
基于HLS 工具的CNN 加速器的设计与优化方法研究*
2021-04-02 03:44程佳风王红亮
电子技术应用 2021年3期
程佳风,王红亮
(中北大学 电子测量技术国家重点实验室,山西 太原030051)
0 引言
近年来,卷积神经网络的应用范围越来越广泛,其应用场景也日益复杂,卷积神经网络的计算密集和存储密集特征日益凸显,成为快速高效实现卷积神经网络的限制。 于是基于GPU[1]、ASIC[2]、FPGA[3]的不同的加速器平台被相继提出以提升CNN 的设计性能。 GPU 的电力消耗巨大,硬件结构固定,限制了卷积神经网络在嵌入式设备的应用;ASIC 开发成本极高,灵活性低,不适合搭载复杂多变的卷积神经网络;FPGA 具有功耗低、性能高、灵活性好的特点,因此更加适用于卷积神经网络硬件加速的开发研究,但由于Verilog HDL 开发门槛高,开发周期相对较长,影响了FPGA 在卷积神经网络应用的普及[4-5]。
本文基于软硬件协同的思想,利用HLS 工具,在PYNQ-Z2 上实现了一个卷积神经网络加速器, 并采用矩阵切割的设计方法对卷积核运算进行优化。
1 PYNQ-Z2 和卷积神经网络
本设计采用Xilinx 公司推出的PYNQ-Z2 开发板作为实验平台。 PYNQ-Z2[6-9]是基于Xilinx ZYNQ-7000 FPGA 的平台,除继承了传统ZYNQ 平台的强大处理性能外,还兼容Arduino 接口与标准树莓派接口,这使得PYNQ-Z2 具有极大的可拓展性与开源性。 PYNQ 是一个新的开源框架,使嵌入式编程人员无需设计可编程逻辑电路即可充分发挥Xilinx Zynq All Programmable SoC(APSoC)的功能。 与常规方式不同的是,通过PYNQ-Z2,用户可以使用Python 进行APSoC 编程,并且代码可直接在PYNQ2 上进行开发和测试。通过PYNQ-Z2,可编程逻辑电路将作为硬件库导入并通过其API 进行编程,其方式与导入和编程软件库基本相同。
卷积神经网络[10-13]是一种复杂的多层神经网络,擅长处理目标检测、目标识别等相关的深度学习问题。 卷积神经网络通过其特有的网络结构,对数据量庞大的图像识别问题不断地进行图像特征提取,最终使其能够被训练。一个最典型的卷积神经网络由卷积层、池化层、全连接层组成。 其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过全连接层完成图像的分类任务。卷积层完成的操作可以认为是受局部感受野概念的启发,而池化层主要是为了降低数据维度。综合起来,CNN 通过卷积来模拟特征区分, 并且通过卷积的权值共享及池化来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
