
UNET与FPN相结合的遥感图像语义分割
2021-04-10 05:51任洪娥
液晶与显示 2021年3期
王 曦, 于 鸣,2*, 任洪娥,2*
(1. 东北林业大学 信息与计算机工程学院, 黑龙江 哈尔滨150040;2. 黑龙江省林业智能装备工程研究中心, 黑龙江 哈尔滨 150040)
1 引 言
卷积神经网络(Convolution Neural Networks,CNN)[1]以其局部权值共享的特殊结构以及良好的容错能力、并行处理能力和自学习能力被广泛应用于语义分割[2]、对象检测[3]、人脸识别[4]、图像分类[5]等诸多计算机视觉领域[6]。以图像语义分割为例,Long J和Shelhamer E首次将CNN引入了图像语义分割问题,提出了著名的FCN[7]结构。FCN将深度学习扩展到语义分割领域。FCN在提取特征方面与CNN基本一致。不同的是,FCN为每一个像素分配一个值,用于表示该像素属于特定类别的概率。相比使用手工设计的特征描对图像进行编码,通过反卷积实现上采样将CNN获取的编码恢复到原有图像尺寸,采用端到端的训练方式,简化了语义分割问题过程,得到了更优的准确率。Ronneberger O和Fischer P等人在FCN[8]基础上提出了UNET结构,使用了编码器解码器结构并加入了横向连接,f反卷积使得从图像特征编码到最后的预测结果更加平滑,横向连接为解码器增加了来自浅层具有局部信息的特征,丰富了解码器阶段包含的信息,进一步提升了效果。Chen L C和Papandreou G提出了DeepLab V3模型,在模型中对空间金字塔池化模块(ASPP)进一步改进,使用具有不同感受野的空洞卷积提取多尺度语义信息,通过1×1卷积进行整合,提升了模型整合多尺度信息的能力,将语义分割的效果带上了新台阶。
UNET模型最早用于医学影像分割,该模型以其简洁的结构以及显著的效果受到了国内外学者的关注。李忠智等人提出基于UNET的船舶检测方法,通过在UNET中加入多变输出融合策略算为基础在模型中加入特征融合[9];周锐烨等人提出PI-UNET用于异质虹膜精确分割,使用深度可分离卷积替换传统卷积对模型进行加速,在上采样阶段同时使用反卷积与二次先行插值,弥补因深度可分卷积带来的精度问题[10];蒋宏达等人提出I-UNET用于皮肤病图像分割,在UNET中加入Inception提升UNET对多尺度信息的捕捉能力[11]。本文将对UNET模型出现的问题进一步探究,通过两种方式对其进行改进,提升模型的语义分割精度。
高分辨率遥感影像语义分割[12]问题是语义分割的一个重要分支。梁华等人[13]利用深度学习技术对航空对地小目标进行检测。对遥感影像精确的分割以及对建设数字型、智慧型城市有着重要意义。语义分割是将图像中属于相同类别的像素聚类为一个区域,对图像更加细致地了解[14]。本文在语义分割[15]基础上,探究语义分割模型在遥感影像分割上的应用。针对分割过程中存在的图像边缘分割精细程度不佳的问题,本文提出了一种改进UNET模型,通过加入具备整合多尺度信息的FPN结构,丰富每一个像素点在分类时所需要的信息。同时使用能够更好捕捉目标边缘[16]的损失函数,缓解上述模型在目标边缘分割不佳的问题。实验证明,在加入上述两种改动后,模型对目标边缘的分割精细程度有所提升,得到了更优的分割效果。
