
多尺度时序依赖的校园公共区域人流量预测∗
2021-05-23 13:17谢贵才蒋为鹏徐一凡
软件学报 2021年3期
谢贵才,段 磊,蒋为鹏,肖 珊,徐一凡
(四川大学 计算机学院,四川 成都 610065)
随着2018 年国家发布《智慧校园总体框架》标准,集校园工作、学习和生活于一体的高校智慧校园正在逐渐成型.其中,基于数据分析、人工智能等信息技术支撑的校园公共区域人流量预测作为其重要组成部分,具有如下意义.
(1)校园公共区域人流量预测,对于维护学校安全,维持各区域的正常运营有重大意义,尤其是在面对疫情等突发事件时,预估和掌握校园公共区域的人员流动情况,可以辅助人流量控制和执行消毒工作;
(2)对于学生而言,进行校园公共区域人流量预测可以有助于学生提前计划和安排时间,避开人流高峰期前往图书馆、食堂等区域,既保证了公共资源的有效利用,也降低了公共区域的管理难度.
校园公共区域人流量预测包含多种场景应用.以食堂为例,预测其人流量可避免人群拥挤,减少聚集隐患,同时优化供餐服务,减少食材浪费.以往食堂人流量预测由食堂管理人员根据平时积累的经验完成,即管理人员利用所在食堂的食材采购历史记录和消费人次两种类型数据,以同时段就餐人数或消费金额均值对食堂人流量进行估计.现有的估计方式不仅工作量巨大,而且由于参考数据有限,容易出现错误的预估人流量,不具有参考意义.图1 展示了某高校A食堂和B食堂在2019 年6 月23 日~7 月6 日期间的人流量分布情况(横轴表示时间,纵轴表示食堂人流量).
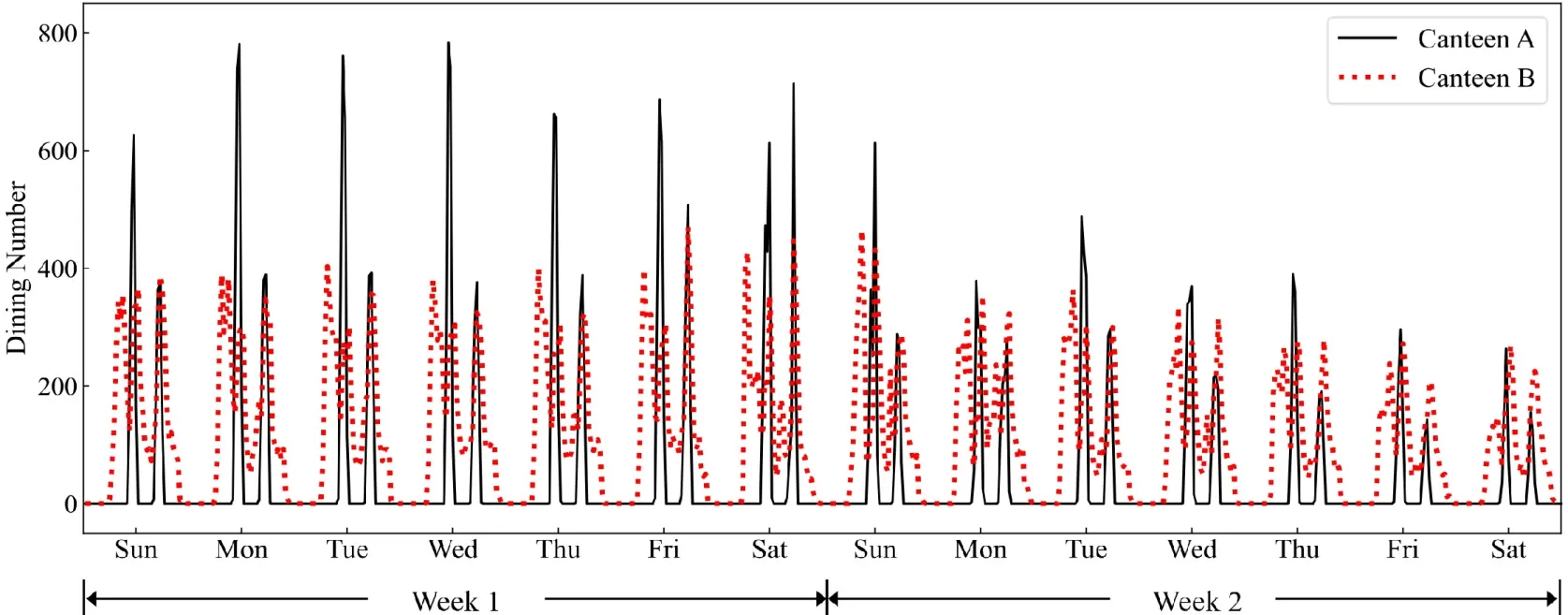
Fig.1 Pedestrian volume distributions of canteen A and canteen B图1 某高校A 食堂和B 食堂人流量分布情况
从技术上讲,校园公共区域的人流量预测问题具有如下挑战.
• 挑战1:师生前往公共区域的行为具有不确定性,即师生选择在何时到何地是不确定事件,只与个人邻近时序片段的心理状态或所面临的环境事件等因素有关,这为区域人流量预测问题增加了不确定性.由图1 可知,第1 周(week 1)人流量高峰远高于第2 周(week 2)的人流量高峰,其原因是后一周正逢期末考试周;
• 挑战2:校园公共区域人流量与学校教学安排直接相关.学校教学安排以5 个工作日为一个教学周执行教学计划,因此在非工作日、法定节假日以及学校考试等时间的人流量分布与工作日期间的差异较大,如图1 中A食堂工作日与非工作日的人流量分布差异;
• 挑战3:不同类型的公共区域人流量之间具有相关性,即:对于相对封闭的校园环境而言,校园中的总人流量变化往往围绕某一常数上下波动,因此,处于同一时刻的一个区域人流量变化会影响到其他区域的人流量.
目前,智慧校园的建设为校园公共区域人流量预测提供了良好的数据基础,将与人流量相关的属性数据预测(如校园食堂人流量预测关注就餐人数以及消费记录)当作是时序预测问题.目前,已有很多学者在时序预测问题上进行了大量的研究[1−4].早期的时序预测模型只能针对相对平稳且呈线性变化的数据进行预测[1,5],很难与校园公共区域这类数据相适应.传统机器学习方法虽然可以对复杂的关系进行建模,却无法有效捕获校园公共区域人流量数据中的短时依赖和长时周期模式,并且这类方法很大程度上需要依赖于特征工程.近年来,深度学习技术在时序任务上得到越来越多的关注.其中,卷积神经网络模型被用于从序列中提取平移不变的局部模式特征进行动作识别[6,7],而循环神经网络也被用于捕获时序任务的时间规律[2,8].但将神经网络模型融合到校园区域人流量数据中,同时捕获不同尺度的时序模式和变量局部依赖性,目前仍在探索之中.
