
基于TF-IDF 进化集成分类器的铁路安全故障文本分类*
2021-04-24 11:36王富章赵俊华李高科
电子技术应用 2021年4期
高 凡 ,王富章 ,张 铭 ,赵俊华 ,李高科
(1.中国铁道科学研究院,北京 100081;2.北京经纬信息技术有限公司,北京 100081)
0 引言
安全问题历来是铁路运输的重点关注问题,在铁路安全监控体系中,为减少运营过程中可能存在的安全隐患,减少设备故障,保障系统稳定运行,安全人员根据日常巡检、专项巡检、重大节假日排查等计划定期到现场检查存在的安全生产故障隐患,并将问题记录为文本形式存储。管理人员依据这些问题记录,分析、总结与整改问题。在长期形成的海量的安全问题文本文件中,采用文本分类技术将安全问题自动归类,辅助管理人员更好地掌握与处理安全问题,在铁路安全领域的重要性日渐凸显。
一般来说,文本分类过程有以下3 个步骤[1]:预处理、文本表示和文本分类。其中,文本预处理包括分词、去除停顿词、去除不规则数据等。文本表示即将提取的文本特征转换为计算机可处理的数据类型(通常用向量表示)。文本表示方法包括词袋模型(BOW)、词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF),以及基于深度学习的Word2vec 表示方法等[2]。在构造分类器时使用的技术大体包括单个的基分类器、集成分类器以及深度学习模型[3]。集成分类器主要包含Bagging 和Boosting 两种,Bagging 的主要算法是随机森林,Boosting 的主要算法是梯度提升树。在深度学习领域,有基于深度信念网络、卷积神经网络[4-5]、循环神经网络等完成文本分类任务[6]。
目前,国内学者在铁路文本分析领域研究较多。王广采用贝叶斯网络的预测模型和自适应增强算法(Adaptive Boosting,AdaBoost)的预测模型实现天气相关的铁路道岔故障预测[7];赵阳等以故障文本信息为依据,针对高铁信号车载设备,提出贝叶斯结构学习算法(HDBN_SL)[8];李佳奇等将面向Agent 的分布式人工智能技术引入到信号设备故障诊断系统中[9];杨连报针对信号故障不平衡数据,采用SVM-SMOTE 算法对TF-IDF转换后的小类别文本向量数据随机生成,分别采用基分类器和集成分类对数据进行分类[10]。本文处理安全问题为事故故障发生前人员检查时发现的风险、隐患内容,通常包括安全问题发生的时间、地点、问题描述等关键要素[11],所以针对每一类安全问题,存在特定的关键词,本文在文本特征抽取上采用TF-IDF 表示,针对Bagging集成分类器的基础上,采用遗传算法优化,提升分类准确性[12]。
1 进化集成分类器模型
安全问题文本分类属于文本挖掘中的分类问题,应用文本分析的处理流程,进化集成分类器模型分为3层:数据预处理层、进化优化层以及智能决策层[13],如图1 所示。基于TF-IDF,数据预处理层对安全问题描述文本进行特征提取和特征向量化表示,通过基分类器决策树(Decision Tree)对上述文本进行分类并建立相应的基模型,再基于Bagging 集成分类器对预处理结果进行采样训练,产生集成分类器分类模型[14]。在数据预处理层Bagging 训练过程中产生的每个基模型的解的基础上,进化优化层使用遗传算法优化集成分类器并最终得到具有更高分类准确度的基分类器组合。最上层智能决策层为用事先定义好的指标评价模型,经调整和改进后的模型直接用于文本自动分类[15]。
