
基于参照物和深度估计的建筑物体尺度估算
2021-05-28 12:38丁晓凤熊赟晖林祖轩
现代计算机 2021年10期
丁晓凤,熊赟晖,林祖轩
(华南理工大学数学学院,广州510640)
0 引言
单目图像中物体的尺度估算是计算机视觉领域的经典研究方向,在建筑保护与重建[1]、场景理解[2]、图像合成[3]等领域应用广泛。目前,对建筑物的保护和重建大多是对已有建筑进行3D扫描后进行建筑物外部和内部信息的重建。大部分重建工作集中在建筑物外部轮廓[4],也有对室内空间信息的重建工作[5]。这些重建工作的一个关键基础就是需要建筑物的3D点云数据。但是,在对已损毁建筑的重建工作上就会遇到困难。由于历史原因,也许只保留了这些建筑的历史图像信息,而实物荡然无存,也就无法通过扫描的方式获取它们的三维数据。因此,需要从这些图像中恢复出一些关键物体的尺度信息来重建已损毁的建筑及建筑间的空间布局,这是建筑群布局复原流程的关键[6]。
目前苹果和谷歌公司都有开发有关测距的测距仪App,但是这些软件存在较多的限制条件,例如:拍摄相机的所有相机参数已知,只能测量近距离的小物体尺度等,对于图像中尺度信息稍大的建筑物,物体尺度信息的计算容易造成较大的偏差。因此,本文的工作集中在对单目图像场景的建筑物尺度估算上。建筑物尺度估算的关键是需要获取单目图像中各像素点的深度信息,但目前对单目图像的深度信息估计还是存在一定的偏差,影响场景中各物体尺度的计算准确度。这就需要引入先验知识来改善计算精度。根据这样的思路,提出了检测图像中已知尺度的参考物体,并用它来修正图像中的其他建筑物尺度。从实验效果来看,在增加了先验信息的情况下,能有效地提高建筑物尺度计算的精度。
1 相关工作
目前,3D LIDAR等基于结构光的深度获取设备获取到的深度信息为最准,但也存在数据噪声的问题,获取物体的三维数据的过程也相对复杂。而单目图像的获取成本相对来说较低,设备也比较普及。特别是早期古建筑或园林只保留了少量图像资料,要对它们进行重建恢复,就只能从已有的单目图像中进行深度估计。
1.1 单目图像深度估计
Lecun等人[7]在LeNet架构中提出的CNN可以对高维图像数据进行处理,CNN利用卷积神经核提取图像特征,通过深度神经网络对特征层抽象来完成高级的视觉任务,如基于深度学习的单幅图像深度估计方法。Saxena等人[8]在最大化后验概率框架下以超像素为单元,利用马尔可夫随机场(MRF)拟合特征与深度、不同尺度的深度之间的关系,进而实现对深度的估计。
Eigen等人[9]首次将深度神经网络用于单目深度估计,使用两个尺度的神经网络对单张图片的深度进行估计:粗尺度网络预测图片的全局深度,细尺度网络优化局部细节。Liu等人[10]将深度卷积神经网络与连续条件随机场结合,提出深度卷积神经场,用以从单幅图像中估计深度。对于深度卷积神经场,使用深度结构化的学习策略,在统一的神经网络框架中学习连续CRF的一元势能项和成对势能项。Garg等人[11]利用立体图像对实现无监督单目深度估计,不需要深度标签,其工作原理类似于自动编码机。训练时利用原图和目标图片构成的立体图像对,首先利用编码器预测原图的深度图,然后用解码器结合目标图片和预测的深度图重构原图,将重构的图片与原图对比计算损失。Jin Han Lee等人[12]提出了一种基于多尺度局部平面制导层的从小到大的端到端的单目图像深度估计方法。Katrin Lasinger等人[13]提出了一种对于深度的范围和尺度具有不变性的训练方法,从而可以在训练期间混合多个数据集,利用3D电影构建了一个数据集并进行训练,然后对未在训练数据集中出现过的数据进行评测。这个方法的主要特点是将不同类型的数据集混合在一起进行训练,从而改善图像深度估计的精度。
1.2 目标检测