为应对上文提到的挑战,本文提出一种基于深度学习的多尺度时序卷积网络MSCNN(multi-scale temporal patterns convolution neural networks)模型.该模型通过短时模式组件捕获区域人流量序列的短时依赖时序模式(挑战1、挑战3),提出长时模式组件来捕获长时周期时序模式(挑战2、挑战3),设计一种融合组件对不同卷积运算输出结果进行特征融合和重标定来得到最终的预测结果.本文的主要贡献概括如下:
(1)考虑校园公共区域人流量数据的短时依赖、长时周期时序模式特征和变量空间的局部依赖关系,并分别利用短时模式组件和长时模式组件分别建模获取这些特征;
(2)提出一种融合多尺度时序模式特征的融合组件,并对融合的结果进行重标定实现对校园公共区域任一时段人流量进行预测;
(3)在真实校园人流量监测数据集和公开数据集上进行实验,验证本文模型的有效性和执行效率都优于现有的预测方法.
本文第1 节介绍国内外关于时序预测问题以及校园数据预测的应用研究.第2 节对校园公共区域人流量预测问题及文中使用的符号进行了定义.第3 节详述MSCNN 模型的结构设计.第4 节在真实校园数据集和公开数据集上进行实验验证与分析.第5 节总结全文并对未来工作进行展望.
1 相关工作
1.1 时序预测
校园公共区域人流量预测是一个典型的时序预测问题.现有的时序预测方法主要分为基于统计学的方法和基于深度学习的方法.
基于统计学的方法包括回归模型和非参数模型.差分滑动平均自回归模型ARIMA[1,9]利用统计模型对数据序列进行描述和预测,可适用于各种指数平滑技术,且具有足够的灵活性,如自回归模型(AR)、移动平均模型(MA)和滑动平均自回归模型(ARMA)都是其延伸.向量自回归模型(VAR)[1]是单变量自回归模型推广到多变量场景的体现,可将预测场景中的每一个变量作为所有变量的滞后值函数构造模型.此外,时序预测问题还可以视为具有时间变化参数的标准回归问题,如线性支持向量回归(SVR)将时变参数当作是回归损失函数的超参数进行学习.但这类方法无法捕捉变量之间的非线性依赖关系,不适用于校园公共区域人流量预测.高斯过程模型(GP)[10]是一种在连续域上模拟分布的非参数模型,它可以作为贝叶斯推理的函数先验来处理非线性空间的关系.但由于其计算过程中涉及到矩阵求逆运算,增加了模型预测的计算复杂度.
近年来,基于深度学习的方法被广泛应用在多个领域的研究任务中,包括时序预测任务.文献[3,4]将ARIMA 模型和多层感知机MLP 相结合,提出一个混合模型用于时序预测.文献[6]利用卷积神经网络CNN,从输入序列数据中提取平移不变的局部模式作为特征,从而进行动作序列分类.Dasgupta 等人[2]对传统的动态玻尔兹曼机(DyBM)和循环神经网络RNN 进行结合,捕捉时间序列中的依赖关系,实现对多元时序数据的预测.长短时记忆网络LSTM[11]及门控循环单元GRU 是循环神经网络RNN[8]的重要变体,具有额外的记忆控制门和记忆单元,可以存储历史信息,在时序数据分析中得到了广泛应用.Lai 等人[12]设计了LSTNet 模型进行多变量时序预测,该模型利用CNN 和GRU 获取变量之间的短时局部依赖性和长时时序趋势模式,并使用自回归组件来解决神经网络模型的尺度不敏感问题,在多变量时序预测任务上取得了前沿的结果.Shih 等人[13]基于LSTM 和CNN模型提出了TPA-LSTM 方法,该方法利用LSTM 获取时序数据的时间相关性,并利用多个步骤结合CNN 模型获取变量间的注意力分数来进行多变量预测.但GRU 和LSTM 的网络结构天然存在梯度消失的问题,对于长期时序趋势模式的捕获能力有限,并且会产生较高的计算代价.
1.2 校园数据挖掘
校园数据挖掘近年来受到广泛的研究关注.目前,校园数据挖掘主要关注于学生的学习表现,从而提高学生学习质量,完善教育管理.例如:Li 等人[14]提出了一个基于深度学习的顺序预测框架SPDN,利用学生网课的在线学习记录和校园网网络日志预测学生的学习成绩;Zhang 等人[15]借助学生校园卡行为数据对学生的学业表现进行预测,并根据预测结果进行学业预警;Zhang 等人[16]结合学生基本信息,如年龄、所属专业、学业评估考试分数及每学期平均绩点等数据,对学生的辍学风险进行预测.除了学生的学习过程,学生的兴趣爱好预测也引起了研究者的注意:Peng 等人[17]试图通过学生的校园消费记录和轨迹信息,对大学生的网络成瘾水平进行估计,从而预测学生的网络成瘾倾向;Hang 等人[18]对教育签到数据进行分析,在学生的校园WiFi 访问日志的数据基础上,用异构图对学生、兴趣点和活动之间的相似性进行编码,用来预测学生的兴趣点;Wei 等人[19]提出了一个基于改进的Harris-Hawks 优化器预测模型,并且利用学生基本信息以及校园创新创业实践等数据对学生的创业兴趣进行预测.现有的校园数据预测工作大都是将学生作为研究对象,聚焦教育研究与教学实践相关的问题.但是,将学校作为研究对象,对学校公共区域进行人流量预测以维护校园安全,提升校园管理水平的研究工作尚处于起步阶段.
校园公共区域人流量预测研究问题的核心在于如何有效捕获人流量序列中的短时依赖和长时周期时序模式,并考虑多区域之间的相互依赖关系.由于校园会存在多个类型相同的公共区域,如不同校区的图书馆、多个教学楼或食堂,而利用基于统计学的研究往往不能针对多个时序变量同时进行预测,因此无法被直接应用于校园公共区域人流量预测.并且,校园区域人流量变化具有的短时依赖和长时周期时序特性都是人流量预测的重要依据,现有基于深度学习的方法无法直接对区域人流量数据的多尺度模式同时进行考虑,预测结果不够准确.因此,需要一种模型能够同时融合校园多区域人流量数据的多尺度时序模式进行人流量预测.
2 问题定义
校园人流量序列是反映校园特定区域人流量变化的时间序列.用表示第d个区域在t时段的人流量,fd=(xd1,xd2,…,xdT)∈ℝT表示校园某区域在历史T个时段内的人流量序列,(f1,f2,…,fD)∈ℝT×D表示校园D个区域在T个时段的所有人流量序列.
定义(区域人流量预测).给定待预测区域个数D,表示这D个区域在t时刻的人流量,令F=(X1,X2,…,XT)∈ℝT×D为输入历史人流量序列,预测T+h时段D个待预测区域人流量:

其中,h表示目标时段距离当前时段T的时延.
对于不同的数据集,h值代表的含义取决于特定任务的实际需求.例如:对于高校食堂人流量预测,输入人流量序列F=(X1,X2,…,XT)∈ℝT×D的时间度量单位为小时.设XT∈ℝD为D个食堂中午12:00~13:00 时段的人流量,h=6 表示预测6 小时后D个食堂18:00~19:00 时段内的就餐人数.表1 列出了本文中主要使用的符号定义.

