
基于DBSCAN的港口泊位自动识别算法设计
2021-04-17 05:47刘鑫鑫
上海船舶运输科学研究所学报 2021年1期
刘鑫鑫, 韩 懿
(中远海运科技股份有限公司,上海 200135)
0 引 言
近年来,船舶自动识别系统(Automatic Identification System,AIS)在船上得到广泛应用,装有AIS的船舶通常配合全球定位系统(Global Positioning System,GPS),将船位、船速、改变航向率和航向等船舶动态数据与船名、呼号、船型、吃水和危险货物等船舶静态信息相结合,实时向外广播,为航运企业和海事机构等进行船舶安全管理提供基础数据。当前,在信息技术不断发展的大背景下,AIS数据已从服务航行安全保障走向服务航运企业的经营管理和行业决策,成为航运大数据挖掘的基础信息,帮助企业对船舶管理、成本核算、风险控制和运力分配等进行优化。
在已有研究中:张智凯等[1]在总结多泊位油品码头平面布置要点时指出了泊位空间平面布置的重要性;汪士寒等[2]基于排队论,对鼠浪湖铁矿石码头泊位的布局进行了优化研究,指出鼠浪湖泊位优化方案是基于泊位位置和具体信息得到的。这些研究都是在单个港口的静态泊位数据的基础上开展的。为进一步研究泊位对港口作业的影响,找出泊位的具体位置尤为重要。叶仁道等[3]提出采用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)密度聚类算法研究船舶停泊点,虽然采用DBSCAN聚类了船舶在海上的停泊点,但只是进行了初步的聚类,没有对聚类结果进行处理,获取的只是海上一些零散的点,且聚类的是海上的停泊点而非泊位,不具备成为普遍实用性数据产品的可行性。2018年,中远海运科技股份有限公司开始基于大数据技术和数据服务技术研发航运数据中台,目标是应用海量的AIS数据、港口基础数据和水文气象数据实现对船舶航行全生命周期内行为的动态识别,并进一步将该平台拓展应用到港口动态监控、航线识别与动态监控、船队运营情况和大宗商品运力监控等领域中。本文主要对港口泊位的位置进行研究,实现泊位从静态信息到动态信息的自动化识别,用于对泊位作业状态进行实时监控,对历史数据进行分析,并实现数据可视化,为船舶、港口的作业计划优化和风险管理提供参考。
1 数据采集
本文基于船舶AIS历史数据、船舶动态信息和船舶静态信息,采用DBSCAN密度聚类算法对全球4 079个港口的泊位进行自动识别,得到泊位的位置、方向、岸线长度和类型等信息,用于实时跟踪船舶在港作业动态,分析泊位历史作业情况。图1为某船舶某个完整航次的动态信息和气象条件。