2 TF-IDF 法数据处理
安全问题中存在的大量铁路专用术语,如低压过流、闭锁、红光带等,本文采用基于字典的结巴分词工具,构建了包括通用语料及专业语料的铁路安全问题语料库,以便对安全问题准确分词。
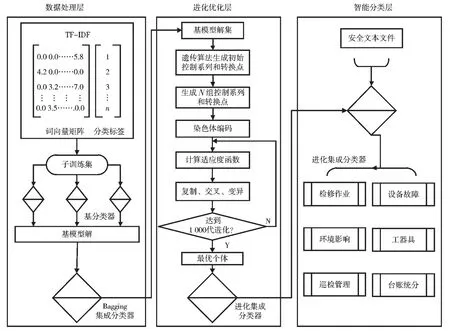
图1 进化集成分类器模型整体框架

表1 铁路信号安全问题表述
安全问题以文本形式记录在信息系统中。表1 列举了铁路领域各类别安全问题的典型实例,根据对安全问题的表述,可见虽然铁路安全问题类别较多,但在各类别中都有各自特征的高频词,同时在其他安全问题类别中呈低频出现,如图2 所示。
在本文的模型中,应用TF-IDF 将经过分词的词语过滤低频词后再计算词频。
词频(Term Frequency,TF)和逆向文件频率(Inverse Document Frequency,IDF)均表示搜索关键词在所有文档中出现的频率,前者频率越高,证明该关键词与文档相关性越高;后者频率越高,表示该关键词与文档相关性越低。所以,为了对文档中某一词语的出现次数进行归一化处理,可以通过分析该词语的词频。对于词语ti,在某个文档中的重要程度可表示为:

式中,TFi,j为词频,ni,j是词语ti在dj文件中检索到的次数,是dj中所有字、词出现的次数之和。
逆向文件频率由总文件数据除以包含某词语的文件数据取对数得到,用于度量一个词语普遍重要程度,其公式如下:

式中,IDFi为逆向文件频率,|D|为总文件数,为包含某一词语的文件数。
高权重wi,j=TFi,j×IDFi,由文档内的高词语频率乘以该词语在整个文档集合的低文件频率。
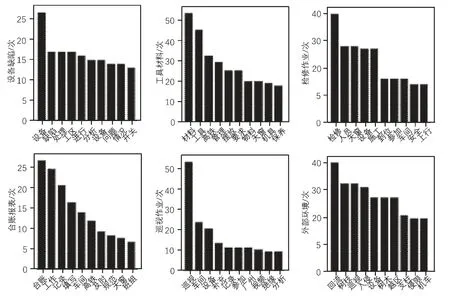
图2 安全问题内容特征分析
数据预处理流程如图3 所示。首先在既有语料库的基础上,根据不同的安全问题进行分词,同时统计特征词语所在的文档及其出现次数,然后通过TF-IDF 方法计算该特征词语的词频并过滤低频词,最终形成矩阵X和矩阵Y,其中矩阵X 代表文档特征的权重,矩阵Y 代表分类类别。
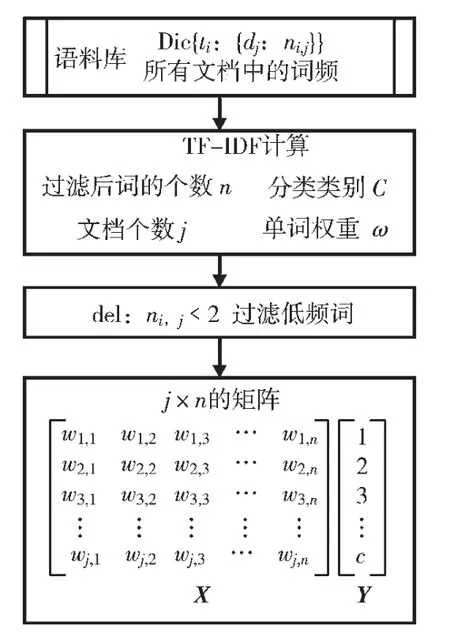
图3 数据预处理流程
3 基于遗传算法的进化集成分类器
3.1 决策树基分类器
决策树分类器是训练一棵大规模的树结构,对该树进行减枝,直到达到合适的规模和分类效率。本文采用ID3算法,ID3 依据信息增益选择属性。其中属性TF-IDF 过滤后的单词,若属性w 的值将样本集T 划分成T1,T2,…,Tm,共m 个子集,其信息增益表示为:
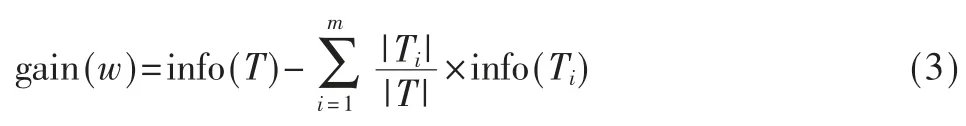
式中,|T|为T 的样本个数,|Ti|为子集Ti的样本个数。其中inf o(T)的计算公式为:
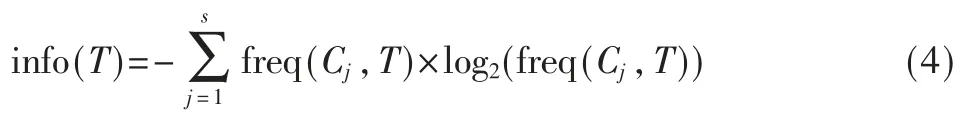