在得到了图像深度估计值后,由于深度估计算法存在一定的误差,这样会导致计算图像物体间距离也产生偏差。解决这个问题的一个思路是检测图像中参照物:已知尺度的物体(如墙面上一块已知尺度的方砖),用深度估计值得到一个估计距离,再和精度值比较得到一个尺度修正系数,重新调整图像物体间的距离,从而提高图像中物体尺度的计算精度。因此要利用参照物的真实尺度,必须先从图像中检测出已知的参照物。
传统目标检测的方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,常用的特征有SIFT[14]、HOG[15],最后使用训练的分类器进行分类。SSD[16]检测算法使用不同阶段不同分辨率的下采样特征图进行预测,表征能力较弱。FSSD[17]检测算法也是使用不同阶段不同分辨率的特征图进行预测,相比于SSD,FSSD多了一个特征融合处理,将网络较低层的特征引入到网络的较高层,在检测的时候能够同时考虑不同尺度的信息,使得检测更加准确。R-CNN[18]生成区域的方法是传统方法Se-lective Search,主要思路是通过图像中的纹理、边缘、颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,每个生成的区域即一个候选区域。这种方法基于传统特征,速度较慢。后来就有了速度较快的Faster R-CNN[19]和RFCN[20]算法。
YOLO算法是端到端的目标检测算法,目前已有4个进化版本。YOLOv1[21]开创性提出了目标检测中的anchor-free,在速度上得到了很大的提升,但在精度上与两阶段的算法还有差异。YOLOv2[22]采用DarkNet-19作为特征提取网络,增加了批量标准化(Batch Nor-malization)的预处理,并借鉴了Fast R-CNN的思想,引入Anchor机制,利用K-means聚类的方式在训练集中聚类计算出更好的Anchor模板,在卷积层使用Anchor Boxes操作,增加区域提议的预测,同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。YOLOv3[23]在v1和v2基础上做了一些改进,主要包括三点:新的backbone基础网络、多尺度预测和损失函数的调整。2020年YOLOv4[24]设计了一种有效的策略用于扩展大目标检测器,使其更有效、更适合GPU训练。我们采用了YOLOv3算法,其在稳定性、速度和精度上都达到了较好的平衡。
2 尺度估算流程及其关键算法
单目图像尺度估算的流程主要是,采用已有的深度估计算法对单目图像进行深度估计,再结合目标检测确定已知尺度的参照目标物,引入先验知识进行尺度的修正,最后通过尺度估算公式得到单目图像中建筑的真实尺度估算值。如图1所示。
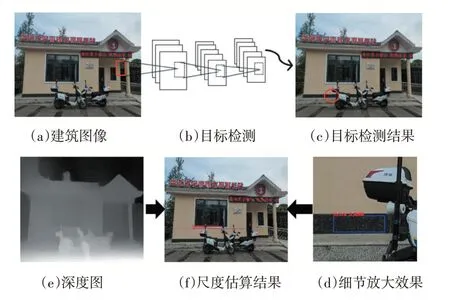
图1 本文主要流程
在整个流程中,关键步骤如下:
(1)单目图像的深度估计。对获取的单目图像用文献[13]深度学习算法来对单目图像进行深度估计,得到每一像素点的深度估计值。
(2)图像中参照物的检测。在获取单目图像后,需要对图像中已知尺度的参照目标物进行检测。考虑到检测精度和检测效率,采用YOLOv3来进行参照目标物的目标检测。将单目图像作为神经网络的输入,然后获取参照目标物的检测框,将参照目标物估计尺度和真实尺度信息相对应,就能获得相应的修正系数。
(3)建筑真实尺度估算。将单目图像的深度信息和目标检测中得到的修正系数相结合,通过尺度估算公式来实现对单目图像中的建筑进行真实尺度估算。
3 算法具体实现过程
整个算法分三步骤完成:①先对单目图像进行深度估计,得到每一像素点的深度信息,通过坐标转化得到每一像素点的空间坐标。②再对图像进行参照物目标检测,结合参照物真实尺度得到修正系数。③最后通过修正系数和尺度估算公式得到建筑物体尺度的估算值。

