
相对边缘方向幅值模式耦合SIFT的人脸识别算法
2021-03-23 09:14郑笔耕谭云兰
计算机工程与设计 2021年3期
赖 玲,郑笔耕,谭云兰
(1.荆楚理工学院 计算机工程学院,湖北 荆门 448000;2.荆楚理工学院 电子信息工程学院,湖北 荆门 448000;3.井冈山大学 电子与信息工程学院,江西 吉安 343009)
0 引 言
人脸识别(face recognition,FR)是指使用计算机从给定一组属于不同人群的照片中识别出一个人[1]。目前,FR是一些商业或执法应用中的一项关键任务,如监视通缉犯、限制区域的访问控制以及照片共享应用程序中的自动标注。然而,该技术在复杂环境中,其识别准确度明显较低[2]。
近年来,学术界出现了许多相关的FR技术,如毋立芳等[3]设计了一种全姿态二值SIFT的人脸识别技术,该方法在标准人脸库中取得一定的成绩。但在二值化过程易损失部分有效信息,降低了识别率。此外,算法的性能主要依赖脸部图像的质量,因此,对光线变化、遮挡等环境下识别效果还有待提高。魏月纳等[4]将Gabor脸部特征融合,再根据信息的重要性划分子块。然后定义一种改进的隶属函数完成分类训练,可以弥补训练样本不足时导致的准确率不稳定。但是该技术在光照变化、视角变换等复杂环境中,所提算法稳定性较差,识别率不理想。此外,Gabor使用过程易出现维数灾难,降低效率。Chen等[5]通过结合类内信息,建立了一种新的目标函数。该算法是利用块策略和核理论推导出来的。实验结果表明所提系统在标准人脸库有效。但是,KNMF无法处理非线性可分离的数据点,无法有效判别特征非线性关系,对于复杂背景以及遮挡时识别效果不佳。
考虑到复杂环境对人脸识别的影响,引入多种方法来量化每种识别中所涉及的不确定性,对许多AFR应用都是非常有益的。因此,在本文算法中,引入了RPOEM与SIFT两种特征。RPOEM能够提取快速脸部关键点并进行聚类,剔除无效杂点。然后将RPOEM离散化,采用局部二值模式编码(local binary pattern,LBP)编码,构建了LBP直方图特征,消除了像素零值对脸部特征提取的影响,并且考虑相邻像素的相关性,能够准确提取脸部信息,对光照、遮挡等效果明显。另外,本文通过共形预测(conformal prediction,CP)来分类识别。在特定的情况下,CP可以提供一个置信度测量,以表明每个识别正确的可能性,从而缩小每张照片的可能候选范围。最后,通过两个常用的数据库来验证所提技术的有效性。
1 共形预测
共形预测(conformal prediction,CP)是一种预测分类模型,它利用校准集(经验)建立新预测的精确置信水平,提供了一种在适用于分类和回归上下文的在线设置中获得误差校准的方法[6]。CP允许用户设置可接受错误的百分比,满足了数据集的可交换性条件。CP的一个主要优点是,如果数据是可交换的,即新数据的行为类似于旧(训练)数据,则该方法能产生有效的预测。
设A={(xi,yi)|i=1,…,N} 表示训练集,其中,xi是以输入向量形式的对象。R={t1,t2,…,tc} 为输入向量,yi∈R。 令B={Xk|k=1,2,…,M} 为测试集。其中,Xk是测试样本。定义Ck,l=A∪{(Xk,tl)},其中,tl∈R。 通过置信度度量来评估预测这些集合,并在给定期望的置信度水平的情况下,为测试实例Xk找到候选标签。

对于每个测试样本k,有c个NCS序列,表示为Hk,l。 给定一个NCS的序列Hk,l,计算测试样本 (Xk,tl) 的可能性,表示如下
(1)

