
基于知识图谱和自动机器学习的软件缺陷预测
2021-04-22 02:45李鹏宇江云松滕俊元
空间控制技术与应用 2021年2期
李鹏宇, 江云松, 高 猛, 滕俊元
北京轩宇信息技术有限公司, 北京 100090
0 引 言
随着航天软件的数量、复杂性和规模急剧增加,软件系统变得日趋庞大和难以驾驭,软件的体系结构也从过去的单任务顺序运行逐渐演变为多任务并发运行,软件的开发和集成变得越来越复杂,航天任务对软件的功能要求越来越强大,可信性要求越来越高.航天软件缺陷的主要特点是强实时中断问题多、故障处理策略和状态转换时序约束强、太空辐射可能改变软件运行状态等.软件测试作为保证软件产品质量,提升软件可信性的重要措施,目前在第三方确认测试中,主要通过代码审查和动态测试发现软件函数模块中的缺陷,然而这种静态和动态的测试方法对人的能力、经验依赖较大,需要投入大量代码审查时间和动态测试覆盖率分析,很难满足航天软件研制和测评进度紧、质量高的要求.
近年来,软件缺陷预测[1-3]成为智能软件工程领域研究的热点,软件缺陷预测主要是根据历史数据来预测软件中潜在的缺陷,国内外学者针对软件缺陷预测模型和方法进行了大量的学术研究,取得了很好的成效.WAHONOZAI[4]从研究趋势、数据集、方法和框架3个维度,阐述了2000~2013年的软件缺陷预测研究成果.HASSAN等[5]总结了2009~2018年的软件缺陷预测研究成果,包括6个类别(Bayesian算法、Decision Tree算法、Clustering算法、Artificial Neural Networks算法、Deep Learning算法、Ensemble Learning算法)30种软件缺陷预测模型.CHRIS等[6]提出AutoWEKA分类算法的组合选择和超参数优化,通过3种集合方法,14种元方法,30个基本分类器,以及各种超参数设置,实现了构建网络结构、调整网络结构、调整超参数、模型评估等过程全部自动化完成.
通过软件缺陷预测能够在测试策划阶段提供函数模块缺陷倾向性排序的评判依据,有助于代码审查合理分配资源,提高测试工作效率,提升软件测试质量.但是软件缺陷预测技术在软件工程实践领域却没有得到很好的应用,究其原因:软件缺陷预测效果除了与缺陷数据集分布规律有关外,还主要受限于软件缺陷预测模型,不稳定和召回率低效的软件缺陷预测模型难以在行业领域应用.如何有效提高软件缺陷预测模型各项性能评价指标,已成为软件缺陷预测在航天行业应用亟待解决的问题.
在人工智能和大数据的背景下,知识图谱[7]、自动化的机器学习[8]和深度学习技术日益受到学术界和工业界的重视.人工智能的核心是算法的设计,自动化的机器学习和深度学习技术降低了人工智能应用的门槛,有助于完成人工智能项目的开发和部署.凭借这种低门槛、自动化的特性,自动化机器学习有望在未来几年中彻底颠覆传统的测试方式,让人工智能真正普及起来.
本文提出了基于知识图谱辅助自动化机器学习的软件缺陷预测模型方法,首先在第1、2节阐述构建软件缺陷预测模型领域的知识图谱,描述软件缺陷预测模型方法AutoKGGAS和工作原理.其次在第3节通过实证研究,验证AutoKGGAS软件缺陷预测模型与传统经典缺陷预测模型的性能对比测试、以及AutoKGGAS和AutoWeka性能对比测试.最后第4节给出结论.
1 面向软件缺陷预测领域的知识图谱构建
构建领域知识图谱包括:知识获取、知识抽取、知识融合、知识存储、知识计算和推理.软件缺陷预测模型领域知识图谱构建流程如图1所示.