图1 某船舶某个完整航次的动态信息和气象条件
本文研究的基础数据主要为AIS历史数据、船舶在港动态信息和船舶静态信息。AIS主要将航运动态定义为航行、锚泊、靠泊和搁浅等4种,分别用0、1、5和6表示,航运数据中台基于AIS动态数据实现对船舶行为的识别,即对所有船舶靠泊行为的识别(如图1所示)。以锦州港为例,从船舶历史动态数据中提取的历史靠泊数据见图2。从船舶历史动态数据中提取的数据字段说明见表1。
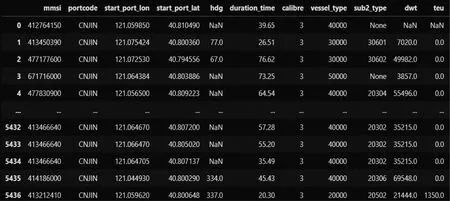
图2 从船舶历史动态数据中提取的历史靠泊数据

表1 从船舶历史动态数据中提取的数据字段说明
2 算法比较及选择
常见的聚类算法主要有基于密度的聚类方法(代表算法为DBSCAN算法)、基于层次的聚类方法(代表算法为BIRCH算法)和基于划分的聚类方法(代表算法为K-Means算法)等3类。此外还有一些基于这3类算法的衍生算法。本文主要对K-Means算法和DBSCAN算法进行对比分析。
2.1 K-Means算法
在应用K-Means算法时,需先确定样本类的个数n,从样本中随机挑选n点作为类心,迭代更新类心,直到类心不再改变,流程如下:
1)在样本中随机选取K个点,作为每一类的中心点。
2)计算余下n-K个样本点到每个聚类中心的距离(距离有很多种,这里采用欧式距离)。对于每个样本点,将其归到与其距离最近的聚类中心所属的类中。
3)重新计算每个聚类中心的位置,步骤2)中得到的结果是n个点都有自己所属的类,对每一类内的所有点取平均值(这里假设是二维空间,即对x坐标和y坐标分别取平均值),计算出新的聚类中心。
4)重复步骤2)和步骤3)的操作,直到所有的聚类中心不再改变。
2.2 DBSCAN密度聚类算法
DBSCAN密度聚类算法是基于密度的聚类算法,在应用该算法时,不需要预先确定簇的个数,只需设置半径eps和半径内最少点的个数min_samples即可。该算法将数据点分为3类,其中:核心点是在半径eps内点的数量超过min_samples的点;边界点是在半径eps内点的数量小于min_samples,但落在核心点的邻域内的点;噪声点是核心点和边界点以外的点。主要概念定义如下。
1)直接密度可达:给定一个对象集合D,若对象p在对象q的eps邻域内,而对象q是一个核心对象,则称对象p从对象q出发时是直接密度可达的。
2)密度可达:若存在一个对象链p1,…,pi,…,pn,满足pi=p和pn=q,pi是从pi-1出发时关于eps和min_samples直接密度可达的,则对象q是从对象p出发时关于eps和min_samples密度可达的。
