
基于代码行变更指数的异味类排序方法
2021-03-23 09:38位欢欢吴海涛高建华
计算机工程与设计 2021年3期
位欢欢,吴海涛,高建华
(上海师范大学 信息与机电工程学院,上海 200234)
0 引 言
代码异味[1]的出现给软件质量和可维护性带来了很大的隐患。而解决它们的有效方式是进行重构,但是由于重构的成本相对较高,对所有的异味进行重构是不现实且不必要的,因为不同异味类的异味程度并不是相等的[2]。因此,需要对异味类进行排序,着重关注那些有较大概率出现异味的代码。
Vidal等[3]提出了一种基于3个标准的半自动化的异味类排序方法。Fontana等[4]采用度量值与阈值的比较结果(强度值)来对代码异味进行排序。Natthawute等[5]基于开发人员的角度来研究代码异味的排序,研究表明开发人员是通过代码的耦合程度以及组件的重要性来对代码异味进行筛选和排序的。Anshul Rani等[6]则是通过对不同异味类之间的耦合程度计算出每个类的影响因子,并根据影响因子的大小对代码异味进行排序。Mcintosh等[7]通过在 5ESS® 软件项目上进行研究,发现代码变更的规模与软件出现错误的概率具有相关性。Charalampidou等[8]的研究表明代码变更的规模与软件易错性发生的概率存在正相关关系,即代码变更规模越大的类,出现异常和错误的概率越大。
本文基于代码变更与软件易错性存在正相关关系,通过研究在历史代码变更信息中各个类的代码行数动态变化情况,提出基于代码行变更指数的异味类排序方法(CLCI)。并在开源项目HospitalAutomationWithJavaEE上进行实证分析,实验结果表明,本文提出的异味类排序方法可以使后续异味类重构更加容易,从而为项目开发和维护节约成本。
1 相关工作
1.1 异味类排序
Vidal等[3]提出了一种半自动化的方法,用于在决定对代码异味进行适当重构之前先对异味类进行优先级排序,该排序方法主要基于以下3个标准:发生异味的代码的稳定性、开发人员是否使用常规标准来对每种异味进行主观评估,以及相关的可修改性场景。通过在两个案例研究中进行实验验证,结果表明建议的代码异味顺序对开发人员是有用的。其研究结果表明代码异味排序对于实际的程序开发是有效的。
