
基于注意力机制的全卷积神经网络模型
2021-05-07 02:24刘孟轩张蕊曾志远金玮武益超
现代信息科技 2021年23期
关键词:注意力机制
刘孟轩 张蕊 曾志远 金玮 武益超




摘 要:全卷积神经网络FCN-8S在进行多尺度特征融合时,由于未能考虑不同尺度特征各自的特点进行充分融合,导致分割结果精度较低,针对这一问题,文章提出了一种基于注意力机制的多尺度特征融合的全卷积神经网络模型。该模型基于注意力机制对FCN-8S中的不同尺度特征进行加权特征融合,以相互补充不同尺度特征包含的不同信息,进而提升网络的分割效果。文章模型在公共数据集PASCAL VOC2012和Cityscapes上进行验证,MIoU相对于FCN-8S分别提升了2.2%和0.8%。
关键词:语义分割;全卷积神经网络;注意力机制;特征融合
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2021)23-0092-04
Full Convolutional Neural Network Model Based on Attention Mechanism
LIU Mengxuan, ZHANG Rui, ZENG Zhiyuan, JIN Wei, WU Yichao
(North China University of Water Resources and Electric Power, Zhengzhou, 450046, China)
Abstract: Aiming at the problem of low accuracy of segmentation results due to the failure to consider the respective characteristics of different scale features when the fully convolutional neural network FCN-8S performs multi-scale feature fusion, this paper proposes a fully convolutional neural network model with multi-scale feature fusion based on attention mechanism. This model is based on the attention mechanism to perform weighted feature fusion of different scale features in FCN-8S to complement each other with different information contained in different scale features, thereby improving the segmentation effect of the network. The model proposed in this paper is verified on the public data sets PASCAL VOC2012 and Cityscapes. Compared with FCN-8S, MIoU increases by 2.2% and 0.8%, respectively.
