
基于PMI 与BTM 的船舶事故原因文本挖掘*
2021-04-29 13:31于卫红付飘云王庆武
交通信息与安全 2021年1期
于卫红 付飘云 任 月 王庆武
(1.大连海事大学航运经济与管理学院 辽宁 大连116026;2.大连海事大学航海学院 辽宁 大连116026)
0 引 言
船舶事故频繁发生,严重影响了水上交通安全形势的稳定。从历史事故中发现规律、吸取教训可以在某种程度上避免同类事故重复发生。历史事故的相关信息通常以自由文本的形式记录在事故调查报告中,如,可以从地方或国家海事局的官网中检索出大量的碰撞、搁浅、自沉等各种事故类型的船舶事故调查报告。这些事故报告为官方出具[1],对事故调查取证情况、重要事故要素认定、事故经过、事故原因、安全管理建议等内容进行了详细可靠地描述。采用文本挖掘技术从事故调查报告中提取出事故关键特征或更加隐含的特征要素之间的语义关系,能够帮助全面理解船舶事故的发生模式、更好地识别水上交通的危险因素,充分发挥事故调查报告在总结经验教训、遏止事故风险中的作用。
但是,现阶段,对船舶事故调查报告进行文本挖掘存在如下难点。
1)船舶事故调查报告是高度非结构化的文本数据,特别是中文文本具有复杂的语言结构,语法、语义、语用等常存在歧义,需要综合运用信息抽取、机器学习、概率统计、数据可视化等多种技术来进行处理。
2)船舶事故调查报告缺乏统一的模板,内容格式不规范,存储形式多样化(如“.pdf”“.doc”“.html”“.jpg”等形式),给数据清洗和数据预处理工作带来很大的困难。
迄今为止,船舶事故调查报告文本挖掘相关的成果主要以文本信息抽取研究为主,如:姚厚杰[1]在统计分析382 起船舶交通历史事故数据的基础上,利用文本挖掘提炼出船舶交通事故的风险因素。Lee Jeongseok等[2]使用文本挖掘技术从电子海图事故报告中挖掘事故原因的相关词语,并使用词云图、词语网络图等进行可视化展示。吴伋等[3]以长江内河航道419 起船舶碰撞事故报告为语料,使用分词及卡方检验等算法提取出能够表征船舶碰撞事故4要素(人为因素、船舶因素、环境因素、管理因素)的特征词。余晨等[4]采用基于规则的海事信息抽取方法,从事故报告的自由文本中提取事故发生的时间、地点、涉事船舶、事故类型等信息。
上述研究主要是从单个词语的角度展开的文本挖掘研究,即从事故调查报告中提取出与事故因素相关的特征词,继而利用这些词进行事故统计或预警等分析。
根据1篇文档的生成过程:1篇文档包含若干主题,而每个主题又对应着不同的词。1篇文档的构造过程,首先是以一定的概率选择某个主题,然后再在这个主题下以一定的概率选出某1 个词,这样就生成了这篇文档的第1 个词。不断重复这个过程,就生成了整篇文档[5]。所以,对于文本挖掘,在文本特征词提取的基础上还可以进行更深入的语义挖掘,如,挖掘词语与词语之间的关系、文档中的主题分布等。
因此,可以从词语和主题2 个层面对船舶事故调查报告进行语义挖掘。在词语层面,通过挖掘文本特征词之间的频繁共现模式,可以揭示出事故因素之间的关联关系;在主题层面,通过对若干起同类事故的事故原因文本的主题提取,可以对该类事故的原因进行系统地归纳,并且可以通过主题在文档中的分布初步量化出每种原因的发生概率。
基于此,本研究应用频繁共现词挖掘、短文本主题建模的思想和算法对船舶事故调查报告中的事故原因文本进行挖掘,试图通过词语和主题2 个层面的语义挖掘发现事故的规律、提取出事故的致因模式。
1 研究思路
研究思路见图1,其核心环节包括以下4 个方面。