Fontana等[4]提出基于强度因子来对代码异味进行排序,强度因子是表示代码异味强度情况的指标,通过对静态度量值与阈值的比较并计算得出的。实验研究是在Qua-litas Corpus上的74个开源项目上进行,实验使用自己研发的工具JcodeOdor,通过对6种代码异味进行一些静态度量值测量来建立实验模型。但是,强度因子的实验过程相对复杂,不利于开发人员的实际应用。
Natthawute等[5]通过对10个专业开发人员在异味的选择和排序需要考虑哪些因素进行问卷调查,把开发人员对于异味的看法分为15个类别,以此来判断开发人员在异味选择时最关注的因素。实验结果表明,开发人员在选择异味时,工作相关性是首先被考虑的,其次是异味的严重性;在开发人员对代码异味排序时,模块重要性是普遍被优先关注的,其次是项目相关性。但是,其研究并没有为开发人员在代码异味排序提供具体的定量指标。
Anshul Rani等[6]的研究是基于类间的耦合性来对异味进行排序的。实验共分为两个部分,第一部分为检测代码异味,得到异味类列表;第二部分是基于异味影响因子来对异味类进行排序,影响因子越大表示异味越严重。实验结果表明,根据排序列表进行重构的结果,明显好于随机进行重构的结果,作者的研究为开发人员提供新的异味类排序方法。
1.2 代码变更与软件易错率的相关性
Mcintosh等[7]通过在5ESS®软件项目上进行实证研究,得出代码变更的规模与软件出现错误的概率具有相关性。通过建立预测模型,研究得出随着代码变更次数、代码变更行数的增加和相关联的子系统数目的增加,软件出现错误的可能性也会相对增加。此外,不同类型的代码变更对于软件系统出错率的影响是不同的,新增加的代码出现错误的概率要比修复缺陷的代码变更容易出现错误,因为修复代码的变更相对规模较小。
Charalampidou等[8]通过使用代码异味出现概率来对常见的TD代码中的代码异味进行评估分析,分析异味出现概率与模块的变化倾向的关系。案例研究的结果表明,比起不易变更模块中代码异味出现的概率,代码异味显然更易集中在具有变更倾向的模块中。这些研究结果对研究人员和实践者都是有用的,可以为后续研究重构策略和重构的优先级提供方向。
陈芝菲[9]通过对大规模数据集的历史维护信息进行分析,发现出现代码异味和没有出现代码异味的类发生变更或错误的次数存在较大的差异。为了进一步探索软件变更与代码异味出现的关系,建立负二项回归模型来对其进行研究,研究表明代码变更是软件发生易错性的最重要因素,尤其是代码行等自变量。