Keywords: semantic segmentation; full convolutional neural network; attention mechanism; feature fusion
0 引 言
图像语义分割是计算机视觉领域的三大核心任务之一,其目标是为图像中的每一个像素分配一个预先定义好的语义类别标签,并对不同的目标进行分割[1]。近年来,随着深度学习[2]在计算机视觉领域的不断发展,语义分割在越来越多的领域中得到了广泛应用,比如自动驾驶,医疗图像分割和物体缺陷检测等,成为当下研究的热点。
随着计算机算力的不断提升,深度学习方法得到了人们的广泛关注,并逐步被应用于图像处理领域。2015年,Long等人[3]将图像分类网络VGG-16[4]中的全连接层替换为卷积层,形成了全卷积神经网络(Fully Convolutional Network, FCN),首次实现了端到端的图像语义分割。但由于卷积神经网络(Convolutional Neural Network, CNN)[5]中的池化操作,输入图像在下采样过程中分辨率大幅下降,丢失了大量空间位置信息,导致FCN最终的分割结果较为粗糙。为了解决这个问题,FCN-8s通过融合三个尺度的特征获得了比只使用一个特征的FCN-32s更好的结果,但分割结果仍然不够精细。同时FCN-8s在进行特征融合时赋予了三个尺度特征相同的权重,未考虑到不同尺度特征的差异。
针对以上问题,本文通过注意力机制有选择的强调有用特征而抑制无用的特征,在空间和通道两个维度上计算注意力分布,对FCN-8S中不同尺度特征赋予不同的权重来充分融合多尺度特征,以提升最终的分割效果。实验证明,本文提出的基于注意力机制的FCN能够更有效地进行特征融合,提升最终的分割效果,在公共数据集PASCAL VOC2012[6]和Cityscapes[7]上取得了较好的结果。
1 相关研究
随着计算机硬件性能的提升,深度学习技术得到迅速发展,深度卷积神经网络被广泛应用于图像处理领域。2015年,Long等人[3]提出的FCN使语义分割进入了一个全新的阶段,大量研究人员尝试使用全卷积神经网络来解决语义分割模型。比如常用于医疗图像分割的UNet[8],为了减少FCN下采样过程中损失的信息,其在上采样和与之对应的下采样之间构建跳跃连接,进行特征融合,形成了一个对称的U型结构。HRNet[9]通过并行连接高分辨率到低分辨率卷积来保持高分辨率表示,并通过重复跨并行卷积执行多尺度融合来增强高分辨率表示,实验证明了其在像素级分类任务上的有效性。上述方法虽然通过特征融合也获得了很好的效果,但简单的等权值融合方式忽略了不同特征的差异性,未能充分利用各层特征包含的豐富信息。而计算机视觉中的注意力机制可以看作是一个基于输入图像特征的动态权重调整过程[10],常见的有通道注意力机制SENet[11],空间注意力机制GENet[12]和联合空间和通道注意力的CBAM[13]、BAM[14]等。故本文基于注意力机制对FCN-8S中三个尺度特征进行加权融合,改进FCN-8S的性能,提升分割精度。
2 本文方法