本文采用一种典型的手写数字识别网络CNN LeNet5 模型[14-16]对系统进行测试,模型结构如图1 所示,总共包含6 层网络结构:两个卷积层、两个池化层、两个全连接层。 网络的输入为28×28×1 像素大小图片,输 入 图 像 依 次 经 过conv1、pool1、conv2、pool2、inner1、relu1、inner2 层后,得到10 个特征值,然后在softmax 分类层中将10 个特征值概率归一化得出最大概率值即为分类结果。 网络中的具体参数设置如表1 所示。
由表1 可以计算出,该CNN 网络总共的权重参数量为260+5 020+16 050+510=21 840 个变量。若将这21 840个变量都采用ap_int(16)来存储,将大约消耗43 KB 的存储资源,本文采用的PYNQ-Z2 有足够的存储空间用于存放这些变量。
2 系统设计与实现
本文设计并实现基于PYNQ-Z2 的CNN 通用加速器,采用PYNQ-Z2 的PS 部分做逻辑控制,PL 部分执行卷积神经网络运算。由于全连接运算是特殊的卷积运算,因此依据卷积神经网络的特性设计了两个通用的运算模块,即通用的卷积运算模块和通用的池化运算模块,如图2 所示。

表1 网络参数表
由图2 可以看出,这种加速器框架实现了两种通用的加速电路(即通用的卷积运算电路和通用的池化运算电路),CPU 通过axi_lite 总线对卷积池化电路的参数进行配置,卷积池化电路通过axi_hp 总线对CPU 中存储的特征权重参数进行读取。当存储器中输入一组数据的时,CPU 就会进行参数配置并调用卷积运算模块进行运算, 卷积ReLU 后的结果保存在存储器中再进行参数配置并调用池化运算模块进行运算,可以通过这种循环运算的方式实现卷积神经网络的运算。
2.1 CNN LeNet5 模型训练
本文在TensorFlow 中搭建CNN LeNet5 网络模型并进行训练,训练过程如图3 所示。 其中横坐标轴代表训练次数,纵坐标轴表示每次训练的误差。 设置训练速率为50,训练20 000 次,随着训练次数的不断增多,误差逐渐减小,最后的模型错误率仅为1.58%。
2.2 CNN 加速器的IP 核的设计与实现
Xilinx 推出的HLS[17]工具是基于FPGA 的设计与开发,用户可以选择多种不同的高级语言(如C、C++、System C)来进行FPGA 的设计,在代码生成时可以快速优化FPGA 硬件结构,提高执行效率,降低开发难度。

图1 典型的手写数字识别网络结构
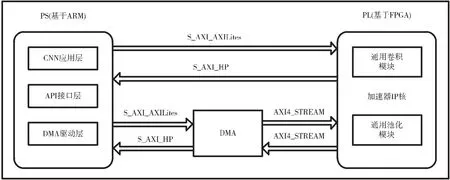
图2 系统硬件原理框图

图3 CNN LeNet5 误差与训练次数的关系
