
基于软件定义网络的数据中心自适应多路径负载均衡算法
2021-04-20 14:07许红亮杨桂芹蒋占军
计算机应用 2021年4期
许红亮,杨桂芹,蒋占军
(兰州交通大学电子与信息工程学院,兰州 730070)
0 引言
软件定义网络(Software Defined Network,SDN)[1-2]是网络领域提出的一种新型架构,其核心理念是将网络的控制平面与数据转发平面分离解耦,实现网络的集中控制和面向业务层可编程,网络的可编程帮助控制底层网络数据的转发行为,有助于感知底层网络的运行状态。但随着计算机和网络产业的不断推进,新型网络应用的出现使得网络通信量呈现爆发式增长,给数据中心网络提出了考验[3]。传统网络设备运行在封闭系统中,应用层不能感知底层网络运行状态,在有限的链路上处理海量的数据请求,给数据中心带来极大流量压力,出现负载不均衡、吞吐量低等问题。为解决该问题,国内外学者针对数据中心多路径负载均衡[4]做了一些研究,采取静态或动态的负载均衡算法来处理,这些算法虽然取得了效果,但缺少一定的自适应性,面对网络中实时变化的动态流量,无法快速感知网络运行状态和链路的实时传输状态,或者只是局限于实现局部的最优转发,因此不能保证在全局最优的网络状态下,最大限度实现基于数据中心网络的多路径负载均衡。
传统的负载均衡采用等价多路径(Equal Cost Multi-Path,ECMP)路由算法[5-6],其核心是将数据进行哈希计算,均衡在所有等价的路径上,把流量负载平均分配在每条链路,来实现网络数据转发;但该算法缺少拥塞感知机制,未考虑网络实时状态。针对数据中心胖树拓扑的网络,目前也有一些其他的解决方案:AL-Fares 等[7]提出了全局首次匹配(Global First Fit,GFF)算法和模拟退火法。GFF算法获取网络中所有的链路信息,选取首次满足匹配条件的路径,虽然实现方法简单但不能实现全局最优;模拟退火法用概率性搜索的方法,虽然选择了全网最优的路径转发,但网络收敛性变差。Li 等[8]通过局部动态的路由策略,实现了动态负载均衡(Dynamic Load Balancing,DLB),但该算法未从全局层面研究,导致局部链路负载太重,出现网络拥塞现象。Lu 等[9]提出了基于SDN 的流量控制策略,在网络利用率方面作了改进,但在路径选择时有排除更优路径的可能。孙三山等[10]针对数据中心拥塞问题,提出基于流调度代价的拥塞控制路由算法(Flow Scheduling Cost based Congestion Control Routing Algorithm,FSC-CCRA),对数据流量区分大小流,根据定义流调度代价选取路径,但该算法自适应动态选择路径的能力不足。
针对急剧增长的数据量给数据中心带来的压力、传统封闭的网络运行系统和有限链路传输的限制,使得网络出现负载不均衡、吞吐量低等问题,本文选用新型架构软件定义网络(SDN),在此网络背景下,利用SDN 能充分感知网络实时运行状态和集中管控的特点,结合蜘蛛猴优化(Spider Monkey Optimization,SMO)算法良好的自适应全局探索能力,提出了一种基于蜘蛛猴优化的SDN 自适应多路径负载均衡算法(Load Balancing Algorithm based on SMO,SMO-LBA)。首先,建立SMO-LBA 的实现框架,通过各模块的协调配合,实时获取计算数据中心网络中各路径的链路空闲率;然后,计算评估各路径相应的适应度值,在蜘蛛猴的本地领导者阶段和全局领导者阶段进行自适应评估更新;最后,动态选择出数据中心网络中链路占用率最小的路径,且此路径为全局最优路径,作为数据最终选定的转发路径,根据选路结果,下发新的流表按此流表规则进行转发,能有效解决在数据中心网络环境下的负载不均衡的问题。
通过仿真实验表明,SMO-LBA 发挥了SDN 感知底层网络细节特征的优点,能获取链路的实时状态信息,同时利用蜘蛛猴优化算法的全局探索能力,从局部到全局地动态开采,自适应地调整数据流的选路,实现了数据中心网络的负载均衡,有效地解决了传统网络缺乏感知和负载均衡算法缺少自适应性的问题。
1 算法设计与实现
1.1 算法实现架构
根据SDN 体系架构,其数据平面通过南向接口收到控制器的指令,按照指令要求处理网络数据,南向接口反馈网络配置和运行状态信息给控制器,应用层通过北向应用程序接口(Application Programming Interface,API)对网络进行控制。为实现本文提出的基于蜘蛛猴优化的自适应多路径负载均衡算法(SMO-LBA),在算法实现框架内设计了信息收集模块、网络管理模块、自适应路由模块和流表下发模块,总体框架如图1 所示,这些模块作为数据中心的核心功能模块,完成网络流量从收集到下发的所有流程,实现自适应多路径负载均衡。
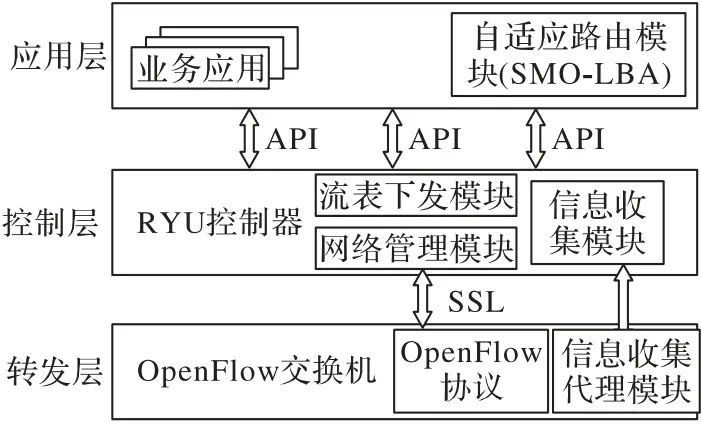
图1 SMO-LBA实现框架Fig.1 SMO-LBA implementation framework
1.1.1 信息收集模块
信息收集模块作为基础模块,以信息收集代理模块作为辅助,主要用来收集数据中心网络中的实时状态信息,探测感知网络中各节点状态信息和各路径上的链路状态信息,获取数据中心完整网络拓扑结构,建立相关路径信息监测表,为后续自适应路由模块提供全网拓扑结构和流量信息。信息收集模块通过链路层发现协议(Link Layer Discovery Protocol,LLDP)[11]将相关信息封装在Packet_in/Packet_out 消息中,在控制器和交换机之间通信,对反馈信息解析整理得到全网拓扑。
1.1.2 网络管理模块
为实现自适应动态负载均衡,需要对网络内的参数实时动态监控,用网络管理模块周期性监测网内各参数信息。网络管理模块通过南向OpenFlow 协议[12]获取端口统计信息,周期性获得网络流量和各转发路径负载情况,不断更新管理路径信息监测表,包括流管理、节点管理和链路管理,计算各路径负载均衡度,一旦负载均衡度高于设定阈值,则调用自适应路由模块,根据实时参数对路径重新评估,选择合适路径转发来降低负载均衡度。
1.1.3 自适应路由模块
作为整个数据中心网络架构的关键模块,自适应路由模块综合来自信息收集模块和网络管理模块的信息,基于全网路径重新选路。该模块主要采用基于蜘蛛猴优化的自适应多路径负载均衡算法(SMO-LBA)对网络中的多条路径进行评估,以链路利用率作为目标函数,从局部到全局的过程进行寻优,为数据中心网络流量寻找最佳转发路径,选取适应度值最高的路径作为目的转发路径,对负载均衡度不满足条件的路径重新择路。
1.1.4 流表下发模块
流表下发模块是根据自适应路由模块评估最佳目的转发路径,产生对应的路由转发策略,由Ryu控制器以流表的形式下发到各个交换机节点,交换机按照更新后的新流表执行自适应路由模块的选路结果,根据转发规则匹配相应的流表项,对数据中心网络流量进行转发,完成SDN 的自适应多路径负载均衡。
1.2 算法设计思想
蜘蛛猴优化(SMO)算法[13]是受蜘蛛猴觅食行为启发的群集智能优化算法,利用SMO 算法较强的开采能力和较高的寻优精度,本文针对基于SDN 的数据中心网络提出了基于蜘蛛猴优化的自适应多路径负载均衡算法(SMO-LBA),将各个网络节点作为蜘蛛猴种群寻优的食物源,将数据流通过链路到达各个节点的过程模拟成蜘蛛猴种群在寻找最优食物所经过的路径,获取每条链路负载信息和从每个网络节点出发所有链路的链路利用率,建立网内路径转发的路径信息监测表,进行周期性的维护更新。
根据建立的路径信息监测表,获取节点以及链路的信息,得到实时链路负载均衡度V,表示为:

其中:Lp=Max{Lij|(i,j) ∈p},i和j用来表示路径上的节点位置,p是用节点表示的路径集合,Lp表示当前转发路径的链路负载,把该路径上各节点间最大的负载作为链路负载;Bm是该条路径的实际带宽n为当前转发路径的链路数目,Bmi表示每条转发路径的实时带宽情况;Cp是数据中心网络的所有数据流量,即所要处理的整体网络负载;B是建设时总的网络带宽,表示为B=N×BMAX,N为总的传输链路条数,BMAX为链路的最大传输带宽。以比值形式计算所有转发路径的负载均衡度,当负载均衡度越高时,说明这条链路上承载的流量越重,更需要通过重新选路来均衡负载,即触发自适应路由模块工作,开始执行SMO-LBA 择路。依据大量研究中对负载均衡度阈值的设定,本文假设满足触发条件的最大负载均衡度阈值Vth为75%。
SMO-LBA 机制的原理是:首先,初始化网络中的数据流,将其分为多个小组来尽量减少竞争的压力,以便提高寻优效率和寻找最佳转发路径;其次,对于各小组,将寻优过程分为本地领导者(Local Leader)阶段和全局领导者(Global Leader)阶段,从局部到全局的顺序不断反馈更新,更新其在组内的最优结果;最后,全局领导者根据反馈结果更新至最优值,若结果未达到预先设定的阈值,则将组分为更小的组,重复执行上述步骤,直到找到最优的转发路径。
首先对所需相关参数初始化,构造数量为N的蜘蛛猴种群,DFi(i=1,2,…,N)是一个D维变量,代表种群中的第i只蜘蛛猴,即作为被优化问题的潜在解,按式(2)对其进行种群初始化:
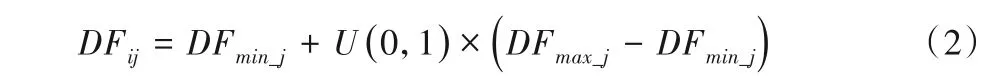
式中:DFij是第i只蜘蛛猴的第j维分量;DFminj和DFmax_j是第j维上的边界;U(0,1)是[0,1]上的随机数。
在本地领导者阶段,每个DF根据本地领导者和小组信息更新在网络中的节点位置,计算新节点位置相应的适应度值Fit(DFi):