Table 1 Symbol notation表1 符号表示
3 基于深度学习的多尺度时序模式卷积网络
校园公共区域人流量预测会受到不同尺度的时序模式影响,呈现出不同的数据表征.例如,预测校园某公共区域2019 年7 月20 日下午17:30~18:00 时段的人流量,与预测时段直接相邻的时段(如7 月20 日17:00~17:30)、对应1 天前的相同时段(如7 月19 日17:30~18:00)以及1 周前的相同时段(7 月13 日17:30~18:00)的人流量数据均能提供有用信息,而当日上午07:00~07:30 的人流量数据提供的信息会少很多.为了得到充分的时序信息,同时减少不相关历史信息带来的影响,我们设计短时模式组件(第3.1 节)和长时模式组件(第3.2 节)分别捕获区域人流量数据的多尺度模式特征,并利用融合组件(第3.3 节)对获取的特征进行融合学习和重标定,以提升对预测目标有益的特征并抑制用处不大的特征.MSCNN 的总体架构如图2 所示.
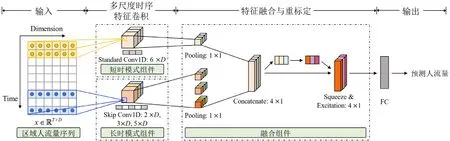
Fig.2 Architecture of MSCNN图2 MSCNN 模型架构图
3.1 短时模式组件
短时模式组件主要捕获短时时序片段FS=(XT−S+1,XT−S+2,…,XT)∈ℝS×D的模式特征,即与预测时段直接相邻的一段历史时间序列片段.直观地,校园公共区域人数的聚集和分散是逐渐形成的,一个区域上一时段的人流量会对下一时段的人流量产生很大的影响.例如:某食堂的就餐人数达到上限,会使大部分人选择更换食堂就餐,从而致使食堂下一时段的就餐人数减少.在MSCNN 模型中,采用CNN 卷积运算来捕获这种短时时序片段模式和不同区域间存在的局部依赖关系.
CNN 卷积核的大小反映了一个单元的状态由多大范围内的邻近单元状态所决定.对于短时模式组件,其网络结构如图3 所示.
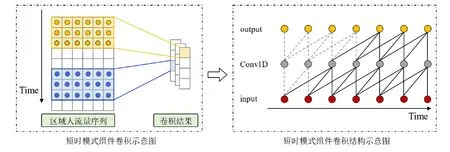
Fig.3 Structure of the short-term pattern component图3 短时模式组件结构
可以发现,短时时序片段在输入空间中表现为相邻的单元.设置K个大小为6×D的卷积核对短时时序片段FS进行卷积操作,可以捕获到短时行为时序模式和变量之间的局部依赖性.其中,用第k层卷积核对FS进行卷积操作:

3.2 长时模式组件
长时模式组件主要捕获长时周期的时序片段FL=(XT-L+1,XT-L+2,…,XT)∈ℝL×D的模式特征,即与预测时段具有相同时序片段或相同星期属性的片段组成.以校园食堂场景为例,由于受到食堂营业时间、固定的教学作息规律等因素影响,食堂流量数据存在明显的周期性,如每周星期三的食堂人流量变化情况与历史星期三的人流量变化类似.对此,长时模式组件的目的就是要捕获食堂流量数据中不同间隔时段中含有周期或相似性的长时周期模式.同样地,长时模式组件也考虑了不同食堂之间相互依赖影响的因素.
与短时模式组件相同,利用卷积操作来捕获上述提到的特征.不同的是:为了捕获长时周期模式,我们基于Dilated 卷积设置了skip 卷积运算来实现该目标,网络结构如图4 所示.
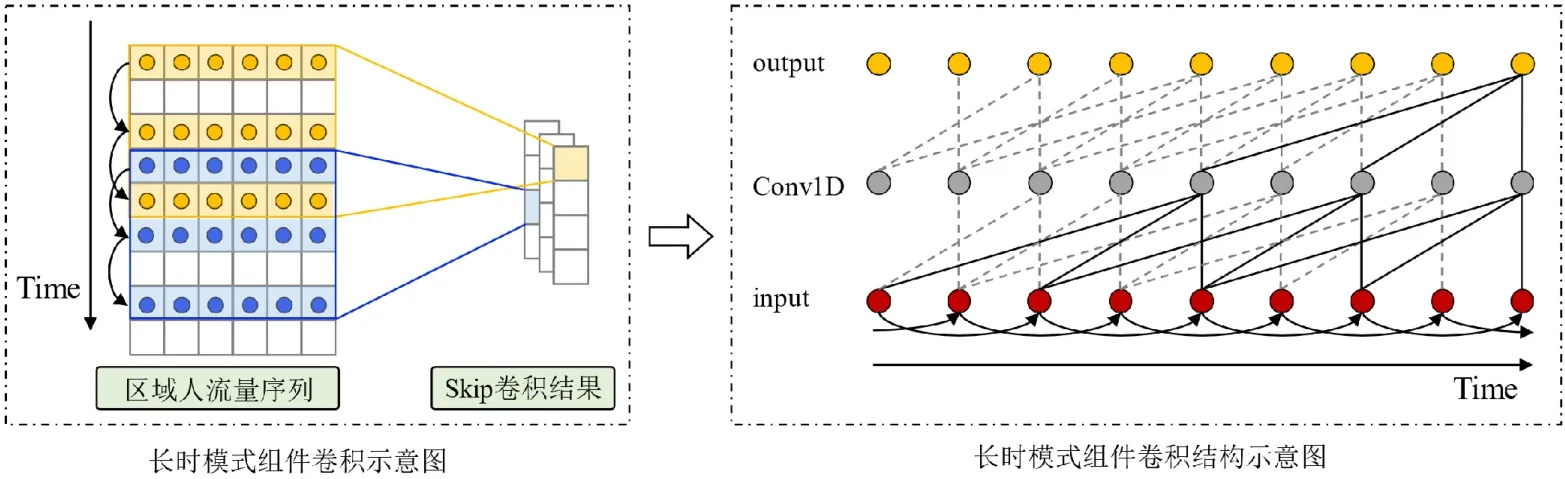
Fig.4 Structure of the long-term pattern component图4 长时模式组件结构
设置K个卷积核对长时周期的时序片段FL进行卷积操作,与普通卷积不同的是,skip 卷积操作是对于选定的FL片段执行跳跃skip 个单元进行运算.此外,MSCNN 模型设置3 种不同维度的skip 卷积核分别捕获不同的长时周期模式特征.详细如下.