图1 研究思路Fig.1 Research ideas
1)事故调查报告的获取。首先使用爬虫技术从海事局官网获取各事故调查报告的存储网址,然后通过Java编程将事故调查报告批量下载到本地。
2)事故调查报告的预处理。将以不同格式存储的事故调查报告统一转换成纯文本格式,通过文档结构分析,对事故调查报告中描述事故原因的内容进行定位,编程抽取出事故原因文本。
3)事故原因文本预处理。根据中华人民共和国交通部制定的国家标准的“水上安全监督术语”[6]构建用户自定义词典,以保证专有名词、专业术语在分词时不被拆分。在R 语言环境下,使用jiebaR算法对事故原因文本进行分词,并进一步使用百度停用词表去掉无意义的虚词。继而对事故调查报告中常见的同义词(如,“瞭望”和“了望”“船首”和“船艏”等)进行统一处理。
4)事故原因文本挖掘。从词语和主题2 个层面对事故原因文本进行挖掘。在词语层面,使用点互信息(pointwise mutual information,PMI)算法提取事故原因文本中频繁共现的词对,通过词语之间的语义关联分析出事故致因要素间的联系。在主题层面,使用双词主题模型(biterm topic model,BTM)算法对事故原因文本进行主题建模,以此对属于同一事故原因的词语进行聚类。
2 研究方法
2.1 基于PMI的频繁共现词挖掘
频繁共现词指的是2 个或2 个以上的词语经常搭配在一起使用的1种频繁模式。自然语言是随机的,词语频繁共现对揭示词语之间施事、受事、工具、处所、领属等上下文语义关系十分重要。如,{船舶,超航区,航行}这3个词频繁共现可以揭示出“船舶超航区航行”是船舶事故的常见原因之一。
PMI是挖掘词语之间关联关系的1种十分有效的统计方法[7]。对于语料库中的词语x和词语y,将x和y的点互信息记为PMI(x;y),则[8]

式中:P(x)为词语x在语料库中出现的概率;P(y)为词语y在语料库中出现的概率;P(x,y)为词语x和词语y同时出现的概率,即联合概率;P(x|y)为在词语y 出现的前提下词语x出现的概率,即条件概率;同理,P(y|x)为在词语x出现的前提下词语y出现的条件概率。
根据概率论可知,PMI(x;y)的值越大,词语x和词语y搭配使用的关联性越强[9]。
根据PMI 算法的原理,设计了从事故原因文本中挖掘频繁共现词的方法。
1)读取语料文本,构建语料库。
2)对语料库进行分词。
3)构建词语与文本的对应关系,即构建由文本ID和文本中的词组成的二维表。
4)编程计算词语之间的PMI。
5)根据业务需要设定阈值,筛选出PMI以及共现次数满足阈值条件的词对。
2.2 基于BTM的事故原因文本主题建模
2.2.1 BTM算法的基本原理
主题建模又称主题聚类,指的是通过非监督学习对文本集合中隐含的语义结构进行分组、归类[10]。传统的主题建模使用潜在狄利克雷分布(latent dirichlet allocation,LDA)算法,是David M.Blei 等[5]于2003 年提出来的1 个3 层贝叶斯概率模型。由于LDA 算法的假设之一是“1 篇文档包含了多个主题”,因此该算法特别适用于对长文本语料库进行主题建模。
船舶事故调查报告中描述事故原因的文本长短不一且以短文本居多,文本较短时会出现严重的特征稀疏、数据不足等问题,使用LDA 算法难以准确推断出文档中主题混合分布的参数以及每个词的主题属性,从而影响聚类效果。
BTM是Yan Xiaohui等[11]于2013年提出的适用于任意长度文本尤其适用于短文本主题建模的双词主题模型。双词指的是在同1个上下文中共现的词对,用户可以根据所分析的文本特征指定上下文窗口的大小。本质上说,BTM 是LDA 的1 种变形算法,二者的参数估计方法和模型训练过程中的采样算法都是一样的。BTM 最大的改进在于采用双词而不是单词作为主题建模的单元,它假设每个双词由同1个主题产生,而主题由1个定义在整个语料库中的主题混合分布产生,即BTM算法是“双词→主题→语料库”的3层贝叶斯概率模型。通常,2个词共现次数越多,其语义越相关,也就越可能属于同1个主题。因此,BTM算法使主题建模的语义更加清晰,通过双词组合也避免了短文本长度过短导致的特征矩阵稀疏、文档建模困难等问题。
BTM 算法的思路是:假设要提取的主题数为K,首先以一定的概率选择某个主题Z,然后在主题Z下抽取2 个共现的单词Wi和Wj形成双词b=(Wi,Wj),则b的概率P(b)为
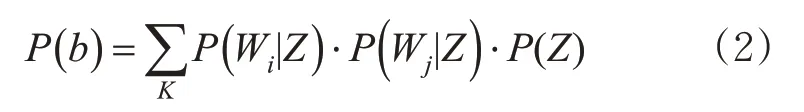
式中:P(Wi|Z)为单词Wi在主题Z下出现的概率;P(Wj|Z)为单词Wj在主题Z下出现的概率;P(Z)为主题Z在语料库中出现的概率。
不断重复这个过程,就形成了整个语料库。BTM主题建模就是这个过程的逆过程,即对于给定的语料库不断进行迭代运算,每次迭代得到主题数为K时的主题概率分布向量θ 和词在主题下的概率分布矩阵Φ,直到计算收敛。
2.2.2 BTM主题模型评估指标的确定
主题建模有3 个非常重要的输入参数:主题数K、主题的先验分布α,词的先验分布β。对于BTM算法,α通常取值为50/K,β通常取默认值0.01。最难确定的是主题数K,其值的大小常常决定了主题建模结果的优劣。
因此,需要确定评估指标对主题建模结果进行性能评价,以此来不断调整模型的参数,特别是确定最佳的主题数K。本研究综合考虑了主题模型的对数似然和主题一致性2个指标。
1)主题模型的对数似然。对数似然是检验主题建模结果拟合优度的指标,似然值越大表明模型拟合得越好。针对BTM主题建模,评估建模结果对数似然的公式为