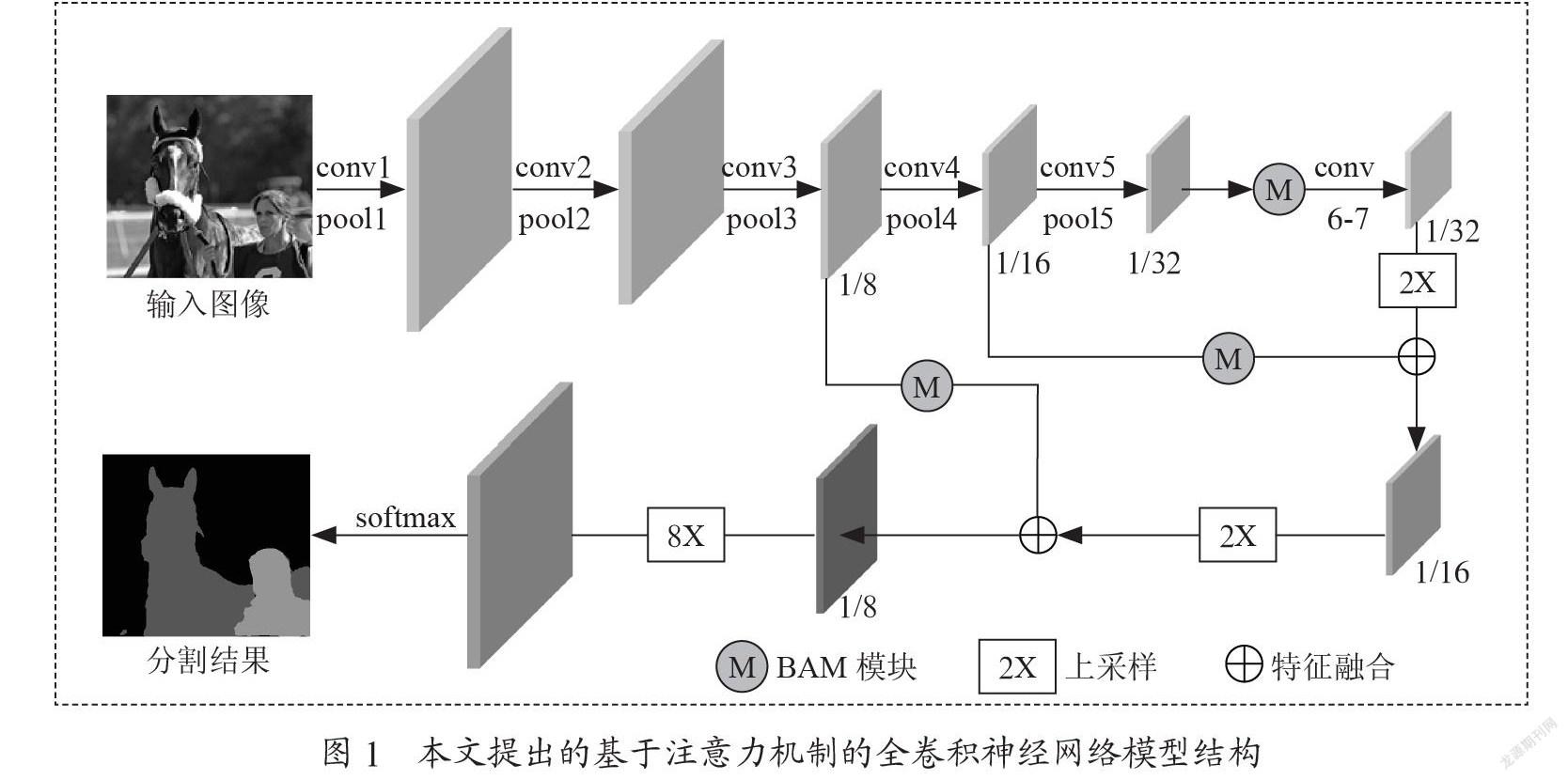
本文提出的语义分割模型框架如图1所示。模型以全卷积神经网络FCN-8S作为基础网络,在其特征融合时加入BAM注意力模块对不同尺度特征进行加权,以强调利于分割的有用信息,抑制无用的冗余信息,提升网络的分割性能。具体操作为:首先对VGG网络提取到的尺度为原图1/8、1/16和1/32大小的特征分别使用BAM注意力模块计算注意力分布,得到带有注意力权重的不同尺度特征;然后将其按照FCN-8S中的融合方式进行特征融合,得到尺度为原图1/8大小的特征;再对其进行8倍上采样,最后利用softmax分类函数得到最终分割结果。
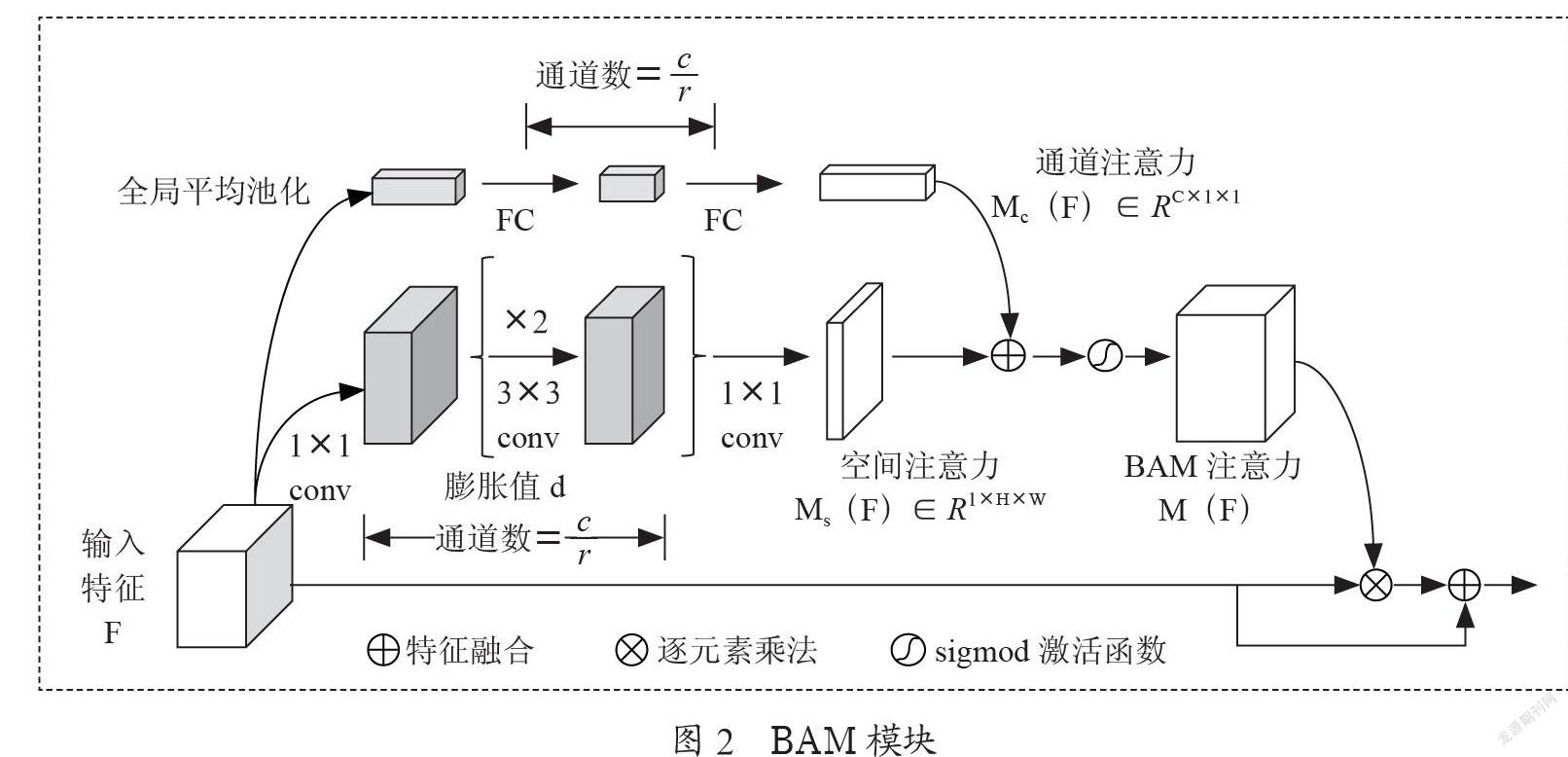
BAM模块[14]的结构如图2所示,输入的特征F分别通过两个独立的分支计算得到通道注意力图Mc(F)和空间注意力图Ms(F),然后对两个注意力图进行特征融合并经过sigmod激活函数得到BAM注意力图M(F),最后将输入特征F与M(F)逐元素相乘后再特征融合得到具有注意力权重的特征。其中有两个超参数膨胀值d和缩减比r。膨胀值决定了接受域的大小,这有助于空间分支上的上下文信息聚集;缩减比控制两个注意分支的容量和开销。这里d和r分别设置为4和16。
3 实验结果与分析
3.1 数据集及评价指标
本文在公开的PASCAL VOC2012[6]和Cityscapes[7]数据集上验证所提模型的性能。PASCAL VOC2012是用于视觉对象类挑战比赛的数据集,包括人、动物、交通工具和生活用品等20类常见物体对象和1个背景类。本文使用SBD数据集[15]对PASCAL VOC2012数据集对进行扩充,得到训练集图像10 582张,验证集1 449张和测试集1 456张。Cityscapes数据集记录了50个不同城市的街道场景,拥有5 000张高质量像素级注释的图像以及20 000张粗糙注释的图像。5 000张精细标注图像中2 975张图像用于训练,500张图像用于验证,1 525张图像用于测试,一般使用19个类别标注。每张图像大小均为2 048×1 024,图像中道路场景复杂,目标类别尺度不一。
本文使用语义分割领域常用的评价指标像素精度(Pixel Accuracy, PA)和平均交并比(Mean Intersection over Union, MIoU)来评估模型的性能和预测结果的准确性。假设总计有k+1分类(标记为L0到Lk,其中包含一个背景类别),Pij表示类别为i的像素被预测为类别为j的数目。
像素精度PA表示预测正确的像素和总的像素的比率[3],用以下公式计算:
平均交并比MIoU通过计算真实值集合和预测值集合的交集和并集之比来计算图像真值与预测结果的重合程度[3],是最具代表性的语义分割度量指标。它先基于每个类别计算,然后再求均值,公式为:
3.2 实验环境