Luca Gazzola等[10]通过在软件系统交互时存在故障和程序不稳定问题的研究中,发现代码的大量变更容易导致项目出现错误,并提供统计数据来支持其声明,更进一步提出应避免对超过25%的现有代码进行更改,对于此类情况建议重新编码而不是修改。上述研究均表明代码变更规模越大,越容易导致项目出现错误,给项目后期的维护带来负担。
本文基于代码变更规模与代码出现异味的概率存在正相关关系,通过关注代码行数在整个开发过程中的动态变化来定量描述代码变更的规模,并把代码变更的规模定义为代码行变更指数,根据其值的大小来对异味类进行降序排序。
2 代码行变更指数排序方法
在软件项目的开发过程中,随着项目需求的变更、错误代码的修正、软件项目的优化、测试案例的选择和后期项目的维护,开发人员需要对代码进行增加、删除、修改操作。但是,代码变更不可以不计其规模而进行,若软件项目的变更大于项目代码总数的25%时,修改代码所花费的成本将大于重新编译该项目[10]。设计良好的项目结构其类的稳定性相对较高,面临上述情况时,其代码变更规模相对较小,相反,若是一个类的代码行数频繁变更,则其代码的结构设计越糟糕,出现异味的概率越大。此前,对于代码行数的研究大多基于静态的最终代码行数,而本文主要关注在一个项目开发周期中代码行数的动态变化,即每个开发人员每次提交的代码变更信息中代码行数的变化,并用代码行变更指数(CLCI)来表示该变化,CLCI值越大表示该类的代码变更规模越大,则该类出现异味的概率越大。本文的实验是基于类的代码行变更指数(CLCI)来对异味类进行排序,以此减少后期维护成本。实验的整体流程如图1所示,共分为3步,描述如下:
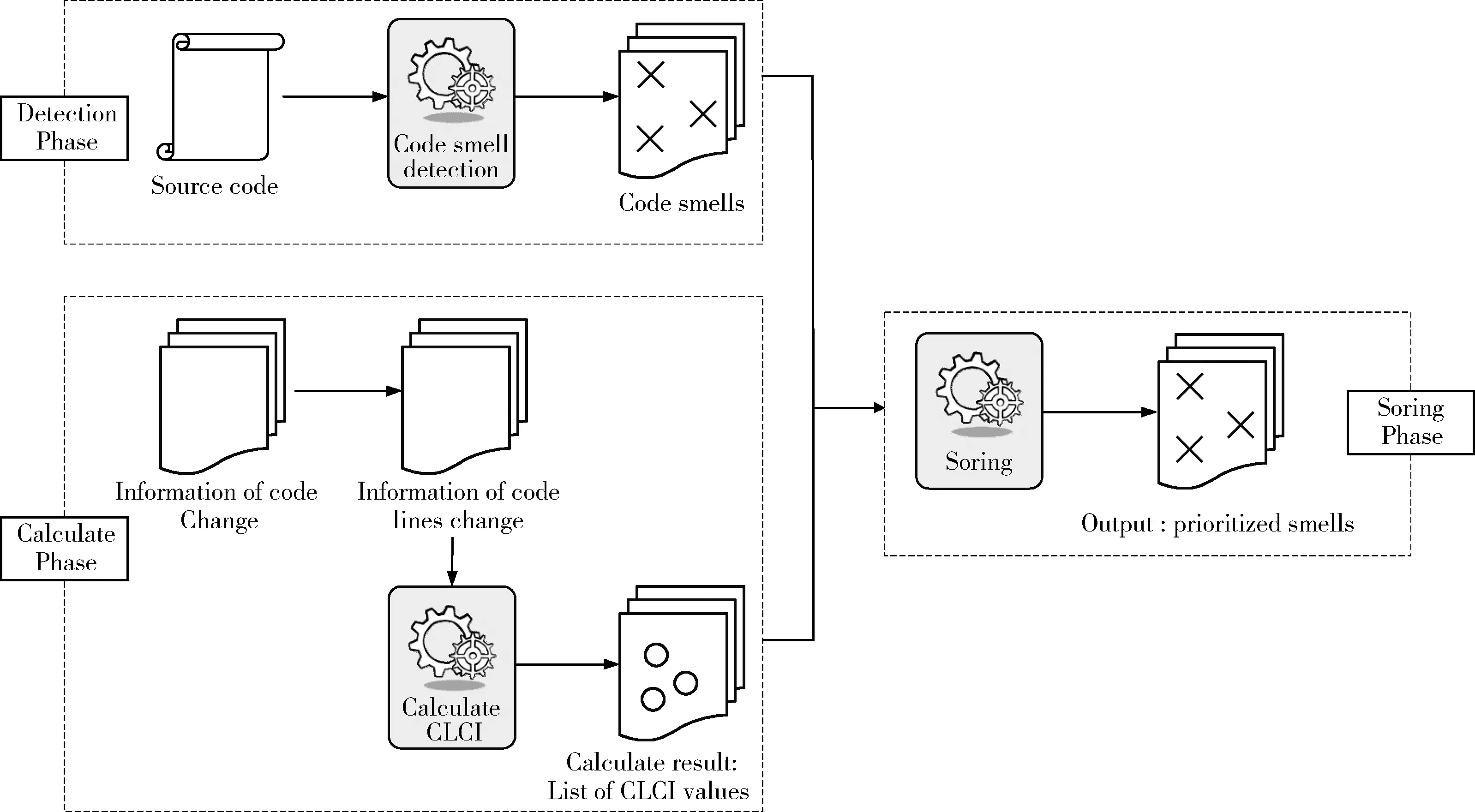
图1 整体流程
(1)检测阶段:在检测过程中,本文使用开源检测工具JDeodorant,它是eclipse的免费开源插件,检测的异味为feature envy,Duplicate code,Type checking,Long Method,God Class,根据检测结果得到异味类列表;
(2)计算阶段:收集项目开发过程中每个开发人员每次提交的代码变更信息,统计同一异味类每次代码变更前后的代码行数,计算其差值为该次代码变更的行数;之后,把代码行变更指数与最终代码行数的比值之和称为代码行变更倍数(Times),并对其进行sigmoid函数归一化,得到的值即为代码行变更指数(CLCI),分别计算各个异味类的CLCI值,得到所有异味类的代码行变更指数列表;
