
基于Stacking模型融合的用户购买行为预测研究
2021-04-06 03:41张建彬霍佳震
上海管理科学 2021年1期
关键词:机器学习
张建彬 霍佳震


摘 要: 在大数据时代背景下,如何利用大量的销售数据精准预测顾客未来需求,成为企业制定客户管理和库存管理决策的一个重要问题。目前关于用户购买行为预测的研究中很少能够预测用户具体的购买时间。基于已有的销售数据,提出了基于机器学习和Stacking集成的综合预测模型预测用户的购买行为,即未来是否购买及其购买时间。将模型应用在一家大型连锁零售企业的需求预测中,并对方法的有效性进行评估。结果表明,基于Stacking集成的融合模型对预测用户未来是否购买具有最佳性能,准确率达85%,AUC值达到0.928; LightGBM集成算法在预测用户购买时间时具有最优性能,相比于融合模型提升了5.5%的预测性能;融合模型+LightGBM算法的组合相比于均使用融合模型提升了9.4%的预测性能。
关键词: 组合预测;机器学习;购买行为预测;LightGBM算法;Stacking集成
Abstract: In the era of the big data, how to use a large amount of sales data to accurately predict customers' future demand is an important issue for companies to make customer management and inventory management decisions. Currently,few studies on the prediction of consumers purchase behavior can predict the specific purchase time. Based on the existing sales data, this paper proposes a comprehensive prediction model based on the integration of machine learning and Stacking to predict future purchase behavior of consumers. We applied the model to the demand forecast of a large retail chain and evaluated the effectiveness of the method. The results show that the fusion model based on Stacking has the best performance for predicting whether consumers will purchase in the future, and the accuracy rate is 85%, the AUC value is 0.928; the LightGBM integrated algorithm has the best performance in predicting the consumer purchase time, which improves the prediction performance by 5.5% compared with the fusion model; the combination of the fusion model + LightGBM algorithm improves the prediction performance by 9.4% compared with that applying the fusion models in predicting both whether to buy and when to buy.
Key words: combination forecast; machine learning; purchase behavior prediction; LightGBM algorithm; Stacking integration