3)密度相连:若存在对象O∈D,使对象p和q都是从O出发时关于eps和min_samples密度可达的,则对象p到q是关于eps和min_samples密度相连的。
DBSCAN算法原理[4]如下:
1)DBSCAN通过检查数据集中每点的eps邻域搜索簇,若点p的eps邻域内包含的点多于min_samples个,则创建一个以p为核心对象的簇;
2)DBSCAN迭代地聚集从这些核心对象出发时直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
3)当没有新的点添加到任何簇时,该过程结束。
2.3 算法选择
研究初期选定的算法是K-Means算法,采用该算法的关键在于确定类的数量,通过搜索引擎搜索港口泊位的真实信息。在应用该算法过程中存在几个无法避免的问题。
1)泊位数(即类的个数)不能准确获取。很多港口的泊位情况并没有在网络上实时更新,通过搜索引擎搜索,搜索到的泊位数量并不准确。
2)由于漂移等问题,AIS原始数据中会有很多噪声点或错误的船舶状态信息,在此情况下按真实泊位数量聚类,会导致一些分开的泊位聚在同一个类中,或同一个泊位聚在不同的类中。
以锦州港为例,首先搜索到该港有24个泊位(更新时间为2019年9月),采用K-Means算法进行聚类,结果见图3。图3中:不同的颜色代表不同的泊位;方框部分没有分开,方框内应该是同一泊位,但被分到了2个泊位中;右下角很多零散的泊位被分到了一起作为1个泊位,这样的效果非常不理想。
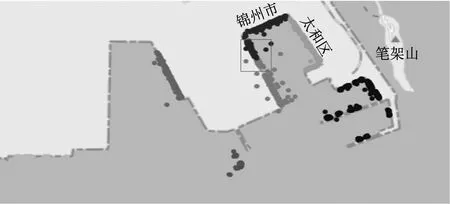
图3 采用K-Means算法聚类的效果
为避免K-Means算法存在的上述问题,尝试采用DBSCAN算法。该算法的优势在于不需要提前设置类的个数,只需设置搜索半径和半径内点的最少个数,对不规则图形有较好的聚类效果。图4为采用DBSCAN算法聚类的效果。从图4中可看出,方框内的泊位被较好地聚类了出来,右下角的零散泊位也得到了很好的分类。
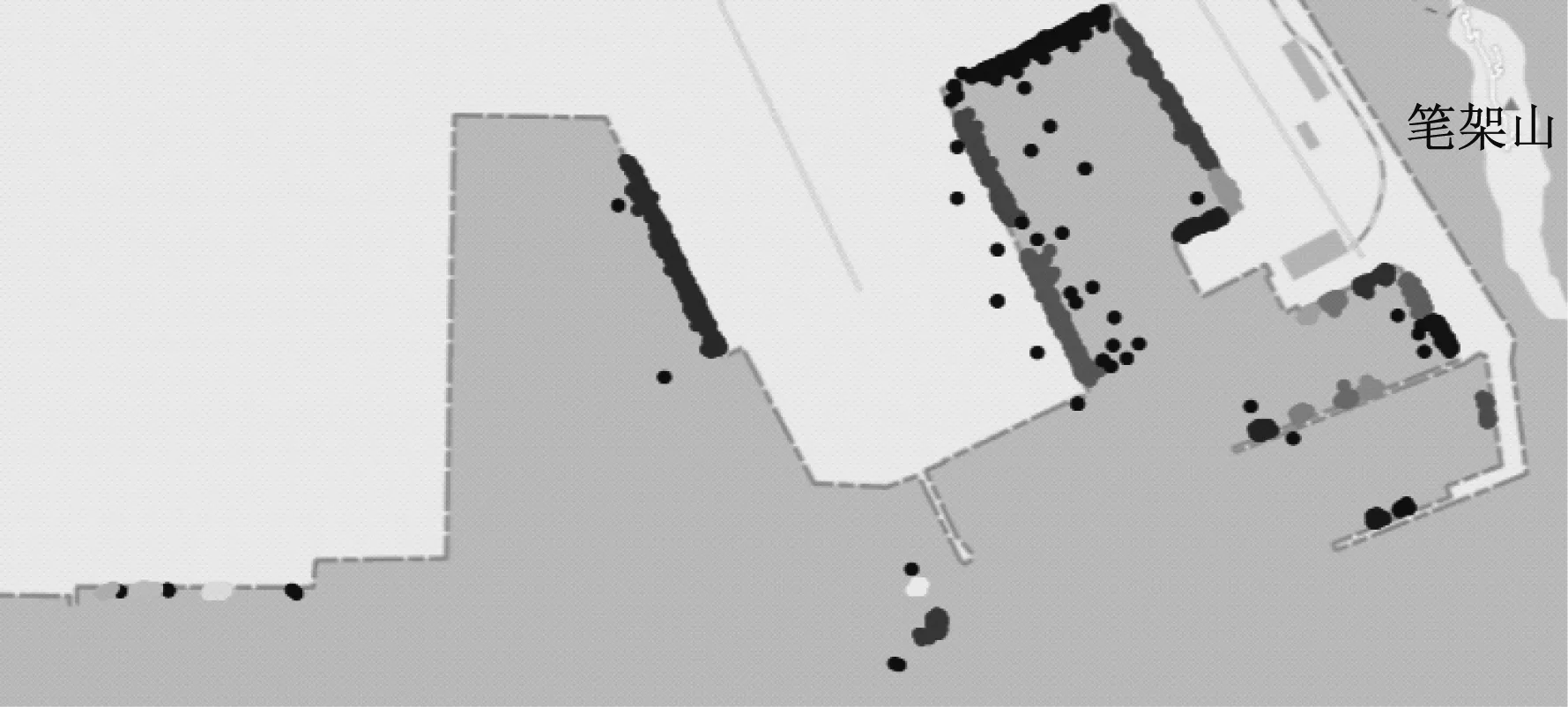
图4 采用DBSCAN算法聚类的效果
上述聚类算法各有优劣,可根据不同的应用场景选择合适的聚类算法。本文主要对AIS靠泊数据进行聚类,首先排除图团体检测,图团体检测使用场景为数据可被表示为网络或图。由于在聚类之前无法获取泊位的具体个数,从网络上获取的泊位数据不完整且准确度不够高,因此不能采用K-Means算法和高斯混合模型。
