
数据挖掘在电信客户流失预警模型中的应用
2021-04-05 03:37杨成义林瑞琼
现代信息科技 2021年17期
杨成义 林瑞琼
摘 要:文章结合了某电信公司系统存储的业务数据,对数据进行清洗和分析,在提取重要特征后,利用了Python所提供的scikit-learn核心算法库,实现了逻辑回归,支持向量机,K近邻等监督学习算法的建模,最后对各个算法的结果进行分析。在实际的商业活动中,企业人员可以综合利用模型中准确率较高的几种算法,制定对应的运营方案和挽回策略,从而有效地减少客户的流失。
关键词:客户流失预警;Python;sklearn;逻辑回归
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)17-0032-03
Abstract: Combined with the business data stored in the system of a telecom company, this paper cleans and analyzes the data. After extracting important features, it uses the scikit-learn core algorithm library provided by Python to realize the modeling of supervised learning algorithms such as logistic regression, support vector machine and k-nearest neighbor. Finally, the results of each algorithm are analyzed. In actual business activities, enterprise personnel can make comprehensive use of several algorithms with high accuracy in the model to formulate corresponding operation schemes and recovery strategies, so as to effectively reduce the loss of customers.
Keywords: customer churn early warning; Python; sklearn; logistic regression
0 引 言
在电信行业中,客户的库存流失包括主动网外流失,被动网外流失和潜在流量流失这三种主要的表现形式。顾客主动要求注销和关闭之前购买过的账户,并将服务转移到其他运营商的损失,称之为主动网外损失,该现象的损失是可衡量的。用户将服务和需求转移到其他网络,终止当前服务之前,必须经过相关的流程或者程序通过才可实现。客户欠费、停机的情况(即没有通过流程的客户)称为被动网外流失。该损失可以衡量,不过这会造成企业的坏账。由于使用意愿的转移和服务次数明显降低,客户虽然目前还是在网络中的,但客户的流量(呼叫使用率)却大大下降,称之为潜在流量损失。这种损失往往是很难去估量的,是因为我们不清楚客户的使用意图发生何种变化。