在企业客户管理中,要求企业对投资支出的成本和收益進行评估,并在一段时间内为营销和销售活动确定最优的资源配置。因此,了解顾客在未来一段时间内的购买行为是销售和市场部门有效分配资源的关键驱动力之一(Allenby, Leone & Jen, 1999)。同时,这些信息在制定仓库(或销售点)的库存计划,以及制造商制定生产计划时也至关重要。
目前预测用户购买行为的研究主要集中在预测用户是否购买(Martínez,et al., 2018;Liu et al., 2019),很少研究用户具体的购买时间。本文提出一种使用Stacking方法融合多种决策树模型的组合预测模型来预测用户未来是否购买和其具体的购买时间。该模型采用Stacking模型融合的思想将LightGBM、XGBoost、随机森林三种不同的集成决策树模型的预测结果进行融合,然后基于融合的预测结果使用简单的逻辑回归分类模型和线性回归模型分别预测用户未来是否购买和具体的购买时间。此外,在本研究中,我们使用真实的零售企业销售数据对所提出方法的预测性能进行了评估。
1 文献综述
用户购买行为预测在很早的时候便引起学者们的关注(Herniter, 1973),但是由于过去历史数据的缺乏导致这方面的研究长期停滞不前。用户购买行为预测中最具挑战的问题是当用户的当前状态无法直接观察,同时可用的历史记录非常少的情况下,对用户购买行为的预测(Platzer et al. 2016)。在过去的几年中,信息技术的飞跃发展使得用户交易数据的可用性极大增加(Wu et al., 2013)。这些用户交易数据的初始分析通常以汇总统计的形式进行,例如平均订单数量或订单平均订购量,以及与用户行为有关的信息特征等。
在数据可用性极大增加的情况下,机器学习和数据挖掘技术经常被用于基于用户的预测中,而用户流失预测是该领域中的重要问题之一。近年来,用户流失的概念和相关的预测分析已得到了很好的研究(Richter et al., 2010; Lin et al., 2011; Amin et al., 2017)。准确地预测用户购买行为能够为企业制定库存和销售计划提供依据,从而减少销售损失和不必要的库存成本。因此,近年来有不少研究关注于预测用户的未来购买行为。Martínez等(2018)提出了一个动态的、数据驱动的框架,用于预测非合同环境下用户是否打算在不久的将来在公司内进行购买。Liu等(2019) 根据给定的用户购买历史记录,通过非参数贝叶斯模型预测用户的下一次购买。
上述对未来用户购买行为预测的研究中,仅关注于未来一段时间内用户是否会购买,而并没有预测用户具体的购买时间。因此,本文将在预测未来一段时间内用户是否会购买的基础上,进一步预测会购买用户的具体购买时间。
可用于购买行为预测的方法有许多,具体包括时间序列分析、面板数据模型、基于机器学习的模型和随机模型(例如BG/ NBD模型)。时间序列分析包括诸多不同的方法,例如指数平滑法(Hussain et al.,2012; Tratar et al.,2016)、移动平均法(Lee and Fambro,1999)、自回归集成移动平均(ARIMA)模型(Ramos et al.,2015; Amini et al.,2016)等。对于这些方法的研究较为成熟,但是这些方法没有纳入足够的因素,或者没有考虑到个人的影响。面板数据(Ren et al.,2014)和随机数据模型(Fader &Hardie,2002)比时间序列分析包含更多的因素,目前已成功应用在各种与预测有关的业务场景中。另一方面,基于机器学习的模型则可以考虑更多的因素,可考虑更多的变量(Choi et al., 2014)。