本文通过C 语言描述了两个加速电路,利用HLS 工具生成加速器的IP 核。 系统通过CPU 配置IP 核的参数,采用AXI 的通信方式进行数据传输,输入的数据通过IP 核进行CNN 运算,运算的结果通过AXI 总线输出。图4 是加速器IP 核的原理图。
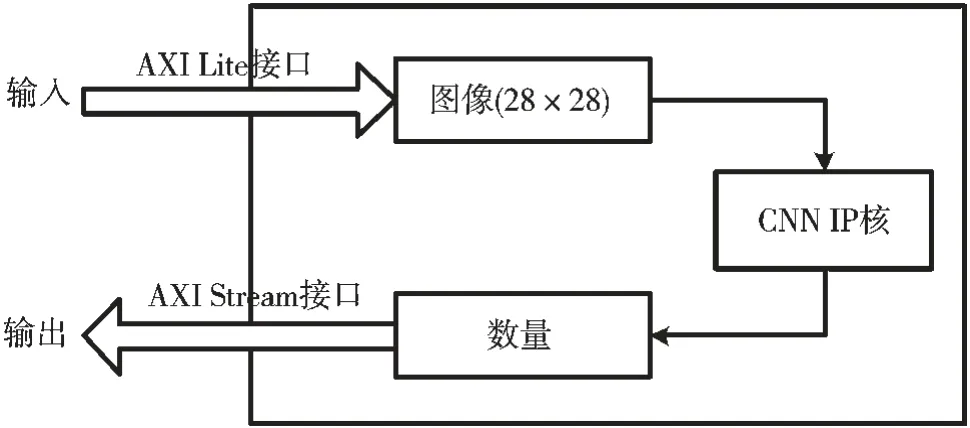
图4 加速器IP 核原理图
2.3 CNN 加速器的IP 核优化
由于特征、权重参数都是多维的空间变量,无法在计算机中读取,因此需要将其展开为一维变量。 如图5 所示,对于特征参数, 它在空间中的排布方式为三维变量,因此需要将其展开为一维变量,考虑到FPGA 的并行计算能力优秀,所以在空间中沿输入特征的通道C 将其切割为C/k 通道,每一个通道可以实现k 路并行的计算且需要的特征存储空间减少,大大提高了加速电路的运算效率,节约了FPGA 的存储资源。 特征参数经过切割后,它在内存中的排布方式变为了一维变量:[C/k][H][W][k]。

图5 卷积运算的矩阵切割
权重参数在空间中的排布方式为四维变量,要将它展开为一维变量,也是对其输入通道CHin 切割为CHin/k通道,实现每一个通道的k 路并行,它在内存中的排布方式变为一维变量:[CHout][ky][kx][CHin/k][k]。
其中k 的取值会对系统性能造成极大的影响,一个合适的k 值可以使得存储资源、计算资源、带宽资源三者达到平衡。 通常k 的取值有8、16、32、64,其不同的取值对应的资源消耗如表2 所示,不同取值对应的计算图片的时间如表3 所示。
通过表2 和表3 的数据对比可以得到,在k=32 时的资源占用较为合理,可以使得系统的性能达到最优,同时权衡了计算时间和数据存储时间,达到了比较好的均衡效果。

表2 不同k 的取值对应的资源消耗
3 实验与结果
3.1 实验测试平台
本实验采用PYNQ-Z2 开发板,其主芯片是XC7Z020,主要由PS 和PL 两部分组成,PS 端是650 MHz 双核Cortex-A9 处 理 器,PL 端 的 时 钟 频 率 为100 MHz。 通 过表3 可以看出,在进行单张图片测试时,CNN IP 核在k=32 时计算图片的时间比PS 端减少了将近39 ms,达到了近6 倍的加速效果。接下来进行多张图片测试来记录加速效果。
3.2 图片流测试
在MNIST 数据集中选取1 000 张图片,分成10 组,每组100 张测试图片,组成图片流,分别送入ARM 层和硬件层的加速器IP 核进行CNN 运算, 并且记录各自所用的时间,从而得到加速器IP 核对图片流的加速效果。实现结果如图6 所示。
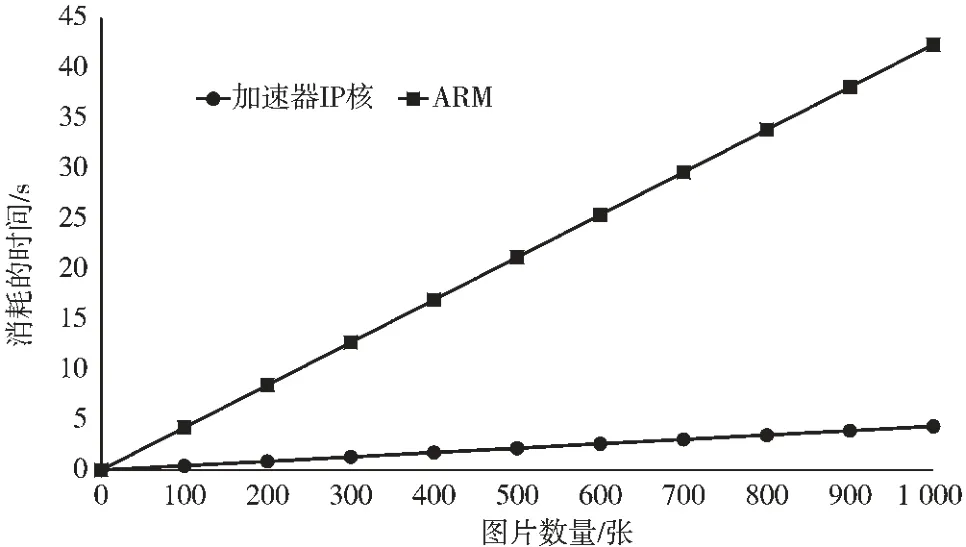