2 研究技术与方法
UNET是通过反卷积与通道维度连接进行整合;反卷积上采样与通道连接的优点在于可以得到更加平滑的结果,但是经过conv + relu的非线性变换,通过该层传递的浅层信息传递到下一层的量将会减少。我们希望每一层都可以像ASPP那样尽可能多的掌握不同尺度语义信息,很显然,UNET的方式不能满足对图像中目标边缘附近区域精准分割。所以本文主要从以下两个方面着手进行改进:
(1)通过在UNET中加入FPN结构,提升UNET整合多尺度语义信息的能力,丰富其像素点标签分类所使用的特征中包含的信息。
(2)对损失函数进行改进,相比对每个点独立进行预测的多分类交叉熵,本文使用了能够更好地捕捉目标边缘的边界标签松弛损失函数。
2.1 改进的UNET模型
为提升UNET模型的分割效果,本文对UNET模型的整体结构进行了改进,在UNET结构中引入FPN结构,充分利用UNET编码器中包含多尺度信息的优势。
FPN结构又称特征金字塔网络,这是一种广泛应用于目标检测任务中的结构,FPN结构能有效整合来自编码器部分的多尺度语义信息。FPN主要由自底向上流程、自顶向下流程和横向连接3部分构成,如图1所示。
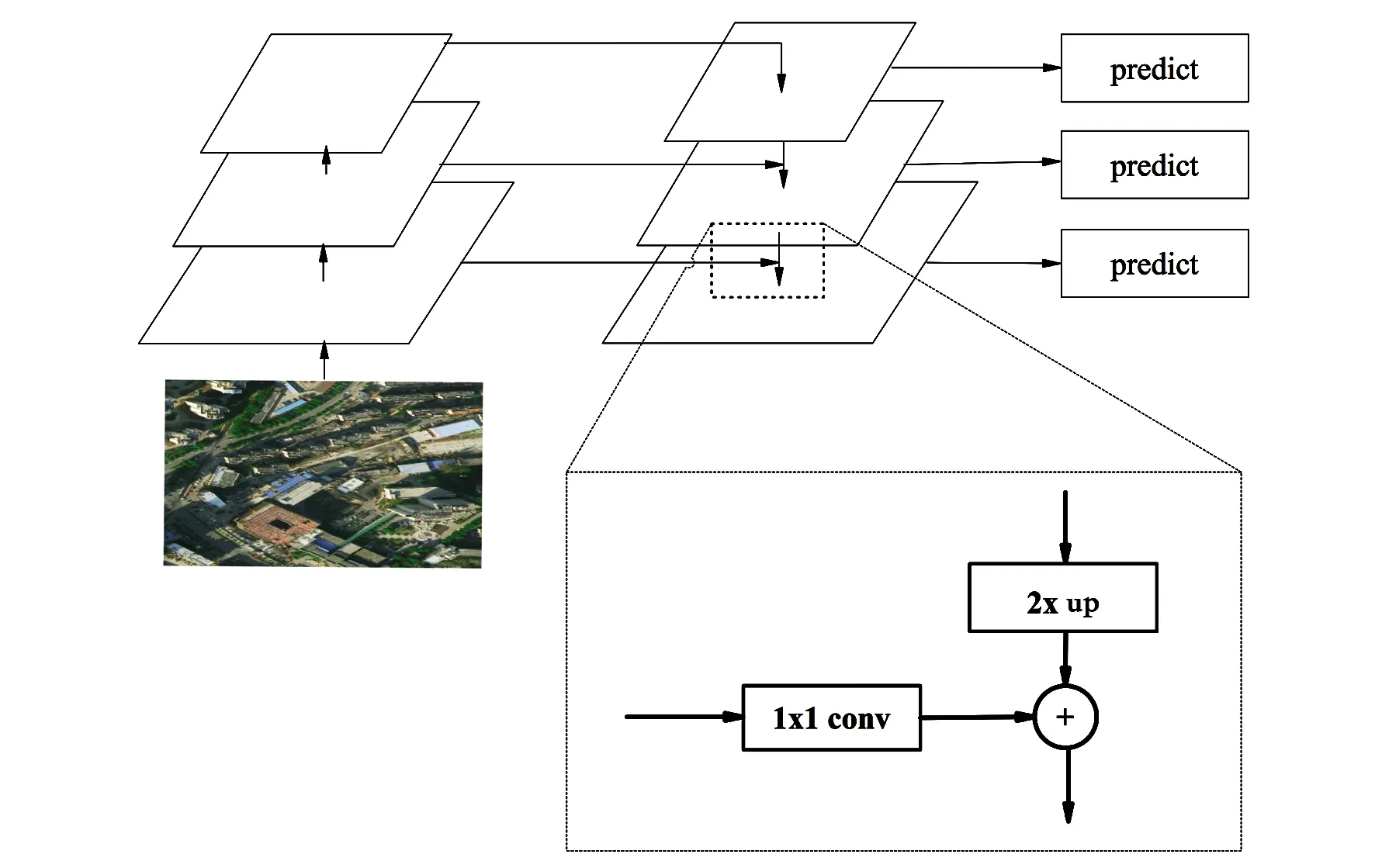
图1 FPN网络结构Fig.1 Diagram of FPN network structure
自底向上流程即为卷积神经网络在前向计算时提取具备不同尺度特征的过程。自顶向下流程即对前述所提取每步卷积特征进行上采样处理,保证处理后的高层卷积特征维度与自底向上的低层特征维度相同。随后将高级特征图与横向连接传递的低层特征图对应元素进行相加,得到具备多尺度信息的融合特征。低层次特征由于经历的卷积次数相对于高层特征较少,因此具有较多的纹理信息,而高层次特征因为经过多次卷积滤波,具有更高级的语义特征。经过对高层的特征上采样至同等尺寸,与低层次特征进行相加,使用低层次特征包含的纹理和细节信息,进一步对高层特征做补充,丰富了融合后的特征图所包含的信息。
UNET使用的反卷积上采样可得到相对平滑的结构特征,但是经过卷积加非线性激活层的变换后,使原始特征无法得到较好的保留,所以在UNET中通过跳层连接传入来自浅层的特征对原始特征进行弥补。图像中每个像素点的准确分类要依靠来自不同尺度的语义信息,而UNET的跳层连接传递的特征较为单一。因此本文引入了FPN结构。此外FPN的上采样方式为二次线性插值,相比反卷积操作,对原始特征保留更完整,加和方式特征整合保证了传递给解码器的每一层都包含尽可能多的多尺度信息。对比FPN结构与UNET结构,发现二者具有相似性,FPN结构中的横向连接可使用UNET中的横向连接实现。这一特征为FPN结构扩展UNET模型提供了便利。充分利用UNET中结构的同时,极大地利用UNET模型中包含的不同尺度信息。在加入FPN结构后,UNET整体结构如图2所示。