随着数据可获得性的提高,越来越多研究基于机器学习的预测模型来预测用户的未来购买行为。这些基于机器学习的预测方法主要包括逻辑回归(Martínez et al., 2018)、支持向量机(Lu et al., 2014; Candelieri, 2017)、人工神经网络(Günay,2016; Chawla et al.,2019)、梯度提升决策树(GBDT)(Martínez et al., 2018)等。Lu等(2014)基于特征变量选择,采用支持向量机回归的方法构建了针对计算机产品的混合预测模型,结果表明对于计算机这类具有高度可替代性的产品,该预测模型具有良好的预测性能,能够为销售管理提供更多有用的信息。另外,Martínez等(2018)提出了一个动态的、数据驱动的框架,比较了逻辑回归、神经网络、梯度提升决策树(GBDT)三种机器学习算法的预测性能,结果表明梯度提升决策树具有最佳的预测性能。这些研究大多使用单一的预测模型,通过将多种不同的单一模型进行比较,从而发现表现性能较好的一种或几种预测方法。
采用单一的预测模型虽然研究方法相对成熟,但容易受到其他一些随机因素的影响,导致预测准确率不太高,且模型一般仅适用于特定环境,泛化能力不够强。因此,为了有效减少或者抵消单个模型中的随机因素的影响、提高预测模型的预测精度和可信度,一些学者使用不同的组合模型来解决预测问题(汪同三与张涛,2008)。倪冬梅等(2013)基于对需求影响因素分析建立了基于ARIMA 的时间序列和多元回归相结合的综合需求预测模型,并将该综合预测模型与库存决策相结合,构建了需求预测与库存决策集成模型。结果表明,综合预测模型的预测精度高于单阶段模型; 需求预测与库存决策集成模型的成本远低于非集成模型。Fan等(2017)利用汽车行业历史销售数据和在线评论数据,采用Bass模型和情感分析相结合的方法对汽车需求进行预测。结果表明,相比于标准的Bass模型和其他销售预测模型,组合模型具有更高的预测精度。
由以上研究可以发现,在大多数情况下组合预测模型相比于单一的预测模型具有更好的预测性能。因此,本文在上述研究的基础上,将前沿机器学习技术XGBoost算法、LightGBM算法、随机森林算法与Stacking集成学习方式有效结合,提出一种基于多个差异化模型的组合预测模型来预测用户未来的购买行为。
2 研究方法
本文提出了基于Stacking融合模型的用户购买行为预测方法。图1描述了整个方法的总体框架。
首先,采用所有用户的原始数据集来分别预测用户是否购买和用户的购买时间。使用完整的数据进行两个方面内容的预测能够保证数据的一致性,同时使得模型能够最大可能地利用数据,从而提升模型整体的预测性能。
其中,用户是否购买预测的目标为使用分类模型预测下一段时间内用户是否购买目标商品,即得到会购买目标商品的用户用户集。具体如下:首先收集所需的数据,同时进行分析和处理,得到噪声较少以及更加结构化的数据集。其次,根据用户购买行为分析进行特征选择和特征构建,得到较高维度的特征数据集。然后,将特征数据集输入Stacking分类融合模型中进行有效的训练。最后,即訓练得到的分类融合模型进行样本外预测,得到预测结果1,即预测得到未来一段时间内将会购买目标商品的用户集。
用户购买时间预测的目标为使用回归模型预测下一段时间内每个用户具体的购买时间。这一步骤与用户是否购买预测的步骤类似,即先进行数据收集和处理,接着进行特征选择和特征构建,然后使用Stacking回归融合模型进行训练,最后对训练得到的回归融合模型进行样本外预测,得到预测结果2,即预测得到未来一段时间内所有用户的购买时间。
本文的最终目标是预测得到下一段时间内会购买目标商品用户的具体购买时间。因此,将预测结果1和预测结果2进行整合,得到最终的预测结果,即预测得到未来一段时间内将会购买目标商品的用户及其具体的购买时间。
2.1 数据收集和处理
在本研究中,我们主要收集了某个零售商的历史销售数据。我们为每条数据提取了以下属性:会员编码、订单编码、购买时间、购买数量、购买价格、花费、产品容量和产品品类。这些属性如表1所示。
收集到的历史销售数据包括会员和非会员的购买记录,会员具有唯一标识Vipcode,非会员Vipcode属性值为空值,因此我们删除了Vipcode属性值为空值的所有记录。同时,Number属性值一般来说为正整数,但在收集到的销售数据中存在Number属性值等于0或小于0的现象。经过分析得知小于0的为退货数据,等于0的为进行促销时的赠品数据。因此,为避免这些噪声数据对预测结果产生影响,我们将Number属性值小于0的数据与顾客对应的购买数据进行抵消,同时删去所有Number属性值为0的数据,从而保证所有Number属性值大于0。最后,我们进行了空值和重复值的处理工作。