计算完所有p值后,它们可用于生成满足预设置信水平1-δ(δ称为显著性水平)的预测集。考虑到显著性水平δ,CP将输出预测集
{tl|pk(tl)>δ}
(2)
希望预测集尽可能小,预测集的大小取决于p值的质量,也取决于所使用的非一致测量(nonconformity mea-sure,NCM)[8]。因此,CP将输出标签tr,表示如下
r=argmaxl=1,2,…,cpk(tl)
(3)
换句话说,tl对应最高的p值。这一预测与可信度指标相辅相成。低可信度意味着要么数据违反了互换性假设,要么特定的测试示例与训练集示例差异巨大。
2 本文人脸识别算法
通常,每张人脸图像在识别前需构造为一组特征向量。对于人脸识别而言,首先需要自动检测人脸图像中的关键点。然后,使用RPOEM和SIFT两种特征来计算这些点的人脸表示。如果图库包含一个人的更多图像,使用所谓的“组合模型”,将从属于给定人的所有图像中提取的特征放在一起,并创建一个组合表示。最后,将人脸表示与图库图像进行比较,以完成人脸的判断识别,整个过程如图1所示。
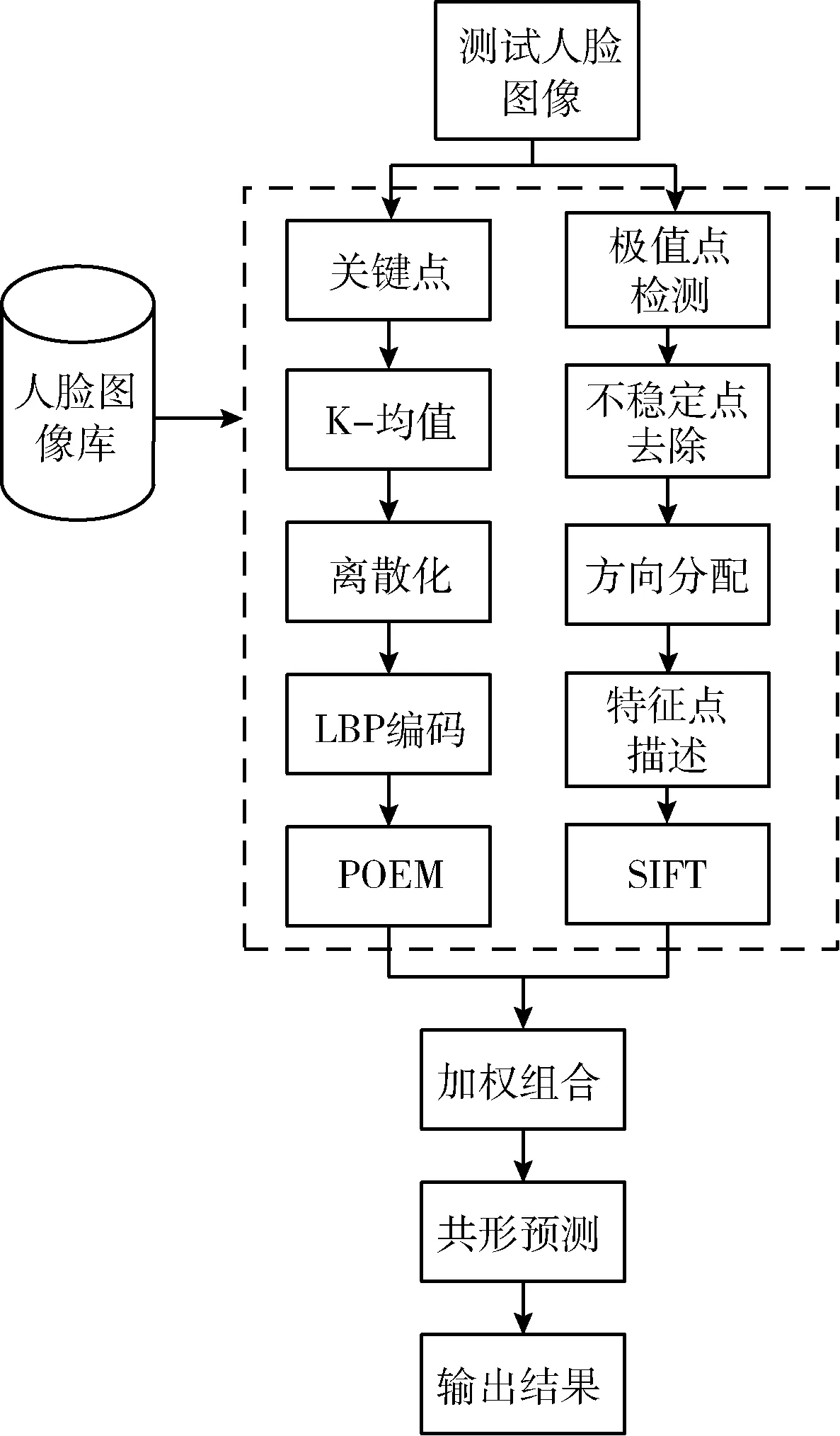
图1 所提人脸识别算法的过程
2.1 相对方向边缘幅值模式(RPOEM)
方向边缘幅值模式(POEM)通过测量梯度来获取人脸的方向和幅值,再利用LBP累加幅值[9]。将一组不同方向和波长的Gabor应用于图像,然后根据滤波器响应确定关键点。使用w×w大小的方形滑动窗口W过滤后,窗口中心 (r0,c0) 被认为是关键点
(4)
(5)
其中,Rj是滤波器j的响应(使用滤波器j过滤图像的结果),j=1,2,…,NG(NG为Gabor数量)。wi*hi分别为图像宽度和高度。对于脸部关键点,Rj值必须大于定义邻域中的所有点,同时高于响应j中所有像素的平均值。
确定的关键点数量通常太高(数百个),并且这些点数通常集中在重要的面部附近。此外,大量的点显著增加了计算的复杂性,因此,利用K-均值对关键点聚类,识别出最重要的点[10]。
在POEM过程中,一般先计算输入图像中每个像素的梯度,设图像I(x,y),在特定光线下,I(x,y)的质量由光照分量L(x,y) 和反射分量R(x,y) 组成,表示如下
I(x,y)=L(x,y)·R(x,y)
(6)
R(x,y) 描述了脸部变化特征。I(x,y) 的梯度大小和方向可表示如下
(7)
梯度方向表示为
(8)
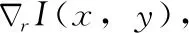
(9)
如果I(x,y) 中光照分量L(x,y) 缓慢变化,可看作为L(x+1,y)≈L(x,y),所以