图2 参照物目标检测
3.1 单目图像深度估计
对图像各像素点深度信息的估计采用了文献[13]的算法,这是一种基于迁移学习的无监督单目深度估计的算法。先利用Pareto-optimal算法将五种互补训练集进行混合训练:ReDWeb、MegaDepth、WSVD、DIML Indoor和3D movies数据集,使算法具备一定的尺度不变性特征。然后根据鲁棒性损失函数来预测图像深度:

式中,Nl表示训练集的大小;M表示图像中像素的个数;Um表示一幅图像中修正了20%最大残差的像素点个数;d表示预测深度;d*表示相对应的真实深度;K=4表示4个等级,每一个等级图像分辨率减半;Ri=di-,α=0.5。通过对尺度和位移不变的损失函数约束最后得到单目图像的深度估计。在此深度估计图的基础上,再通过转化函数得到图像相对深度矩阵,从而获取每一像素的深度估计值。
3.2 单目图像参照物体目标检测
在目标检测领域,基于深度学习的目标检测算法主要分为Region-Proposal和End-to-End,前者需要对原始图像进行特征提取,找到可能含有目标的候选框;再结合CNN进行检测,输出目标类别和位置。后者是输入原始图像到深度学习网络中,直接输出图像中目标类别和位置。从便捷性和检测效果上来看,采用端对端的算法能直接获得检测结。YOLO算法正是这种算法的典型代表,在目标检测中有更好的精度和速度。
将单目图像作为YOLO算法的输入,输出为类别标签和包围框信息。在得到的图像中标定目标参照物的位置(Mleft,Mright,Mtop,Mbot)之后,确定可以表示参照物尺度的像素点坐标(x,y),如图2所示M1=(x1,y1),M2=(x2,y2)。
3.3 建筑真实尺度估算
通过图像的深度和像素坐标转化得到像素的空间坐标,再对图像目标检测得到参照目标物的估算尺度与真实尺度相结合的修正知识,然后把修正知识引入尺度估算,最后对建筑真实尺度估算公式进行构建,从而获取图像中建筑的真实尺度估算值。
3.3.1像素坐标系与相机坐标系之间的转换
像素坐标系[u,v]向相机坐标系[Xc,Yc,Zc]进行转换的实质是先由像素坐标系转化为图像坐标系,再由图像坐标系转化为相机坐标系。
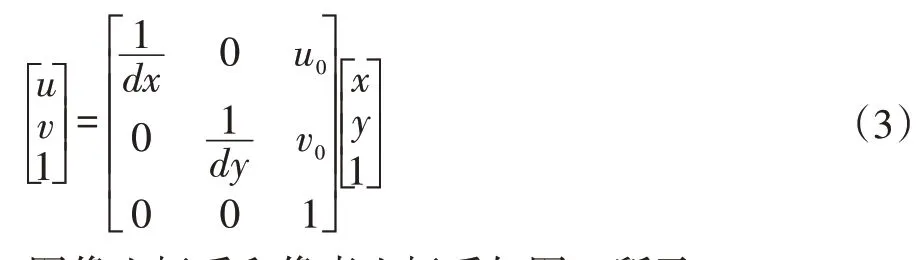
以图像左上角为原点建立以像素为单位的直角坐标系u-v,像素的横坐标u与纵坐标v分别表示图像数组中所在的列数与所在的行数。将相机光轴与图像平面的交点(一般位于图像平面的中心处,也称为图像的主点)定义为图像坐标系的原点O1,且x轴与u轴平行,y轴与v轴平行,假设(u0,v0)代表O1在u-v坐标系下的坐标,dx与dy分别表示每个像素在横轴x和纵轴y上的物理尺寸,则图像中每个像素在u-v坐标系中的坐标和在x-y坐标系中的坐标之间存在如下关系:

式中,假设图像坐标系的单位为毫米,dx的单位为:毫米/像素。x/dx的单位为:像素。矩阵形式表示为:
图像坐标系和像素坐标系如图3所示。
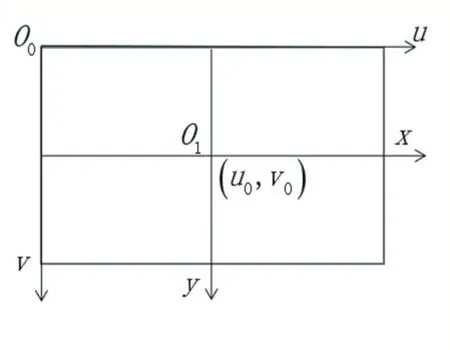
图3 像素和图像坐标系
根据针孔成像原理如图4所示,以平面π为摄像机的像平面,点Oc为摄像机中心,f为摄像机的焦距,以Oc为端点且垂直于像平面的射线为光轴或主轴,主轴与像平面的交点p为图像的主点。

图4 图像和相机坐标系
由图4可得,图像坐标系为o-xy,摄像机坐标系为Oc-xcyczc。记空间点Xc摄像机坐标系中的齐次坐标为:Xc=[xc yc zc1]T。它的像点m在图像坐标系中的齐次坐标为:m=[x y1]T。根据三角形相似原理:.矩阵形式表示为:

当前大部分数码相机拍摄的照片属性里面都有焦距的信息,早期的35mm胶片相机拍摄的图片,相片大小为36mm×24mm,可以假设视角范围是45°,这样也能近似得到焦距信息。因此,根据公式(5)可以实现从像素坐标系到相机坐标系之间的转化。
3.3.2 基于映射原理的尺度估算公式定义
单目摄像机拍摄的图像满足透视投影的原理[25],如图5所示。

图5 针孔成像原理
我们可以建立一个估算尺度和真实值之间的比例关系,用来修正建筑的真实尺度估算。根据透视投影的原理和三角形相似定理,假设从深度估计算法中得到深度信息zc的与真实深度值ztrue之间存在一个比例关系,则根据公式(5)可计算出来的两点间距离也存在这样相同的比例。如图6所示,由于图像中物体真实尺度与估算尺度之间的比例一致,我们可以利,其中dtrue是参照物da的真实尺度,da是参照物通过深度估计算法计算出来的尺度。
进而构建尺度估算的修正公式。以db为例,其修正后的尺度估算值为D=db·k,详细推导过程见附录。
算法1.步骤如下:
输入.图像像素点的深度估计值和基于目标检测的参照物修正系数k。
输出.图像建筑尺度估算值。
(1)计算参照物的估算尺度,从图像中参照物位置,选取已知尺度dtrue参照物的两个像素点,再结合相机参数焦距f获取空间坐标(xai,yai,zai)和(xaj,yaj,zaj),通过欧氏距离公式计算得到参照物的估算尺度:用参照物定义一个修正系数

式中i,j=1,…,m,m为图像像素点个数。这样就可以得到修正系数。
(2)计算建筑目标物的估算尺度,从图像中建筑目标物的位置,选取表示建筑尺度的两个像素点,获取空间坐标(xbi,ybi,zbi)和(xbj,ybj,zbj),通过欧氏距离公式计算得到建筑物的粗估算尺度:

(3)计算D=db·k,将其作为图像中建筑真实尺度估算值并返回。
图6展示了从图像中计算建筑尺度的方法。首先确定参照物目标位置,然后选取已知尺度dtrue的两个像素点A和B,计算图像中参照物的估算尺度da,接着选取表示图像中建筑物尺度的两个像素点C和D,计算建筑物的估算尺度db;最后在真实尺度估算公式中计算得到建筑物M-N间的真实尺度。
4 实验及结果分析
实验运行环境是基于Windows 10系统,采用Python 3.7实现,目标检测算法YOLOv3的训练是在TensorFlow下基于DarkNet框架下进行,深度估计算法的训练是在PyTorch下进行,在实验过程中还用到了OpenCV等图像处理库。
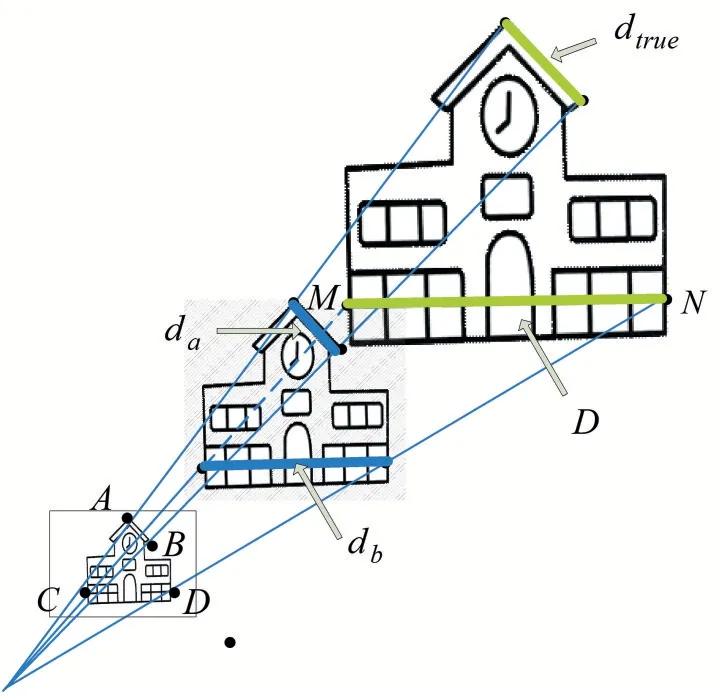
图6 真实尺度修正算法
4.1 数据类型及来源
算法处理的数据有室外场景单目建筑图像和用于深度估计的混合训练集。
有两组带有建筑物体的单目图像数据,这些图像中都带有焦距信息。一个来自于园林场景数据集,包括阁楼、船厅、凉亭、祠堂等建筑物;另一个是日常场景的数据集,包括楼房、车库、走廊、体育馆、仿古建筑等建筑物。用于深度估计的混合训练集包括:ReDWeb、MegaDepth、WSVD、DIML Indoor和3D movies。
4.2 参照物检测对应点优化
如算法实现过程所述,所提出的尺度估算公式与建筑物的相机坐标有直接的关系,而建筑物的相机坐标是通过参照物检测获取的对应像素点坐标和图像的深度估计得到的。因此,参照物检测对应点的选择对尺度估算结果有着重要影响。
以任一像素点M为例,假设检测的像素点的像素坐标为M(x,y),对应的空间坐标为M(xc,yc,zc)。如图7所示,选取以点M为中心,步长α为半径的矩形框中所有的像素点,使得更新后的像素点M的空间坐标为:。
剔除异常数据。利用Z-分数统计量检测异常值并剔除异常点和以M为中心的对称点。Z-分数为:,其中σ为矩形框中像素点深度值数据的标准差。若矩形框中存在一点,其Z-score>τ,其中τ为阈值,则剔除该点及其关于M的对称点,然后再根据上述步骤重新计算M的空间坐标。若剔除点为M,则跟据算法1重新获取参照物坐标。建筑物坐标优化和上述方法同理。