(3)排序阶段:根据异味类的代码变更指数(CLCI)值的大小对检测到的异味类进行排序,CLCI值越大的异味类则表示其代码变更规模越大,出现代码异味的概率相对较高,反之,则表示该异味类出现异味的概率相对较低。
2.1 检测工具的选择
许多学者已经对代码异味的检测进行研究[11-14],而本文主要研究代码异味的排序方式,对于代码异味的检测倾向于选择开源且易于操作的代码异味检测工具。本文通过对代码异味检测工具的分析和研究,最终选择JDeodorant作为本文代码异味检测的工具,见表1。选择JDeodorant工具的优势:
(1)JDeodorant工具是eclipse软件的一个开源插件,且操作简单;
(2)JDeodorant工具可以自动识别java程序中本次实验需要检测的所有异味类型;
(3)JDeodorant工具可以向开发人员提供多种重构建议并自动实施开发人员所选择的重构建议。

表1 异味检测工具
2.2 代码变更指数的计算
大量研究表明,代码变更规模与软件易错率存在正相关关系[7-10],本文正是基于代码变更规模的大小来判断哪些类更容易出现异常和错误,代码变更规模较大的异味类出现异味的概率相对较大。而此前的研究主要关注每个类最终的静态代码行数,而忽略在整个项目开发中每个类的代码行数随着每次开发人员提交代码而发生动态变化的情况。本文基于每次代码变更前后代码行数的变化情况来对异味类进行排序,其中代码变更次数相对较多,每次代码行数变化相对较大的类,则其出现异味的概率也相对较大。因此,本文为了描述代码行在整个项目开发周期中的动态变化,定义了代码行变更指数(CLCI)。代码行变更指数是指在项目开发周期中,每次开发人员提交代码时,该异味类代码行数发生变化的总和是最终代码行数的倍数Times,并对其进行sigmoid函数归一化。代码行变更指数(CLCI)的计算公式如下
(1)
(2)
其中,k表示代码变更总次数,CR(i)(Code Row) 为异味类第i次代码变更后的代码行数,其中CR(0)=0,则CR(i)-CR(i-1) 为第i次代码变更时,发生变化的代码行数,在除以最终代码行数(LCR)并求和,并对求和结果进行sigmoid函数归一化,使其值范围属于(0,1)之间。计算代码行变更指数的伪代码设计如下:
算法1: CLCI计算过程
输入: 代码提交行数CR,代码变更次数k,最终代码行数LCR
输出: CLCI值
(1) CLCI←0,CR(0)←0
(2) Fori←1 tokDo
(3) If CR(i)≥CR(i-1) Then
(4) CCR(i)←CR(i)-CR(i-1)
(5) Else
(6) CCR(i)←CR(i-1)-CR(i)
(7) End if
(8) Times←Times+CCR(i)/LCR
(9) End for
2.3 异味类排序
通过上述方式对异味类进行计算得出所有异味类的代码行变更指数,CLCI的值越大,则表示在项目开发过程中该类的代码变更规模越大,即该类出现异味的概率越大。反之,CLCI的值越小,则该类出现异味的概率越小。最后,根据CLCI值的大小来对异味类进行降序排序,从而得到排序后的异味类列表。
3 实验研究
为验证依据代码行变更指数对异味类排序的有效性,本文以HospitalAutomationWithJavaEE[6]系统作为测试背景,计算该项目所有异味类的代码行变更指数,并依据代码行变更指数值的大小进行排序,最终得到排序后的异味类列表。实验主要寻求以下几个问题的解答:
Q1:使用CLCI排序方式进行重构,前序异味类重构之后能否使后续需要重构的异味类数量减少?
Q2:使用CLCI排序方式进行重构,重构后总体异味类剩余数量是否减少?
Q3:使用CLCI排序方式进行重构,比基于类间耦合性[6]进行排序,异味剩余率是否减少更快?
3.1 实验准备
本文实证研究是在java开源项目上进行的,项目名称为HospitalAutomationWithJavaEE[6],此项目共有49个类,58次代码变更记录信息,选择此项目的原因为:①曾在其它论文中使用[6],具有一定的可信度;②有很高的错误比例(36%),给代码异味的排序供了实例。检测代码异味的工具为自动化检测工具JDeodorant,主要检测的代码异味为feature envy,Duplicate code,Type checking,Long Method,God Class,该工具操作简单且具有重构功能,能够为后期重构节约成本。
3.2 数据预处理