2)主题一致性。主题一致性通过计算条件似然而不是对数似然来衡量主题中词语间的共现关系。即,它通过计算主题中高分词之间的语义相似度来评价单个主题,主题一致性的分值越高越好[12]。主题一致性的计算公式[13]为


3 船舶自沉事故原因文本挖掘实例
3.1 文本数据描述
截止到目前,在中国海事局官网发布了109 份自沉事故调查报告。存在部分报告链接地址无法访问、文件乱码或报告中事故原因描述不详等异常,剔除这些异常整理出了100份船舶自沉事故报告。这些事故调查报告的原存储格式不一,见表1。

表1 事故调查报告不同的存储格式Tab.1 Different storage formats of accident investigation
同时,这些事故调查报告由不同的海事局提供(见表2),各海事局采用的事故调查报告模板不完全相同,导致了报告的文档结构不统一,部分术语表述不一致等问题。

表2 事故调查报告不同的来源Tab.2 Different sources of accident investigation reports
文本的异构性给研究带来了很大的困难。为了保证文本挖掘的质量,使用半人工的方式进行了大量的事故报告文本清洗工作,综合运用字符串查找、截取、正则表达式、文本标注等技术和工具从清洗后的事故调查报告中抽取出“事故原因分析”部分的内容作为文本挖掘的语料。
3.2 事故原因文本频繁共现词挖掘
根据2.1设计的方法,从预处理后的100份自沉事故调查报告的事故原因文本中,提取出共现次数大于10且PMI>2.5的词对见表3。

表3 频繁共现词Tab.3 Frequent co-occurrence terms
为了更加形象、直观地展示出词语之间的语义关联,使用词共现网络图将表1 中的频繁共现词进行可视化展示,见图2。网络图中的每个节点代表1个词语,节点与节点之间的连线代表词语共现关系,连线的粗细表示共现的频繁度。