对客户的流失情况进行分析,其目的是为了挽留可能会流失的用户,提升业务效益。客户流失预警分析,就是使用数据仓库、数据挖掘等综合分析方法,对已经流失的客户在过去一段时间内所拨打的电话、客户服务情况、交费信息等数据进行分析,提取出已经流失或有流失倾向的客户所具有的各种行为特征,建立了客户流失的预警模型,并将该模型广泛地应用于实际的客户服务中,及时预测潜在的可能流失的客户,并提前采取相应的市场营销措施和手段,使客户维持原有的服务。
1 数据分析
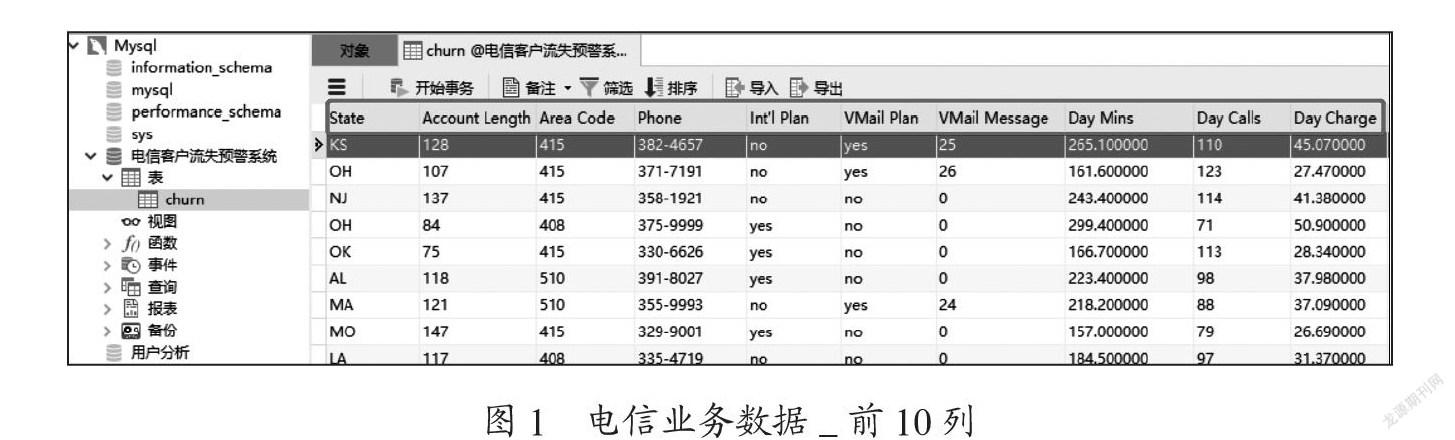
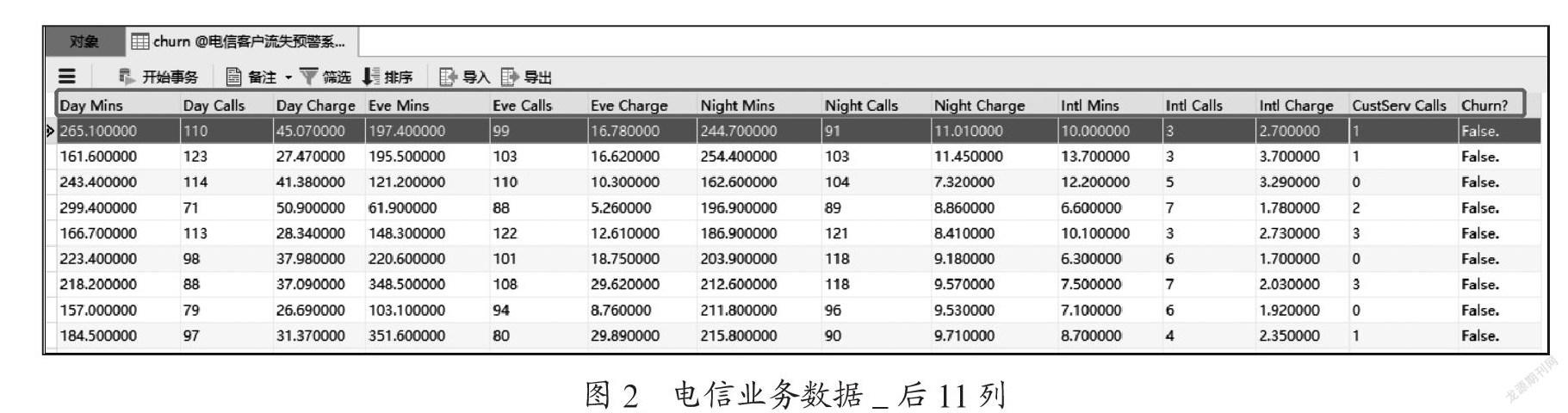
本次建模一共准备了30多份数据,包含了3 000多个用户信息,将其导入Python中用于数据分析的pandas库,进行数据分析和处理。使用pandas库的方法来了解数据的基本情况。数据库中存储的电信业务数据如图1、2所示,图1展示了前10列数据。图2则展示后11列数据,通过两图可以得知,收集的dataset总共包含21个属性。
在图1、图2中,所选中的数据含义分别是:State:地区名缩写;Account Length:账户长度为128;Area Code:区号值为415;Phone:电话号码为382-4657;Int'l Plan:国际漫游需求与否为no,说明该客户没有国际漫游的需求;Mail Plan:參与活动为yes,说明有参加活动;Mail Message:语音邮箱信息数量是25;Day Mins:白天通话分钟数265.1分钟;Day Calls:白天打电话个数为110;Day Charge:白天收费情况是45.07;Eve Mins:晚间通话分钟数197.4分钟;Eve Calls:晚间打电话个数为99个;Eve Charge:晚间收费情况是16.7;Night Mins:夜间通话分钟数是244.7分钟;Night Calls:夜间打电话个数是91个;Night Charge:夜间收费是11.01;lntl Mins:国际通话分钟数为10分钟;lntl Calls:国际打电话个数是3个;lntl Charge:国际收费是2.7;CustServ Calls:客服收到的电话数量为1个;最后是属性Churn:流失与否,为False,即该客户没有流失。
2 特征提取
针对数据之间的关系属性,使用matplotlib和seaborn这两个库进行数据的可视化。
查看VMail Message的分布,语音邮箱个数集中在1个。查看Intl Calls和Churn的关系,流失用户的白天电话个数平均值要比没有流失的用户高:
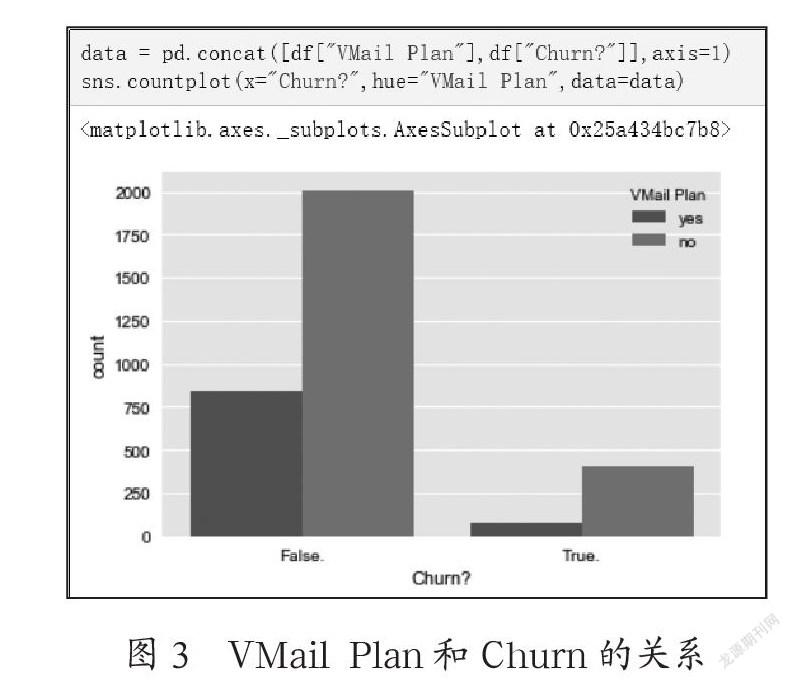
