
基于改进生成对抗网络的单帧图像超分辨率重建
2021-05-11 02:39陈宗航胡海龙姚剑敏林志贤
液晶与显示 2021年5期
陈宗航,胡海龙,姚剑敏,2*,严 群,2,林志贤
(1.福州大学 物理与信息工程学院,福建 福州350108;2.晋江市博感电子科技有限公司,福建 晋江362200)
1 引 言
生活中许多领域都对图像的分辨率有着较高的要求,如安防、医疗、航天、刑侦等,而图像超分辨率(Super Resolution,SR)重建技术也渐渐成为近年来研究的热门话题。图像超分辨率技术于1984年首次被提出[1],其指的是通过某种方法将低分辨率的图像重建为高分辨率的图像,它是图像处理和计算机视觉领域的重要研究方向。图像超分辨率方法主要有基于差值的方法、基于重建的方法和基于学习的方法[2]。基于差值的方法是利用某个像素点周围的像素值以及其中相对的位置关系,依据数学方法来进行评估,主要有最近邻插值法[3]和双三次插值法[4]。基于重建的方法主要是利用自然预想的先验知识(如平滑性),常见的方法有凸集投影[5]以及最大后验概率法[6]。基于学习的方法主要有传统的机器学习方法和近年来被广泛应用的深度学习的方法。基于机器学习的方法一般是结合矩阵变换的相关方法来学习其中复杂的映射关系,需要人为地提取特征进行学习。与传统方法相比,基于深度学习的超分辨率重建不需要手动进行特征提取,而是经过神经网络自动地提取复杂丰富的特征,然后学习两幅图片之间的映射关系,且通过深度学习方法还原的高分辨率图像具有更丰富的纹理信息和更清晰的视觉感知。
Dong等人提出了SRCNN(Super-Resolution using Convolutional Neural Network)[7],其是深度学习应用在超分辨率领域的开山之作,对图像超分辨率的重建效果和速度取得了重大突破。而后VDSR[8]、LapSRN[9-10]等又在SRCNN的基础上做出了许多改进,极大地推动了图像超分辨率技术的发展。之后Ledig等人[11]将生成对抗网络[12](Generative Adversarial Networks,GAN)应用在图像超分辨率重建中,提出了SRGAN算法,使得图像在重建后拥有更多的高频细节,感受野更好,但是其中GAN网络的训练不稳定,训练时间也较长。本文设计了不同于SRGAN的生成对抗网络,且在损失函数中使用了与MSE[13]不同的SmcothL1损失并引入了Earth-Mover距离[14]的思想来稳定网络的训练,实验证明图像评价指标PSNR和SSIM都有提升。
2 网络模型设计
2.1 生成对抗网络
生成对抗网络是由Goodfellow提出的一种基于生成模型的网络。其灵感来自于零和博弈论中的纳什均衡[15]。GAN网络的训练目标就是生成网络G强大到可以混淆判别网络D的同时,判别网络D又能很好地分辨出生成网络G生成的图像和原始图像,GAN的目标函数可以表示为:
minmaxV(D,G)=Ex~Pdata(x)[lgD(x)]+