• 2-skip 片段:选定与预测时段间隔skip 的每2 个时段形成的片段:

此时,卷积核大小为2×D.则可以得到卷积输出
• 3-skip 片段:通过选定与预测时段间隔skip 的每3 个时段形成的片段:
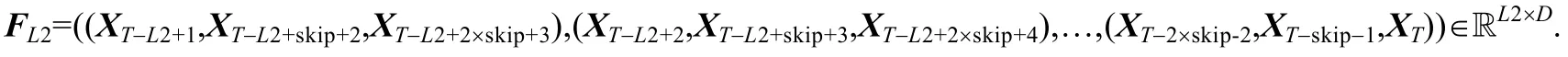
令卷积核大小为3×D,可以得到卷积输出为
• 5-skip 片段:选定与预测时段间隔skip 的每5 个时段形成的片段:
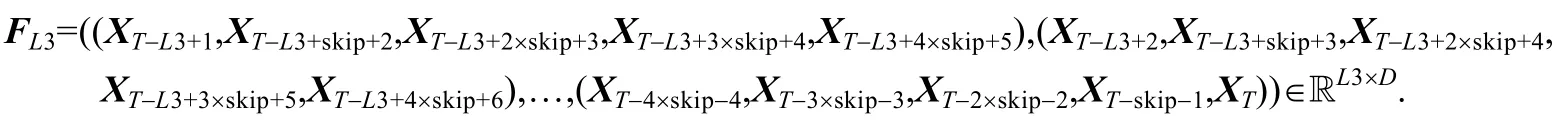
设置卷积核大小为5×D,那么得到卷积输出
与公式(1)中的参数描述相同,3 种不同维度的skip 卷积输出,与短时模式组件输出具有类似可学习的权重和偏置参数.为保证执行skip 卷积时能对原始数据空间的所有序列单元进行卷积计算,对长时模式组件的输入序列FL进行向下zero-padding 操作,经过K个卷积核后,分别得到维度为K×Q2×1,K×Q3×1 和K×Q4×1 的3 种输出结果.
3.3 融合组件
融合组件由两个子件组成,其中,一个子件用于将短时模式和长时模式组件捕获到的特征进行融合,另一个子件用于特征的重标定以便预测到更加准确的结果.该组件的核心依赖于 SENet(squeeze and exicitation network)[20]模型对不同的特征维度上的信息进行聚合.图5 展示了融合组件的具体结构和运算过程.
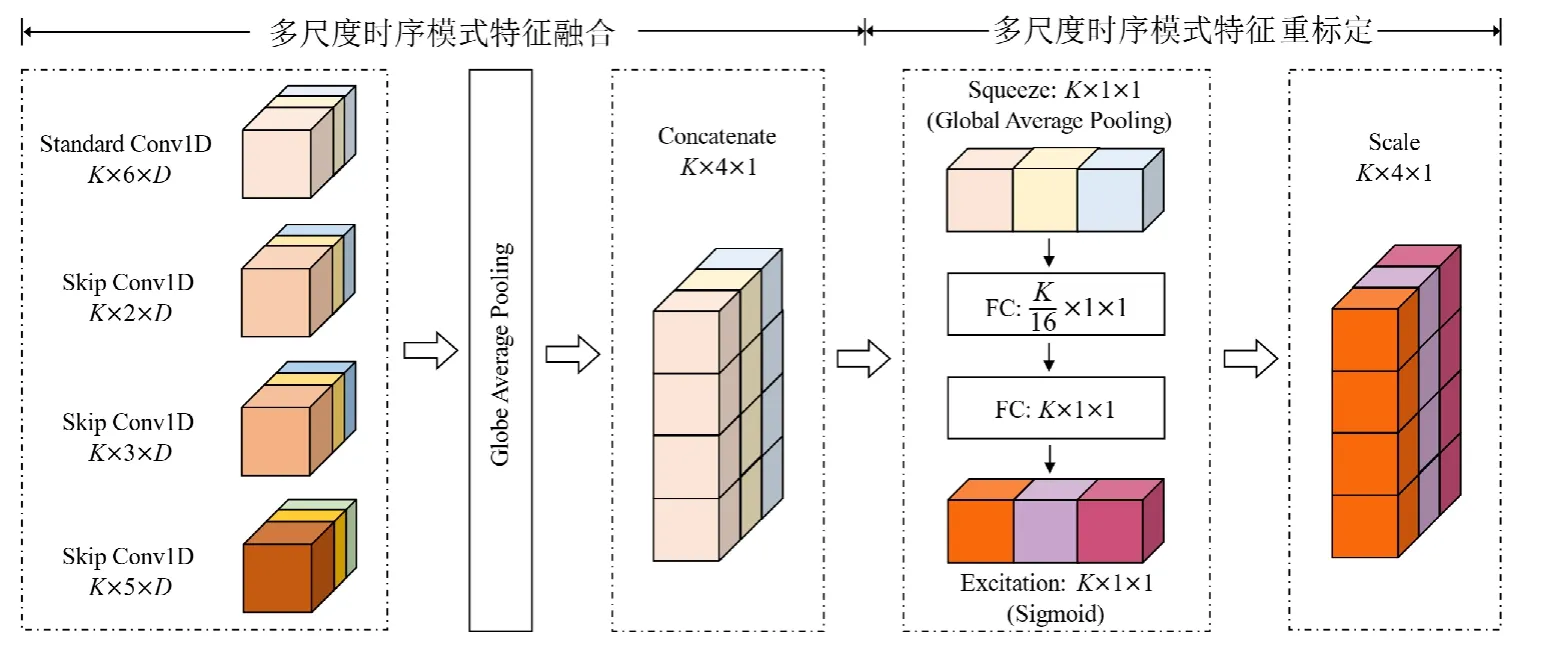
Fig.5 Structure of the fusion component图5 融合组件结构
(1)多尺度时序模式特征融合
为了将短时模式和长时模式组件获取的多尺度时序模式特征信息融合,以便进行后一步分析.由于卷积核不同的设置,输出的结果维度不同,即Qj≠Qj(i≠j,i,j∈{1,2,3,4}).对于不同大小和类别的卷积核映射得到的4 个不同维度的卷积输出,由于其卷积核个数始终为K,因此可以通过Global Average Pooling 保留全局有用信息得到4个维度相同的K×1×1 采样结果,直接进行拼接后可得到K×4×1 的特征融合结果.
(2)多尺度时序模式特征重标定
通过卷积运算捕获的多尺度时序模式特征可以视作是局部感受野在空间(变量空间)和特征维度(不同尺度模式)的信息聚合,其输出结果可以理解为不同变量在不同特征空间上信息的聚合.因此,基于SENet 组件对卷积映射的时序模式特征进行重新标定,获取不同时序长度和待预测时段的新模式特征.具体的实现方法见图5所示的Squeeze 和Excitation 流程.
对于融合的K×4×1 多模式时序特征,首先进行Squeeze 操作,对空间维度进行特征压缩得到K×1×1 的一维实数,表示在特征通道上的空间特征全局分布;其次是Excitation 操作,即通过两个全连接层分别对空间特征通道间的相关性进行学习生成权重,即与融合结果具有相同维度的重标定权重,表示不同特征通道的重要性.需要注意的是:经过第一个全连接层时,将通道压缩比例设定为16;最后通过权重更新对融合结果进行重标定,得到与原始特征具有相同维度K×4×1 的特征映射更新结果.
对于融合得到的特征,采用传统CNN 对序列数据进行预测的结构,经过全连接层后可以得到预测目标,全连接模块同样使用RELU 作为激活函数.在该网络结构中,选择预测任务常用的平方误差作为损失函数,如下式所示:

其中,||⋅||F表示矩阵范数,h为第2 节提到的目标时段距离当前时段的时延.
4 实验与分析
4.1 实验环境设置
4.1.1 实验数据集
本文选取的真实校园数据来源于某高校,使用该校2019 年3 月3 日~7 月20 日春季学期期间某校区的全校师生校园一卡通数据.该校区日常管理较为严格,校外人员无法随意进出该校区,该校区学生在校内的所有消费可通过校园一卡通完成.出于数据隐私保护的角度,所选数据集无法直接公开,因此本文选择了1 个与真实校园数据同样具有周期性表现的时序数据集进行有效性验证.数据集详细介绍如下.