式中,freq(Cj,T)为T 中的样本属于Cj类别的频率,s 是T 中的样本的类别数量。
3.2 Bagging 集成分类器
本文采用决策树作为基分类器。假设原始训练数据量是n。在原始数据集随机抽取训练数据,抽取的数据量为n′(n′≤n),用抽取的数据训练第一个决策树,用同样的方法做m 次有放回抽取,训练m 个决策树,将测试集放到每一个决策树中预测,最后通过最优分类器与其他分类器的加权投票组合,选出表现性能最优的组合集成分类器,其学习过程如下:
(1)输入训练集
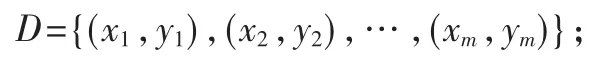
(2)过程:
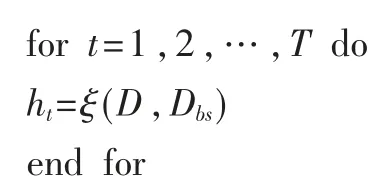
其中,ξ 为基分类器算法;T 为训练轮数。
(3)输出:
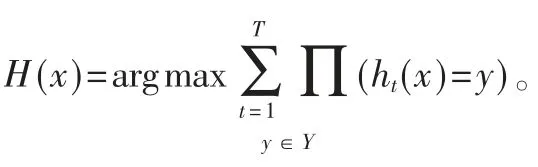
3.3 进化集成分类器
遗传算法是一种自适应全局优化的搜索算法,通过对初始解进行遗传迭代,每一次迭代通过适应度函数对当前解进行优劣进行评价,在评价的基础上产生优秀的下一代。进化集成分类器是建立在给定的某个Bagging集成分类器上,通过遗传算法优化该集成分类器并最终得到的具有更高分类准确度的基分类器组合。进化集成分类器的核心主要为基因编码及种群繁殖过程。
3.3.1 基因编码机制
进化集成分类器搜索最优解的目标为得到基分类器的最优组合。根据这一原则,本文设定50 个基分类器,种群(个体)规模为25,为了模拟基分类器是否被选择,设定个体大小(基因长度)与基分类器数量一致,采用0、1 编码基因,0 表示基分类器未选择,1 表示被选择。所以初始个体基因由0、1 随机编码长度为50 的二进制符号串组成。
3.3.2 种群繁殖过程
种群繁殖过程是将种群内个体不断地经过选择、交叉、变异的操作,把适应度较高的个体遗传到下一代,通过这一迭代过程最终得到一个优良个体的过程。可以认为,这一最终得到个体的表现型是最接近该问题的最优解。本文中迭代次数G=100。
(1)初始适应度计算:初始适应度计算以每个基分类的准确度为准,准确度越高的其适应度越高。pi(0<i<50)代表每个基分类器(决策树)的准确度,p¯代表全部基分类器的均值,σp代表全部基分类器的方差,个体适应度公式为:
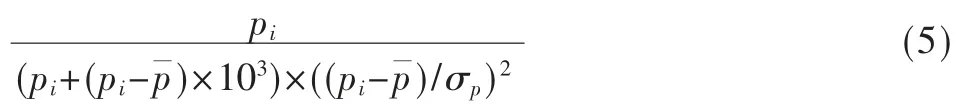
(2)选择:选择过程即根据个体适应度,选择优秀的个体遗传到下一代。本文以个体灵敏度随机选择要交叉的两个个体,个体初始灵敏度ps=0.95,个体灵敏度计算过程如下:
①s=min((ps+c×0.010),ps)
②for i=1,2,…,n do
③ps=((s-1)/(s×len(a))2-(1))×((s×len(a))2-(i))
其中,c 反映经过迭代后其准确度是否有提升,如果有提升加1。经过计算,准确度越高的个体其灵敏度就越低,越不容易被选择变异。a 为个体总数。
通过上述计算,本文将适应度最大的精英个体保留下来。
(3)交叉:对于种群中的所有个体,以随机原则将其两两搭配成对,对于每一对个体组合,设定一定的概率来交换两个个体间的部分染色体,本文设定交叉概率Pc=0.75。