2.2 特征工程
在研究中,为了有效地扩大样本数据量,使预测模型的训练尽可能覆盖所有历史数据,我们使用了时间滑窗方法进行特征提取。时间滑窗如图2所示。
如图2所示,每组数据长度为5个月,其中最后一个月为标签月,前四个月用于提取特征,每次滑动长度为一个月。特征时间窗又分为五个特征提取窗口,分别为距离标签月首日7天、14天、1个月、2个月、4个月。然后,分别统计分析这五个窗口内的特征。
在用户购买行为预测的研究中,影响预测准确性的主要因素包括用户因素(徐琪等,2014;马云高等,2012)和产品因素(Arunraj et al.,2015)。在对销售数据进行充分分析之后,我们基于用户购买行为习惯和产品属性等因素从小的特征提取窗口中提取出了用户特征和商品特征,如表2所示。
除此之外,考虑到数据的全局性以及产品的消耗率相对固定等特点,我们还在最大的时间窗口内提取出了以下用户特征,如表3所示。
2.3 应用模型
本文采用多种机器学习分类和回归算法,包括LightGBM算法(Ke, Meng & Finley, 2017)、XGBoost算法(Chen & Guestrin, 2016)、随机森林算法(Liaw & Wiener, 2002)、逻辑回归算法、Lasso回归算法,其中前三种算法是集成模型,后两种为简单模型。前三种算法用于与融合模型比较预测性能,同时也是融合模型的基学习器,而后两种算法仅作为融合模型的元学习器。
2.3.1 LightGBM算法
LightGBM(Light Gradient Boosting Machine)是一款基于决策树算法的分布式梯度提升框架。它的优点在于减少了数据对内存的使用,保证单个机器在不牺牲速度的情况下,尽可能地使用更多的数据;同时减少通信的代价,提升多机并行时的效率,实现在计算上的线性加速。
2.3.2 XGBoost算法
XGBoost(eXtreme Gradient Boosting)与LightGBM都是基于决策树的算法。它的优点在于使用许多策略去防止过度拟合,同时支持并行化,添加了对稀疏数据的处理,训练速度快,训练结果精度高。
2.3.3 随机森林算法
随机森林(Random Forest)是指利用多棵决策树对样本进行训练并预测的一种算法。随机森林算法是一个包含多个决策树的算法,其输出的类别是由个别决策树输出类别的众树来决定的。
它的优点在于对于大部分的数据,它的分类效果比较好;它能处理高维特征,不容易产生过度拟合,模型训练速度比较快,特别是对于大数据而言;在决定类别时,它可以评估变数的重要性;它对数据集的适应能力强,既能处理离散型数据,也能处理连续型数据,数据集无需特意规范化。
2.3.4 逻辑回归算法
逻辑回归(Logistic regression)是一种与线性回归非常类似的算法。从本质上讲,线型回归处理的问题类型与逻辑回归不一致。线性回归处理的是数值问题,而逻辑回归属于分类算法。也就是说,逻辑回归预测结果是离散的分类,例如判断一封邮件是否是垃圾邮件等,所以逻辑回归是一种经典的二分类算法。逻辑回归是在线性回归的计算结果加上了一个Sigmoid函数,将数值结果转化为0~1的概率,然后根据这个概率做预测,例如概率大于0.5,则这封邮件就是垃圾邮件。
2.3.5 Lasso回归算法
Lasso回归和岭回归(Ridge regression)都是广义线性回归模型的一种。Lasso回归与岭回归都属于后验概率模型。
2.4 Stacking模型融合
Stacking模型融合方法(Ting & Witten,1997)首先将原始特征数据集划分成若干子数据集,输入第1层预测模型的各个基学习器中,每个基学习器输出各自的预测结果。然后,第1层的输出再作为第2层的输入,对第2层预测模型的元学习器进行训练,再由位于第2層的模型输出最终预测结果。Stacking模型融合方法可以通过对多个模型的输出结果进行泛化,提升整体预测精度。