构建软件缺陷预测领域知识图谱的数据模式,对整个知识图谱的结构进行定义,采用自顶向下的方法和自底向上的方法相结合构建软件缺陷预测模型领域知识图谱.软件缺陷预测模型分类包括贝叶斯分类器、神经网络分类器、功能分类器、元分类器、惰性分类器、规则分类器、时间序列分类器、树结构分类器、其他分类器等,每种软件缺陷预测模型提供标准化输入参数,训练和测试各种分布规律的数据集,多维度评价指标构建软件缺陷预测模型知识图谱.

图1 知识图谱构建流程Fig.1 Knowledge graph construction process
知识获取的数据包括:软件缺陷预测模型性能测试的结构化数据,软件缺陷预测模型扩展列表半结构化数据,以及软件工程期刊、论文中各种软件缺陷预测模型纯文本非结构化数据.其中,通过编写自动化脚本,获取软件缺陷预测模型性能测试的结构化数据的流程如图2所示.

图2 结构化数据知识获取的流程Fig.2 Structured data knowledge acquisition process
知识图谱中的知识融合包括模式层的融合与数据层的融合.知识抽取为RDF(resource description framework)[9]三元组的形式,RDF的数据结构主要包括两种形式:节点和边.其中节点代表实体、属性,边代表实体间或实体与属性间的关系.将上述构造的RDF数据导入图数据库(graph database)存储.图数据库支持的图结构、实体和关系表示、查询机制.知识图谱的计算包括图挖掘计算和基于规则的推理.从Percision、Recall、PRC(precision recall characteristic)、ROC(receiver operating characteristic)、F-Measure、MCC(matthews correlation coefficient)6个评价指标维度聚类,知识图谱推荐每个评价指标前20名软件缺陷预测模型数据,作为AutoKGGAS自动化搜索的热启动条件.
2 基于AutoKGGAS的软件缺陷预测方法
2.1 Stacking集成学习方法
对于Stacking堆叠结构的集成学习,集成选择配置包括基层分类器和元层分类器的选择配置.Stacking堆叠结构面临的难点如下:
(1)泛化精度高的 Stacking 配置往往是领域相关的,即对于不同类不平衡或类重叠的数据集,最佳的 Stacking 配置是不同的,因此同一个配置运用在不同数据集上,得到的 Stacking 分类器的准确率就可能不同.
(2)Stacking 配置的泛化能力是由基分类器和元分类器的组合决定的,这些采用固定配置的方法都偏重于元分类器的选择,而忽略了基分类器如何选择的问题.
2.2 遗传算法(Genetic Algorithm)
DEAP(distributed evolutionary algorithms in python)[10]是一个新颖的遗传算法进化计算框架,用于快速原型设计和测试.旨在使算法清楚和数据结构透明,可以在并行机制之间完美协调.
2.3 AutoKGGAS实现方法和工作原理
AutoKGGAS软件缺陷预测模型方法的基本思想如图3和图4.
(1)获取114个软件缺陷预测模型(软件缺陷预测模型来源于Weka 3.9.3)性能测试.
(2)借助于知识图谱推荐的各评价指标排名,作为软件缺陷预测模型自动化搜索的热启动输入条件.
(3)使用DEAP遗传算法框架构建自动化搜索优化.
(4)在meta-Stacking(元分类器堆叠)基础上逐层递归,查找可被meta-Stacking替换的模型结点.
(5)根据不同的评价指标,优化不同最佳的Stacking堆叠模型结构.
AutoKGGAS软件缺陷预测方法流程如图4所示.

图3 AutoKGGAS基分类器选择配置Fig.3 AutoKGGAS base classifier selection configuration

图4 AutoKGGAS软件缺陷预测方法流程Fig.4 AutoKGGAS software defect prediction method flow
3 实验和评估
在样本数量和缺陷率各种不同的数据集条件下,运用本文提出的基于知识图谱辅助自动化机器学习的软件缺陷预测模型和传统经典软件缺陷预测模型进行对比实验测试,实验环境:Windows 7 Service Pack1、Intel(R) Core(TM) i5-3320M CPU @2.60 GHz RAM 8 GB,Open JDK1.8.0,Weka 3.9.3.