实验所需的初始数据为项目历史记录信息,项目历史记录信息可以在公共的开发仓库获得,如CSV,GitHub,对于公司内部项目,开发人员更改代码的记录可以从项目日志中获得。本文实验数据是从github项目仓库中获得,实验项目的历史记录信息为每次代码变更提交的commit记录。项目历史记录信息包含的内容较多,但本次实验并不需要所有的数据信息,因此,根据本文实验要求从历史记录信息中提取实验所需代码变更信息,举例如图2所示。

图2 代码变更信息举例
代码变更信息中包含类、配置文件以及网页的变更信息,基于本文的实验要求,首先需要对代码变更信息进行数据选取,即保留类的变更信息,清除其它不必要的变更信息,进行数据选取时,可以依据提交主题中的关键词进行快速数据选取;其次,依据类名对代码变更信息进行分类汇总,得到每个类的代码变更信息;最后,对分类信息进行统计整理,记录每个类的代码变更hash值、代码变更作者、代码变更时间、代码变更行数以及该类的最终代码行数,此处以SaveAppointmentsService.java类的变更信息为例,见表2。
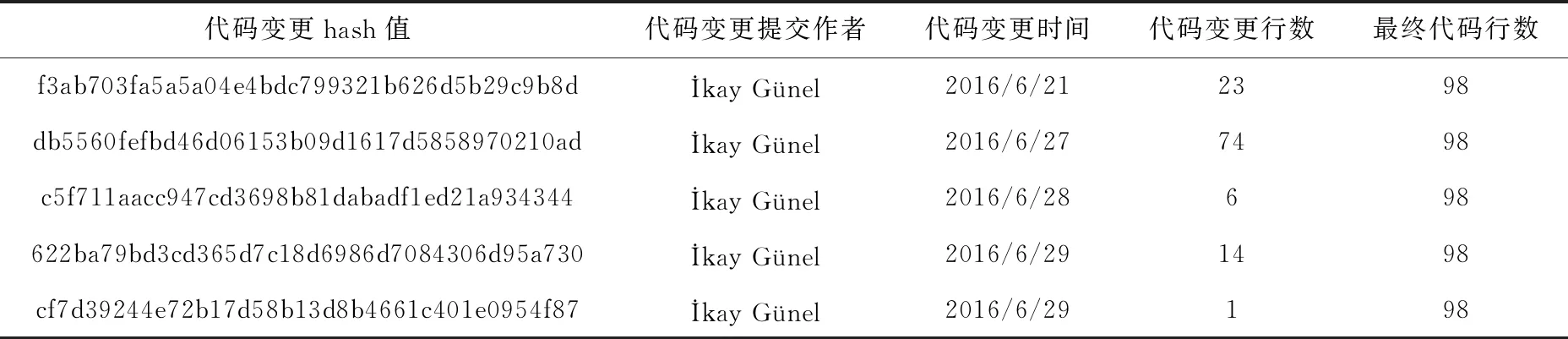
表2 SaveAppointmentsService.java类代码行变更信息
3.3 检测与计算结果
通过对HospitalAutomationWithJavaEE项目的49个类,58次代码变更记录信息进行异味类检测与代码行变更指数计算,检测与计算的结果见表3,该表采用代码行变更指数递减的顺序排列。检测阶段的结果表明,在该项目中Duplicate Code异味较为常见,其次为Feature Envy与God Class异味。计算阶段的结果表明,当CLCI值大于0.9时,出现代码异味的概率较大。
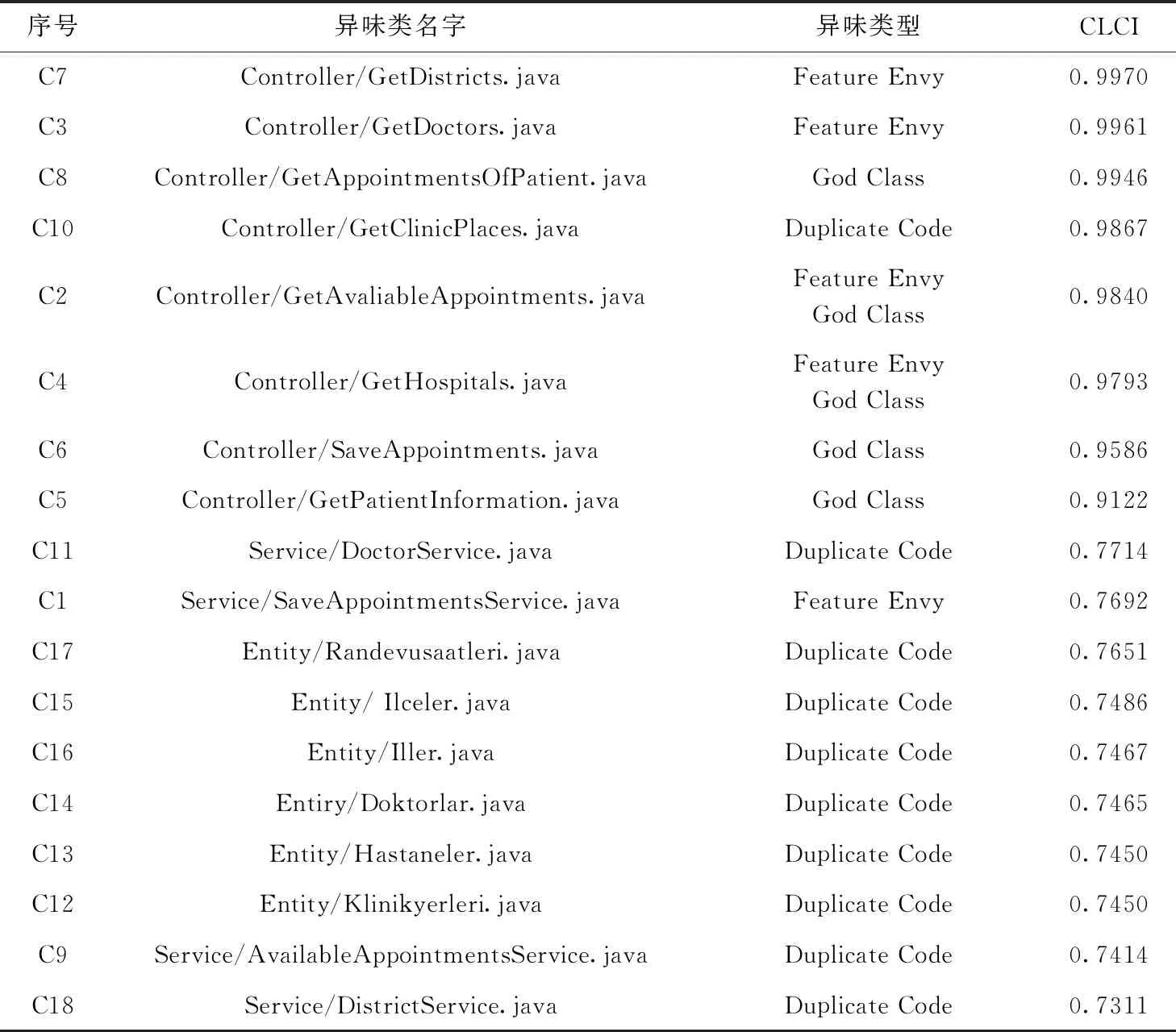
表3 检测与计算阶段结果
3.4 实验结果分析
根据检测阶段和计算阶段的实验结果,逐一回答前文提到的Q1、Q2、Q3问题。
Q1:为验证使用CLCI的排序方式进行重构,前序异味类重构之后能否使后续需要重构的异味类数量减少,本文采用JDeodorant工具对异味类按照代码行变更指数降序排序的顺序对异味类进行重构,并在一个异味类重构之后观测后续异味类的数量是否减少。