分别为R=1 与Q=1 的高斯白噪声。
3.2 实验结果分析
图4、图5 分别是两种算法实验误差的对比与跟踪效果。
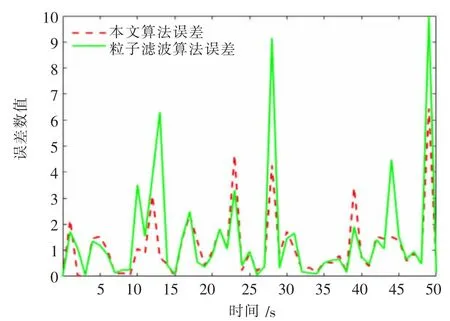
图4 误差分布
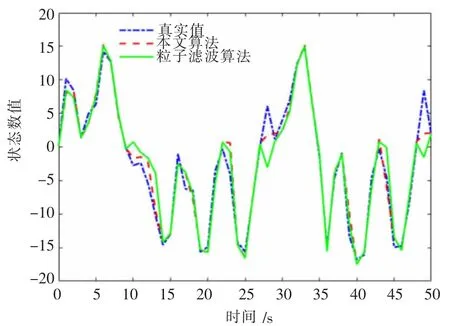
图5 状态估计
分析图4 可得:在粒子数目与跟踪时长均相同的条件下,相比于粒子滤波算法,本文改进算法误差分布的峰值得到了有效降低,大误差现象得到了一定程度的改善。这主要是改进算法在亮度公式的计算中利用了最新时刻观测值,相比于粒子滤波算法的次优提议分布误差得到了减小。从图5 可以看出,本文改进算法跟踪效果有了显著提高,大部分时刻都围绕在真实值附近,而粒子滤波算法估计值与真实值之间出现了较大的偏差。这主要是本文改进算法不对低权重粒子进行舍弃,低权重粒子不断向高权重粒子移动从而提高了跟踪的准确性。
为了定量评价本文改进算法的性能,采用均方根误差(Root Mean Square Error, RMSE)作为标准计算真实值与预测值的偏差。均方根误差RSME 公式如下所示:
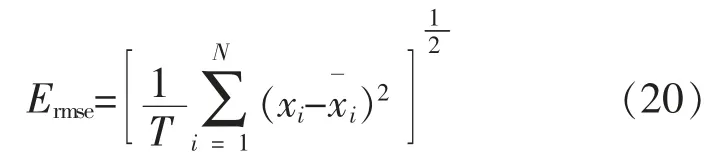
取过程噪声方差R 分别为1 和0.1,粒子数目分别为50 和100, 其余参数详见3.1 节参数设置。为了排除实验的随机性,减少偶然误差,表1 的数据是在进行100 次实验的基础上取平均值得到的。

表1 均方根误差数据
分析表1,当噪声方差相同时,随着采样粒子数目的增加,粒子滤波算法与本文改进算法的均方根误差均相应减小。 以R=0.1 为例,粒子滤波算法的误差随着采样数目的增加减小了6.7%, 本文改进算法的误差减小了9.2%。 增加采样粒子数目可以减小状态估计的误差,但与之伴随的是计算时间的增加,影响了算法的时效性。 在噪声与粒子数目均相同的条件下,本文改进算法误差小于粒子滤波算法误差,验证了改进算法的性能。分析原因,粒子滤波重采样过程对低权重粒子直接舍弃,高权重粒子的大量复制降低了有效粒子数目。而本文改进算法对低权重粒子进行移动寻优操作,使其分布在真实后验概率分布值附近,这个过程中没有舍弃低权重粒子,降低了估计状态与真实状态之间的误差。
3.3 二维目标跟踪模型
对于平面内做匀速运动的载体, 可以使用位置、速度信息来描述其运动状态。本文使用的状态变量为X(k)=[xp(k),xv(k),yp(k),yv(k)]T。 其中,xp(k)、 xv(k)为载体水平方向的位置与速度,yp(k)、yv(k)为载体竖直方向的位置与速度。载体的状态运动方程如式(21)所示:
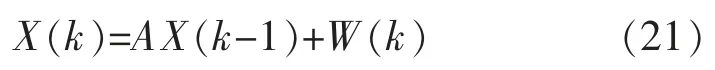
其中,A 为状态转移矩阵,W(k)为系统模型噪声。