3.1 自动化机器学习软件缺陷预测原型
自动化机器学习软件缺陷预测原型配置包括预测类型的选择、数据集的选择、知识图谱推荐缺陷预测模型数量、遗传算法配置(随机种子、遗传代数、种群规模、变异率)、模型深度、评价指标等,配置界面如图5所示.

图5 软件缺陷预测原型配置界面Fig.5 Software defect prediction prototype configuration interface
3.2 实验对象和评价指标
NASA的13个数据集[11-12]全部是美国航空航天局的实际工程项目,包括了卫星飞行控制软件、模拟器软件和地面站测试软件等.数据集覆盖C、C++、Perl、Java共4种编程语言.NASA数据集中,函数模块缺陷率百分比分布为0.41%~48.80%,数据集中的分类标签是函数模块是否有缺陷,函数模块的属性包括代码行数、McCabe度量值、Halstead度量值等.NASA数据集具体描述如下表1所示:
评价实验对象6个性能指标[13-14]包括Percision、Recall、F-Measure、MCC、ROC、PRC.

表1 NASA数据集软件缺陷相关情况Tab.1 Software defects related to NASA data set
3.3 实验设计
在命令行模式下,通过自动化脚本测试,每次测试数据集拆分为66%作为训练集,34%作为测试集.每个软件缺陷预测模型运行10次,取平均值作为模型评价指标.
3.3.1 知识图谱的缺陷预测模型数据获取实验设计
按照软件缺陷预测模型类别划分,114个软件缺陷预测模型(取默认参数)实验提供知识图谱数据可视化分布图,按照数据集划分,在NASA的提供的开源13个数据集,从Percision、Recall、F-Measure、MCC、ROC、PRC 6个评价指标维度聚类推荐软件缺陷预测模型知识图谱数据.
3.3.2 基于AutoKGGAS自动化机器学习实验设计
从13个数据集中选择4个有代表性的数据集CM1、KC4、PC1、PC4,按照知识图谱推荐的评价指标F-Measure、MCC、ROC、PRC前20名软件缺陷预测模型作为基类分类器和元类分类器,实验设计如下:
(1)AutoKGGAS与经典软件缺陷预测模型对比测试
实验1:在PC1数据集ROC评价指标的情况下,对比AutoKGGAS自动化机器学习模型与知识图谱推荐的前20名经典软件缺陷预测模型测试.
实验2:在KC4数据集F-Measure评价指标的情况下,对比AutoKGGAS自动化机器学习模型与知识图谱推荐的前20名经典软件缺陷预测模型测试.
实验3:在PC4数据集MCC评价指标的情况下,对比AutoKGGAS自动化机器学习模型与知识图谱推荐的前20名经典软件缺陷预测模型测试.
(2)AutoKGGAS与AutoWeka自动化模型对比测试
实验4:在NASA数据集JM1、KC1、KC3、KC4、MC1、MC2、MW1、PC1、PC3、PC4、PC5条件下,从评价指标Precision、Recall、F-Measure、MCC、ROC、PRC六个维度,对比AutoKGGAS与AutoWeka缺陷预测模型测试验证.
3.4 实验结果和分析
3.4.1 知识图谱的缺陷预测模型数据实验结果分析
按照数据集划分,在NASA的提供的开源13个数据集,从Percision、Recall、F-Measure、MCC、ROC、PRC 6个评价指标维度的知识图谱推荐数据可视化如图6所示.
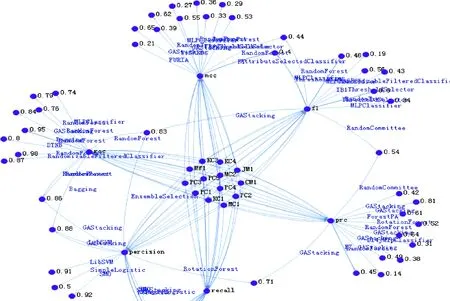
图6 知识图谱推荐数据可视化Fig.6 Knowledge graph recommendation data visualization
3.4.2 AutoKGGAS自动化机器学习实验结果分析
(1)AutoKGGAS与经典缺陷预测模型测试结果分析
实验1:在PC1数据集的情况下, AutoKGGAS模型ROC评价指标为0.887表现最优,ROC对比指标如图7.