图2 词共现语义网络图Fig.2 Word co-occurrence semantic network
根据频繁共现词的挖掘结果,自沉事故是人、船、货、环境多方面共同作用的结果,包括以下4种因素。
1)人的因素。船员不适任、安全意识淡薄、配员不足、超航区航行、严重超载、应急处置不当。
2)船的因素。船舶不适航、船体破损、船舶储备浮力与稳性丧失。
3)货的因素。货物移位。
4)环境因素。大风浪、恶劣天气、甲板上浪。
3.3 事故原因文本主题建模
3.3.1 最佳主题数的确定
主题数K是主题建模重要的输入参数,根据2.2.2确定的主题模型评估指标,采用如下步骤确定主题数K。
步骤1。设定主题数的变化范围,主题数每变化1次,就按照BTM算法生成1次主题模型,计算每次所生成模型的对数似然和主题一致性。
步骤2。综合考虑主题模型的对数似然和主题一致性的变化情况,确定出最佳主题数。
在R语言环境下,设定主题数K从5变化到50,根据事故原因文本预处理后的分词结果构建主题模型。不同主题数下主题模型的对数似然及主题一致性的计算结果见表4。
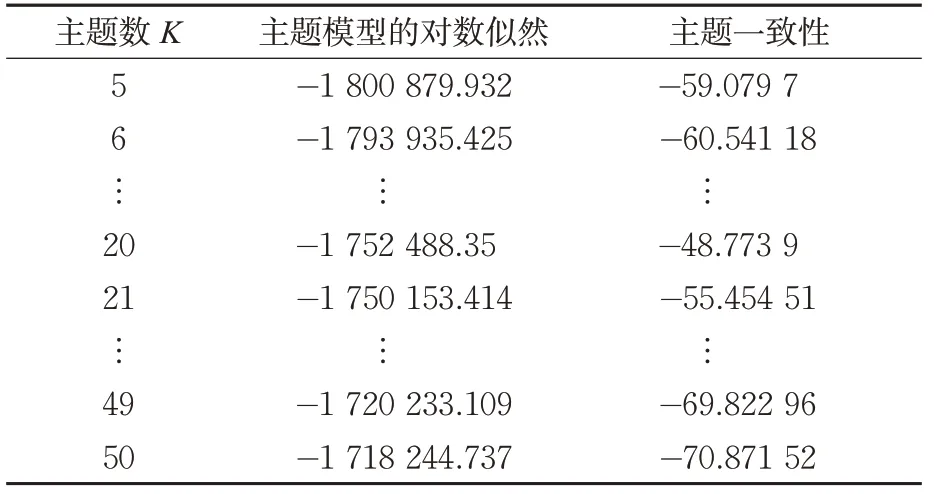
表4 主题模型评估指标值随主题数变化的情况Tab.4 Topic-number-dependent changes of topic-model evaluation measures
根据表4,绘制出上述2个评估指标的变化曲线见图3~4。

图3 主题模型对数似然的变化曲线Fig.3 Log-likelihood curve of the topic model

图4 主题一致性的变化曲线Fig.4 Topic coherence curve
从图3可见,随着主题数的增加,主题模型的对数似然呈增加的趋势,模型的拟合优度不断提升,极易产生过拟合。同时,主题数的增加也会导致主题聚类的粒度越来越细,从而减弱模型的泛化能力,不利于对自沉事故的原因进行归纳解释。因此,对于本研究使用的语料,在BTM 算法下,难以单纯使用主题模型的对数似然来确定最佳主题数K,通过主题一致性进行评估则更加合理。从图4 可以看出,当主题数为20时,主题模型的一致性值最大,因此,确定20为最佳主题数。
3.3.2 主题建模结果及可视化展示
BTM主题建模的结果主要包括:词语在主题中的概率分布Φ 和主题在语料库中的概率分布θ 。通过Φ 可以提取出能够代表每个主题特征的前n个词,通过θ 可以判断出主题发生的概率。
1)词语在主题中的概率分布Φ。本研究的语料库分词后得到2 245个不重复的有效词条,主题数为20时词语在主题中的概率分布Φ 就是1个2 245×20的矩阵,矩阵中第i行第j列的值为第i个词语在第j个主题中的概率分布,见表5。

表5 词语在主题中的概率分布Tab.5 Probability distribution of words in topics
在每个主题下按照词语概率分布从大到小排序,可以得到能够代表主题特征的前n 个词,以Z5,Z6,Z14 这3 个主题为例,这3 个主题下出现概率最高的前10个词见表6。