• Canteen-Dining:该高校2019 年春季学期某校区全校师生的校园一卡通消费数据,以每30 分钟为时间间隔统计全校师生在21 个食堂的人流量记录,其中,同一时段的同一校园卡ID 视为单人记录,序列长度为6 720.实验中,将前12 个教学周为训练集,中间4 个教学周为验证集,后4 个教学周为测试集;
• Canteen-Consumption:该高校2019 年春季学期某校区21 个食堂的流水记录,即各个食堂每间隔半小时的消费总金额.基于各食堂消费水平,可侧面反映出食堂的消费人数.训练集、验证集和测试集的划分与上一个数据集相同;
• Solar-Energy(https://www.nrel.gov/grid/solar-power-data.html):Alabama 州级2006 年太阳能生产记录,包含137 个光伏发电厂每间隔10 分钟读取的太阳能发电数据.序列长度为52 560.其中,前219 天作为训练集,中间73 天作为验证集,后73 天作为测试集.
为了显示时序数据集中的短时或者长时周期重复模式特征,通过绘制自相关图对一个时序信号Xt与其自身在不同时刻的互相关程度进行表示,记为R(τ):

其中,μ和σ分别表示时序信号Xt的均值和标准差.在计算时,使用无偏估计量来得到自相关系数.为便于观察,我们从数据集中随机选择3 个变量进行展示,数据集所有变量的自相关图可在模型源码链接(https://github.com/striver314/MSCNN)中查看.
如图6 所示,实验所选用的3 个数据集均存在较高自相关性的重复模式.进一步地,从图6(a)、图6(b)中可观察到,校园真实数据集的短时重复模式(每间隔24 小时)和长时重复模式(每间隔7 天);从图6(c)中可看出,公开数据集的重复模式是每间隔24 小时1 次.
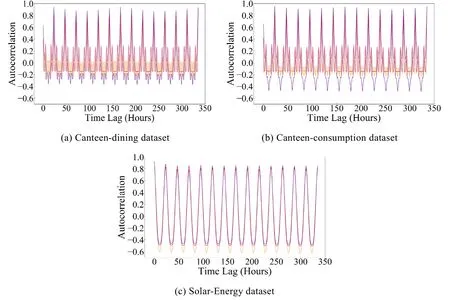
Fig.6 Autocorrelation analysis w.r.t time lag on three datasets图6 3 个数据集随时间滞后的自相关分析
4.1.2 模型参数设置
本文的实验环境为Intel(R)Xeon(R)CPU E5-2698 v3@2.30GHz,并基于Pytorch 1.5.1 框架,使用Python 3.7来实现MSCNN 模型.其中,短时模式和长时模式组件中均使用100(K=100)个相同大小的卷积核,并保证卷积核沿空间轴维度始终为D.此时,融合组件中Excitation 操作的结果取整为100/16=6.由于输入数据的长度会对实验结果产生影响,实验中设定与基准方法LSTNet-Skip[12]相同的序列长度24×7 作为预测序列窗口长度.每次实验均执行50 个Epoch 得到预测结果.
由于校园真实数据的私密性,我们只将实验采用的公开数据集以及MSCNN 模型源码均存放于https://github.com/striver314/MSCNN.
4.1.3 基准方法
本文选取相关工作中提到的7 种时序预测方法与MSCNN 模型进行比较.
• HA:历史均值法,使用预测序列窗口长度的历史序列的平均值作为预测目标的值;
• AR:标准自回归模型,相当于一维的向量自回归VAR 模型;
• LRidge:具有L2 正则化项的向量自回归模型,被广泛应用在多变量时序预测问题中;
• LSVR[21]:具有支持向量回归目标函数的向量自回归模型;
• LSTM[8,11]:长短时记忆网络,作为一种特殊的RNN,其时间记忆性能够在一定程度上解决序列数据的时间依赖问题;
• LSTNet-Skip[12]:带有Skip RNN 层的LSTNet 模型,利用CNN 和GRU 分别捕获短时局部依赖和长时趋势模式;
• TPA-LSTM[13]:带有注意力机制的长短时记忆网络模型,捕获时序数据的时间相关性.
4.1.4 评价指标
本文采用相对平方误差(RSE)、经验相关系数(CORR)以及预测准确率(Accuracy@E)这3 种度量标准来评估模型的预测性能(其中,预测准确率是同一时段内观测值与预测值的误差绝对值在最大允许误差E以内的样本数占所有测试样本的比例.对于不同的数据集,最大允许误差E的取值及表示含义有所不同).
• 相对平方误差的计算公式如下所示:

• 经验相关系数的计算公式如下所示:

• 预测准确率的计算公式如下所示:

4.2 有效性实验
本文提出的MSCNN 模型在数据集Canteen-Dining,Canteen-Consumption 和Solar-Energy 上与第4.1.3 节中提到的7 种基准方法进行了比较.我们测试了这些模型在不同时间间隔h(即目标时段距离当前时段的时延)的预测精度.表2 记录了h分别取3,6,12,24 时,这些模型在Canteen-Dining 和Canteen-Consumption 数据集上未来1.5 小时~12 小时内的预测结果,以及在Solar-Energy 数据集上未来30 分钟~240 分钟内的预测结果.
表2 表明:随着h逐渐增大时,预测难度会增大,但本文提出的MSCNN 模型在多数情况下的RSE 和CORR两种评价指标中均取得更好的结果.特别地,在食堂就餐人数数据集Canteen-Dining 中,MSCNN 模型取得上述方法中最优的结果,在h取3 预测未来1.5 小时内的就餐人数时,MSCNN 模型较LSTNet-Skip 模型提升了1.9%,较TPS-LSTM 模型提升了7.5%.为了进一步验证模型预测性能的稳定性,我们将上述方法在3 个数据集上的RSE 和CORR 指标随着h的变化通过图7 和图8 进行展示.从整体情况来看,MSCNN 模型随着h的增加,其预测结果在3 个数据集上的波动程度与预测任务的难度波动具有一致性,即预测结果随着h的增大而降低.在2个真实校园数据集中,波动程度最大的是TPA-LSTM 模型.而在公开数据集上,MSCNN 模型和LSTNet-Skip 和TPA-LSTM 这3 种方法的整体预测结果相似,均远胜于其他时序预测方法.