其中,ax和 ay是服从的高斯白噪声。
观测站可以使用激光、无线电、红外等仪器对运动载体的状态X(k)进行探测,探测得到的距离用 Z(k)来表示,探测噪声用 V(k)来表示。 系统的观测方程如式(22)所示:
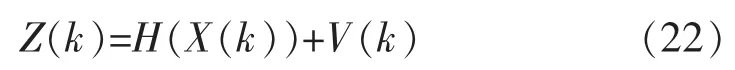
3.4 仿真结果分析
图6、图7 是两种算法的跟踪效果图与误差对比,图8 是时间消耗对比,图9 是方差为1 的高斯噪声。
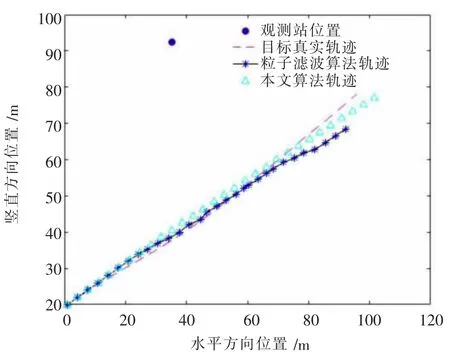
图6 跟踪效果对比
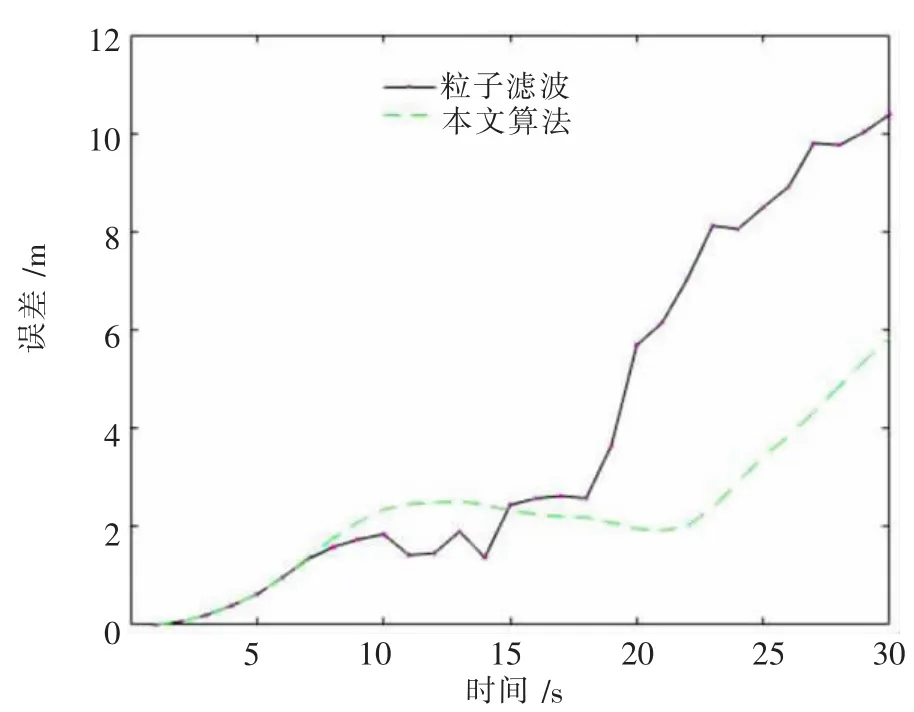
图7 误差对比
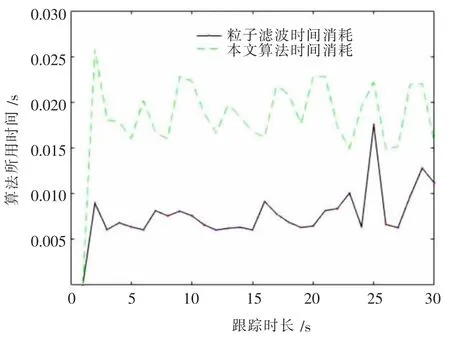
图8 时间对比

图9 方差为1 时的高斯噪声
图6、图7 是对二维平面内的运动载体跟踪了100 次所得出的。 对比来看,本文改进算法的跟踪效果优于粒子滤波算法。 随着跟踪时长的增加,粒子滤波算法误差不断增加, 而本文算法跟踪误差小于粒子滤波算法, 在20 到30 时刻之间误差改善效果更为明显。 但另一方面,本文算法的运算时间明显大于粒子滤波算法。 如图8 所示,本文算法的时间消耗是粒子滤波的2~3 倍。 为了减小跟踪的误差, 这种以增加运算时间来换取跟踪准确性的操作是必然的。 重采样算法只是简单地选中并复制粒子,造成了粒子种类的减少。 本文算法不对粒子进行选择与复制, 通过粒子的移动来保证粒子种类的多样性, 因此提高了跟踪准确性并减小了跟踪误差。
4 结 论
本文将萤火虫算法引入到粒子滤波过程中,改进了萤火虫算法中相对亮度与吸引度的计算方法,在相对亮度的计算过程中利用了当前时刻的观测值数据。 在吸引度的计算中引入递减函数,粒子在向最优值靠近的过程中避免了在最优值附近震荡。 利用最优个体指引萤火虫的移动,降低了算法的复杂度, 最后通过仿真实验验证改进算法的性能。 结果表明:
1) 粒子滤波算法提议分布的选取没有融合当前时刻的观测值,当似然函数远离提议分布的峰值时,无法保证状态估计的准确性。 本文改进算法融合了当前时刻的观测值,提高了估计的精度。
2) 重采样过程用大权重粒子替代小权重粒子,解决了粒子退化问题,但是造成了样本的匮乏。本文改进算法中小权重粒子通过一定的规则向大权重粒子移动, 从而分布在大权重粒子的周围,保证了样本的多样性,从而减小了估计的误差。
3) 通过对非线性过程的仿真得出本文改进算法可以保证估计的精度, 具有一定的实用价值,下一步将研究改进算法在智能跟踪、导航等场景的具体应用。
猜你喜欢
摄影之友(影像视觉)(2019年3期)2019-03-30
小天使·一年级语数英综合(2018年7期)2018-09-12
小天使·一年级语数英综合(2017年6期)2017-06-07
小天使·六年级语数英综合(2017年5期)2017-05-27
现代工业经济和信息化(2016年19期)2016-05-17
公民与法治(2016年23期)2016-05-17
为了孩子(孕0~3岁)(2016年1期)2016-01-16
海军航空大学学报(2015年1期)2015-11-11
小天使·一年级语数英综合(2015年8期)2015-07-06
空间控制技术与应用(2015年3期)2015-06-05
