
视觉位置识别中代表地点的标识牌算法
2021-04-12 09:50叶海峰赵玉琛
小型微型计算机系统 2021年4期
叶海峰,赵玉琛
(广西大学 电气工程学院,广西壮族自治区 南宁 530004)
1 引 言
视觉位置识别是计算机视觉领域最基本的课题之一,其任务是基于给定查询图像进行位置准确和有效地识别.长期以来,由于对于机器人自主性的关注逐渐增加和视觉传感器成本快速下降,视觉位置识别的研究得到了广泛的关注与快速的发展.位置识别是SLAM中活跃的研究领域,在过去的十几年间有了长足的发展,围绕所采用的图像描述符的类型可分为全局描述符,局部描述符,BoW[1]及其组合类型[1].
S.Garg[2]提出通过语义位置分类改善条件和环境不变的位置识别,利用语义场所分类创建了物理空间的有益信息的自然分割.利用场所识别和场所分类过程的强大互补性来创建一个新的混合场所识别系统增加了鲁棒性.作者[3]M.Mohan开发了一种方法,该方法从大型可用参考数据库生成用于场所识别的不同类别的环境,以减少用于匹配场所的搜索空间.他们基本上将整体物理空间划分为位置识别系统内相似环境的类别,并且不使用任何语义位置分类.这些类型的框架利用位置分类标签来提供有关空间的信息,从而减少了对象搜索空间并提高了对象识别性能.
至今,在视觉位置识别的领域仍然存在一系列的挑战[4].其中一个挑战即是环境中多个位置看起来非常相似,而且同一地点从不同视角看起来会不尽相同,这会导致感知混淆的问题.针对上述问题,本文提出一种算法以提供解决该问题的思路.通过构建地点的分类标签来分割空间信息,以避免感知混淆的问题,同时这又会减少搜索空间提升效率.
在视觉位置识别的研究中,同一位置仅由一张帧图像描述,该图像包含该位置的地理信息,一个地点有多个位置组成.将机器人走过路径的图像信息顺序依次存储,在记录存储的包含位置信息的图像数据中,发现对于不同地点下的所属图像是存在明显差异的,而对于同一地点下的图像是相似的,尽管这些图像存在差异,但与其它地点下图像的差异相比则微不足道.从主题模型的角度分析,同一地点的图像描述的都是同一主题,不同地点描述的是不同主题.针对这一现象,本文提出一种方法,该方法从主题模型的角度出发,构建能有效描述位置地点的主题,通过主题与当前机器人视觉图像的计算,来确定与当前机器人视觉图像相似图像集的范围.通过粗略的匹配搜索来准确定位机器人的大致位置范围,在通过精确匹配搜索和寻求最优的方式来最终确立机器人的位置,以此来避免感知混淆的问题.同时由于本文减小搜索空间,减少了位置识别系统中工作运行的时间,带来另一个优点.
为了高效计算地点的主题,需要减少图像的干扰信息.为此,需要对图像进行有效的分割,提取其中包含关键有效信息的部分.显著性算法模拟人类视觉注意力的特点计算视觉中的显着性对象[5-8].随着显著性对象检测变得日益精确,并且因其存在广泛的应用而得到越来越多的研究.由于显著性算法可以减少大量的冗余背景信息,对实现本文的目的非常重要.故本文预先对图像进行显著性算法的计算,获取图像中引起人类注意的区域.
故本文的算法思路先使用显著性算法对图像进行有效信息的提取,并对提取信息进行特征描述,再使用聚类的方法获取相似的对象.聚类成同一个簇中的每个对象,在忽略一定差异的条件下,可以看成是同一个物体或人,且有差异的原因可以看成是由于视角或光线等原因造成的.本文使用聚类的中心来代表描述同一主体但存在差异的不同对象.