表6 各主题下出现概率最高的前10 个词示例Tab.6 Demo about top 10 words under each topic
使用BTM主题建模,不仅可以分析出单个词语在主题中的重要性,还可以提取出各主题下词语之间的语义联系,见图5。
根据各主题下词语的分布以及词语间的语义关联,对所挖掘出的主题进行梳理、解释,见表7。
2)主题在文档集合中的概率分布θ 。通过对主题建模结果中θ 向量的提取,得到各主题在文档集合中的概率分布,见表8。
根据主题在文档集合中的分布可以初步量化出每种事故原因的发生概率,见图6。图6 是对表7 和表8整合结果的可视化展示。
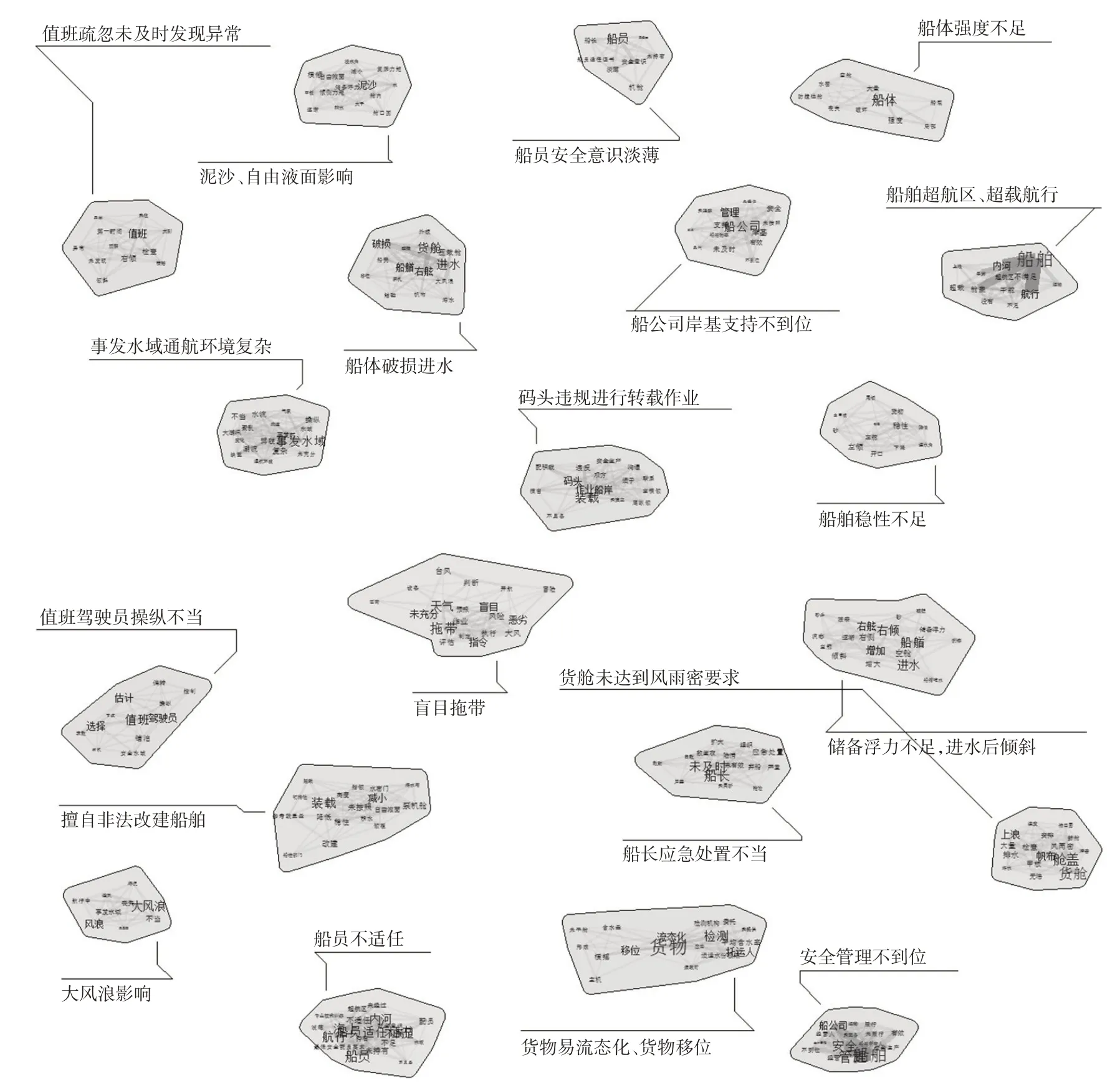
图5 主题建模结果的可视化展示Fig.5 Visualization of topic-modeling results