其中:f(DFi)表示当前路径的链路利用率;f(DFi)越小说明此路径的占用程度越小,更易被选择为解决负载问题需要的转发路径,计算出的适应度值相应变高,在位置更新过程中,新位置的适应度值高于原位置,则更新位置。
在继承更新原位置的信息时,为了使算法在后期迭代的过程中有较好的局部搜索能力,考虑在位置更新中引入一个基于目标函数的动态自适应惯性权重[14]为w,由w表示在每次更新中,新位置对于原位置信息继承的程度,通常取w为0到1 之间的常数。本文将链路利用率作为目标函数引入自适应惯性权重中,即把优化问题与蜘蛛猴个体的适应度建立映射关系,当随着各负载链路情况发生变化,其所对应的适应度也相应变化。首先计算λ(k):
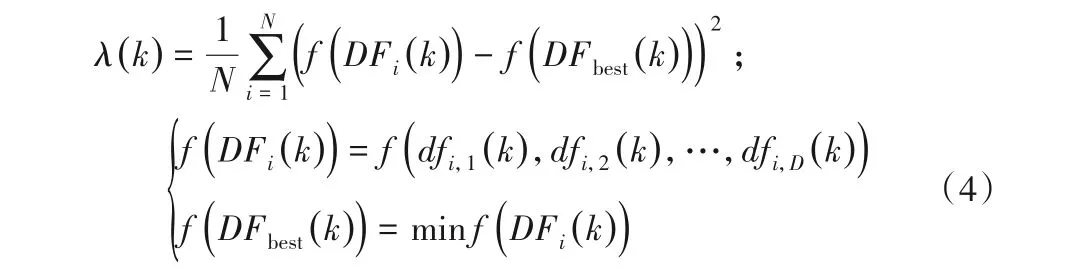
其中:k(k=1,2,…) 为更新次数;f(DFi(k)) 为第i(i=1,2,…,N) 只猴子第k次更新相应位置的目标函数值;f(DFbest(k))为第k次更新的最优蜘蛛猴相应的目标函数值。根据λ(k)得到对应的w:
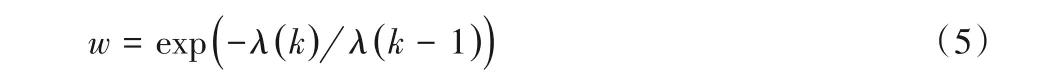
此处,当k=1时,取λ(0)=0.9,λ(k)用来衡量惯性权重w变化的平滑程度。
因此本地领导者阶段的位置更新公式为:
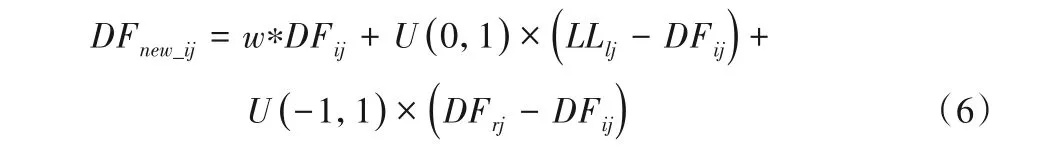
其中:LLlj和DFrj分别表示第l组内本地领导者和第r只蜘蛛猴的第j维分量,r可以随机选取。
完成本地领导者的寻优过程后,进入到全局领导者阶段,在此阶段蜘蛛猴通过全局领导者和本地小组信息更新在全局层面的位置。全局领导者阶段更新公式如下:

其中:GLj为全局领导者的第j(j∈{}1,2,…,D)维分量,且j随机选择。
在全局领导者阶段,蜘蛛猴种群对于全局的搜索能力变差,需要增大它对于全局的开发能力,因此在适应度计算的基础上,通过适应度值再得到一个概率计算公式如式(8),用来获得更大的开发几率:

通过本地领导者阶段和全局领导者阶段的位置更新过程,最终获取在分组情况下全网中最优转发路径,对超过负载阈值的数据流选择最佳转发路径,通过控制器下发流表的形式,形成新的流表转发策略,由流表下发模块匹配转发。
2 仿真与性能评估
2.1 仿真环境
本文使用Mininet2.3.0 版本仿真软件[15]和Ryu 开源控制器完成仿真实验平台搭建,模拟基于SDN 的数据中心网络运行环境,部署网络实现架构中的各模块。Mininet 是一个轻量级的虚拟网络仿真平台,它可以模拟一个真实完整的网络环境,支持OpenFlow 协议与Ryu 控制器相连接,Ryu 是一款基于Python编写的开源SDN控制器,作为算法实现的控制平台,使用Iperf工具,模拟产生各主机之间的数据流量。
因为胖树网络具有多层次的树状拓扑结构固有的容错能力,因此本文选择构建一个K=4 的简单胖树网络拓扑[16-17],它能够在核心层对多路径负载及时处理,故选用它来模拟数据中心网络场景,如图2 所示。其中,汇聚层和边缘层分为4个Pod,每个Pod 里都分别有2 台交换机在汇聚层和2 台交换机在边缘层,核心层共有4 台核心交换机,每台交换机端口都与汇聚层交换机向上的级联口相连接,网络所支持的服务器总数为16台。

图2 K=4的胖树网络拓扑Fig.2 Fat-tree network topology with K=4
为完成蜘蛛猴种群在本地领导者阶段和全局领导者阶段的位置更新,在进行模拟仿真实验时,将蜘蛛猴种群规模设置为数量为N=50的种群[13],模拟数据在网络中的寻优过程。
2.2 对比分析
搭建完整仿真实验平台之后,将数据中心网络与Ryu 控制器远程连接,用Iperf 流量工具模拟数据中心网络多路径数据流量,设置链路带宽为100 Mb/s,控制器监控周期为5 s,逐步增大负载进行对比实验。选取节点过载次数、传输时延和平均链路利用率三个性能指标,将本文算法与FSC-CCRA 和ECMP算法进行性能对比实验,得到的实验对比效果如下。
1)节点过载次数。
节点过载次数表示在数据流转发过程中,由于负载过大使得节点发生过载情况的次数,转发路径的过载次数反映算法均衡负载的能力。若节点过载次数过大,表示在针对数据中心多路径负载均衡时,算法不能根据实时网络状态,合理均衡负载完成数据转发。节点过载次数实验结果如图3所示。