在本研究中,我们使用LightGBM、XGBoost、随机森林三种不同的集成模型算法作为基学习器得到三组预测结果,然后将三组预测结果应用在第二层使用元学习器,包括逻辑回归或Lasso回归进行训练,从而得到最终的预测结果,如图3和图4所示。其中,用户是否购买和用户购买时间预测所用的Stacking模型融合方法步骤大致相同,不同的是用户是否购买的基学习器使用的是三种集成算法中的分类算法,元学习器使用的是逻辑回归分类算法,而用户购买时间预测的基学习器使用的是三种集成算法中的回归算法,元学习器使用的是Lasso回归算法。
3 实证分析
3.1 数据
本文以一家连锁零售企业洗衣用品的POS机销售数据作为实证样本,其中以品类105(洗衣皂)为目标商品进行用户未来是否购买和具体购买时间的预测。
本文的数据集包括从2011年4月1日到10月31日的7个月内8种洗衣用品每天的销售数量、价格、花费及产品容量等。考虑到数据集数据量比较小,为了有效扩大样本数据量,使预测模型的训练尽可能覆盖所有历史数据,我们使用了时间滑窗方法进行特征提取。进行原始数据处理后,我们设置最大时间窗口为120天,特征提取窗口分别为7天、14天、30天、60天和120天。由于用户每次商品的购买时间间隔集中在15~30天,因此设置每隔15天滑动窗口一次,具体如图5所示。确定时间窗口后,我们提取出了包括159个维度的特征向量。
图5中,时间窗左侧的25701等数字表示当前数据组满足4个月内购买过产品的会员用户数,目的是保证用户在前4个月的特征提取窗口内有过购买行为,即能提取出有效的用户特征。其中,前四组作为训练集,第五组(十月份组)作为测试集用于检验模型性能。
3.2 模型性能评估
本文进行了用户未来是否购买和购买时间预测问题的研究,本节分别使用机器学习中常用的分类问题和回归问题评估指标来评估预测模型的性能。为了使模型具有一定的可解释性,我们还分析了预测性能较优的若干个模型的特征重要性结果。
3.2.1 购买行为预测模型性能评估
预测用户未来是否购买是一个典型的二分类问题,因此我们使用二分类问题中常用的评估指标,包括准确率、精确率、召回率、Auc值以及Roc曲线来评估模型性能。同时,我们将Stacking融合模型和单个的基学习器和元学习器模型结果进行了比较,在测试集上的评估结果如表4所示。
如表4所示,逻辑回归算法的表现最差,原因是逻辑回归这样的线性分类模型不适用于本研究中的非线性问题,它无法处理复杂的非线性分类问题。在三个单一的集成模型中,随机森林结果表现最差,所有评估指标结果均低于其他两个模型。而LightGBM的评估指标中次优结果有三个,说明其具有较好的预测性能。比较除逻辑回归外的其他四个模型的结果,可以发现融合模型的准确率和精确率以及Auc值都达到最优,这说明使用Stacking模型融合的方法对于预测用户购买行为具有很好的预测性能。
融合模型的Roc曲线如图6所示,曲线非常靠近y轴以及y=1,同时曲线下方面积即auc值达到0.928以上。这也说明融合模型对于用户购买行为具有很好的预测性能。
3.2.2 购买时间预测模型性能评估
预测用户的购买时间是一个回归问题,我们使用回归问题常用的三个指标均方误差(MSE)、平均绝对误差(MAE)以及解释方差(explained_variance_score,EVS)来评估模型性能。同时,我们将Stacking融合模型和单个的基学习器和元学习器模型结果进行了比较,在测试集上的评估结果如表5所示。
如表5所示,線性回归模型Lasso回归表现最差,同样说明Lasso回归这样的线性回归模型不适用于本研究中的非线性问题,它无法有效处理复杂的非线性回归问题。在其他四个非线性模型中,LightGBM的预测性能最优,其中MSE和EVS值为最优,MAE值次优。融合模型的三个评估指标结果有两个为次优且与最优结果差距不大。这说明在解决购买时间的预测问题上,LightGBM模型是最优的,其次是融合模型。
3.2.3 特征重要性分析
特征重要性分析可以用来评估构建的特征的预测能力或对预测模型的重要性。通过特征重要性分析,可以很直接地观测到所构建的特征的预测能力,从而在一定程度上解释模型或进一步调整模型结构。在这里我们主要考虑那些表现较好的模型的特征重要性,即用户是否购买考虑融合模型,用户购买时间预测考虑LightGBM模型。