图6 图片流的测试结果
由图6 可以看出,两种不同平台的测试结果都成线性关系,说明每张图片的运算时间都是固定不变的,加速器IP 核处理单张图片的平均时间为4.3 ms, 而ARM平台处理单张图片的平均时间约为42 ms,由此可见,当运算相同数量的图片时,CNN IP 核可将运算速度提高到近10 倍,远远超过了单张图片的加速效果。 当处理1 000 张图片时,加速器IP 核比ARM 端快了38 s 左右,并且随着图片的数量越来越多, 加速器IP 核的性能也将越来越好,加速效果也将越来越显著。
3.3 实验结果比较
本文采用的HLS 工具实现的加速器IP 核与FPGA实现卷积神经网络[18]相比较,比较结果如表4 和表5所示。
通过表5 可以看出,文献[18]中提出的利用FPGA实现CNN 加速器与传统的CPU 相比有很大的加速效果,在处理单张图片时的加速比为4.17,在处理10 000张图片时的加速比为3.43,可见随着处理图片的数量逐渐增加,加速器的效果在不断降低。 本文提出的利用HLS 工具生成的CNN 加速器在处理单张图片时所耗时间为8 ms,加速比为5.875,与传统CPU 相比有很好的加速效果;在处理1 000 张图片时,加速器IP 核耗时4.352 s,通用CPU 耗时42.322 s,此时的加速比为9.72,加速效果越来越明显,并且随着处理的图片数量越来越多,加速效果会越来越好,具有很好的参考意义。
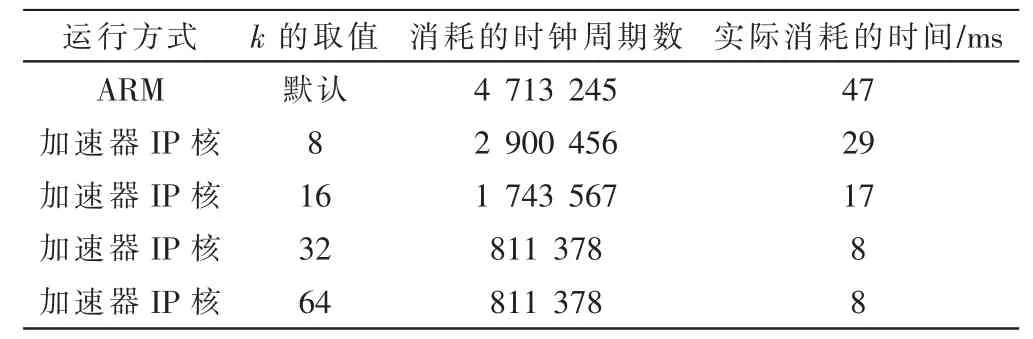
表3 不同k 的取值对应的计算图片的时间

表4 文献[18]与本文实验平台的对比
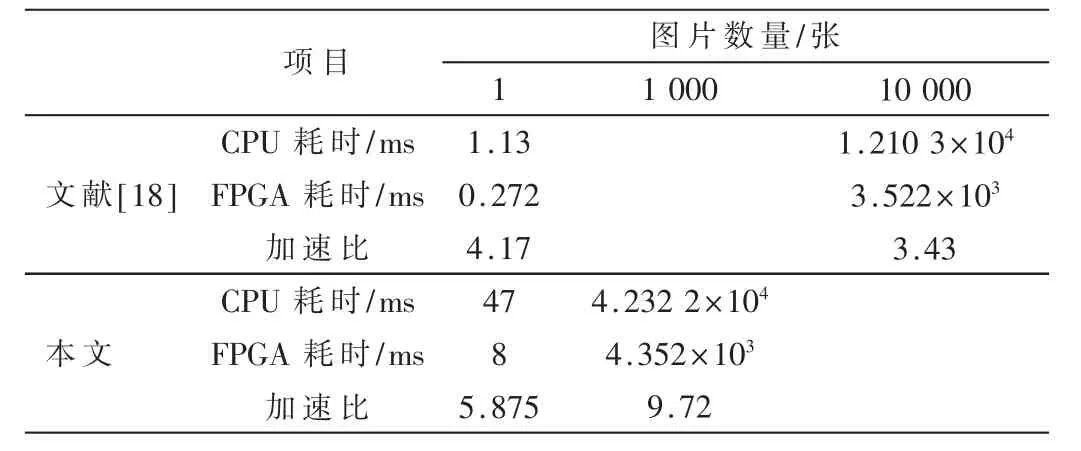
表5 文献[18]与本文对不同数量的图片处理的运算速度的对比
4 结束语
本文在PYNQ-Z2 平台上利用HLS 工具设计了加速器IP 核来进行卷积神经网络运算,并通过矩阵切割的方法对加速器IP 核进行优化,充分利用了FPGA 的并行计算能力。 通过实验证明在k=32 时,均衡了存储资源和计算资源,使得加速器IP 核的性能达到最优,运算速度得到明显的提升。由于本实验采用的开发平台资源有限,若采用资源更多的FPGA 平台进行加速运算,加速器的性能将得到更大的提升。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
少先队活动(2021年6期)2021-07-22
影像视觉(2020年4期)2020-05-09
计算机技术与发展(2019年1期)2019-01-21
印刷技术·数字印艺(2016年11期)2016-12-06
印刷技术·数字印艺(2016年7期)2016-05-14