EZ~P(Z)[lg(1-D(G(Z))],
(1)
其中:Pdata(x)表示真实样本的分布,而P(z)表示生成网络的分布。判别函数D希望真实数据的D(x)概率更大,D(G(z))更小,对于D来说希望这个目标函数的值更大,生成网络函数G则希望G(z)更接近x,使得D(G(z))更大,这时目标函数的值就会更小。这也体现了GAN网络中的G网络和D网络一种对抗的特点。SRGAN的训练流程如图1所示。
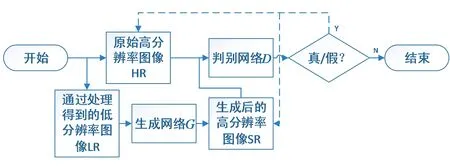
图1 SRGAN训练流程Fig.1 Training process of SRGAN
首先,对原始的高分辨率图像HR进行某种方法的预处理以获得低分辨率图像LR;后将低分辨率图像送入生成网络G中,得到生成高分辨率图像SR;再将SR和原始高分辨率图像HR组成一个图像对送入判别网络D中。判别网络的输出实际上是一个判断图片是HR还是SR的二分类问题。在获得判别结果的误差后,调整模型的参数,以使模型能够在学习过程中自动更新参数信息。
2.2 基于DenseNet的生成网络
SRGAN中使用的生成网络为ResNet[16],这是一种残差网络,而DenseNet[17]提出了一个密集型的连接模型,具体来说就是每一层除了会接受上一层的输出作为输入还会接受之前所有层的输出作为输入。其简易原理图如图2所示。
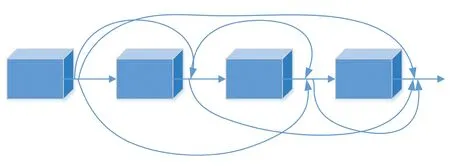
图2 DenseNet简易原理图Fig.2 Simple schematic diagram of DenseNet
DenseNet每个层都会与之前所有层channel维度上相连接,并作为下一层的输入。当一个DenseNet网络有L层时,DenseNet总共会包含L(L+1)/2个连接,且DenseNet是直接合并来自不同层的特征图,这可以更好地实现特征复用,提升网络的训练效率。
2.2.1 子像素卷积
子像素卷积[18](Sub-pixel convolution)是一种较为特别的图像和特征图的放大方法,其又可以称作像素清洗(Pixel shuffle)。以往的DenseNet使用较多的上采样方法为逆卷积,但是逆卷积往往会掺杂过多的人工因素,而子像素卷积的过程是需要学习的,相比于逆卷积,这种通过样本学习的方式得到放大图像或者特征图所需参数的方法其放大性能更为准确。子像素卷积模块如图3所示。

图3 子像素卷积模块Fig.3 Module of sub-pixel convolution
2.2.2 生成网络模型
本文采用了8×8的密集连接模块,输入图像需要经过一个4倍的下采样过程。EDSR[19]中提出BN层(批规范化层)[20]用于解决较高层的计算机视觉问题,而BN层并不适合应用在图像超分辨率这类低层的计算机视觉问题中。如果将BN层加入到生成网络中,其会消耗与它之前的卷积层相同的计算资源,且并不会对重建出的图像质量有所帮助。