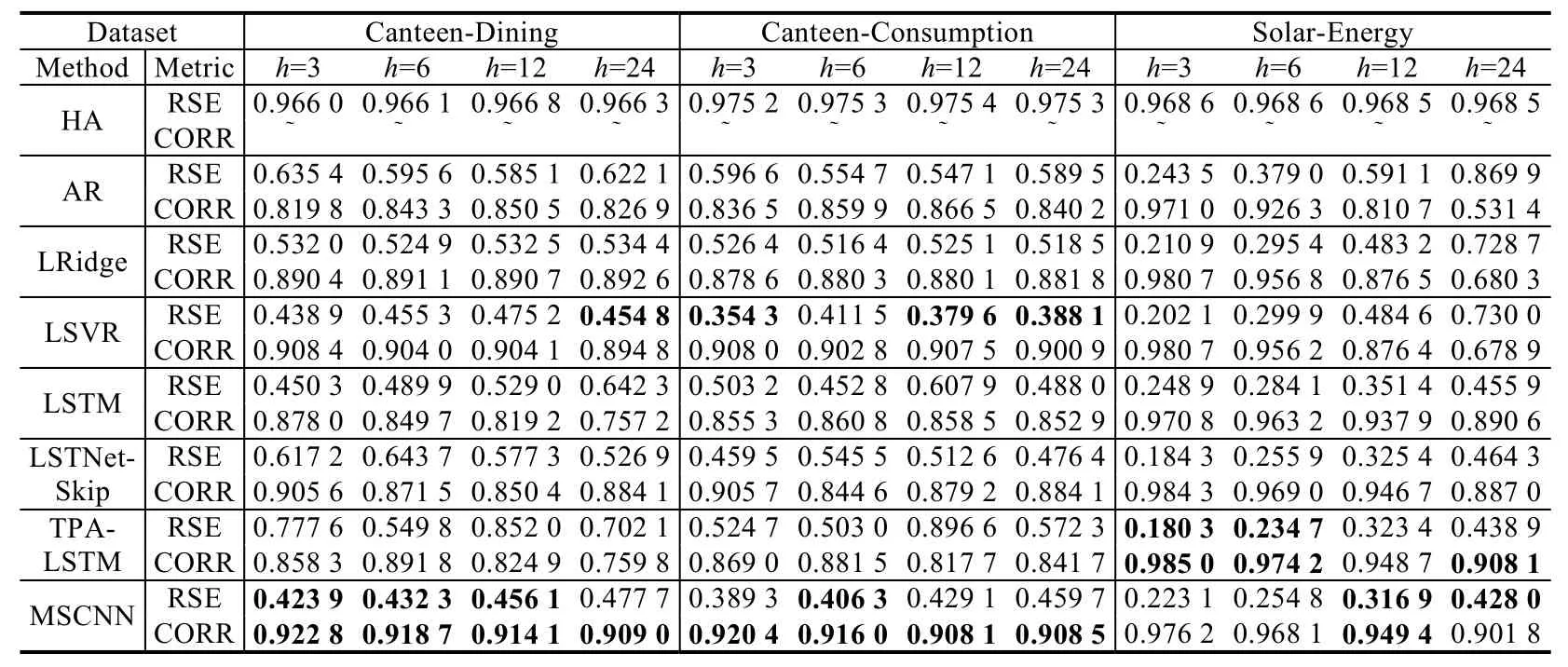
Table 2 Experimental results (in RSE and CORR)of all methods on three datasets表2 所有方法在3 个数据集上的实验结果(RSE 和CORR)
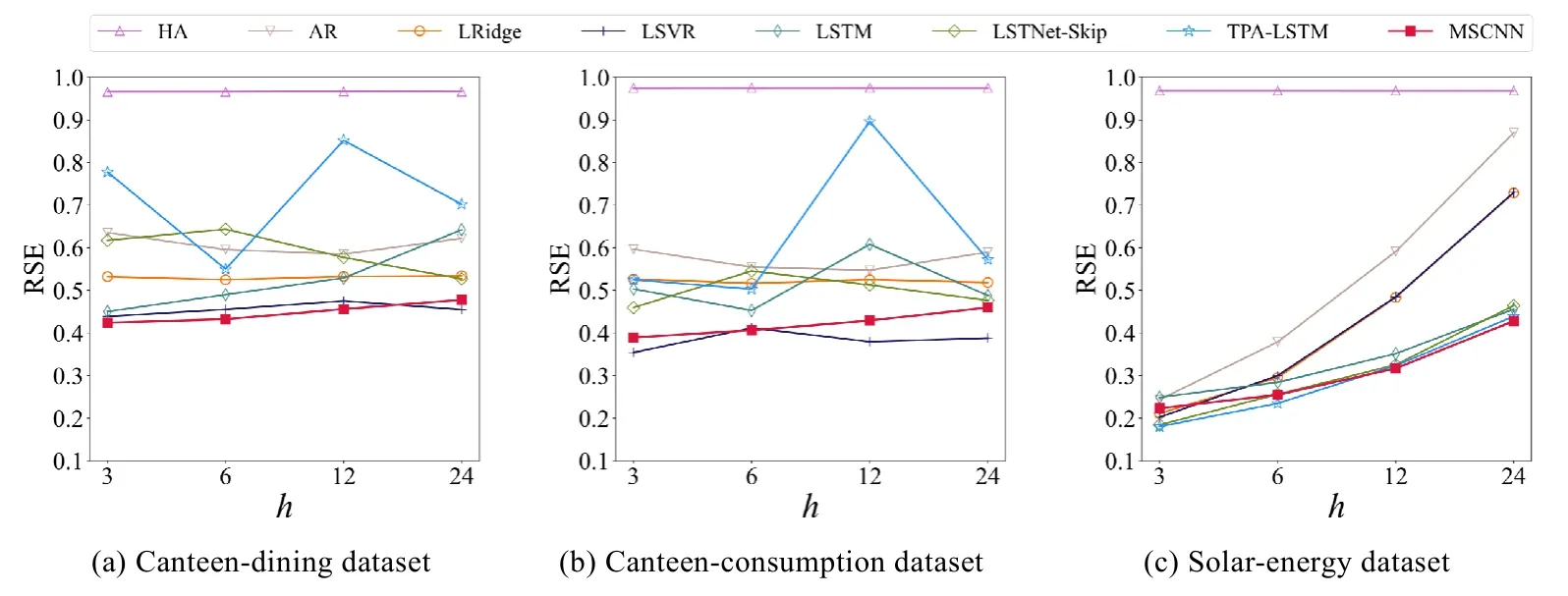
Fig.7 Performance (in RSE)of all methods on three datasets with different h图7 所有方法在3 个数据集上随着h 变化的实验结果(RSE)
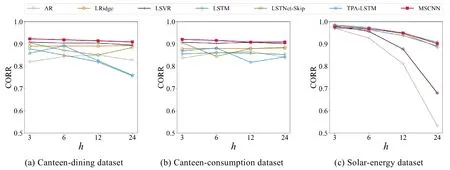
Fig.8 Performance (in CORR)of all methods on three datasets with different h图8 所有方法在3 个数据集上随着h 变化的实验结果(CORR)
此外,考虑到模型的实际应用场景需要准确了解不同时段的人流量分布情况,结合最大允许误差E选取的实际意义,我们以数据集Canteen-Dining 为例,最大允许误差E表示某个食堂的人流量预测值的误差极限值,计算LSTNet-Skip,TPA-LSTM 以及MSCNN 这3 种方法在h=3 的Accruacy@E指标,结果如表3 所示.可以发现:在食堂人流量预测问题中选取的5 个不同误差的Accuracy@E指标,MSCNN 模型在4 个指标中都取得了最优的结果.