(10)

图2 不同光照梯度计算
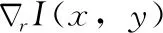
RPOEM={H1,H2,…,Hm}
(11)
2.2 SIFT
SIFT可看作为局部特征,具有尺度不变性,并且对光线同样有良好处理效果[11]。SIFT主要有:①极值点检测;②不稳定点去除;③方向分配;④特征点描述等4个步骤组成。分别介绍如下:
(1)极值点检测
SIFT特征点通过Gaussian差分(DoG)空间的局部极值点生成[12]。将某个中心点与其周围的26个点比较,如图3 所示。如果这个点在DoG尺度中大于或者小于所有26个点,则将其选作极值点。

图3 极值点检测
(2)不稳定点去除
由于尺度采样的存在,SIFT检测的极值点处于像素点上,但如果通过空间曲面进行拟合时,大部分极值点都处于像素点附近,出现了偏移。为了精准获得极值点的位置,设DoG区域是连续的,通过二阶Taylor展开式进行拟合与测量DoG的响应值。如果该点的响应值超过0.03,那么保留该点;反之,将该点看作为低对比度的点去除[13]。
对于不稳定边缘点,通过计算DoG的2阶导数,获得主梯度方向和其它方向比率,将比率小于某个值的特征点保留下来。过程描述如下:①分别估计每个极值点在x,y方向的2阶导数和xy方向的导数。②通过①可生成极值点的Hessian矩阵,表示如下
(12)
式中:Ixx,Ixy,Iyy分别表示x,xy,y的二阶导数。③计算Hessian矩阵的迹和行列式;④计算矩阵迹的平方与行列式的平方的比值,若该比值小于阈值(通常取10),那么该点可认为是真正的极值点。
(3)方向分配
然后,计算基于像素附近的局部梯度方向,建立局部梯度方向的平滑直方图,然后对直方图中的峰值进行分配。为关键点指定一个方向,确保其保持旋转不变性。
(4)特征点描述
最后一步是为局部图像区域创建描述符,计算涉及关键点位置的16×16邻域,在邻域的每个点上计算梯度大小和方向。它们的值由Gaussian窗口加权,对于大小为4*4(16个区域)的每个子区域,创建方向直方图。最后,生成一个包含128(16×8)值的向量。得到特征后,为消除光照变化的影响,对其实施归一化
(13)
式中:hi为区域的梯度幅值。
2.3 Lenc-Kral匹配
在这项工作中,分别将两个不同特征进行相似性度量。其中,SIFT特征通过定义的余弦相似性进行比较,表示如下[14]
(14)
式中:qm,Qn分别为测试集和训练集的特征向量。
RPOEM特征通常使用直方图交叉(histogram intersection,HI)进行比较,定义如下[14]
(15)