图7 用于坐标优化的所有像素点
4.3 误差定义
通过人工标注的方式得到图像参照物的真实尺度值,再利用算法1的计算结果得到图像建筑物的真实尺度估算值。用建筑尺度估算值与真实值之间的相对误差和整体误差来评估本文算法的有效性。误差函数定义如下:
相对误差函数:

整体误差函数:

整体误差为同一图像内多个物体尺度估算的均方误差,用来表示图像的整体尺度估算误差,其中c表示建筑尺度估算值;gt表示建筑尺度真实值;eabs=|c-gt|表示绝对误差;i=1,…,n表示一组可以表示建筑尺度的估算值数目。
4.4 结果分析
对于修正系数的有效性,从10个不同场景中选取了3个样例在表1中展示。图8为这10个不同场景用了修正系数下的尺度估算的对比结果。由图7的对比结果显示,修正算法对尺度估算具有更好的准确性,误差更小。
接下来所有表中出现的“尺度估算”都是经过修正系数修正过的尺度估算值。

表1 修正系数下的估算结果

图8 添加修正系数前后对比的结果
表2为同一单目图像内,相同场景内不同测量尺度下的估算效果。第1列是采集的单目建筑图像;第2列是YOLOv3参照目标物检测结果,其中蓝色框标定的是已知真实尺度的参照物;第3列是对应的深度估计图,有深度估计图转化可得到深度估计矩阵,从而知道像素点对应的相对深度值,得到相应的空间坐标;第4列是由尺度估算公式得到的建筑尺度估算值。表3为同场景内不同测量尺度下的整体误差。A、B、C为单目图像中三个不同的建筑物,D、E为单目图像中两个不同的参照物砖块,其中A为建筑右起第一个门,B为建筑右起第二个C为建筑总长,D、E为建筑表面的不同砖块。实验表明修正后的尺度估算值离实际尺度的偏差较小。

表2 相同场景内不同测量尺度的估算

表3 同场景内的整体误差
表4比较了在不同尺度的不同场景尺度估算的效果,表5显示了在不同尺度下的建筑物估算误差,结果显示在0-5m和5-10m的尺度下估算误差较小,20m以上的大尺度估算误差较大,由此可见算法1对于20m以下具有较好的鲁棒性,对于超大尺度的估算则有待优化。