Table 3 Result of Accuracy@E (h=3)on Canteen-dining dataset表3 Canteen-dining 数据集的Accuracy@E(h=3)结果
同时,为了证明MSCNN 模型在食堂人流量数据中对短时依赖和长时周期的多尺度时序模式的捕获能力,我们绘制了h=3 时,单个食堂在未来一天内预测值和真实值的对比结果,如图9 所示.其中,图9(a)为LSTNet-skip模型的对比结果,图9(b)为MSCNN 模型的对比结果.可以明显看出:MSCNN 模型可以更加准确地预测到每天不同时段的人流量分布情况,而LSTNet-skip 模型在人流量高峰期的预测值与观测值有较大的误差,进一步验证了MSCNN 模型可以更为准确地捕获到多尺度时序模式特征.
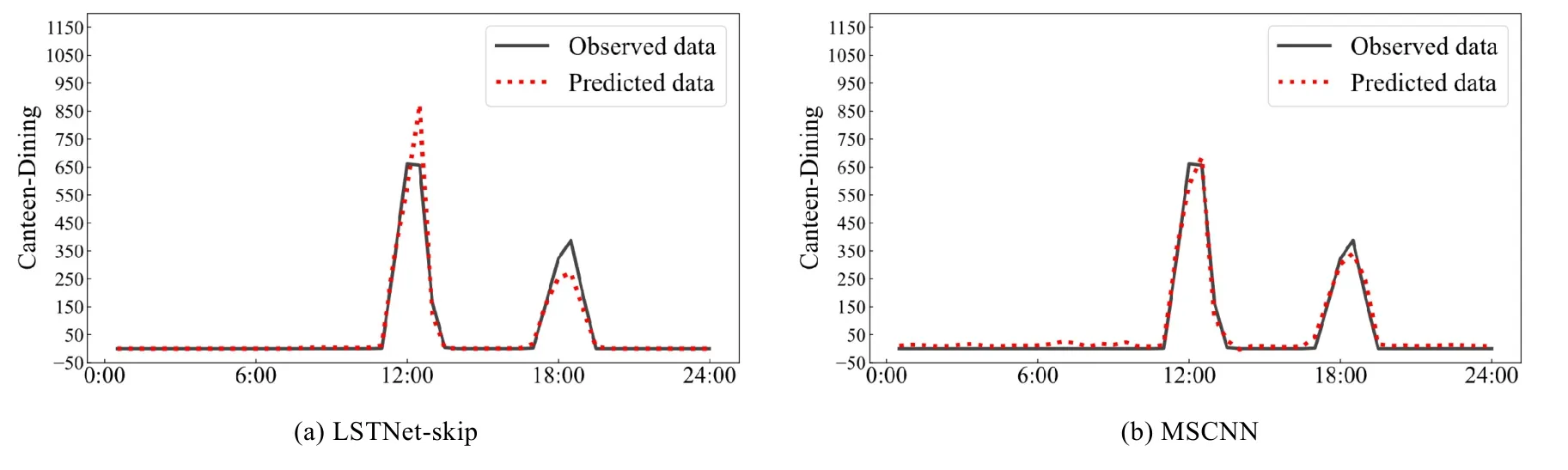
Fig.9 Predicted data (h=3)of LSTNet and MSCNN vs.obsvered data on Canteen-dining dataset图9 LSTNet-Skip 和MSCNN 在数据集Canteen-dining 上,单个食堂的预测值(h=3)与观测值对比情况
综上,分析实验结果可得到如下3 点结论.
(1)对比MSCNN 和HA 结果发现:MSCNN 模型的效果明显优于仅根据历史时序片段的均值进行估计的模型HA.这是由于人流量预测是一个复杂非线性且受综合因素影响的问题,从另一个方面也说明了依靠经验进行预测会产生较大的误差;
(2)对比MSCNN,AR,LRidge 和LSVR 模型可以发现:与这些基于统计学的模型相比,MSCNN 模型可以取得更加稳定且准确的预测结果.这是因为其他模型对于非线性数据无法很好地拟合,并且在多变量时序预测场景下,这些模型未考虑变量之间的依赖性;
(3)对比MSCNN,LSTM,LSTNet-Skip 和TPA-LSTM 模型可以发现:MSCNN 模型要优于现有基于神经网络方法的相关模型,主要体现在模型预测性能的稳定性、预测误差以及与真实数据的拟合效果等多个方面.这是由于MSCNN 模型捕获了多尺度时序模式特征,相较于只获取单一时序模式的方法效果更好.
4.3 时间性能分析
表4 展示了上述4 种基于神经网络的方法(即MSCNN,LSTM,LSTNet-Skip,TPA-LSTM)在真实数据集上的模型训练时间和测试时间.所有模型的训练过程都在相同的实验环境和实验参数下完成.
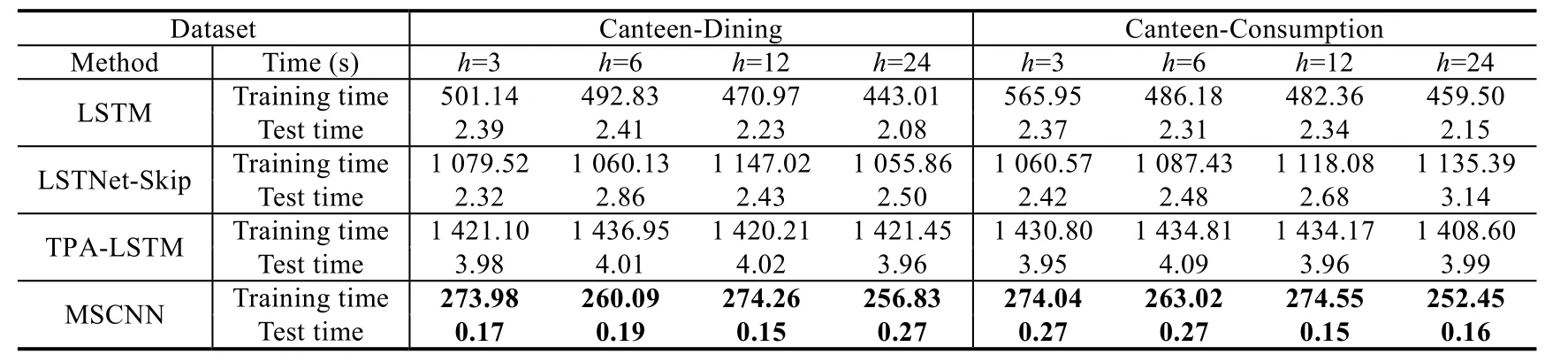
Table 4 Comparison on training time and test time of four methods表4 4 种模型训练时间和预测时间对比
相较于与其他3 种基于LSTM 的模型(LSTM,LSTNet-skip,TPA-LSTM),仅在模型内部使用CNN 结构的MSCNN 模型在训练时间和测试时间上明显少于另外3 种方法.随着数据规模的增大,这样的优势会逐渐扩大.对于校园公共区域人流量预测和控制可以得到更好的应用.
4.4 消融实验
为验证MSCNN 模型设计的有效性和合理性,我们使用真实校园数据集进行消融实验.每次对模型移除一个组件,并与MSCNN 模型进行对比验证各组件的效率.将没有不同组件的模型进行命名用作实验区分.
