
基于全局与局部融合的相关性对齐跨模态检索
2021-04-25 05:23张勇
现代计算机 2021年6期
张勇
(贵州师范大学,贵阳550000)
1 介绍
跨模态检索[1-5]以不同模态间语义关联为基础,通过建立不同模态的共同表征,实现以一种模态输入搜索语义相似的其他模态样本,其关键问题是不同模态的表征及匹配对齐。随着社会数字化的快速发展,如何通过一种模态的输入查询到语义相似的其他模态的信息成为亟需解决的问题。
由于跨模态数据呈现底层特征异构、高层语义相关的特点。如何表示底层特征、怎样对高层语义建模以及如何对模态间的关联建模,这些都是跨模态检索面临的挑战。不同模态数据拥有不同的数据形式,数据特征的结构和分布都存在一定的差异,实现跨模态检索需要解决模态之间的异构性问题,使得不同模态数据可以进行相互比较。如今,实现跨模态检索的方法越来越多,检索准确率越来越高。现有研究在基于哈希变换上做了大量工作,主要思想是利用不同模态样本之间的信息,通过将不同模态样本的表示映射到一个公共的汉明(Hamming)空间中,然后在这个空间中实现不同模态的跨模态检索。
基于哈希变换的跨模态检索可分为传统方法和深度学习方法。传统方法是特征提取过程独立于哈希代码学习过程,这意味着手工制作的特征可能不能最优地与哈希代码学习过程兼容。因此,现有的手工特征的CMH 方法在实际应用中可能无法取得令人满意的性能。代表性的方法如:Bronstein 等人[6]提出的交叉模态相似敏感哈希(CMSSH)等。深度学习方法则更为复杂,它利用神经网络强大的建模能力,构建多层神经网络模型,使用激活函数进行非线性映射,优化损失函数学习映射方法,将原始特征映射到公共汉明空间中进行哈希学习。代表性的方法如:蒋等人[1]提出的深度跨模态哈希(DCMH)等。但是他没有考虑异构数据的相关性,对于跨模态检索来说至关重要。为了更好地利用异构数据的相关性,从而提高检索的准确性,本文提出了一种端到端的方法。用于图像和文本模态的两个深度神经网络都包含语义层和散列层,因此将学习两个散列函数。对图像和文本网络我们分别学习全局特征和局部特征,并分别对全局特征和局部特征的非均匀分布进行对齐,以很好地挖掘模态间相关性。
2 相关工作
跨模态检索的目的是学习一个共同的表示空间,在该空间中可以直接测量不同模态样本之间的相似性。根据特征表示的类型,学习公共表示空间的方法通常可以分为两类:实值表示学习[10-11]和二进制值表示学习[12-13]。本文使用的方法属于后者:二进制值表示学习,也称为交叉模式哈希学习。跨模态散列方法将不同模态的数据投影到公共汉明空间中,用于跨模态相似性检索。最近,已经提出了各种跨模式散列方法。布朗斯特等人[6]提出了CMSSH,它采用增强技术来保持模态内的相似性。张等人[7]提出的模式匹配算法利用标签信息重构语义相似度矩阵,以保持模式间的最大相关性。由丁等人[8]提出的CMFH 使用集合矩阵分解来学习不同模态的统一散列码。林等人[9]提出SePH,该算法将异构数据的语义信息转换成概率分布,并最小化库勒贝克-莱布勒散度来学习哈希码。上述跨模式散列方法都是基于手工特征的方法。这些方法的一个缺点是特征提取过程独立于哈希学习。最近,利用神经网络的深度学习已经被广泛地用于从零开始的特征学习,并且具有良好的性能。因此,他们也提出了一些基于深度学习的跨模式散列方法。DCMH[1]在端到端深度框架中同时学习了深度功能和散列函数。然而,DCMH 只使用全局特征,丢失了局部细节所携带的语义信息,从而降低了其检索结果的准确性,同时没有关注语义相关性对齐。为此我们提出了关于关注全局信息和局部信息的网络框架,同时我们还关注我们提取到的异构信息的语义相关性对齐。

图1 我们所提出方法的框架图
3 方法提出
我们提出的方法的概述如图1 所示。图像和文本模态分别有两种网络。对于成对的图像和文本,将图像的原始像素输入到图像网络中学习哈希码,同时将文本的单词包特征输入到文本网络中学习哈希码。通过使用反向传播算法和小批量随机梯度下降来训练网络,将学习到高效的散列函数。
3.1 符号说明
3.2 网络结构
对于全局特征,图像我们使用CNN-F 来提取全局特征f1,文本使用BOW 来提取文本全局特征g1,以获得整体的信息。对于局部特征部分,图像使用VGG 结合目标金字塔网络来提取高语义高分辨的多尺度特征f2,文本使用长短时记忆网络(LSTM)来提取文本局部特征g2,以获得局部细节信息。
3.3 哈希码学习
设融合全局特征和局部特征,得到图像全部特征为f,文本所有特征为g。
为了挖掘语义相关性,在学习过程中保留了模态间的相似性,并将两个样本特征的相似概率定义为:

首先,我们使用交叉熵损失来保持来自图像和文本模态网络的散列码的模态间相似性:

其次,为了更好地挖掘模态间相关性,将非均匀数据的分布对齐如下:

其中Cx和Cy分别表示图像和文本模态的协方差矩阵,它们被定义为:
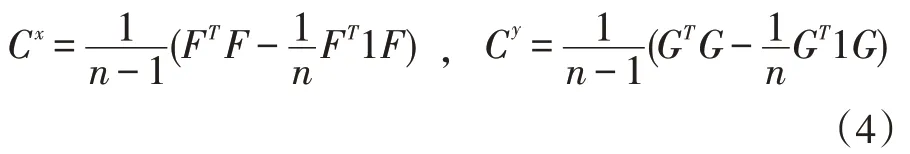
其中1 ∈ℝn是所有元素都为1 的向量。
此外,为了通过输入成对的图像和文本使两个网络的输出接近相同的散列码B,有:
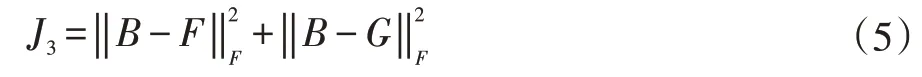
最后,添加位平衡约束来平衡“+1”和“1”的数量,这意味着哈希码的每个位都有“1”或“1”的均等机会,因此语义信息可以在不同的汉明维数上均匀分布[1]。

基于上述分析,目标函数如下:
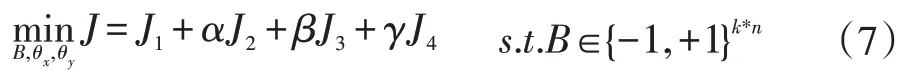
其中α,β,γ是三个超参数。这里总结一下目标函数中各个项的作用:J1可以保留语义相关性,J2保证相关性对齐。J3可以保持哈希码的相似性,而J4可以平衡哈希码。
4 实验
我们提出的方法是在NVIDIA GTX 1080 TI GPU上用开源PyTorch 框架实现的。在两个多标签数据集上的实验验证了其有效性。
4.1 数据集
为了充分评估我们的方法的有效性,我们在MSCOCO 数据集公共多标签数据集上进行了测试。数据集详细介绍如下:MS-COCO 数据集最初是为图像理解任务收集的,包含82783 个训练图像和40504 个验证图像。每个图像都有相应的文本描述和预定义的81维语义标签。在实验中,包括所有具有类别信息的图像(87081 个图像),并且使用2000 维单词包向量来表示文本。具体来说,随机抽取5000 对作为查询集和结果集。对于训练集,我们从检索集中随机抽取10000 对。
4.2 比较方法和评估指标
我们的方法与CCA、CMSSH、SCM、STMH、CMFH、SePH、DCMH 方法进行比较。由于深度方法的图像特征是原始像素,而浅层方法不能直接输入原始像素,而是需要输入提取的特征,为了公平比较,浅层方法的图像特征是从图像神经网络的fc7 层提取的。在这项工作中,我们验证了我们提出的方法两个检索任务:图像检索文本(I2T)和文本检索图像(T2I)。此外,我们使用平均精度(mAP)、召回率曲线来评估我们方法的最终性能。
4.3 实验结果和分析
表1 显示了我们方法的mAP 分数在MS-COCO数据集上相比其他方法最好,最好的方法加粗,其中散列码长度从16 位到128 位。从表中我们可以看出,基于深度学习的方法比那些应用浅层模型的方法获得更好的性能。此外,我们提出的方法在MS-COCO 数据集上获得了最好的性能,而DCMH 获得了相对较低的性能。与我们的方法相比,这是因为我们同时采用了全局特征和局部特征融合的信息以及相关性对齐,可以有效地提高检索精度。我们可以看到,在大多数比较方法上,T2I 检索任务的性能优于I2T 检索任务。这意味着文本可以比图像编码更多的鉴别信息。

表1 与基线相比在MS-COCO 数据集上的mAP,最好的性能用粗体表示
图2 显示了128 位哈希代码的在MS-COCO 数据集上不同方法的两个检索任务的精度-召回率曲线。从图中,我们可以看到我们的方法达到了最好的性能。
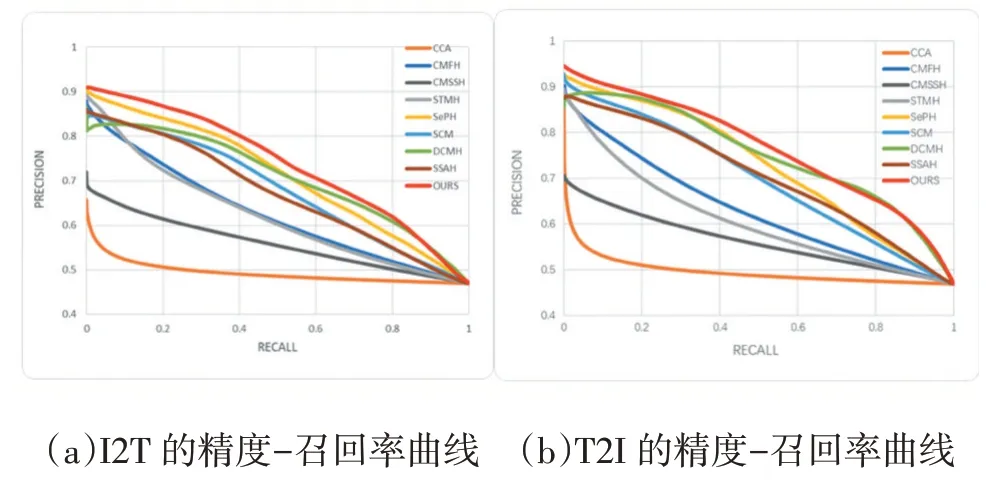
图2
5 结语
在本文中,我们提出了一种端到端的方法——具有局部和全局的相关对齐的深度跨模态散列法。基于DCMH,我们首先构造利用全局与局部信息来挖掘语义,然后采用相关对齐的方法来挖掘模态间的相关性,最后学习得到区分性哈希码。在MS-COCO 数据集上的实验表明了该方法的优越性。
猜你喜欢
中国医院院长(2022年13期)2022-08-15
小学教学研究(2022年18期)2022-06-29
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
金桥(2018年4期)2018-09-26
成长·读写月刊(2018年8期)2018-08-30
感悟(2016年8期)2016-05-14