(16)
式中:sim相似性度量。对相似性进行累加,得到相似性的总和,计算如下
(17)
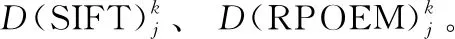
2.4 加权组合

(18)
式中:ω为权重因子。
2.5 基于CP的不一致测量

CP框架通过不一致性分数的定义将假设检验的原理和传统的机器学习算法结合在一起,非一致性分数是一种量化数据点与特定类标签的非一致性的度量,并且适用于每个分类器,定义为
(19)
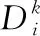
假设有一个新的测试元素sn+1,系统中所有元素s1,s2,…,sn+1的非一致性度量,计算p值函数
(20)
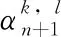
很明显,当yj训练集的非一致度量值高于新的测试点时,p值最高,sn+1最符合yj。 重复这个过程,并使用p值的最高值来确定分配给sn+1的实际类型,从而为分类提供一个转换推理过程。如果pj为最高的p值,pk为第二高的p值,那么pj为决策可信度,1-pk为分类器的置信度。设给定用户的置信度为δ,输出共形预测区域F,包含p值大于1-δ的所有类标签。
3 实验与分析
为验证所提算法的性能,选取常见的FERET与LFW人脸库中实验[15,16]。实验硬件为:Intel i5,3.4 GHz CPU,8 G RAM,Windows10,利用C++的Caffc工具进行处理与分析。为使实验更具说服力,选取文献[3]~文献[5]进行对比。参数设置如下:窗口大小w×w=3×3,置信水平=0.02,分解数m=6,子块n×n=5×5,权重ω=0.6。
3.1 人脸库选择与介绍
FERET人脸库包含14 051张多姿态,大小为512×768。人脸具有光照、表情等差异,是人脸识别中应用最广泛的数据库之一。本文中选择了200人的1000幅正面不同光照条件构建了一个新的子集进行实验,图像大小变换为92×112,部分FERET子集如图4所示。

图4 FERET部分人脸实例
Labeled Faccs in the Wild(LFW)含有1680个人的 13 000 张脸部图,大小均为250×250,这个数据集是人脸评估常用的一个数据集。LFW数据库既有正面照,也有侧面照,并且同一张图种可能含有多张人脸,包含了多种背景、光照变化、遮挡等因素,有的人只对应一幅人脸图,有的人同时保存了多种人脸图。因此,LFW数据库包含的信息复杂,比较随机,具有很强的代表性。实验过程随机选择3000张图像,其中有1500张属于同一人的2张图,另外1500张是不同人的1张图,部分LFW子集如图5所示。

图5 LFW部分人脸实例
3.2 主要参数优化
根据第2节看出,RPOEM的性能与分解数量m和子块n有直接关系,为确定m和n的最优值。实验过程中,从FERET子集中选择每个2张人脸,形成一个容量为400的训练集,其余600张人脸构成测试集。首先,假定分解数m在固定情况下,改变不同的n值测试人脸识别率。图6(a) 为当m=4时,在不同的n值下得到的识别率曲线。从图6(a)看出,随着n的增加,识别率也随之增大。当n=5时,识别率趋于稳定,n的增加对识别效果无促进作用了,并且考虑到n的增加会导致特征数加大,增加计算复杂性,因此,本文中取n=5。
确定n=4之后,通过改变m值来测试不同的识别率。图6(b)显示了不同m下的识别率曲线,可观察出,随着m的增加,识别率走势是先增加,后降低。当m=6时,识别效果最佳,因此,本文取m=6。
3.3 实验结果
为验证提出算法的识别性能,分别在FERET子集、LFW子集中实验。在FERET与LFW子集中,每次随机选取不同数量作为训练集,其余作为测试集。在每个子集中,进行6次相互独立测试,然后取其平均值作为统计数据,结果如图7所示。图7(a)为FERET子集测试结果,图7(b)为LFW子集结果。从图7看出,FERET子集、LFW子集中,本文算法识别率优于其它3种对照组算法,随着特征维数的增加,得到的识别率逐渐提高,从这4条曲线看出,所提算法曲线变化平稳,表明算法的健壮性良好,而其它曲线波动较大。
表1与表2分别为不同训练样本下(1-6个),在FERET子集、LFW子集的识别率数据结果。依据表1与表2得知,在FERET子集中,当训练样本数为6时,识别率高达99.56%。在LFW子集中,当当训练样本数为6时,识别率高达96.52%。