因此本文的DenseNet网络与以往不同的是去除了冗余的BN层,之后在相同的硬件条件下,就可以在模型中加入更多的网络层或者增加各层提取的特征来提高模型性能。生成网络的整体的网络结构如图4所示。其中k代表卷积核个数,n代表通道数,s代表步长。将高分辨率图像HR通过一定方法生成低分辨率图像LR之后,LR和HR组成一个图像对送入网络训练。首先经过一个卷积模块,用于提取低水平特征,该卷积模块由一个卷积层和一个Relu[21]激活函数构成;之后进入密连接模块,其中有8个密连接块(DenseBlock),每个密连接块中有8个密连接层,每个密连接层也采用了一个卷积层加一个Relu激活函数的结构。其中各个块和层均采用了上文提到的DenseNet结构,即各个块和层除了接受上一个块和层的输出还会接受之前每一个块和层的输出。通过两个子像素卷积块进行放大生成高分辨率图像。
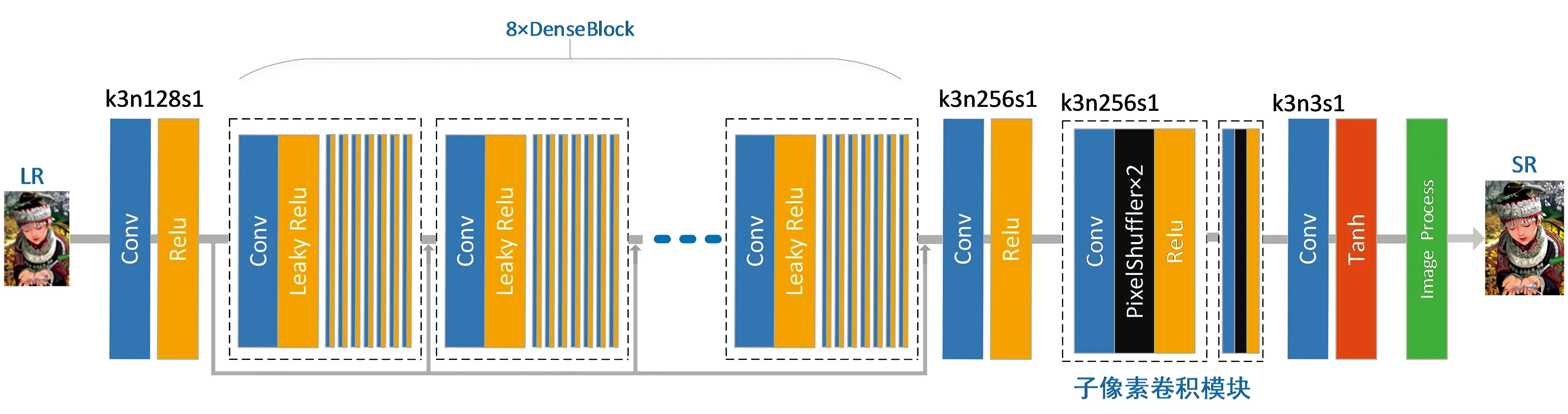
图4 生成网络结构图Fig.4 Structure diagram of generator
2.2.3 判别网络模型
在判别网络中,保留了BN层以用于稳定训练。由于本文引入了Earth-Mover距离的思想,因此判别网络的任务从判断生成图片和原始图片的二分类任务变为了拟合任务,所以在最后一层不使用sigmoid层,以保证损失的收敛。判别网络结构如图5所示。在判别网络中,采用8个卷积核大小为3×3的卷积模块进行特征提取。s1代表步长为1,n代表输出通道数。随着卷积层数的不断加深,特征个数在第3,5,7层时加倍,使用了LeakyRelu激活函数,在第2至第8个层加入了BN稳定网络的训练,最后通过一个全连接层输出一个一维的张量。

图5 判别网络结构图Fig.5 Structure diagram of discriminator
3 损失函数
在SRGAN中,其损失函数为:
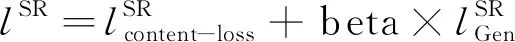
(2)
式(2)中第一项代表了内容损失,可以表示为:

(3)
式(3)的第一项是原始高清图像HR和生成网络生成的图像的像素之间的损失,公式如下

(4)
而由于单纯地使用MSE易使得图像过于平滑,缺乏高频细节,所以SRGAN提出了基于VGG19网络提取特征的损失,公式如下
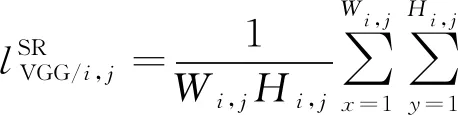
(5)
式(5)表示用VGG19对原始高清图HR和重建出的图像SR分别进行计算,得到两幅图的特征图,之后再对其计算MSE值,式中H和W分别代表图片的宽和长,φi,j表示通过截取VGG19网络的第i层最大池化和第j层卷积层后的特征图。
式(2)的第二项指的是低分辨率图像通过生成网络生成高分辨率SR图像后再经过判别网络得出的值与真实值的交叉熵。
由于MSE损失函数容易放大最大误差和最小误差之间的差距,且对异常点较为敏感。本文采用SmoothL1损失来指导训练的过程。得到的感知损失为:

(6)
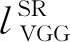