一个地点由多个位置图像描述组成,同一地点可由该地点下多个位置分割出的具有代表性的物体对象来替代,所以一个地点可以由几个簇中心组成.这种求一个地点的多个簇中心的方式类似于求一个地点的主题.即对一个地点下多个不同方面描述该地点的图像进行其背后所含内容的抽象的求解.
不同地点可能会存在相同或相似的物体对象的现象,而聚类的方法是全局进行的,忽略了对象的空间,聚类的结果可能会将某些地点稀少但全局分布的对象寻找出来;或者将不同地点下的相似对象突显出来,但这些对象存在不能有效描述或代表地点的特性.其结果会给我们造成混乱.对于该问题本文提出帧模型算法,该算法即在计算聚类个体对象间的距离时,在距离公式上添加计算两个体间的帧序号间差异量.考虑到两个体在帧序号上相差的距离越远,两个个体是同一地点的肯能性就越小,差异量最好是衰减函数,在坐标轴上的变化趋势应该是的倒抛物线.帧模型参考万有引力公式来确立我们的帧模型函数.
对于大型的复杂环境,可以将图像内容表示为具体抽象和详细级别.在聚类中随着相似度的改变可以形成不同聚类结果.对应的现实即随着相似度值的增大,计算出的抽象内容所能代表的范围也就越大.由此我们针对抽象内容所代表范围的大小,可以建立不同级别的抽象内容.层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树.本文使用层次聚类来建立不同级别的抽象内容.
2 视频序列的标识牌算法
图1所示,一个地点位置与其他地点存在明显区别,这些差别的属性对其他不同地点而言是不同,但对于相同地点的其他帧而言是共有.这类似于主题模型,每个地点存在的特定的主题.我们的工作就是找出这些主题,并保存在搜索空间中.在进行的位置识别系统中,我们通过搜索主题空间来加速并减少搜索空间.
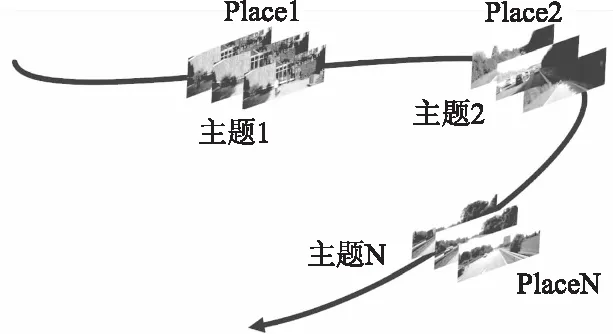
图1 视频序列与位置的关系Fig.1 Relationship between video sequence and location
主题属性定义为同一地点的共有属性,不同地点的差异属性.我们采取的方式是对图像数据集进行分割提取,通过计算来寻找出这些带有主题属性的部分.

图2 算法流程示意图Fig.2 Algorithm flow diagram
具体实施流程如图2所示.采用显著性算法对图像数据集进行对象区域的分割,使用聚类算法聚集出具有代表属性的对象个体.有每个地点的代表个体组成该地点的主题.
2.1 对象区域的提取
显著性检测(Visual Saliency Detection)指通过智能算法模拟人的视觉特点,提取图像中的显著区域(即人类感兴趣的区域).引入视觉显著性的优势主要表现在两个方面,第一,它可将有限的计算资源分配给图像视频中更重要的信息,第二,引入视觉显著性的结果更符合人的视觉认知需求.当前,基于图像显著性分割算法较多,每种显著性算法各有优势.其中,Dejian Zou[9]等人在2018年提出基于调频和单切算法的显著区域检测方法,该方法可以有效地利用傅立叶变换算法输出的显着图来准确,高效地分割最显着区域,满足了机器人系统的实时性要求.其与四种公认的显着性检测算法(IT[9],GBVS[10],AC[11],RC[3])进行定性比较中可以看出,该方法比其他四种算法获得了更好的结果.
图像对象提取如图3所示:流程自下而上,首先对输入图像进行显着性算法的处理,得到显着性图;接着按显着性图的轮廓来对原图像分割.