通过实验观测发现,Service/AvailableAppointmentsService.java与Service/DoctorService.java均为Duplicate Code异味,它们的代码行变更指数分别0.7311和0.7714,根据上述重构规则需要优先对Service/DoctorService.java异味类进行重构,但是在重构过程中发现这两个异味类具有相同的代码片段,两个异味类的相同代码片段如图3所示。使用重构工具JDeodorant提取重复代码片段定义为新的类KlinikerEqualClinic.java,则在service/DoctorService.java异味类被检测出来后,使用JDeodorant插件按照开发人员选择的重构建议进行重构之后,service/AvailableAppointmentsService.java类的异味随之自动解决;此外,对Controller/GetDoctors.java进行God Class重构后,Controller/GetHospital.java类的异味也自动消失。研究结果表明异味类之间具有相关性,一个异味类重构以后会使后续需要重构的异味类数量减少,从而减少重构成本。

图3 异味类重复代码片段
Q2:为验证使用CLCI的排序方式进行重构,重构后总体异味类剩余数量是否减少,本文采用对照实验,把项目复制成内容相同的两份,实验组采用优先对代码行变更指数较大的异味类进行重构;对照组采用随机方式对异味类进行重构。为了判断重构后异味类的剩余情况,本文采用异味剩余率(CML,即“code smell left %”)作为评价指标,异味剩余率为重构后的异味类剩余数量占总异味类数量的比例,其公式如下所示
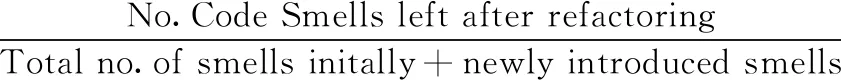
(3)
异味剩余率(CML)值越小则表示使用该代码异味排序方式重构后的异味数量越少,即该代码异味排序方式更优。本文使用JDeodorant工具,并分别采用两种不同的排序方式来对相同项目的代码异味进行重构,重构剩余率对比如图4所示,从图4可以看出当对前10个异味类采用本文的排序方式进行重构后的异味类剩余数量仅占总异味类数量的25%,则使用随机排序方式进行重构后的剩余异味类数量占总异味类数量的50%;使用本文的排序方式,代码异味的剩余率减少速度比随机排序方式快,说明采用本文的排序方式可以使重构后的总体异味类剩余数量减少,从而减少重构成本。
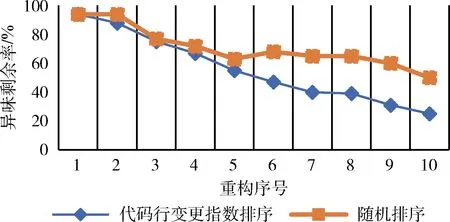