由于GAN网络训练不稳定,不易通过观察损失来了解训练过程的好坏,且Matin[22]等人通过研究GAN的原理解释了GAN训练过程不稳定的原因。主要是由于等价优化的距离衡量JS散度不合理导致,因此本文引入Earth-Mover(EM)距离进行优化。本文模型的EM距离定义为:
L=Ex~Pg[DθD(IHR)]-Ex~Pr[DθD(ILR)],
(7)
生成网络的目标就转变为尽可能最小化EM距离。
4 实验与分析
实验硬件资源为i5-6500处理器搭配一块GTX 1060 6G 加速计算。软件环境有cuda10.1配合显卡加速,pytorch1.4.0用于网络搭建和损失函数的定义,用python3.6.10进行编程。实验的训练集来自公开数据集COCO2014中随机选取的5000张图片,测试集采用SET5、SET14、BSD100基准测试集,用与生成效果图和对比评价指标。为验证本文模型的图像超分辨率效果,实验选取了经典的传统方法双三次插值(Bicubic)以及3种深度学习的方法SRCNN、VDSR、SRGAN进行实验对比。
4.1 评价指标
本文实验采用峰值信噪比(PSNR)与结构相似性(SSIM)[23]两项客观评价指标进行对比。PSNR的定义为:
(8)
本文计算PSNR的方法是先将图片转化为YCbCr格式,然后只对Y分量进行PSNR计算。
SSIM针对SR和HR两张图片进行计算,其公式为:
(9)
4.2 结果分析
本文首先对模型的生成网络进行预先训练,之后才开始训练整个网络。训练过程中通过tensorboard观察网络训练稳定性和训练的程度。图6所示(横坐标为迭代轮数,纵坐标为损失值)为原始GAN训练过程的判别损失图,其损失值此起彼伏是因为判别网络和生成网络正在进行对抗,所以很难通过观察损失来判定训练过程的好坏,GAN的训练相当不稳定。
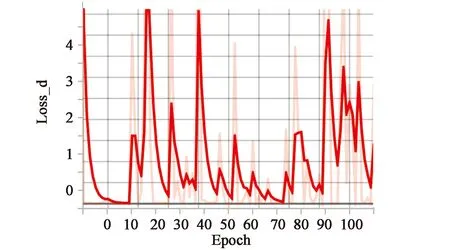
图6 原始GAN判别损失Fig.6 D_loss of original GAN
图7所示为本文模型训练过程的损失变化。可以看出随着训练的进程,损失逐渐趋于某一值开始收敛,这也符合了Earth-Mover距离的思想。
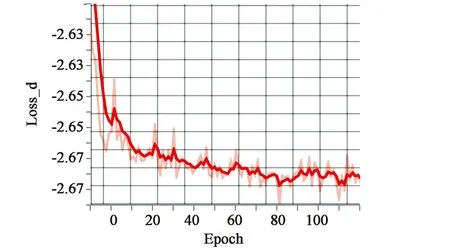
图7 本文模型判别损失Fig.7 Ours d_loss
本次实验通过PIL库对低分辨率图像进行双三次差值重建,并且重建了SRCNN、VDSR、SRGAN模型进行了实验对比,实验结果如图8所示,分别展示了每个模型在测试集中的重建效果。其中图8(a)是通过双三次差值重建的高分辨率图像,图8(b)是通过SRCNN模型重建的高分辨率图像,图8(c)是通过VDSR模型重建的高分辨率图像,图8(d)是通过SRGAN模型重建的高分辨率图像,图8(e)是通过本文模型重建的高分辨率图像;图8(f)是原始高分辨率图像。

图8 重建图像Fig.8 Reconstructed images