2.2 对象的表达及之间的对比
显著性算法无论如何变化,它始终是按照类似环绕对比度,即对象区域与其它区域的不同之处进行比较提取,这一度量单位进行计算,即使最新研究的视频序列显着对象的提取也大都是从对比度出发.显着性对象拥有的对比度这一表达形式并不能有效的描述对象的特征,理想情况下,本文希望使用来自候选对象生成阶段的显着性分数来判断区域的质量.但是,显着性分数在帧之间是无法比拟的.所以需要有效的计算关于对象不规则区域的特征描述符.
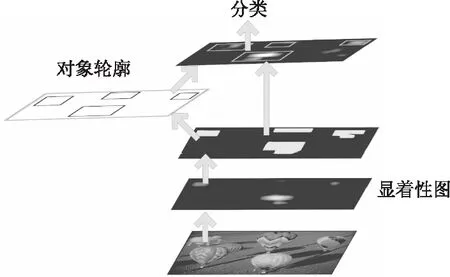
图3 显著性算法分割提取对象示意图Fig.3 Segmentation and extraction of object diagram by saliency algorithm
特征提取是影响图像分类性能的关键因素.传统的图像分类算法仅使用单一特征,因此这些方法带来了局限性.在本文中,本文对基于特征组合的图像分类方法进行了深入研究,并采用一种基于多特征融合的算法.
Keping Wang等人基于SVM的传统图像分类算法为这些特征分配了相等的权重[1].但是,SVM内核功能的计算可能会受到琐碎的相关或不相关特征的支配.考虑到与分类任务有关的每个功能的重要性,本文根据其离散程度确定相关特征,并为相关特征分配更大的权重,丢弃不相关的特征.
测量权重的方式采用限波兹曼机.限制波兹曼机是一种特殊的对数线性马尔可夫随机场(MRF)的形式,其能量函数在其自由参数的线性空间里.它能按照特征的重要程度给予特征相应的权重.
本文提取对象的颜色直方图特征和BoW词袋特征,采用限波兹曼机耦合成一个特征.颜色特征在实际应用中有非常好的效果;BoW特征能有效描述图像的纹理方面,由于其维数低而减少计算量,在图像搜索与匹配中有着很大的应用.通过颜色和纹理组合来更细致地描述对象.算法如下:
任意两个对象用rm,rn来表示,
Sp(rm,rn)=Scol(rm,rn)+Sbow(rm,rn)
(1)
由公式(1)可得出任意两个对象间的对比结果.Sp表示任意两个提取对象间的评价函数,Scol,Sbow分别表示表示任意两个提取对象间关于颜色直方图描述符和Bow描述符的评价函数.
(2)
(3)
(4)
(5)
maxbow=max{dbow}
(6)
由公式(2)(4)分别得到颜色直方图特征和BoW词袋特征的评价函数.
其中,距离度量:
(7)
(8)
(9)
Minkowski距离度量类似于分数距离度量,Minkowski距离是欧几里德空间中定义的度量,除了欧几里德和曼哈顿距离之外,它可以被视为一种泛化形式.
2.3 帧模型
不同地点可能会存在相同或相似的物体对象的现象,而聚类的方法是全局进行的,聚类的结果可能会将某些地点下数量稀少但全局分布并且数量众多的对象寻找出来;或者将不同地点下的相似对象突显出来,由于这些对象存在不能有效描述或代表地点的特性.其结果会给我们造成混乱.为了能有效聚类出每一个地点下的对象,需要对不同地点的对象间的比较度量施加影响.