图4 CLCI与随机排序重构后异味剩余率对比
Q3:为验证使用CLCI的排序方式进行重构,比基于类间耦合性[11]进行排序,异味剩余率是否减少更快。本文采用Q2的对照实验,实验组为基于代码行变更指数的异味类排序方式,对照组为基于类间耦合性的异味类排序方式,并采用异味剩余率来对其结果进行比较。其中,基于类间耦合性的异味类排序方式的计算公式如下
(4)
具体计算公式,可以参考文献[11]。在整个实验过程中,分别记录对照组采用基于类间耦合性排序方式进行重构,重构后的前10个异味类的异味剩余率变化过程和实验组采用基于代码行变更指数排序方式进行重构,重构后的前10个异味类的异味剩余率变化过程,见表4。
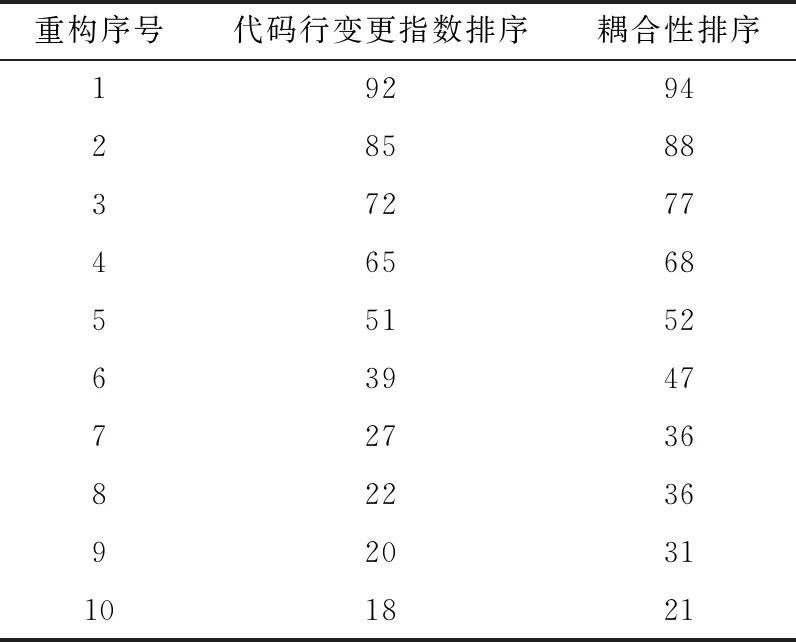
表4 类间耦合与CLCI排序重构后剩余率
从表4可以看出,当CLCI指数较大的7个异味类被重构之后,异味剩余率下降开始减缓,此时,该CLCI值开始小于0.9。而基于耦合性的排序方式在整个重构过程中,异味剩余率下降较为平稳,但整体效果比起CLCI值下降更少,如图5所示。
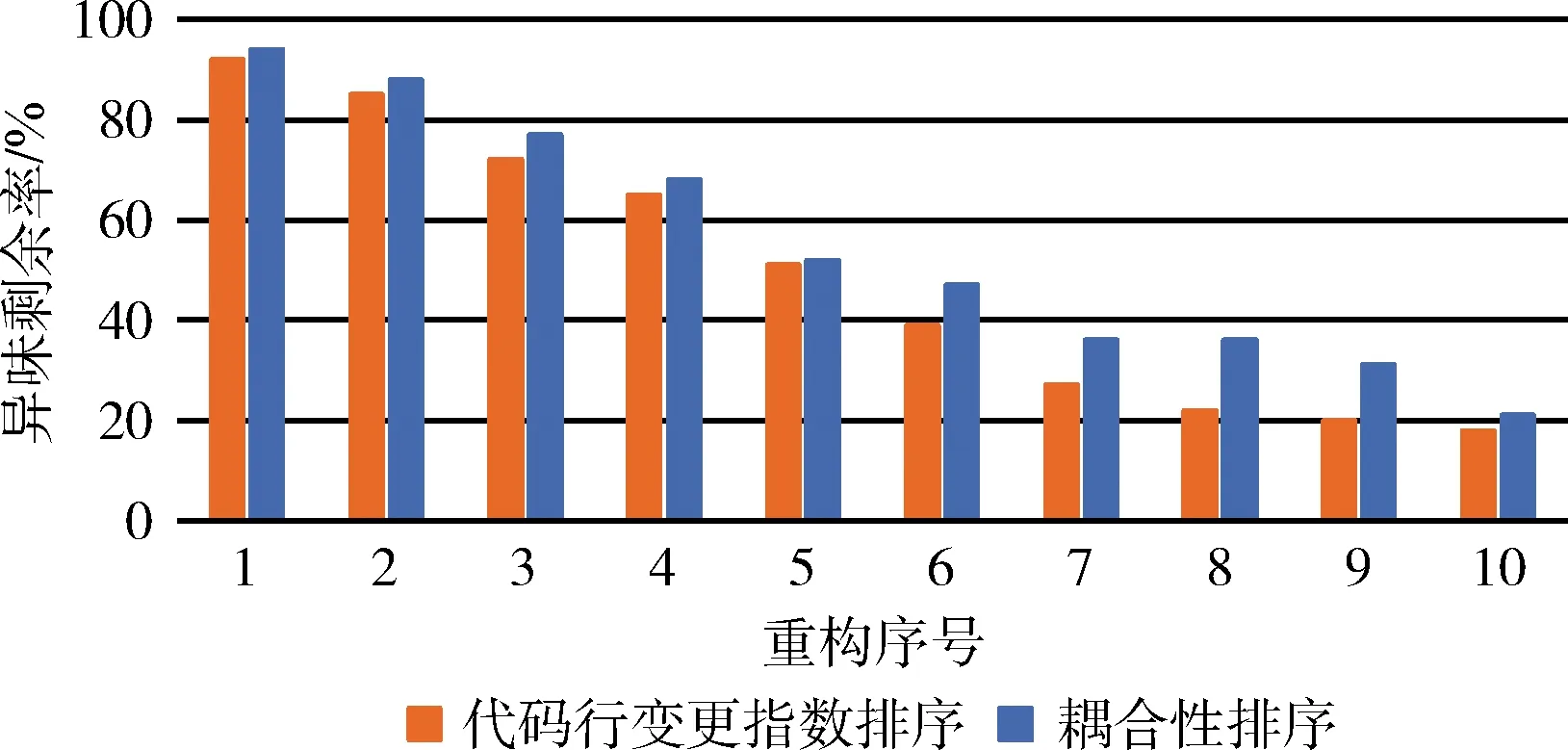
图5 CLCI与耦合性排序重构后的异味剩余率
4 结束语
本文依据代码变更规模与软件发生错误的概率存在正相关关系,定义代码行变更指数来描述软件开发过程中,代码发生变更时代码行的动态变化,并以此来对异味类进行排序,实验结果表明,使用代码行变更指数来对异味类进行排序可以使后续的重构更容易,从而提高重构的效率。在未来的工作中,将会在以下几个方面展开:
(1)持续研究代码变更中其它因素,如代码变更的原因以及发生变更的代码重要程度对于异味排序的作用。
(2)通过研究异味类之间的相关关系,改进基于代码行变更指数的异味类排序方法。
猜你喜欢
中国信息化周报(2019年18期)2019-06-09
石油石化绿色低碳(2019年6期)2019-01-14
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
宠物世界·猫迷(2017年7期)2018-01-25
猪业科学(2018年8期)2018-01-22
电脑爱好者(2015年6期)2015-04-03
家庭生活指南(2009年7期)2010-04-07