用户是否购买融合模型特征重要性前20名如图7所示。
用户购买时间预测 LightGBM模型重要性前20位的特征如图8所示。
图7和图8中120day_105_Gap_max为特征名称,120day表示特征提取窗口为120天;105表示目标商品,若无105则表示全部洗衣商品;Gap表示购买时间间隔;max为统计方式为最大值,包括max(最大值)、min(最小值)、mean(平均值)、median(中位数)、std(标准差)。因此,120day_105_Gap_max表示目标商品(105)在120天内的最大购买时间间隔。
如图7所示,用户是否购买排名前20的特征中,购买时间间隔四个特征有三个排在前三位,另一个标准差特征也在前20中,同时前10中有7个特征与目标商品消耗率或购买时间间隔有关,这说明用户购买目标商品具有一定的周期性。另外,前20特征中还出现了60天内的平均价格和最小价格特征,这说明商品的近期价格在一定程度上也会影响用户的购买行为。此外,与目标商品相关的其他商品的一些特征也会影响购买行为,如所有商品总花费、所有商品的首次购买时间和最后一次购买时间等特征均在前20内。
如图8所示,用户购买时间预测 LightGBM模型特征重要性与图7类似。前20中包括了购买时间间隔相关特征、价格相关特征、总花费相关特征等,这说明用户购买具有一定的规律性,同时也会考虑用户自身的支付能力以及商品的价格。
3.2.4 综合预测性能评估
我们构造了如式(1)所示的综合评估函数,用来评估各种模型组合的综合预测性能。
其中,Kr为实际购买目标商品的用户集,Kp为预测的购买目标商品的用户集,dk表示实际购买时间与预测购买时间之间的距离。
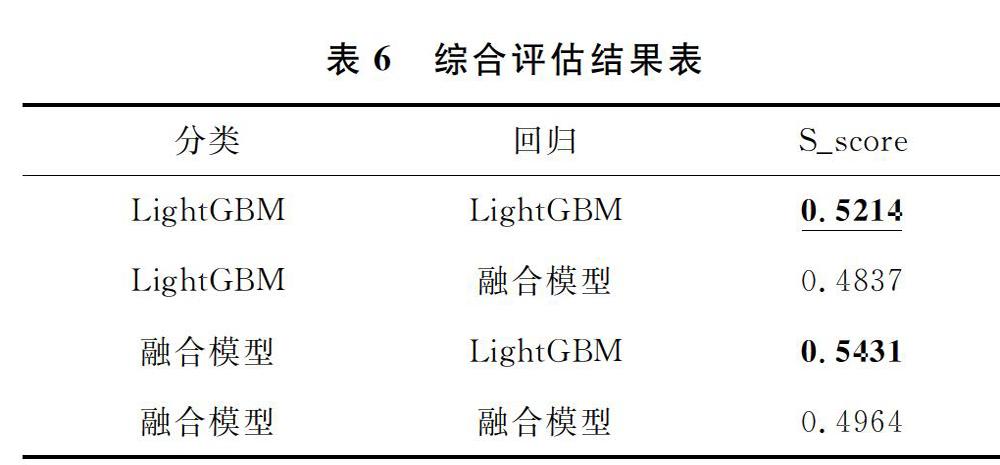
如前所述,LightGBM模型和融合模型都具有较好的预测性能,因此我们使用这两个模型的四种组合来评估综合预测性能,结果如表6所示。
如表6所示,用戶是否购买预测使用融合模型,用户购买时间预测使用LightGBM模型的综合预测性能最优。此模型组合方式相比于两个预测问题均使用融合模型提升了9.4%的预测性能。
4 结语
预测用户未来购买行为和购买时间可以为企业的库存决策和用户营销管理提供支持。尽管已有的研究已经从不同角度进行了研究,但大多研究仅关注于未来一段时间用户是否会购买,而对于用户具体购买时间的研究较少。本文提出一种使用Stacking方法融合多种决策树模型的组合预测模型来预测用户的购买行为及其具体的购买时间。为此,我们将LightGBM、XGBoost、随机森林三种不同的集成决策树模型的预测结果进行融合,然后基于融合的预测结果使用简单的逻辑回归分类模型和线性回归模型分别预测用户的购买行为和具体的购买时间。最后,我们使用了真实的零售企业销售数据来验证评估本文的模型。结果表明,融合模型在预测用户是否购买时具有最高的准确率和AUC值,准确率达85%、AUC值达到0.928。另外,在预测用户具体的购买时间时,我们还发现LightGBM算法相比于融合模型具有最优预测性能。同时,如果在不同问题阶段使用融合模型和LightGBM算法,则融合模型+LightGBM算法的组合相比于两个预测问题均使用融合模型提升了9.4%的预测性能。
一条完整的用户购买记录包括购买时间、购买数量、购买花费等属性值,因此未来可能的研究方向是对未来购买的实际数量或价值的预测。基于相同的特征处理方式训练预测模型,构建预测模型对用户的购买数量和购买价值进行预测是未来一个重要的研究课题,可以为企业的运营和战略决策提供更有利的支持。
参考文献:
[1] ALLENBY G M, LEONE R P, JEN L. A dynamic model of purchase timing with application to direct marketing[J]. Journal of the American Statistical Association, 1999, 94(446): 365-374.