DBSCAN聚类算法、凝聚层次聚类算法和均值漂移聚类算法都不需要先确定类的数量。凝聚层次聚类算法的复杂度较高,不适合计算数量巨大的数据,同时对奇异值比较敏感,在AIS数据质量较低的情况下不适合采用该算法。相对于均值漂移算法,DBSCAN聚类算法对异常数据不敏感,且能发现任意形状的簇,非常符合课题需要,可较好地拟合出泊位的形状和大小。
3 算法设计和实现
3.1 算法工作流程
DBSCAN聚类算法的工作流程(见图5)如下:
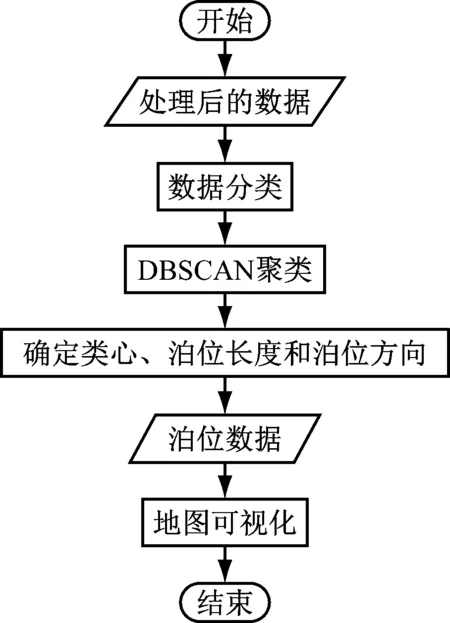
图5 DBSCAN聚类算法工作流程
1)提取某港口的靠泊数据,包括船舶的水上移动通信业务标识码(Maritime Mobile Service Identify,MMSI)、靠泊时间、艏向和经纬度坐标。
2)对数据进行分类。
(1)按集装箱船、液散船、干散货船、客船和其他船型等类别,将不同类型的船分开;
(2)分离出可能要修理的船,停靠时间大于200 h的船属于修理船。
3)对泊位进行聚类,采用DBSCAN算法对不同类型船舶的靠泊位置坐标进行计算。
4)获取泊位特征。
(1)计算每个簇的中心点。
(2)计算簇的长度。
(3)计算簇的方向。
① 若有艏向,则取艏向的众数作为泊位方向;
② 若没有艏向,则以簇内距离最远的2个点连线的方向作为泊位方向。
5)根据泊位内靠泊船舶的类型,按“泊位类型+序号”的形式对泊位进行命名。
6)将计算结果输出到数据库中。
7)前端调用数据库,并将其可视化到地理信息系统(Geographic Information System,GIS)地图上。
3.2 关键步骤实现
本文研究的关键步骤为确定DBSCAN聚类参数、泊位位置、岸线长度和泊位类型。
3.2.1 确定DBSCAN聚类参数
DBSCAN聚类参数有eps和min_samples 2个。
1)对于参数eps,由于输入的坐标是地理上的经纬度坐标,需将传统距离通过单位变换转换到地理坐标系中。经纬度单位与国际长度单位之间的变换关系为:赤道上经度1°为111 km;经线上纬度1°为111 km;其他纬线上经度1°为111 km×cosA(A为纬度)。
首先确定eps,若eps的值过大,会导致噪声点被归入到类内,类的数量会比较少;若eps的值过小,会导致类的数量过多。根据实际情况,eps的取值范围为20~200 m,对应到地理坐标系上约为0.000 2°~0.002 0°。