(1)用柱状条形图查看VMail Plan和Churn的关系,如图3所示。以客户是否参与活动的比例来比较,流失用户中没有参与活动的比例是远远高于忠实用户的。
(2)查看Churn与CustServ Calls的关系,如图4所示。客户忠诚度最高的是只拨打1次客服电话,但是随着拨打次数的增加,用户流失的比例也随着增加,拨打3个或3个以上电话的用户基本处于流失状态。通过子图查同一类型的数据分布可以知道:白天通话的分钟数、打电话个数和最终收费趋势都呈正态分布,这是符合实际情况的,数据没有其他异常情况。
(3)用热力图查看各个特征属性之间的关系:用正数代表两个维度是正相关的,负数代表两个维度之间是负相关的。从而获得与流失率相关性最高的10个特征属性,如图5所示。
3 建模及结果分析
重新编码,将这Int'l Plan和VMail Plan这两列object类型编码为数值类型,方便后面的建模。删除掉三个无关属性列:地区名、电话、区号。在训练模型之前采用as_matrix()方法对数据进行统一的数组转换,然后实现scale,去除量纲的影响。使用model_selectiond的train_test_split方法把数据集划分为训练集和测试集,进行模型验证。将常见的10种监督学习算法来训练本次的数据:
#依次为模型命名
classifier_Names = ['AdaBoost', 'Bagging', 'ExtraTrees', 'GradientBoosting', 'RandomForest', 'GaussianProcess', 'PassiveAggressive', 'Ridge', 'SGD', 'KNeighbors', 'GaussianNB', 'MLP'DecisionTree', 'ExtraTree', 'svc', 'LinearSVC']
print("定义完成")
#然后,划分数据集,70%用于训练,另外30%用于测试。
#导入数据集切分模块
from sklearn.model_selection import train_test_split
#切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=.3)
#准备好数据之后,开始模型训练和测试。
from sklearn.metrics import accuracy_score#导入准确度评估模块
#遍历所有模型
for name, model in zip(classifier_Names, models) :
model.fit(X_train, y_train)#训练模型
pre_labels = model.predict(x_test)#模型预测
score = accuracy_score(y_test, pre_labels)#计算预测准确度
print('%s : %.2f'%(name, score))#输出模型准确度