图3 不同算法节点过载次数对比Fig.3 Comparison of node overload times of different algorithms
从图3 可以看出,ECMP 算法处理负载时,出现过载的情况最严重;FSC-CCRA 处理负载有一定效果,但随着负载的逐渐增加,也开始出现一定程度的过载问题,但发生节点过载的情况不严重;SMO-LBA 实现的效果最优,针对负载过大的路径自适应重新选路,动态调整转发路径,避免节点过载情况发生,但当系统流量达到饱和时,网络处理负载的能力受到限制,最终各算法节点过载次数趋近相同。
2)传播时延。
传播时延作为数据转发过程中的常见指标,是指从发送端发送数据开始,到接收端接收数据总共经历的时间。不同算法选路策略不同,导致传播时延出现差异,实验结果如图4所示。由图4 可看出:实验最初三种算法传播时延都同步上升,这是因为网络还没有数据流量转发行为,需要上报Ryu控制器计算转发路径,下发安装流表导致时延上升,但很快就回落到正常水平。当负载从10 Mb/s 增大到42 Mb/s 的过程中,系统链路健壮性良好,三种算法都能有效处理负载,所以传播时延无太大差异。当负载超过42 Mb/s时,系统承载流量的加重使不同算法处理负载的能力出现差别,ECMP 算法传播时延有较大变化,FSC-CCRA变化趋势与SMO-LBA相近,但传播时延还是呈现出较小的抖动,而本文的SMO-LBA 传播时延虽然也有抖动现象,但基本平稳且传播时延低于基于流调度代价的拥塞控制路由算法。

图4 不同算法传播时延对比Fig.4 Comparison of propagation delay of different algorithms
3)平均链路利用率。
平均链路利用率取所有链路利用率的平均值,表示为网络运行时所有链路的占用带宽与总带宽之比,计算公式为:

式中:bmi(t)表示在t时刻,数据在第m条路径第i条链路的传输带宽;N为总的传输链路条数;BMAX为链路的最大传输带宽。平均链路利用率实验结果如图5所示。

图5 不同算法平均链路利用率对比Fig.5 Comparison of average link utilization of different algorithms
从图5可看出:ECMP算法只是将负载均衡在所有等价路径转发,容易导致链路拥塞,故它的平均链路利用率最低;FSC-CCRA 对数据进行大小流区分,在网络运行前期可以较好均衡负载,但随着流量负载加重,由于自适应不足会造成局部链路承载流量过多,所以其链路利用率变化逐渐变缓;而SMO-LBA 综合考虑了局部和全局的寻优,基于网络实时链路负载,选取全网最优转发路径,因而其平均链路利用率呈现一定优越性。
2.3 实验结论
综上,实验结果表明,当数据中心网络负载较少、多路径带宽足够时,三种算法仿真效果相当;但随着数据流量的增大,对比算法处理负载的能力表现不足,出现局部负载过重或网络拥塞问题,网络系统无法承载当前流量,而本文提出的SMO-LBA 能够实现全局动态寻优,通过重新选路自适应调整流量负载,实现网络更高效的转发。
3 结语
本文基于SDN 体系结构,针对数据中心网络无法感知底层网络细节以及缺少动态自适应选路方法的问题,提出了一种基于蜘蛛猴优化的自适应多路径负载均衡算法(SMO-LBA),通过Ryu 控制器南向接口获取网络实时状态及负载信息,对负载均衡度较高的路径,调用自适应路由模块重新选路,从局部到全局的选路过程使得数据中心寻优精度提高,选择的路径对负载均衡的改善效果更好,最后发挥软件定义网络集中控制的作用,下发流表转发数据中心网络流量。经过在Mininet仿真平台进行实验,结果表明本文的SMO-LBA明显提高了链路利用率,呈现的寻优效果也更好,能够较好实现基于SDN 的数据中心网络的自适应多路径负载均衡。本文选用胖树网络拓扑进行实验,但实际的网络传输场景要复杂很多,因此在之后的工作中,将研究更为复杂的数据中心网络场景来进行模拟负载均衡实验。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
移动通信(2021年5期)2021-10-25
金桥(2018年4期)2018-09-26
小朋友·快乐手工(2018年3期)2018-04-22
小学阅读指南·低年级版(2017年6期)2017-06-12
科技创新导报(2016年27期)2017-03-14
小朋友·快乐手工(2015年1期)2015-03-13
当代贵州(2014年13期)2014-09-21