图6 主题概率分布条形图Fig.6 Bar for the probability distribution of topics

表8 主题的概率分布Tab.8 Probability distribution of topics
根据主题建模结果,安全管理不到位、大风浪影响在船舶自沉事故原因中出现的概率最高。综合来看,船舶自沉事故的原因主要包括以下4点。
1)人为因素。人为因素既包括船公司的安全管理和岸基支持,又包括从业人员的业务素质,如码头装载作业是否规范、船员是否适任、值班人员是否认真履职、船长应急处置是否及时、驾驶员操纵行为是否正确等。
2)客观因素。主要包括大风浪以及事发水域复杂的通航环境。
3)船舶技术指标。主要指船舶稳性、储备浮力、强度、风雨密、水密等是否满足规范要求。
4)货物特性。货物自身的属性(如易流态化)也是导致船舶自沉的1个非常重要的原因。
使用主题建模对船舶自沉事故原因提取的结果与相关文献的研究结果非常接近。如李奕良[15]指出船体结构缺陷增大了船舶自沉事故的概率;陈兴园[16]认为水上交通事故的管理致因包括:船上管理致因、船公司管理致因等;韩俊松等[17]认为:货物的流态化、装载及平舱不当直接影响船舶安全;乔赛雯[18]强调:船舶在大风浪中航行,易对船体造成伤害,从而导致船舶事故。
3.3.3 主题模型对新数据集预测能力的测试
为了进一步验证所构建的主题模型对船舶自沉事故原因的解释能力,随机生成新数据集,测试主题模型能否将每一个词语正确归属到代表某一类事故原因的主题下。新数据集是由编号和词语组成的数据框,见表9。

表9 用于测试的新数据集Tab.9 New dataset for testing
使用BTM算法中提供的predict函数,根据所构建的主题模型,计算每一个词归属于各主题的可能概率。预测结果见表10(保留小数点后3位)。

表10 预测结果Tab.10 Predicting outcomes
由于“精准营销”是与船舶交通事故无关的词语,所以预测函数对该词的计算结果为空。其它各词在不同主题下均有不同的预测得分,在哪个主题下得分值最高,该词就最大可能归属于这个主题。
根据计算结果,“满载排水量”最大可能归属于主题5(船舶超航区、超载航行),可能性为95.3%;“潮汐”最大可能归属于主题6(事发水域通航环境复杂),可能性为78%;“岗前培训”最大可能归属于主题7(船公司岸基支持不到位),可能性为99.6%;“抢滩”最大可能归属于主题20(船长应急处置不当),可能性为64%。
经过对500 组新数据集的预测结果的统计如下。
1)所构建的主题模型能够将语料库中85.6%左右的词,以60%以上的可能性归属到某一主题下。
2)语料库中另14.4%左右的词,主题边界不明显,比如“船舶”这个词在大部分主题中都有分布,单独出现时难以以较大的可能性明确其主题归属。
3)所构建的主题模型可以100%地识别出领域无关的词(如,表9中的“精准营销”)并自动忽略。
4 结束语
随着事故调查报告数量的激增,单纯依靠人工归纳或传统的统计方法已经无法快速有效地对其内容进行分析。文本语义挖掘在船舶事故调查报告交通安全知识自动提取方面的优势将越来越明显。本研究提出了从词语和主题2个层面对非结构化的船舶事故调查报告进行语义挖掘的方法,并以100 份自沉事故调查报告原因文本为语料进行了具体的挖掘研究。
1)在词语层面,基于PMI算法从船舶自沉事故报告的原因文本中提取频繁共现词,通过事故原因特征词的频繁共现反映出事故致因要素间的关联关系。
2)在主题层面,使用BTM 算法对船舶自沉事故原因文本进行主题建模,对隶属于同一事故原因的词语进行聚类,并根据主题在文档中的分布情况初步量化出各种事故原因的发生概率。最后对所构建模型的预测能力进行了测试。
船舶事故调查报告是水上交通安全领域重要的档案资料,但是其高度的异构性给文本挖掘带来了很多困难。为了更好地对海量事故调查报告进行挖掘、利用,建议海事部门进一步规范事故调查报告的模板、术语表达和存储格式等,完善船舶事故调查报告的元数据描述模型。
本研究只抽取了船舶自沉事故调查报告中的事故原因分析文本进行研究。下一步的研究拟从以下2个方面展开。
1)在进一步提高分词质量、增大文本数据规模的基础上,对各种类型(碰撞、搁浅等)的船舶事故原因文本进行综合挖掘,构建事故原因知识图谱。
2)抽取事故调查报告中的其他部分内容进行不同角度的挖掘,如,抽取出“事故经过”文本进行事件序列模式挖掘,从而揭示出导致船舶事故的行为模式。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
基层中医药(2022年4期)2022-07-22
现代畜牧科技(2021年9期)2021-10-13
小天使·一年级语数英综合(2020年4期)2020-12-16
天津外国语大学学报(2020年1期)2020-03-25
知识经济·中国直销(2017年11期)2017-11-28
中国民族医药杂志(2016年3期)2016-05-09
湖南工业职业技术学院学报(2016年6期)2016-04-17
语言与翻译(2015年4期)2015-07-18
传奇故事(破茧成蝶)(2015年7期)2015-02-28