实验2:在KC4数据集的情况下, AutoKGGAS模型F-Measure评价指标为0.832表现最优,对比指标如图8.
实验3:在PC4数据集的情况下, AutoKGGAS模型MCC评价指标为0.570表现最优,MCC对比指标如图9.

图7 PC1数据集ROC评价Fig.7 PC1 data set ROC evaluation
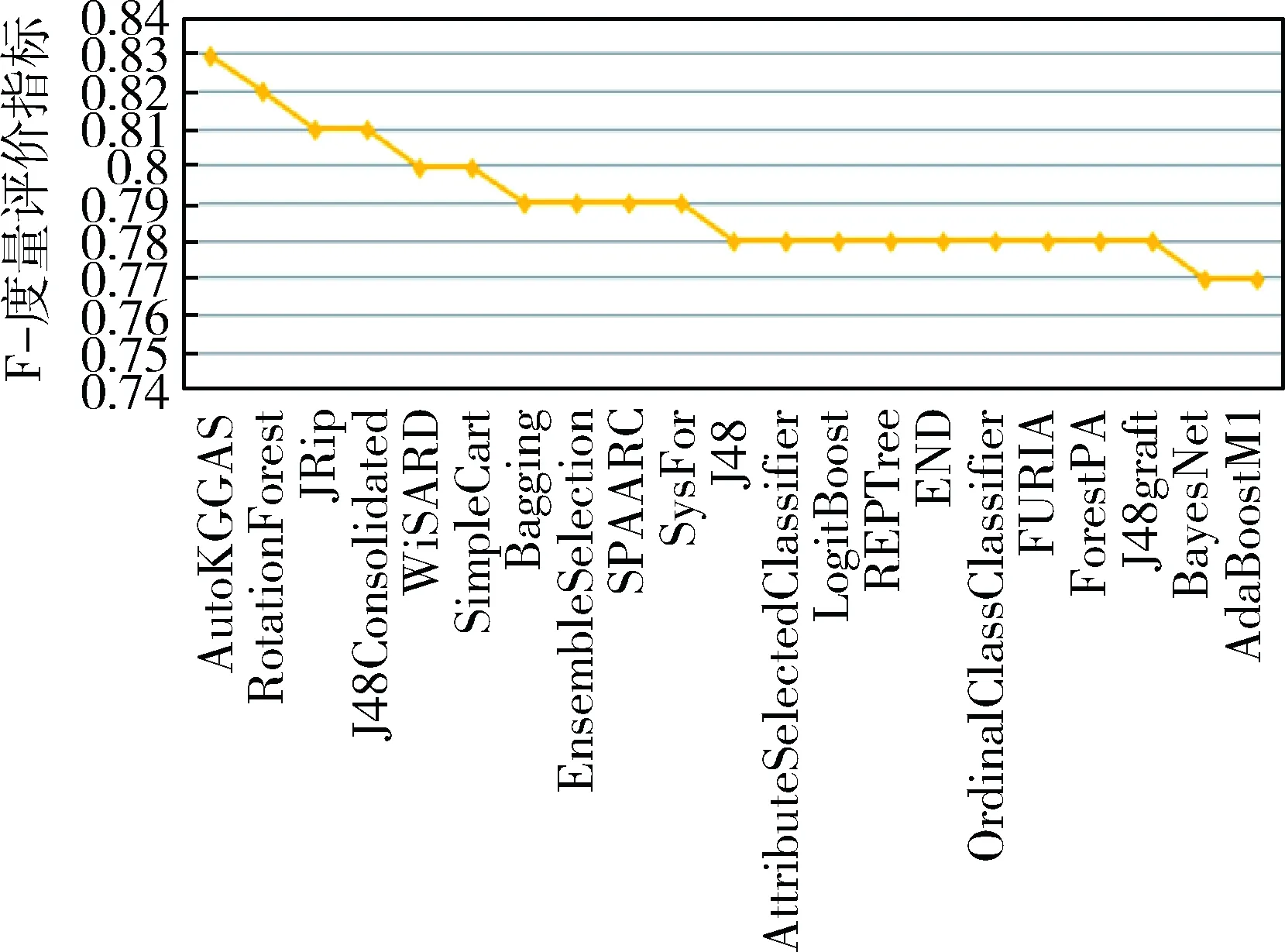
图8 KC4数据集F-Measure评价Fig.8 KC4 data set F-Measure evaluation
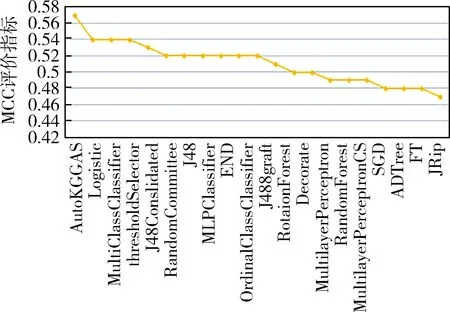
图9 PC4数据集MCC评价Fig.9 PC4 data set MCC evaluation
(2)AutoKGGAS与AutoWeka自动化模型实验结果
实验4:采用AutoWeka自动化软件缺陷预测模型默认的相关参数,在NASA数据集JM1、KC1、KC3、KC4、MC1、MC2、MW1、PC1、PC3、PC4、PC5条件下,从评价指标Precision、Recall、F-Measure、MCC、ROC、PRC 6个维度对比, AutoKGGAS性能指标超越与AutoWeka缺陷预测模型.其中AutoKGGAS与AutoWeka性能Precision评价指标如图10.