可以看出通过双三次差值重建出的图像特征明显模糊,而SRGAN和本文的模型重建的图像不仅较为清晰且拥有许多的纹理细节。为了进一步比较各模型重建图像的效果,图9展示了放大图像某一部分后的图像对比。
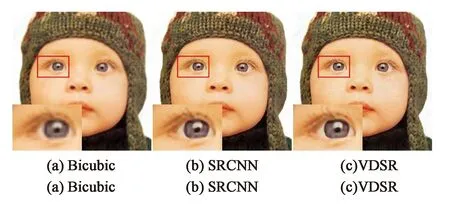
图9 细节对比图Fig.9 Detail comparison
从图(9)中可以看出本文的模型重建出的图像细节更加清晰,色彩亮度更加接近原始图像。
接着我们使用PSNR和SSIM两个图像评价指标对各算法的重建效果进行评估,从而更准确严谨地比较各个算法间的优劣。PSNR越高代表重建出的图像质量越好,失真越少。SSIM值越接近1代表生成的图像结构越接近于原始图像,原图的SSIM值为1。本文采用的放大倍数为4倍,使用skimage工具包进行PSNR和SSIM的计算。表1和表2是各算法在各测试集上的平均PSNR和SSIM对比。从图像指标中可以看出传统的双三次差值方法的图像重建质量落后于深度学习方法,并且通过计算3个测试集指标的平均值,本文方法的PSNR高出SRGAN约2.02 dB,SSIM约高出0.042(5.6%)。
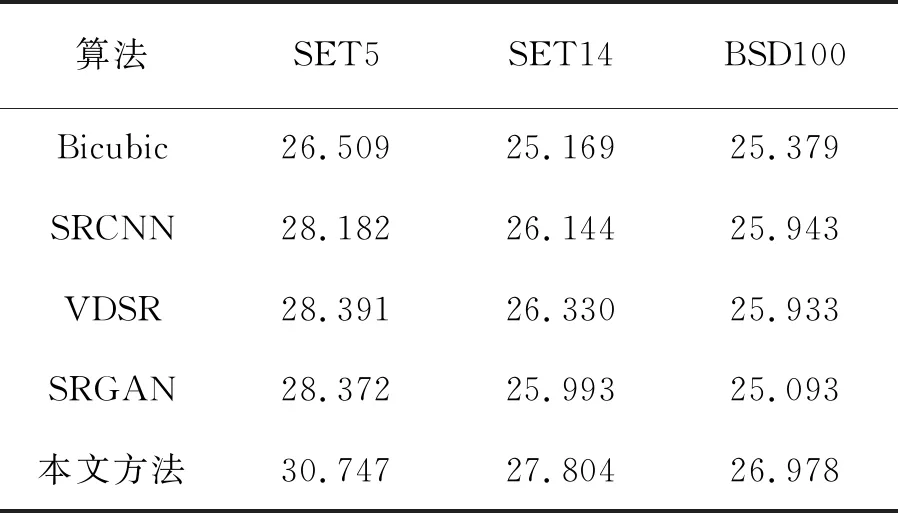
表1 在测试集SET5、SET14和BSD100上的PSNR对比Tab.1 Comparison of PSNR on test sets SET5,SET14 and BSD100

表2 在测试集SET5、SET14和BSD100上的SSIM对比Tab.2 Comparison of SSIM on test sets SET5,SET14 and BSD100

续 表
通过损失函数、重建图像以及评价指标的对比,本文方法的网络训练的稳定性要优于SRGAN,且重建出的图像质量要优于其他算法。
5 结 论
本文提出了一种基于DenseNet的生成对抗网络来进行图像超分辨率重建。与以往不同的是,本文将子像素卷积模块加入DenseNet的网络中,并且移除了冗余的BN层,提高了特征复用率的同时加快了模型训练的效率。本文引入了Earth-Mover距离,重新设计了损失函数,使得判别网络的任务由二分类任务转变为拟合任务。在损失函数中改用了SmoothL1来计算VGG提取的特征图,以防止MSE损失放大最大误差和最小误差之间的差距。最后通过实验验证,本文提出的方法在SET5、SET14以及BSD100三个基准测试集上的图像质量明显好于其他方法,且对比同样基于生成对抗网络的SRGAN,平均PSNR高出约2.02 dB,SSIM高出约0.042(5.6%)。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
雷达学报(2020年3期)2020-07-13
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
太空探索(2015年8期)2015-07-18
浙江大学学报(工学版)(2015年1期)2015-03-01