图2 加入FPN结构后的UNET网络结构Fig.2 Diagram of UNET network structure after joining FPN structure
FPN是通过二次线性插值和对应元素相加的方式进行整合;而UNET则通过反卷积与通道维度连接进行整合。由于二次线性插值是一个线性操作,对原始的浅层信息没有更改,仅仅通过线性插值增加了特征图的尺寸,对应元素相加的方式保证了传递给每个解码器层的特征都是原始浅层特征加和的方式,避免了因反卷积导致的信息丢失,但是二次线性插值的缺点在于会引入噪声,无法获得平滑的结果,因此我们选择在保留UNET的基础上加入FPN结构。
2.2 BLR损失函数
深度学习技术的加入快速推动了语义分割的发展,图像中目标包含的大部分像素都能够被准确分类,但对于边缘部分的分割效果依然有限,探索这一问题的本质在于,深度学习技术的主要方法论是将认为加工得到的目标理解为在一种分布上采样得到的结果,通过训练方式使模型去逼近这种分布,我们无法做到完全准确的拟合,因此对于模型的预测就存在一些出入。此外对于目标边缘上实为两目标相交处,所以此处的像素点类别存在二义问题。针对这一问题,国内外学者的解决方法主要通过更高质量的标注数据和更加复杂的模型去提升分割效果。本文将从损失函数入手,对UNET模型进行改动,本文使用了能更好捕捉目标边缘的边界标签松弛损失函数[15](Boundary Label Relaxation,BLR)来缓解这一问题带来的影响。将边界像素点定义为具有不同标记邻居的任何像素,如图3所示。