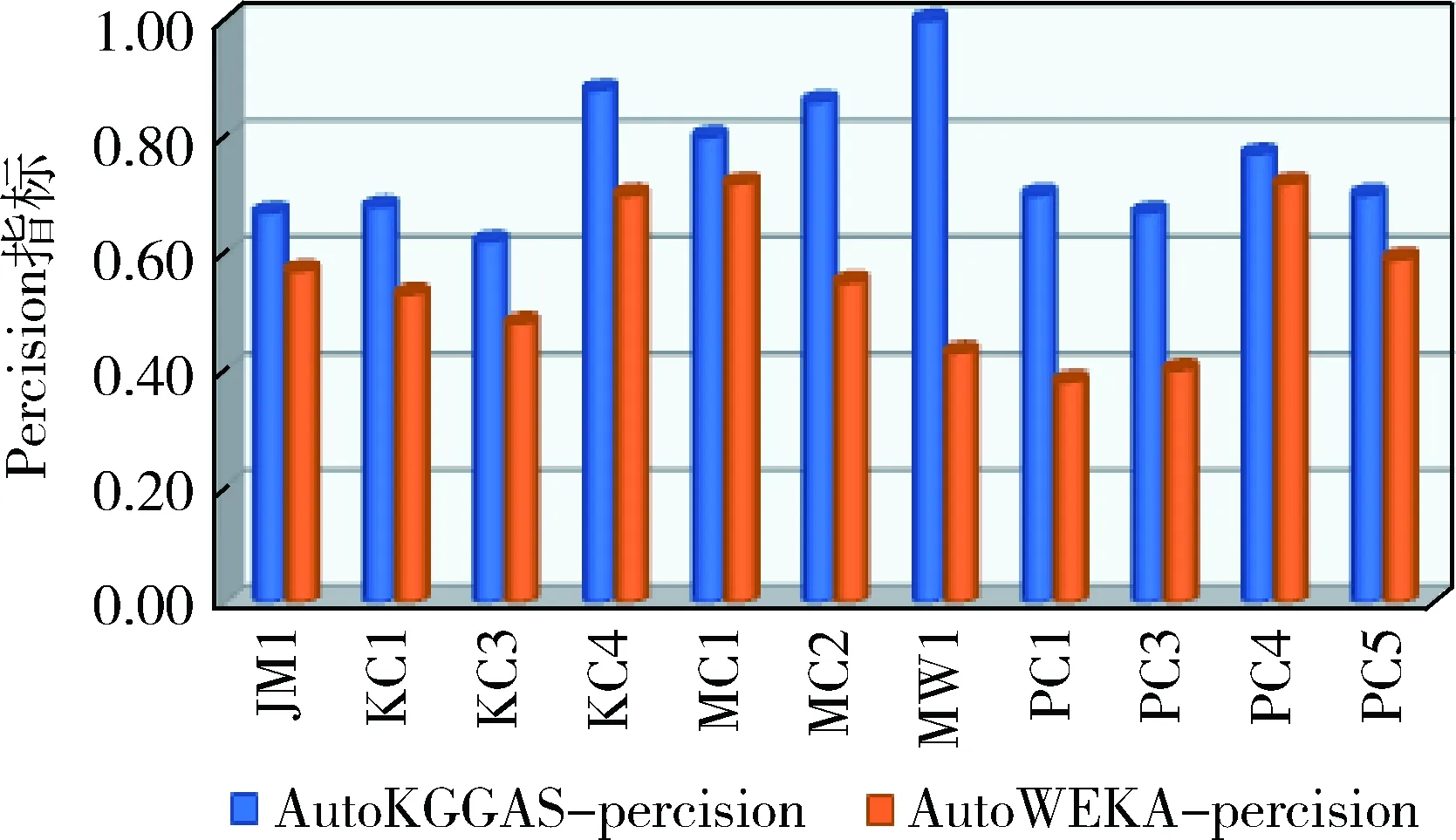
图10 AutoKGGAS与AutoWeka性能PercisionFig.10 AutoKGGAS and AutoWeka performance Percision
3.5 实验结论
根据上述实验可以得出以下结论:
(1)探索构建软件缺陷预测模型领域的知识图谱,获取1339条软件缺陷预测模型数据样本,知识图谱推荐各评价指标排序,传统经典软件缺陷预测模型作为AutoKGGAS的基类分类器和元类分类器自动化搜索的热启动输入条件,取得了较好的效果.
(2)AutoKGGAS自动化软件缺陷预测模型在不同数据集(PC1、KC4、PC4)不同评价指标(F-Measure、MCC、ROC)方面,性能优于知识图谱推荐的传统经典软件缺陷预测模型.
(3)AutoKGGAS自动化软件缺陷预测模型在NASA数据集(JM1、KC1、KC3、KC4、MC1、MC2、MW1、PC1、PC3、PC4、PC5)和6个维度评价指标(Precision、Recall、F-Measure、MCC、ROC、PRC)方面,性能优于AutoWeka自动化软件缺陷预测模型.
4 结 论
本文以软件缺陷预测模型为研究背景,探究了知识图谱的构建和应用、Stacking集成学习,并提出了基于知识图谱辅助自动化机器学习的软件缺陷预测模型AutoKGGAS方法.该方法实证研究采用NASA开源数据集实验对象和6种性能评价指标,实验结果表明, AutoKGGAS自动化软件缺陷预测模型在不同数据集不同评价指标方面,性能优于知识图谱推荐的传统经典软件缺陷预测模型.在与AutoWeka自动化软件缺陷预测模型对比测试中,全面超越取得了较好的效果.自动化软件缺陷预测模型为航天软件缺陷预测辅助代码审查测试提供了原型,在工程实践应用方面具有重要的意义.
展望未来,在其他航天领域数据集对比验证,基于自动化深度学习的软件缺陷预测和基于可解释深度学习的软件缺陷预测是未来发展趋势.
猜你喜欢
黄河之声(2022年10期)2022-09-27
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年15期)2022-07-28
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
新城乡(2018年6期)2018-07-09
软件导刊(2017年4期)2017-06-20