(4)变异:针对个别满足变异的个体,进行随机变化。变异过程可产生新的个体,不仅增加了种群的多样性,也为寻找最优解提供了潜在的可能,本为的变异概率Pm=0.05。
(5)评价函数:经过变异后的种群用评价函数来评价个体的好坏,每个个体为一个基分类器组合(0 为选择,1 为不选择),通过评价函数式(6)计算该基分类器组合的准确度,从而得到最优解,按照准确度从大到小的原则筛选出准确度最大的个体,并将其作为精英个体保留下来。
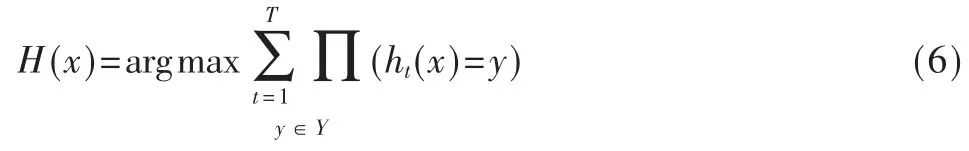
本文设置的终止条件为总的进化代数ng 超过设定代数G。
4 实验结果与分析
为分析本文提出的进化集成分类器进化过程,以某铁路局供电接触网安全问题为实例,采用精准率(Precision)、召回率(Recall)和精确值和召回率的调和均值(F-score)作为模型评价和对比的指标验证分类结果。实现数据包括6 种问题类别2 400 条数据。
精准率(Precision):

式中,TP 代表被正确检索到的样本,FP 代表被误检索到的样本,FN 代表属于此类而被误检索为其他类的样本。
图4 中显示了模型进化过程中种群的多样性(Diversity)、种群分类的平均值(AverageScore)、方差(StandardScore)以及最优值(BestScore)。由实验结果可见,当种群迭代次数达到45 次时,种群繁殖过程中的平均值、方差和分类最大值均达到最大值,种群多样性保持在80%~100%之间。
为了对比不同类型分类器对同一安全问题的分类结果,本文在以TF-IDF 方法表示安全问题文本的基础上,分别采用基分类器、Bagging 集成分类器及进化集成分类器对同一安全问题进行分类,最终结果如表2 所示。从表2 中可以看出,进化集成分类器分类指标最高,Bagging 集成分类器分类指标次之,基分类器分类指标最差。
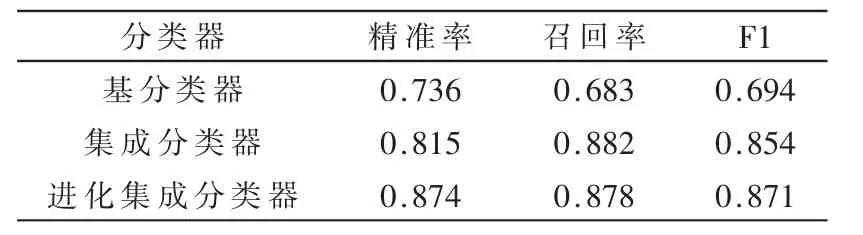
表2 分类模型结果对比

图4 种群繁殖过程
5 结论
本文采用TF-IDF 方法表示安全问题文本,通过遗传算法优化集成分类器并最终得到具有更高分类准确度的基分类器组合,提出了Evolutionary Ensemble Classifier文本分类模型,应用某路局安全接触网问题进行验证,实验证明Evolutionary Ensemble Classifier 模型在安全接触网问题具有较高的准确性,也可以为处理铁路其他文本分类问题提供参考模型。
猜你喜欢
今日农业(2022年15期)2022-09-20
红土地(2018年7期)2018-09-26
建筑科技(2018年6期)2018-08-30
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国交通信息化(2016年5期)2016-06-06
电测与仪表(2016年18期)2016-04-11
电测与仪表(2014年15期)2014-04-04
天津冶金(2014年4期)2014-02-28
当代畜禽养殖业(2014年10期)2014-02-27