图3 边界像素点Fig.3 Border pixels
图3中红色曲线代表边缘,边缘的两侧标签分别为A与B。为了产生更好边缘的预测情况,可以选择两种策略,一种方式为直接对边缘的形状进行建模,但是图像中包含的边缘形状各异,统一对边缘进行建模比较复杂。为此本文选择第二种方式,即对图像边缘两侧的区域进行最大似然估计,上文提到了边缘像素点定义为具有不同标记邻居的任何像素,因此只需要将边缘两侧的区域进行最大似然估计,便可找到边缘区域。又因边缘两侧的标签分布相互独立,因此对两侧区域的概率描述可表示为:
P(A∪B)=P(A)+P(B)
(1)
对该项进行负对数似然估计,则有:
-log[P(A∪B)]=-log[P(A)+P(B)]
(2)
考虑目标边缘具有多变性,为保证每一个目标边缘都能得到理想的语义分割效果,将图片切割成3×3大小的图像块。此时每个图像块上只包含较小部分边缘或者不包含边缘,降低了对整张图像使用梯度下降法求解时的难度。整张图片是由大小相同的图像块构成,因此对整张图片的负对数似然估计为:
(3)
该函数即为上文提到的边界标签松弛(BLR)损失函数,其中M代表每张图片中包含的图像块个数,Ni代表每个图像块,c代表图像块中包含的像素点。相比传统的交叉熵损失函数,优化降低BLR损失函数在保证准确预测图像中包含的每个点的类别标签的同时,提升模型对目标边缘的语义分割效果。在模型训练中只需要使用梯度下降法对上式进行最小化,便可得到比较理想的效果。
2.3 数据集与数据处理
本文选择了CAMVID数据集和“CCF卫星影像的AI分类与识别竞赛”数据集。
(1)CAMVID数据集:该数据由剑桥大学收集整理和标注。数据集由一组道路街景图像构成,其中包含367个训练图像和233个测试图像(白天和黄昏场景)组成,分辨率为360×480。挑战在于划分11类,如道路、建筑物、汽车、行人、标志、电线杆、人行道等。
(2)“CCF卫星影像的AI分类与识别竞赛”数据集:训练集中包含5张尺寸为3 357×6 166的高清分辨率遥感图片,部分影像如图4所示。为了克服数据极其稀少的问题,选择充分利用图片具有的大尺寸高分辨率性质对数据集进行了扩充。首先从5张图像中随机选取4张,使用过采样策略在训练集上的每张图片上随机选点,因为原始图像的像素为3 357×6 166,其中横向像素为3 357个,纵向像素为6 166个,所以一共可以取到约为18×106个像素点。将每个随机选中的点作为图像块中的左上角,分别从左上角的像素点向右和向下延伸256个像素点,这样就得到一个以256个像素为长度切割出256×256的图像块,使用切割得到的图像块构成训练集。将剩余的一张遥感图像使用相同的采样策略,并使用采样得到的图像块作为验证集。