表4 不同尺度下建筑物估算
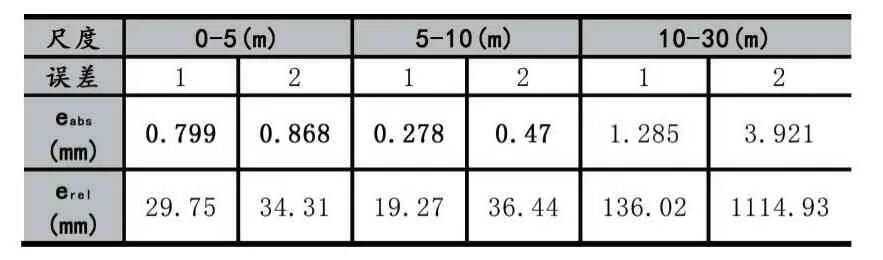
表5 不同尺度下估算误差
表6中显示了本文建筑物尺度估算与其他方法的比较结果,其中TBMDE出自文献[13],FCRN出自文献[26],表明了本文算法的建筑物尺度估算误差较小,性能最好。
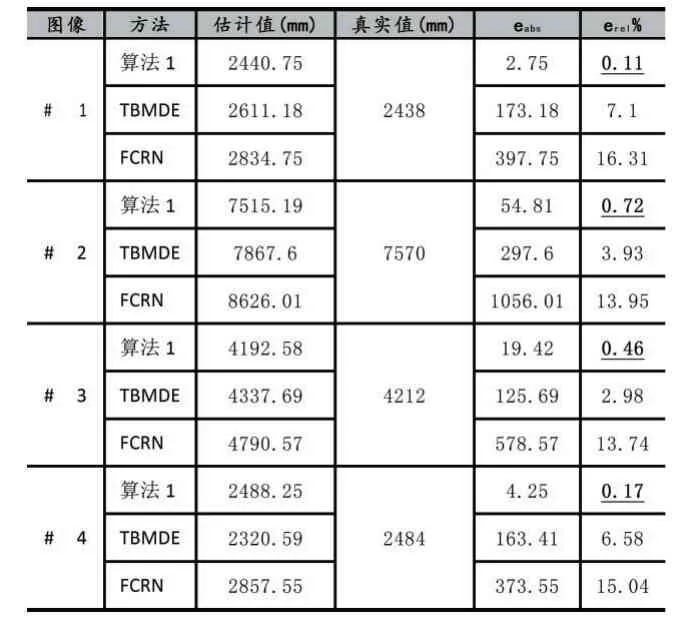
表6 不同方法建筑尺度的误差
5 结语
单目图像尺度估算对于场景理解,建筑物重建和复原有重要研究价值。由于受限于已有深度估计算法对场景尺度分析不足,引入了参照物已知尺度的先验信息,得到一个尺度修正系数,最后得到图像中物体的真实尺度估算。对于在相同相机参数,相似环境下拍摄的多幅图像,从一张存在已知尺度参照物的图像中提取修正参数,也可以适用于其他不存在已知尺度参照物的图像中。实验结果表明,提出的算法1能有效地估算建筑物的真实尺度。
但算法也存在一些局限。如果建筑物出现空洞较大或者植物、车子、大型景观石等物体大面积遮挡建筑物时,会造成深度估计严重偏差,则无法准确地估计出建筑物的真实尺度。早期胶片相机拍摄的照片是用近似计算的方法得到焦距和像素信息也会对计算准确性带来一定的影响。算法对于中小尺度的建筑物尺度估算具有较好的鲁棒性,尺度估算误差小;但对于尺度很大超过20m的建筑物则会出现误差较大的情况。
本文下一步工作将继续研究参照物估算尺度和真实尺度之间更复杂的关系,优化焦距和像素信息的计算,改进修正系数的设定,得到更准确的物体尺度估算。
附录
尺度估算公式的推导过程。由公式(5)可知,
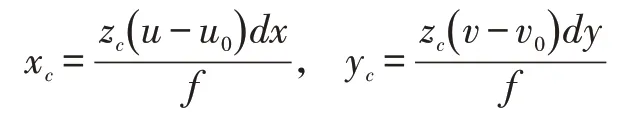
令:
由ztrue=kzc
假设p和q是修正前两点的相机坐标,dpq为修正前两点间尺度值,ptrue和qtrue则是修正后的相机坐标,则这两点间修正后p,q的真实尺度为:

猜你喜欢
社会科学战线(2022年7期)2022-08-26
保健与生活(2021年11期)2021-06-10
现代电子技术(2018年18期)2018-09-12
软件导刊(2018年4期)2018-05-15
电脑知识与技术(2018年35期)2018-02-27
科学家(2017年12期)2017-08-10
科学大众·小诺贝尔(2016年3期)2016-03-04
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
初中生世界·八年级物理版(2013年1期)2013-03-25