Kayal等人的工作中[12],在时间距离上的层次聚类中,对时间距离随时间和帧的变化距离采用指数衰减,并取得了较好的结果.他们的工作给予了我们非常大的帮助和提示,依据其工作的思路本文的帧模型在呈现指数衰减的抛物线模型,由于本文中采用了显著性算法而得到了每一个提取对象的显著性分数,存在在资源利用的目,结合万有引力公式提出本文的帧间距离公式:
(10)
df=|nj-ni|
(11)
(12)
其中,m(rm),m(rn) 为显著性算法分割对象的显着性分数.对象的显着性分数越高,代表其在视觉上的越突出明显,代表其越能有效代表与描述地点.在引力公式中,物体的质量是非常重要的要素,质量能说明物体的重要程度,质量越大,物体所具有的力量越大.显著性分数与质量一定意义上是相识的,所以用显著性分数来替代引力公式中的质量是可行的.类似引力公式,对象显著性分数越高,帧模型得分越大,对象距离越远,帧模型得分越小.
在帧模型中,由于其得分与显著性分数有关,导致了显著性分数小的对象得分不高,在位置识别算法中被剔除掉.而显著性分数不高的对象代表了其在描述与代表地点的有效程度不高,不是本文所需要的,所以这一结果符合本文的期望.
nj与ni表示帧序列号.其中本文g取1200.Φri,j为对象块内每一像素的显著性得分,size(rm)为对象的大小.得到两对象的总评价函数:
S(rm,rn)=Sp(rm,rn)+Lf(rm,rn)
(13)
3 实验结果及分析
本文算法程序基于MATLAB2017开发,运行环境为Windows 10,运行内存为8GB.采用KITTI数据库与自己采收集图像进行试验.
3.1 对象对比效果实验
为了实验使用限制波兹曼机基来融合对象的效果,我们对其进行两次不同的实验测试.首先,先单独测试以限制波兹曼机基为核心,不含帧模型的对象表达式对分割对象的表达效果.本文以常描述符测试一组数据集进行测试.该数据集为图像配准的常用数据集,共七组,每一组图像有尺度、光照、视点和模糊等方面的变化.
由于本文的最终目的是提取相似对象的标识牌,其过程中使用了聚类,所以要测试对象表达式要在聚类中的效果.故我们的测试方法是查看经过聚类后聚类的准确度.
将数据源的顺序打乱,并使用聚类算法对其进行聚类划分.已知数据源为7个种类,设置聚类簇为7类.并使用公式(13)来计算其准确度.
(14)
公式中分子为聚类正确划分所对应类别的数目,分母是所有图像数目.
实验结果如表1和图4所示.结果表明,本文的对象表达式在计算对象相似度优于单一的特征的相似度相.
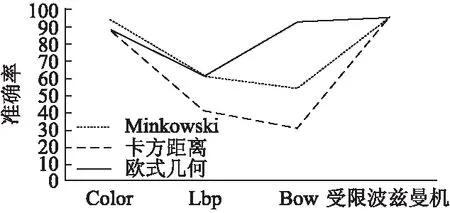
图4 聚类划分的准确率对比Fig.4 Accuracy comparison
接着,再实验对象的表达在本文算法中的效果.为了比较效果,我们设置实验.其中设置6个地点,每个地点都存在不同的几个对象组.其中每一类对象下的对象仅是相似,存在视角不同,光照变化,旋转等差别,每一类对象都是从同一地点下分割出来.
得出结果的精确度使用公式(15),此公式反映中心对象代表地点的准确程度.
(15)
分母为每个地点下的每一类对象的个数的总和,分子为计算出的中心对象与地点下每一类一致的个数.该计算精确度公式是通过计算出的中心对象与实际每一地点的代表对象的比较,反映算法所计算对象代表地点的程度.实验结果如表2和图5所示.
实验数据说明本文的没有包含帧模型的对象表达在本文的整个算法中有较好的表现.与实验结果如表1和图4的试验数据共同说明,本文对象的表达优于使用单一特征的方法.
3.2 帧模型试验
为了研究帧模型对聚类的影响,我们设置试验:设置不同地点存在相似对象的情况存在.共设置两组实验组.对象的精确度使用公式(14).