本文模型在Ubuntu 18.04系统上基于开源框架PyTorch实现,并使用NVIDIA GeForce GTX 1 080 Ti(11 GB)图形处理器进行加速。在训练过程对图片随机进行0.5倍、2倍缩放,并进行随机裁剪,以预防训练过程中出现过拟合。对于VOC2012数据集,图片大小裁剪为321×321,设置批处理大小为8,迭代50个epoch。由于GPU内存的限制,对于Cityscapes数据集,首先对训练集分辨率大小为2 048×1 024的图片下采样为1 024×512大小,再将图片大小裁剪为473×473,迭代100个epoch。优化算法使用随机梯度下降SGD,动量设置为0.9,学习率使用poly衰减策略,初始学习率设置为0.01,权重衰减系数设置为0.000 1。
3.3 实验结果分析
3.3.1 对比试验
为了验证本文方法的效果,分别在PASCAL VOC2012和Cityscapes验证集上与FCN-8s和Deeplabv2进行实验对比,结果如表1和表2所示,MIoU分别达到了68.1%和55.1%,相对于FCN-8S分别提升了2.2%和0.8%。
结合表1和表2可知,在同等的实验环境下,本文提出的方法相对于FCN-8S取得了更好的结果。在PASCAL VOC2012数据集上像素精度PA和平均交并比MIoU分别为91.4%和68.1%,相对于FCN-8S分别提升了0.7%和2.2%;在Cityscapes数据集上PA和MIoU为91.3%和55.1%,对比FCN-8S像素精度PA没有提升,但MIoU提升了0.8%。说明本文提出的基于注意力机制的多尺度特征融合策略是有效的,能够充分考虑不同尺度特征各自的特点,关注重点信息,忽略无效信息,有效改善了FCN-8S的分割效果。
3.3.2 语义分割可视化
为了更加直观的看出本文所提方法的效果,在PASCAL VOC2012验证集上与FCN-8S的预测结果进行可视化对比分析,结果如图3所示。第一行中FCN-8S将火车附近区域部分像素误分为了人,而本文方法没有误分,分割结果相对准确;第二行FCN-8S对于马腿这种小目标并不能完整分割出来,还将部分背景像素误分为其他类,而本文方法相对于FCN-8S分割结果较为精细,并且误分的像素较少,说明其具有一定的细节捕捉能力,能够关注重点目标区域;第三行奶牛类FCN-8S误分类现象严重,而本文方法分割较为完整,误分现象相对于FCN-8S有所改善。综上,可以说明本文提出的基于注意力机制的融合方法能够充分融合各尺度特征,相对于FCN-8S的等权值融合方法具有更好的效果,能够有效改善FCN-8S的分割效果。
4 结 论
本文模型针对全卷积神经网络FCN-8S在进行特征融合时未考虑到不同尺度特征各自的特点,通过简单的等权值拼接融合得到的分割结果较为粗糙的问题,提出了一种基于注意力机制的多尺度特征融合的全卷积神经网络模型。该模型以FCN-8S为基础网络,引入注意力机制从空间和通道两个维度计算注意力分布,强调利于分割的有用信息,抑制冗余信息,对不同尺度特征进行加权融合,以充分利用各尺度特征信息,改善FCN-8S的分割效果。實验结果表明,本文提出的模型相对于FCN-8S有更好的分割结果,说明本文的特征融合策略是有效的。但是,本文模型仍有一定局限性,FCN-8S是相对较老的模型,本身分割效果有限,如何将本文特征融合方法与其他更优秀的模型相结合进一步提升网络分割效果是下一步重要的工作。此外如何进一步提升边界的分割精度也是一个重要的内容。
参考文献:
[1] 田萱,王亮,丁琪.基于深度学习的图像语义分割方法综述 [J].软件学报,2019,30(2):440-468.