2)对于参数min_samples,若其值过大,会导致离群点变多,类变多,同一个泊位被划分到2个不同的类中;若min_samples的值过小,会导致簇中包含过多的离群点。
3.2.2 确定泊位位置和岸线长度
首先确定各泊位的中心点,各泊位中数据点的外形为长条形,可根据类内经纬度极值的平均值获取类的中心点,有
(1)
(2)
式(1)和式(2)中:λcenter和φcenter分别为类的中心点的经度和纬度;λmax和λmin分别为类内经度的极大值和极小值;φmax和φmin分别为类内纬度的极大值和极小值。
其次确定泊位的长度和方向,其中泊位长度L的计算式为
(3)
最后根据泊位的方向确定泊位的2个端点。泊位方向优先考虑采用船舶停靠时的方向,即艏向。靠泊时艏向的众数定义为泊位方向。采用三角函数计算,以泊位长度为斜边长,假设中心点为泊位方向角的顶点,计算端点与中心点的相对位置差。
(4)
(5)
根据经纬度坐标差计算2个端点P1和P2的值,有
P1=(λcenter+λral,φcenter+φral)
(6)
P2=(λcenter-λral,φcenter-φral)
(7)
然而,有很多艏向数据缺失,使得艏向不能单纯作为泊位方向。由于通过观察发现船舶都是靠着泊位停靠的,数据可视化形状为长条形,因此可根据类的形状确定泊位的方向。先取类内的2个极值点,即经度最大和最小的2个点,取二者的纬度值,分为2种情况(图6和图7)。

图6 无艏向情况1

图7 无艏向情况2
1)最大经度点的纬度值小于最小经度点的纬度值为情况1,此时泊位2个端点为
P1=(λmin,φmin)
(8)
P2=(λmax,φmax)
(9)
2)最大经度点的纬度值大于最小纬度值点的纬度值为情况2,此时泊位2个端点为
P1=(λmin,φmax)
(10)
P2=(λmax,φmin)
(11)
3.2.3 确定泊位类型
确定泊位的位置、方向和长度之后就可将泊位可视化在地图上,但在实际中不同泊位的船舶靠泊状态和作业状态是不同的,因此要区分不同泊位的类型。本文根据每个分类中船舶的主要类型确定泊位的类型。
将所有处于跟踪动态的船舶分为集团船和非集团船2种,由于非集团船相关资料的准确性未得到验证,故优先使用集团船确定泊位类型。若类内集团船只有1种类型,则可直接确定泊位的类型。若类内集团船有2种类型,其中80%以上为1种船型,另外有一些是液散船,可考虑少部分船为加油船,泊位类型依旧按占比80%以上的船型判断。若类内集团船有多种船型,则设置泊位为通用型,其中液散船由于其特殊性,只能在特定的泊位停靠泊,将其细分为液化石油气(Liquefied Petroleum Gas,LPG)船、液化天然气(Liquefied Natural Gas,LNG)船和原油船。