• MSCNNw/oCNN:MSCNN 模型没有短时模式组件捕获短时依赖时序特征;
• MSCNNw/oSkip:MSCNN 模型没有长时模式组件捕获长时周期模式特征;
• MSCNNw/oSENet:MSCNN 模型没有融合组件进行多尺度时序模式特征重拟定.
图10 和图11 分别展示了消融实验在不同真实数据集上,RSE 和CORR 指标的结果.
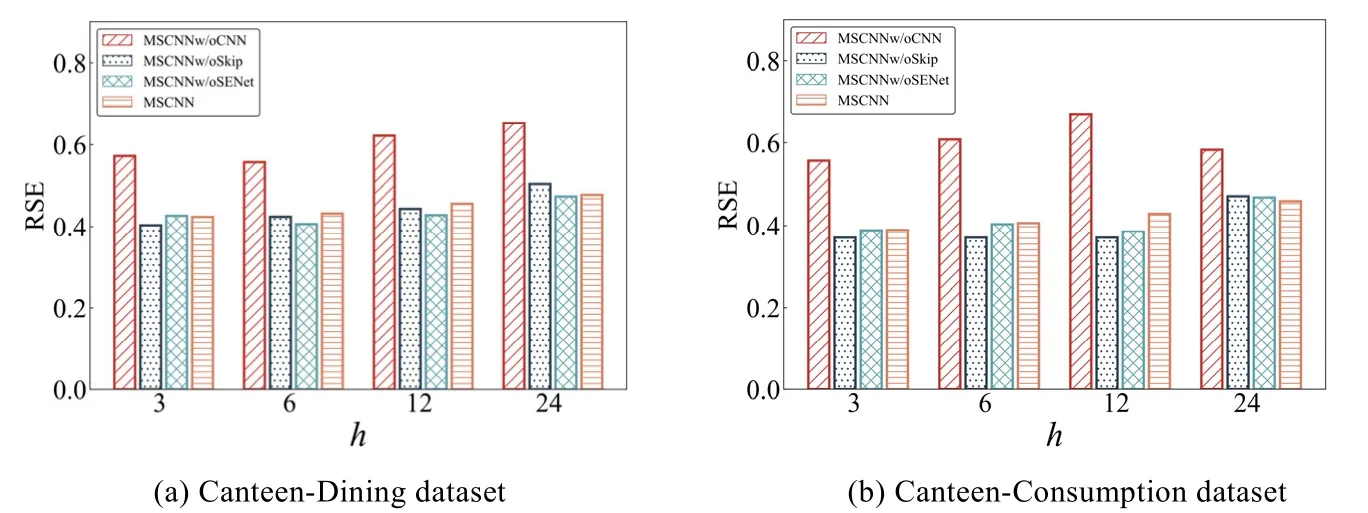
Fig.10 Results (in RSE)of MSCNN in the ablation test on Canteen-dining and Canteen-consumption datasets图10 MSCNN 模型在数据集Canteen-dining 和Canteen-consumption 上的消融实验结果(RSE)
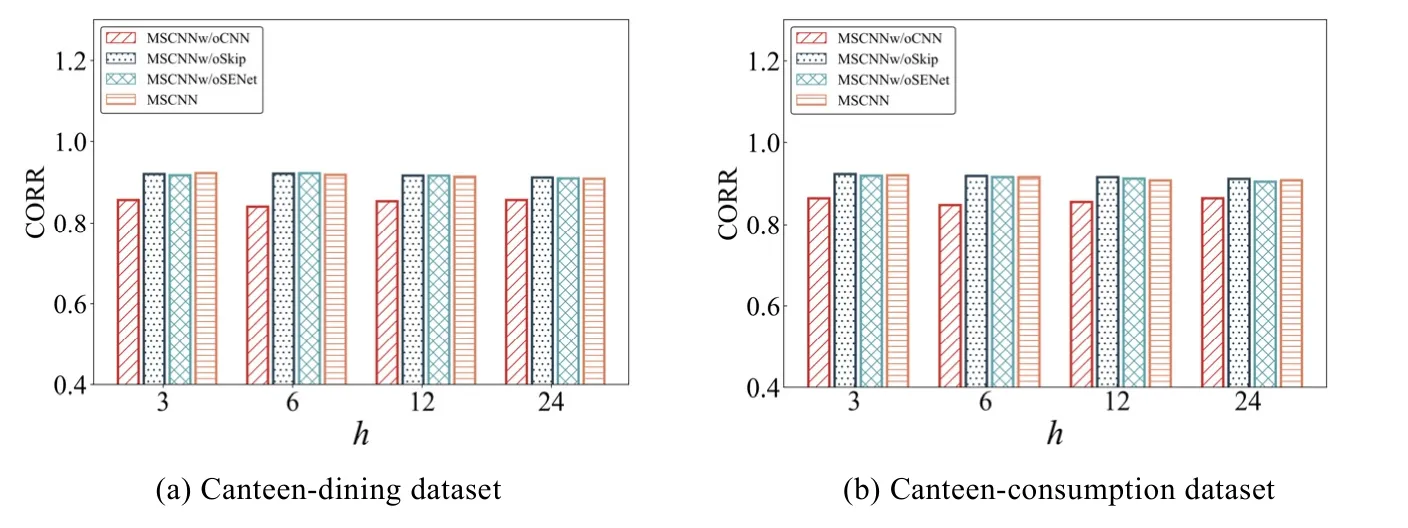
Fig.11 Results (in CORR)of MSCNN in the ablation test on Canteen-dining and Canteen-consumption datasets图11 MSCNN 模型在数据集Canteen-dining 和Canteen-consumption 上的消融实验结果(CORR)
可以看出:短时模式组件对实验结果影响最大,没有短时模式组件的MSCNN 模型在两个指标上均取得最差结果.而没有长时模式组件的 MSCNN 模型在 RSE 指标上取得更好的结果(h=3,6,12);但在h=24 时,MSCNNw/oSkip 模型的结果较差.这意味着没有长时模式组件无法预测未来时长较长的结果.融合组件对实验结果的影响出现较大波动,对MSCNN 模型的效果提升所起到的作用较小.
5 总结
本文提出一种基于深度学习的多尺度时序卷积网络MSCNN,以对校园公共区域人流量进行预测.MSCNN模型利用短时模式和长时模式组件捕获多尺度时序数据中的短时依赖、长时周期模式和变量相互依赖特征,并利用融合组件对特征进行融合和重标定.在真实校园环境数据集上的实验表明:本文提出的MSCNN 模型的预测效果优于其他已有的校园区域人流量数据预测方法,验证了该模型在捕获多尺度时序模式方面的优势.
下一步,我们将通过注意力机制等方法来优化MSCNN 模型,并把校内各公共区域之间的依赖关系考虑进来,以提升模型的预测精度.同时优化MSCNN 模型中不同尺度模式特征的融合组件,拓宽应用场景.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-28
今日农业(2021年10期)2021-11-27
科学与信息化(2020年18期)2020-08-03
铁道建筑技术(2020年11期)2020-05-22
意林·全彩Color(2019年11期)2019-12-30
今日农业(2019年15期)2019-09-03
趣味(语文)(2019年3期)2019-06-12
文理导航(2018年9期)2018-08-16
电子制作(2017年13期)2017-12-15
现代经济信息(2016年34期)2017-08-12