[2] MARTNEZ A, SCHMUCK C, PEREVERZYEV JR S, et al. A machine learning framework for customer purchase prediction in the non-contractual setting[J]. European Journal of Operational Research, 2018.
[3] LIU Y, ZHU T, JIANG Y. Purchase Prediction Based on a Non-parametric Bayesian Method[C] //Proceedings of the 52nd Hawaii International Conference on System Sciences. 2019.
[4] HERNITER J D. An entropy model of brand purchase behavior[J]. Journal of Marketing Research, 1973, 10(4): 361-375.
[5] PLATZER M, REUTTERER T. Ticking away the moments: timing regularity helps to better predict customer activity[J]. Marketing Science, 2016, 35(5): 779-799.
[6] WU X, ZHU X, WU G Q, et al. Data mining with big data[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 26(1): 97-107.
[7] RICHTER Y, YOM-TOV E, SLONIM N. Predicting customer churn in mobile networks through analysis of social groups[C]//Proceedings of the 2010 SIAM international conference on data mining. Society for Industrial and Applied Mathematics, 2010: 732-741.
[8] LIN C S, TZENG G H, CHIN Y C. Combined rough set theory and flow network graph to predict customer churn in credit card accounts[J]. Expert Systems with Applications, 2011, 38(1): 8-15.
[9] AMIN A, ANWAR S, ADNAN A, et al. Customer churn prediction in the tele communication sector using a rough set approach[J]. Neurocomputing, 2017(237): 242-254.
[10] HUSSAIN M, SHOME A, LEE D M. Impact of forecasting methods on variance ratio in order-up-to level policy[J]. The International Journal of Advanced Manufacturing Technology, 2012, 59(1/2/3/4): 413-420.
[11] TRATAR L F, MOJKERC B, TOMAN A. Demand forecasting with four-parameter exponential smoothing[J]. International Journal of Production Economics, 2016(181): 162-173.
[12] LEE S, FAMBRO D B. Application of subset autoregressive integrated moving average model for short-term freeway traffic volume forecasting[J]. Transportation Research Record, 1999, 1678(1): 179-188.
[13] RAMOS P, SANTOS N, REBELO R. Performance of state space and ARIMA models for consumer retail sales forecasting[J]. Robotics and Computer-integrated Manufacturing, 2015(34): 151-163.
[14] AMINI M H, KARGARIAN A, KARABASOGLU O. ARIMA-based decoupled time series forecasting of electric vehicle charging demand for stochastic power system operation[J]. Electric Power Systems Research, 2016(140): 378-390.
[15] REN S, CHOI T M, LIU N. Fashion sales forecasting with a panel data-based particle-filter model[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2014, 45(3): 411-421.
[16] FADER P S, HARDIE B G S. A note on an integrated model of customer buying behavior[J]. European Journal of Operational Research, 2002, 139(3): 682-687.
[17] CHOI T M, HUI C L, LIU N, et al. Fast fashion sales forecasting with limited data and time[J]. Decision Support Systems, 2014(59): 84-92.
[18] LU C J. Sales forecasting of computer products based on variable selection scheme and support vector regression[J]. Neurocomputing, 2014(128): 491-499.
[19] CANDELIERI A. Clustering and support vector regression for water demand forecasting and anomaly detection[J]. Water, 2017, 9(3): 224.
[20] GNAY M E. Forecasting annual gross electricity demand by artificial neural networks using predicted values of socio-economic indicators and climatic conditions: case of Turkey[J]. Energy Policy, 2016(90): 92-101.
[21] CHAWLA A, SINGH A, LAMBA A, et al. Demand forecasting using artificial neural networks: a case study of american retail corporation[M]//Applications of Artificial Intelligence Techniques in Engineering. Berlin: Springer, 2019: 79-89.
[22] 汪同三,張涛.组合预测:理论、方法及应用[M].北京:社会科学文献出版社,2008.
[23] 倪冬梅, 赵秋红, 李海滨. 需求预测综合模型及其与库存决策的集成研究[J]. 管理科学学报, 2013, 16(9): 44-52.
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