[2] HINTON G E,SALAKHUTDINOV R R. Reducing the Dimensionality of Data with NeuralNnetworks [J].Science,2006,313(5786):504-507.
[3] LONG J,SHELHAMER E,DARRELL T. Fully Convolutional Networks for Semantic Segmentation [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:3431-3440.
[4] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for large-scale image Recognition [J/OL].arXiv:1409.1556 [cs.CV].[2021-11-13].https://arxiv.org/abs/1409.1556.
[5] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. Imagenet Classification with Deep Convolutional Neural Networks [EB/OL].[2021-11-13].https://web.cs.ucdavis.edu/~yjlee/teaching/ecs289g-winter2018/alexnet.pdf.
[6] EVERINGHAM M,ESLAMI S M A,VAN GOOL L,et al. The pascal visual Object Classes challenge: A Retrospective [J].International Journal of Computer Vision,2015,111:98-136.
[7] CORDTS M,OMRAN M,RAMOS S,et al. The Cityscapes Dataset for Semantic Urban Scene Understanding [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:3213-3223.
[8] RONNEBERGER O,FISCHER P,BROX T. U-net:Convolutional Networks for Biomedical image Segmentation [J/OL]. arXiv:1505.04597 [cs.CV].[2021-11-13].https://arxiv.org/abs/1505.04597.
[9] SUN K,XIAO B,LIU D,et al. Deep High-Resolution Representation Learning for Human Pose Estimation [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:5686-5696.
[10] GUO M H,XU T X,LIU J J,et al. Attention Mechanisms in Computer Vision:A Survey [J/OL].arXiv:2111.07624 [cs.CV].[2021-11-13].https://arxiv.org/abs/2111.07624.
[11] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-Excitation Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2020,42(8):2011-2023.
[12] HU J,SHEN L,ALBANIE S,et al. Gather-excite:Exploiting Feature Context in Convolutional Neural Networks [J/OL].arXiv:1810.12348 [cs.CV].[2021-11-13].https://arxiv.org/abs/1810.12348.
[13] WOO S,PARK J,LEE J Y,et al. CBAM: Convolutional Block Attention Module [C]//Computer Vision–ECCV 2018.Munich:view affiliations,2018:3-19.
[14] PARK J,WOO S,LEE J Y,et al. Bam:Bottleneck Attention module [J/OL].arXiv:1807.06514 [cs.CV].[2021-11-13].https://arxiv.org/abs/1807.06514.
[15] HARIHARAN B,ARBELÁEZ P,BOURDEV L,et al. Semantic contours from inverse detectors [C]//2011 International Conference on Computer Vision.Barcelona:IEEE,2011:991-998.
作者簡介:刘孟轩(1997—),男,汉族,河南洛阳人,硕士研究生在读,研究方向:图像语义分割;张蕊(1980—),女,汉族,河南濮阳人,硕士生导师,博士,研究方向: 图像处理、三维场景语义分割、激光雷达点云数据处理;曾志远(1997—),男,汉族,河南驻马店人,硕士研究生在读,研究方向:图像语义分割;金玮(1996—),男,汉族,河南周口人,硕士研究生在读,研究方向:图像处理;武益超(1999—),男,汉族,河南安阳人,硕士研究生在读,研究方向:点云语义分割。
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