表2 两种算法准确率对比Table 2 Comparison of the scores of the two algorithms
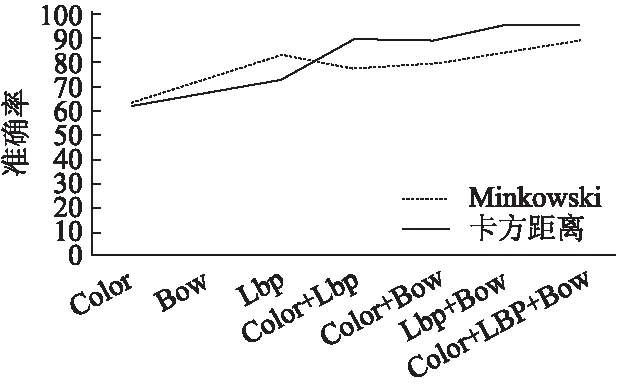
图5 准确率对比Fig.5 Accuracy comparison
实验结果如表3和图6所示.由试验数据表明,与没有帧模型的算法相比,添加了帧模型的算法在位置识别实验的精度上提升了8.09和15个百分点.帧模型对算法具有提升效果.

表3 两种算法基准评价对比Table 3 Comparison of the scores of the two algorithms
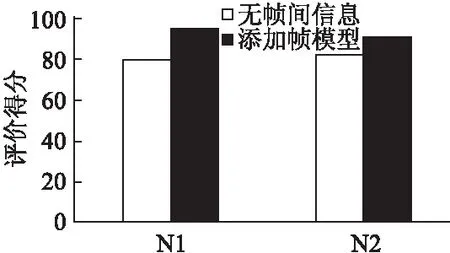
图6 评价得分对比Fig.6 Comparison of evaluate scores
3.3 位置识别的实验
在本文设计的整个位置识别系统中可以分为两个部分,前一个部分是生成地点标识牌的操作,即本文所论述的算法操作,另一个部分即对当前机器人输入图像进行搜索的部分.对这个数据集进行本文算法的操作并将结果存储起来,待有数据输入时,在进行第2部分的搜索操作.其中,检索技术使用倒排索引,倒排索引可以更快地消除不太可能的图像,而不需要线性搜索数据库中的所有图像.将本文算法操作存储数据与直接搜索进行试验对比.
BoW词袋方法在位置识别的研究中有着重要意义,为了比较本文算法的效果,将与BoW进行比较,同时与常规算法欧几里德距离搜索算法相比.
衡量算法运行时间的3个方法有基准评价、统计指令,以及复杂度分析.我们从基准评价和复杂度分析两方面来进行比较.
基准评价方法是首先确定几个具有相同大小的不同数据集合的时间,然后计算出平均的时间;接下来针对越来越大的数据集合,收集相似的数据,在进行几次这样的测试后,就有了足够的数据能够预测算法对任何大小的一个数据集合的表现了.
数据大小为138时,我们在所有采集的关于地点图像中随机选出具有代表性的136张图像用于算法测试的数据样本,其中共6个地点,每个地点含有多个个明显的不同对象,每个对象都有多张存在差异的图像.将6个不同地点共138张图片用于本文算法和直接搜索方法的试验对比.
数据大小为488时,数据大小为1138时,我们增加地点的数目,同时增加地点下对象的数目,按数据集138的设置条件增加对象.同时随机从数据集中选取几个图片作为搜索的输入数据.
我们在保证搜索匹配到正确图像的前提下,达到表1所示的实验结果.该结果为多次实验的数据.该实验结果没有记录本文算法中生成标识牌的时间,仅使用标识牌与一般算法进行搜索时间的比较.可以看出本文算法与常规算法欧几里德距离搜索算和BoW算法相比有较为明显的优势.其中,在生成标识牌的工程中,生成标识牌时间随着添加数据的数量大小的增加,而搜索部分所花费的时间增加并不明显,可以看出本文本文算法将算法的绝大大部分时间花费在生成标识牌的过程中.这一效果给予搜索时间好的效果.
