
一种基于刷卡数据判断食堂拥挤状态的方法
2021-06-01 12:57
数字技术与应用 2021年4期
(长安大学教育技术与网络中心,陕西西安 710064)
0 引言
高校作为人员密集场所,在疫情期间需要采取措施避免师生大规模聚集,如图书馆、教室等区域可以通过限制性手段进行管控。然而,食堂作为师生每日必经之地,排队就餐问题比较突出,且具有就餐时间固定的特点,不能简单的人为限制,师生需要借助某种手段,提前判断人多区域和用餐高峰时间。
目前利用数据预测的方法包括例如马尔科夫链[1],大数据[2]等,这些方法可以实现对人流量及拥挤状态的预测,但这些方法需要经过前期数据采集,算法反复调优,且后端构建都非常繁琐。针对上述问题,本文从结果导向出发。开发拥挤模型的目的是提醒师生错峰就餐,而师生对当前食堂有多少人并不感兴趣,即仅需要获得“非常拥挤”“轻微拥挤”“不拥挤”三种信息就可以实现本文的目的。
通过分析,本文选择校园卡刷卡数据作为基础,开发“动态时间窗口”拥挤模型将数据可视化,通过前端“柱形图+颜色”进行展示并集成至微信公众号方便师生查看。
1 提出的方法
本文提出方法的核心是校园卡刷卡数据,由于学校食堂所有消费必须使用校园卡,无其他支付方式,因此刷卡数据与就餐人数成正相关。
假设每个人平均吃饭时长15分钟(窗口时间),可以理解为刷卡后的15分钟要留在食堂,因此15分钟内的累计刷卡数为当前食堂所有就餐人数。就餐人数与食堂最大容纳人数的比值即为“拥挤指数”,其值大于等于零,若“拥挤指数”大于给定的阈值则判断当前食堂拥挤。该模型比较简单,没有考虑排队人数和刷卡后直接离开的情况,但已经可以动态反应食堂的拥挤状态。
在上述模型的基础上我们进行改进,由于每个人的吃饭时长(窗口时间)在不同就餐时间、不同拥挤状态、不同食堂都是不一致的,因此需要设计成动态时间窗口,其大小根据食堂实际情况进行调整。设定动态时间窗口为n(初始值n=15),则当前食堂人数为Zn,即统计当前时刻到前n=15分钟内的刷卡数据,食堂最大容纳人数Max,判断拥挤的阈值为a,b,a>b(初始值a=0.9,b=0.7),综上“拥挤指数”模型如表1所示,模型示例:

表1 “拥挤指数”模型Tab.1 Model of ‘Crowding Index’
(1)当Zn/Max<=0.7,n=15,即当前食堂人数与最大可容纳人数比值小于0.7,食堂不拥挤,窗口时间设置为15分钟。
(2)当0.7 (3)当Zn/Max>=0.9,n=19,即当前食堂人数与最大可容纳人数比值大于0.9,食堂非常拥挤,出现拥挤排队且找不到座位的情况,窗口时间增加为19分钟。 由于学校食堂较多,每个食堂硬件设施(座位数、面积、楼层、地理位置)、餐饮模式(现炒现做、直接打饭)、人流量等因素都不一样,因此不能使用同一种参数,需要现场多次观察手动调参,参数包括时间窗口n1,n2,n3和阈值a,b,而食堂最大容纳人数Max一般不会变动。食堂调参示例: (1)食堂一:炒菜窗口较多,需要现做,易出现排队等待的情况,因此增加初始窗口时间n1,n2和n3也随之增加。 (2)食堂二:位于一层且靠近教学楼,易出现人流量猛增的情况,因此降低阈值a和b。 (3)食堂三:人流量较小,不易出现拥挤情况,使用标准参数即可。 本文提出的方法涉及多个参数,需要根据食堂实际情况手动调参,因此开发后端调参界面。如图1 所示,包括食堂区域和楼层,以及上一节提到的6种参数,所有参数都给出了默认值,管理员可以根据食堂实际请款进行调整,按照使用经验,管理员可在用餐时作简单观察,每个食堂观察3~4 次即可适配。当前食堂人数Z n 伪代码(SQL)[3-6]示例: 图1 系统后台Fig.1 System back-end select distinct 编号 from 刷卡数据 where (交易日期 between sysdate -interval '15' MINUTE and sysdate) and (JYDD like '餐厅')。 前端采用响应式设计,方便师生在不同终端设备上查看。柱形图表示“拥挤指数”,绿色表示不拥挤,黄色表示轻微拥挤,红色表示非常拥挤。页面每20 秒更新一次数据,倒计时显示。提供手动点击刷新按钮和切换校区按钮,前端界面如图2所示。 图2 前端拥挤指数界面Fig.2 System front-end 本文提出了一种基于校园卡刷卡数据判断食堂拥挤状态的方法,该算法模型简单高效,前后端易于部署,且建设成本较低。基于刷卡数据的“拥挤指数”实现师生错峰就餐的预期,既有助于疫情防控,又提高了用餐效率。除了校园卡刷卡数据,高校应用系统包含更多有价值的数据,需要通过处理将其可视化,从而为学校资源合理分配、校园规划建设、师生学习工作提供有意义的参考。2 开发
2.1 后端模型
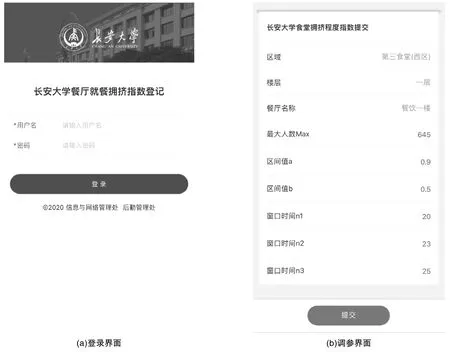
2.2 前端界面

3 结语
猜你喜欢
潍坊学院学报(2020年6期)2020-11-22
文理导航(2018年9期)2018-08-16
现代经济信息(2016年34期)2017-08-12
中国乡镇企业会计(2014年12期)2014-07-20
今日中学生(初二版)(2013年11期)2014-01-23
意林(2007年6期)2007-05-14