各个监督学习算法在本次客户流失预警系统的准确率分别是为:AdaBoost算法:0.86;Bagging算法:0.94;ExtraTrees算法:0.91;GradientBoosting算法:0.94;RandomForest算法:0.94;GaussianProcess算法:0.90,PassiveAggressive算法:0.79,Ridge算法:0.87,SGD算法:0.80,KNeighbors算法:0.90;GaussianNB算法:0.85;MLP算法:0.92;DecisionTree算法:0.92;ExtraTree算法:0.86;SVC算法:0.93;LinearSVC算法:0.87;最高的为Bagging算法,GradientBoosting算法,RandomForest算法,三者准确率均为94%,而准确率最差的是PassiveAggressive算法,只有79%。
这十几个分类器最终的准确度均在70%~90%之间,差距不是很大。出现这样的情况,主要原因有两个。首先,本次建模使用的是一个非常规范、整洁的线性分类的数据集。其次,所有的分类器均采用了默认参数,而scikit-learn 提供的默认参数已经较优,因此不能使用这个准确度结果,来简单断定哪种分类器的性能更优,具体的分类效果表现还取决于参数的选择,比如在支持向量机的算法中,如将gamma系数调整一下,预测结果会大大改变。
4 结 论
本次电信业务样本数据中,注册客户数量占市场份额大约为75.5%,这就意味着用于预测“忠实客户”的模型,必须超过75.5%的准确度,并能进行精确定位。在本次建模中,各算法的计算准确率均不低于此數值,且有多个算法准确度显著高于该数值。所应用的scikit-learn 中常见的多种监督学习方法,从结果上看,不同方法之间有一定的差别。虽然对于不同应用环境中分布的数据,模型的适用情况具有差异性。但在大多数线性分类中,模型的表现和适用性都较好。因此,在电信行业中,可以收集客户的个人信息,将客户的重要特征信息“喂”给模型中准确率较高的几种算法,在进行综合分析的基础上,可以准确预测客户是否会流失,针对可能的流失客户,企业营销人员可以提前制定相应的挽留策略,来避免损失。
参考文献:
[1] 王仁武.Python与数据科学 [M].上海:华东师范大学出版社,2016.
[2] 莫凡.机器学习算法的数学解析与Python实现 [M].北京:机械工业出版社,2020.
[3] 邓立国.Python机器学习算法与应用 [M].北京:清华大学出版社,2020.
[4] 邝涛,张倩.改进支持向量机在电信客户流失预测的应用 [J].计算机仿真,2011,28(7):329-332.
[5] 刘晨晨.基于数据挖掘的通信客户流失预警模型研究 [D].武汉:华中师范大学,2017.
作者简介:杨成义(1985.09—),男,汉族,湖北孝感人,讲师,硕士研究生,研究方向:群决策支持系统;林瑞琼(1997.08—),女,汉族,广东揭阳人,本科,研究方向:软件工程。