在上述过程,的时间复杂度为O(ni),大于直接搜索的时间复杂度O(n),但本文算法搜索的空间远远小于直接搜索的空间,本文算法的效率远大于一般方法.
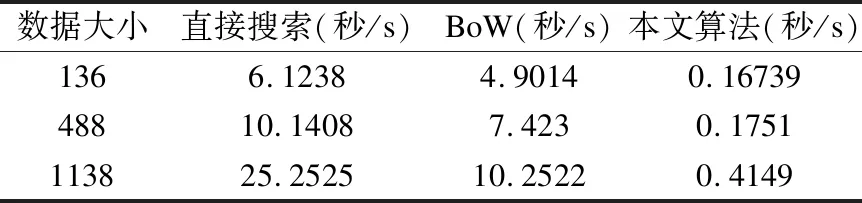
表4 两种算法搜索时间对比Table 4 Search time of the two algorithms

图7 连接效果时间对比Fig.7 Comparison of connection effect time
在上述实验中(见表4和图7),我们精心设置当前机器人的输入数据与数据集,保证机器人的数据不能与存储的数据集数据存在多个不同地点的相似图像.同时我们发现当存现上述情况时,常规算法与BoW会出现位置识别错误甚至位置识别失败,而本文算法的试验结果与表4中相差不大,仍能识别成功.对本文算法分析可以发现,在进行精细的匹配搜索前,由于多出了标识牌搜索的流程,使得在精细匹配的流程中,搜索的范围确立在小的范围内,剔除了一些图像相似的位置地点,使德位置识别的成功率大大增加.
当前经典算法FAB-MAP与SeqSLAM方法的比较如表5所示.
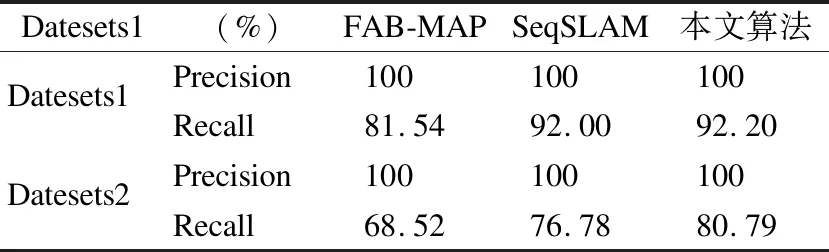
表5 准确度比较Table 5 Accuracy comparison
其中,Datesets1指存储数据库中重复图像非常少的情况,Datesets2指存储数据库中重复图像较多时的情况.当存储数据中重复图像非常少时,3种算法的roc面积都很大;但当情况改变,存储空间的重复图像变得较多时,由于感知混淆的干扰,3种算法的recall开始降低,但本文算法仍能保持较好的recall,说明对存储空间进行分割增添标识牌的方式确实在一定程度上抑制了感知混淆的问题.
4 总 结
位置识别系统中的视频数据,代表某一地点位置的视频序列与代表其他地点位置的数据存在明显差异,而同为一地点的则相似.针对位置识别系统中数据的特点,提出了一种利用基于显著性算法提取出图像显著性区域而生成能代表视频序列段的标识牌的方法.利用该标识牌来减少搜索空间,加快位置识别系统的运行效率.同时由于使用标识牌确立了大致范围,避免了在全局范围内图像相似带来的混淆.本文算法首先采用显着性算法对图像进行分割与提取,以提取图像中的主要和分割开来的信息,使用限制波兹曼基的加权融合来有效描述这些信息,并针对在聚类空间中没有时间信息所导致聚类混乱的情况提出帧信息模型,提取聚类的中心排列成能简单有效代表地点或多个序列帧的标志-标识牌.实验结果表明,本文算法在位置识别系统中有较好的效果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
汽车实用技术(2022年4期)2022-03-07
廉政瞭望·下半月(2021年5期)2021-07-20
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
大东方(2019年1期)2019-09-10
中国知识产权(2018年12期)2018-12-29
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
中国知识产权(2017年5期)2017-05-25