当类内都是液散船时,若其中有LNG船、LPG船和原油船,则优先将泊位类型确定为LPG船泊位、LNG船泊位和原油船泊位。类似的,当类内有铁矿石船时,优先将泊位确定为铁矿石船泊位。此外还有一种重要的泊位类型,即修理泊位,该类型泊位需单独确定,对靠泊时长超过200 h的船进行聚类,聚类出来的泊位即为修理泊位,修理泊位由于其特殊性,后期需单独确认其可靠性。
4 结果和结论
采用DBSCAN聚类算法计算各港口的泊位信息,输出的内容为每个泊位的关联港口代码、类型、中文名称和位置线的点坐标(见图8)。
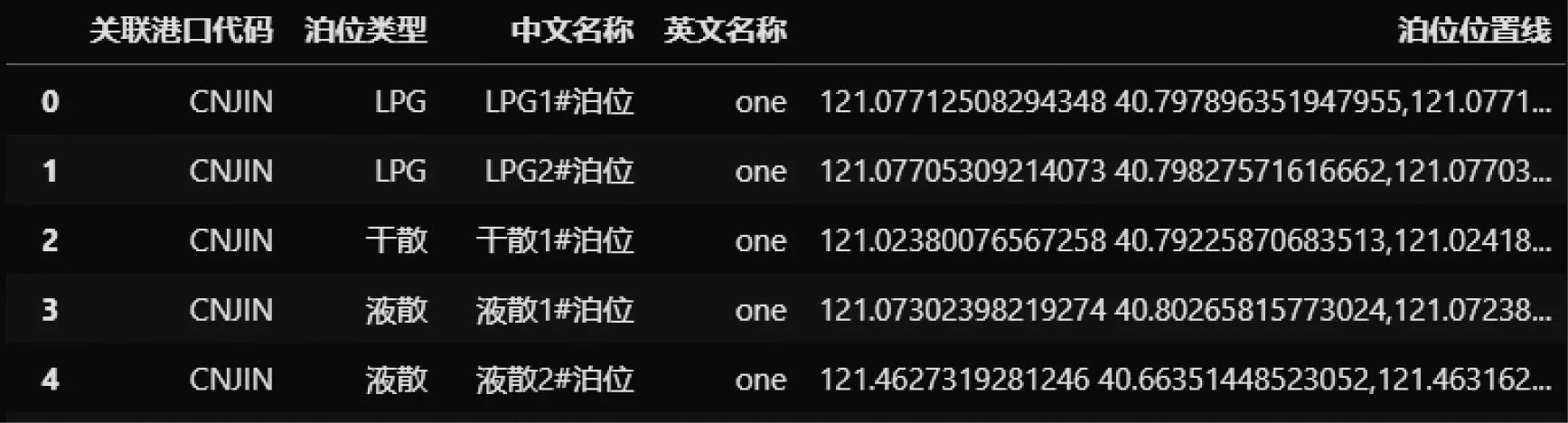
图8 聚类并处理后的结果
目前该航运数据中台已基于DBSCAN聚类算法挖掘出全球4 079个港口34 954个泊位,并结合GIS地图进行了展示,以锦州港为例,聚类结果地图展示见图9,美国IHS公司数据源泊位与采用DBSCAN聚类算法聚类结果综合展示见图10。图10中共有27个泊位,其中有1个液散泊位未被IHS收录,IHS数据源泊位中有1个泊位采用该算法未找到。出现该问题的主要原因在于,该泊位样本点较少,随着数据的增加,通过该算法,可根据实际情况找到该泊位。相对于IHS数据源,该算法更灵活,可根据数据的增加找到新增泊位。综合所有港口,采用该算法的泊位位置识别准确率可达到90%,部分泊位会出现类型错误和多个泊位被识别为1个的情况,这些问题将在后续优化中予以解决。

图9 聚类结果地图展示图

图10 IHS数据源泊位与聚类结果综合展示
5 结 语
本文采用DBSCAN密度聚类算法识别出了港口泊位的位置、方向、长度和类型等信息。根据全球港口的泊位信息,可使船舶动态跟踪更加准确,有利于船公司对船舶进行数字化管理,有利于港航数字化协同。
下一步的主要工作是对泊位信息进行动态修正和动态监控,并对历史数据进行分析。例如,随着数据维度的继续增加,可对泊位信息进行更准确的描述,将泊位名称、岸线长度变化、前沿吃水变化和适合作业的船型等扩充到泊位信息中。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
汽车与安全(2019年5期)2019-07-30
珠江水运(2017年16期)2017-09-21
现代经济信息(2016年6期)2016-05-31
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