图4 CCF卫星影像分类与识别比赛中的裁切得到的影像Fig.4 AI classification and CCF satellite influenced part of the images in the competition
本文对数据集使用了数据增强策略,采用高斯平滑、随机添加噪声点、颜色抖动、图像旋转与缩放等操作对训练集进行扩充,测试集与验证集未做数据增强。
3 实验与结果分析
3.1 训练过程
实验在Ubuntu 16.0.4的环境下,使用Tesla v100GPU作为硬件环境。为了获得更好的结果,使用了Xaiver方法对模型中包含的参数进行初始化。在优化算法上选择了具备自适应调节步长能力的Adam方法,其中学习率初始值设置为0.002批(batch size),大小设置为16,共迭代了6 000次。模型训练过程如图5所示。
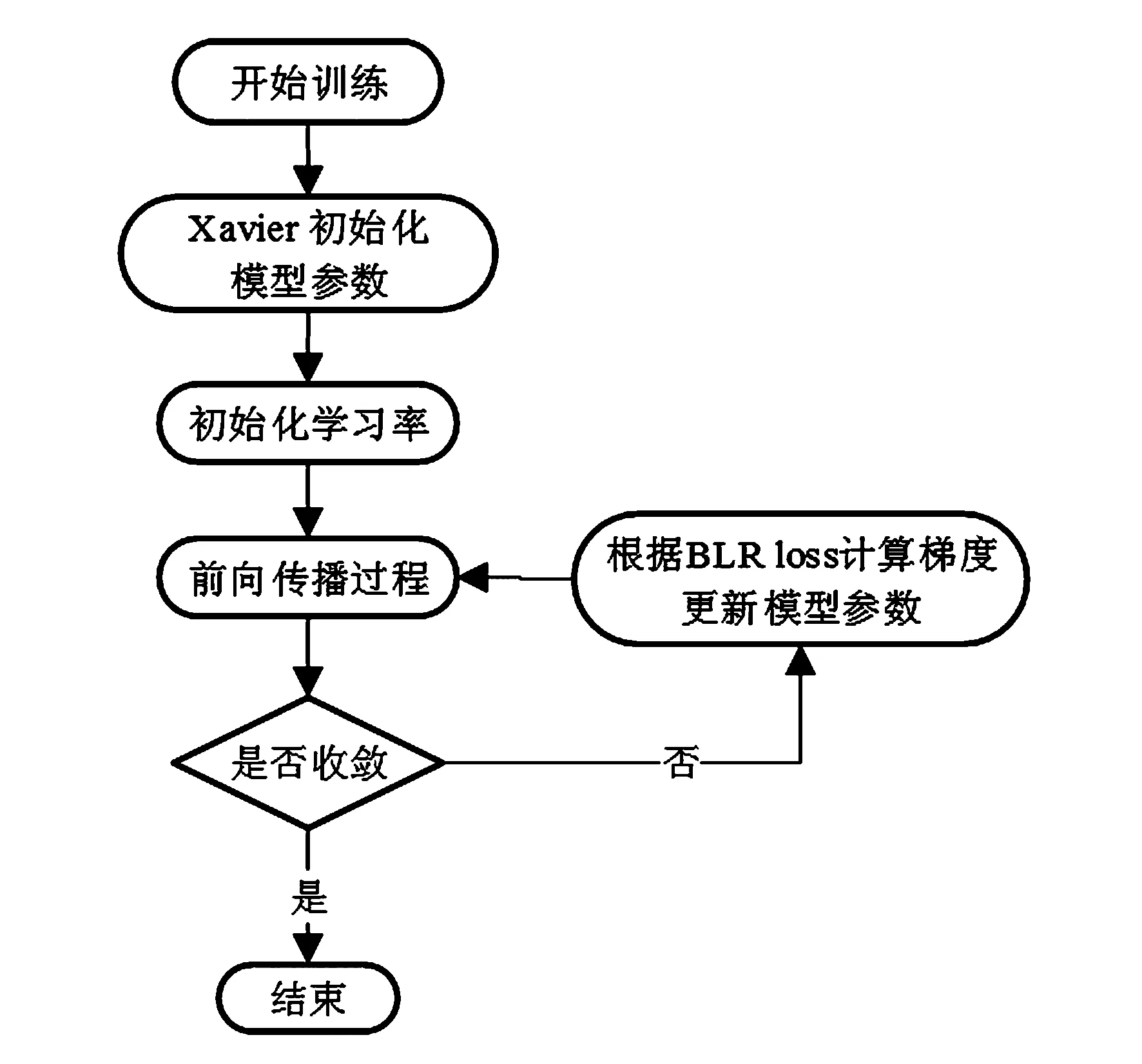
图5 模型训练过程Fig.5 Model training process
此外,为了防止模型出现过拟合,本文在模型中使用了批归一化(Batch Norm),并且在训练阶段加入了系数为0.000 05的L2正则项,训练阶段所使用的损失函数如下:
(4)
在模型推理(inference)阶段,将测试集中的图像调整为相应尺寸,依次送入训练好的改进UNET模型中,得到最终的预测结果。
3.2 对比实验
本文方法在上述2个数据集上与FCN、SEGNET[17]、UNET、DeepLabV1[18]、DeepLabV2[19]以及目前较为先进的DeepLabV3进行了多组实验以验证其语义分割效果。使用了常用的像素精度(PA)和均交并比(MIOU)作为衡量标准:
(1)PA是最简单的度量,为标记正确的像素占总像素的比例,数学表达如下:
(5)
(2)MIOU为语义分割的标准度量。均交并比计算模型预测得到的标注图与人工标注图的交集与并集之比。在每个类上计算IOU,之后取平均,其中Class Number为包含的类别。数学表达如下:

(6)
在CAMVID测试集上得到的分割结果如表1所示,不同模型耗时分析如表2所示。对比表1中的各数值,本文改进的模型具备了与DeppLabV3相近的能力。在平均像素精度和平均交并比上都明显超越以往的FCN模型、SEGNET模型、DeepLabV1、DeepLabV2。对比表2各数值,本文改进后模型的消耗时间快于DeepLabV1、DeepLabV2和DeepLabV3。

表1 CAMVID结果对比(%)Tab.1 Comparison of CAMVID result(%)

表2 CAMVID不同模型耗时分析Tab.2 Time consuming analysis of different models of CAMVID
在CCF影像分类数据上的精度指标如表3所示,不同模型消耗时间如图4所示。对比表3的各个数据可以清晰地观察到在UNET中加入FPN结构后模型的平均像素精度和均交比都有提升,在引入BLR损失函数后模型的均交并比又一次得到了提升,得到了与DeepLabV3相接近的效果。对比表4的各个数据值,不同模型耗时同CAMVID测试集。

表3 CCF影像分类结果精确度(%)Tab.3 Classification result accuracy of CCF image(%)

表4 CCF影像不同模型耗时分析Tab.4 Time consuming analysis of different models of CCF image
在建立的两个数据集上与其他先进方法的时间对比如表2和表4所示。由表可知,DeeplabV1模型耗时最长,造成这一现象的主要原因为条件随机场的参数量大,同时推理速度慢。相比其他方法如FCN,SEGNET,改进的UNET+BLR速度稍逊一筹,原因在于改进UNET+BLR参数量增加,相比DeepLabV3,本文方法具有更快的速度,同时具有相似的效果。
为了更加明显地展示加入BLR损失函数带来的交并比提升,本文将改进的UNET和加入BLR后的改进UNET分割结果进行了可视化,如图6~9所示。图6(a)为原始图片,(b)为改进的UNET的预测结果,(c)为改进UENT+BLR的预测结果,(d)为人工标注的真实值。对比图6(b)与图6(c),注意到加入BLR损失函数后,UNET模型使得目标边缘的分割结果得到了大幅度提升,缓解了原始UNET中对目标边缘分割效果不佳的问题。同时整体分割结果相比于改进的UNET结构,分割结果效果更佳。实验证明,在增加FPN结构和使用BLR损失函数的基础上,相比于原始的UNET结构,本文方法不仅在均交并比和像素类别预测精度上有大幅度提升,同时使得目标边界的预测结果得到了明显改善。

图6 CCF影像分割结果Fig.6 Segmentation results of CCF image

图7 CCF影像分割结果1Fig.7 CCF affect segmentation results 1
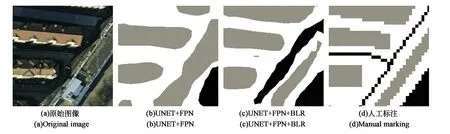
图8 CCF影像分割结果2Fig.8 CCF affect segmentation results 2

图9 CCF影像分割结果3Fig.9 CCF affect segmentation results 3
4 结 论
本文对UNET模型在目标边缘的语义分割精细度不够理想方面做出改进,通过在UNET中加入FPN结构,提升UNET对多尺度语义信息的整合能力,同时引入能更好地捕捉目标边缘的边界标签松弛损失函数BLR。在数据量较少的条件下,使用了将大尺度的遥感图像分割为256×256的图像块,同时通过旋转平移、添加高斯噪声、高斯平滑、椒盐噪声等方式有效地扩充了数据量。实验结果表明,改进的UNET模型在提升语义分割效果的同时,使得目标边缘的分割效果也得到了大幅度改善。未来将尝试RESNET等更加优秀的骨干网络,或在模型中加入空洞卷积,获得性能及速度的进一步提升。
猜你喜欢
现代电子技术(2021年1期)2021-01-17
开放教育研究(2020年2期)2020-03-31
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
通信产业报(2016年44期)2017-03-13
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
雕塑(1999年2期)1999-06-28