图6 参数确定实验

图7 FERET与LFW不同特征维数下的识别率

表1 FERET子集中不同样本下识别率/%

表2 LFW子集中不同样本下识别率/%
从实验结果得出,在FERET子集中,由于人脸图像比较单一,光照变化不大,4种算法取得了较好的识别率。在LFW子集中,由于人脸种类繁多、背景多样、光照变化、脸部遮挡等多种因素的干扰,在图7(b)中,本文算法仍然取得了优异的识别率,而对照组算法得到的曲线波动较大,识别率下降。从表1与表2数据可看出,相同条件下,在FERET子集、LFW子集中,本文算法的识别率均最佳,且在FERET子集中的识别率优于LFW子集。从实验结果得出,所提算法具有良好的人脸识别效果,对多种背景,光照变化、遮挡等因素干扰下能够正确识别出人脸图像,鲁棒性强。本文算法取得如此优异的成绩主要是结合了RPOEM与SIFT特征用于人脸识别。通过提取RPOEM与SIFT特征,提高人脸特征的表征能力,为后续匹配识别提供保证。此外,定义一种相对梯度幅值,对相对梯度幅值分解,对分解后的相对梯度幅值进行Gaussian滤波,消除光照变化与遮挡的影响,还考虑了相邻像素的相关性,从而提高了算法识别率和鲁棒性。而文献[3]中采用了全姿态二值SIFT的人脸识别技术,但在二值化过程易损失部分有效信息,降低了识别率。此外,算法的性能主要依赖脸部图像的质量,因此,对光线变化、遮挡等环境下识别效果欠佳。文献[4]设计了一种Gabor与分块处理的人脸识别方案,该算法在正面姿态、光照稳定时,具有较好识别效率。但是在光照变化、视角变换等复杂环境中,所提算法稳定性较差,识别率不理想。文献[5]设计了一种Kernel-非负矩阵分解人脸识别系统,其通过结合类内信息,建立了一种新的目标函数。该算法对标准人脸库有良好的识别效果,当其无法处理非线性可分离的数据点,无法有效判别特征非线性关系,对于复杂背景以及遮挡时识别效果不佳。
3.4 效率测试
为进一步测试算法的性能,对在LFW子集中,分别统计训练样本为2和5时,算法运行时间,见表3。依据表3中看出,在LFW子集中,当训练样本分别为2和5时,本文算法的运行时间为0.92 s、2.15 s。本文算法运行时间比文献[3]要长,但是比文献[4]、文献[5]要短,与对照组算法比较,所提算法效率能够满足当前使用要求,效率较高。主要原因是分别提取了人脸RPOEM与SIFT特征并进行加权融合,过程简单,复杂性低。而文献[3]采用了二值SIFT,算法简单,效率高。文献[4]采用了Gabor与分块处理,在Gabor使用过程易出现维数灾难,降低效率。文献[5]采用了Kernel-非负矩阵分解,通过结合类内信息,建立了一种新的目标函数,NMF可降维,但目标函数的计算需要花费较多时间,影响了效率。

表3 算法效率测试
4 结束语
为提高人脸识别在光照变化、遮挡等条件下的识别精度,提出了相对边缘方向幅值模式RPOEM耦合SIFT的人脸识别算法。在方向边缘幅值模式的基础上,定义了一种相对方向边缘幅值模式,有效避免了光照变化的影响。此外,为了消除像素零值的影响,将相对梯度幅值分解并采用LBP编码,生成脸部RPOEM特征。同时,为提高人脸特征的表示能力,将具有尺度和旋转不变性的SIFT引入到人脸特征提取中,通过将RPOEM与SIFT加权组合,提高了对人脸特征的表示。在FERET、LFW人脸库中验证了所提算法的有效性,结果显示该算法有效提高了人脸识别在光照变化、复杂背景、遮挡等因素干扰下的识别精度。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
计算机工程(2020年3期)2020-03-19
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
