
一种基于污染风险的地下水监测井网多目标优化方法
2021-06-09 10:04林斯杰邓泽政刘明柱
安全与环境工程 2021年3期
闫 聪,林斯杰,邓泽政,杨 庆,刘明柱*
(1.中国地质大学(北京)水资源与环境学院,北京 100083;2.南方科技大学环境科学与工程学院,广东 深圳 518055;3.北京市地质矿产勘察院,北京 100048)
地下水是维系地下水依赖型生态系统生态服务功能的核心资源,在干旱-半干旱地区显著影响着植被动态和土壤水平衡。然而伴随着经济社会的不断发展,很多地区地下水受到了严重污染,使地下水生态服务功能受到了不同程度的影响。地下水监测可为管理和保障地下水生态安全提供必要的信息。地下水污染监测井的科学布设是地下水保护工作的基础,也是国内外地下水监测领域的共性难题。合理的地下水污染监测井布设是获取有用的地下水污染信息的前提。合理地布设地下水污染监测井,可以大大降低相关监测成本,提高获取信息的可靠性。开展地下水污染监测井网布设的优化研究,目的在于以最小的监测成本获取空间和时间上最具有代表性的地下水水质信息。目前综合考虑不确定性和定性风险评价的多目标优化技术被越来越多的学者采用,原因在于该技术同时考虑了多个目标,且优化方案是根据相互竞争的目标函数优先地位来排序的。多目标优化方法已逐步成为应用最广泛的地下水污染监测井网布设优化技术。
区域地下水污染监测井网布设优化方法主要包括水文地质分析法和数理统计法。作为一种定性方法,水文地质分析法是地下水污染监测井网布设优化的基础方法,该方法主要根据水文地质条件、人为活动、地下水价值等因素对地下水污染监测区域进行动态叠加和划分,最终确定地下水污染监测井位置的合理性。常用的水文地质分析法有地下水动态类型编图法和地下水污染风险编图法,其中地下水污染风险编图法主要适用于地下水污染监测井网布设的优化研究。而数理统计法作为定量方法,主要包括地统计法、主成分分析法、遗传算法、模拟退火算法等,如Tamer等以用最少数量的监测井提供足够空间覆盖的地下水质量信息为目标,采用遗传算法识别现有地下水污染监测井网络中的冗余井,获取了最佳的地下水污染监测井网布设方案。其中,地统计法较为常用,但多适用于针对地下水水位监测井网的单目标优化;主成分分析通过对多个指标的降维,可实现地下水污染监测井布设的优化,但该方法可能无法获取最优解;遗传算法适用于地下水水质监测井网的优化,通过寻求最优解可获取最佳的地下水污染监测井网,但该方法计算耗时大;模拟退火算法同样适用于地下水污染监测井网的多目标优化,且该方法计算效率高,但目前多应用于地下水水位监测井网的多目标优化。
鉴于此,本文在前人模拟退火算法的基础上,利用随机森林方法筛选出对地下水质量演化指示性最强的监测指标,并结合水文地质分析法,考虑地下水污染风险性,以监测成本最低、精度最高和不确定性最小为目标函数,建立了区域地下水污染监测井网多目标优化模型,最后通过案例应用,以验证该方法的有效性。
1 研究方法
1.1 区域地下水污染监测井网多目标优化模型构建
对于人类生活聚集地,尤其是城市,需对地下水整体状况进行长期监测,以便掌握地下水质量的时空变化过程,为地下水管理及维护地下水生态安全提供基础信息,因此需建立以监测成本最低、监测精度最高和不确定性最小为目标函数的区域地下水污染监测井网多目标优化模型。其中,监测成本可用地下水污染监测井的数量表示;监测精度可用地下水污染监测井网的数据丢失量表示;不确定性可简化为地下水污染监测井的均匀分布。该多目标优化模型目标函数的数学表达式如下:
minF
=minN
(1)
minF
=min(CORR+DIST)(2)
minF
=minMSSD(3)
式中:F
表示地下水污染监测井的数量;F
表示地下水污染监测井网的数据分布;F
表示不确定性;N
表示监测井的数量;CORR表示监测数据的相关性分布函数,DIST表示监测数据的边际分布函数,CORR和DIST函数值越小,说明优化前后地下水污染监测井网的相关性分布越接近;MSSD表示地下水污染监测井距离均值,其值越小,说明地下水污染监测井分布越均匀,地下水污染监测井网的不确定性越低。
(
4)

(
5)
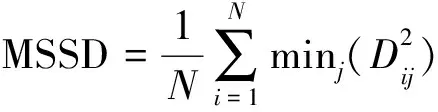
(
6)

n
个目标函数,在每个目标函数的解空间中寻求最优解。为了求得最优解S
,
本文采用加权求和法(Weighted Sum Method),该方法通过自定义每个目标函数的权重,将单个目标函数(Objection Function,OF)聚合为效用函数U
(Utility Function),即新的目标函数(OF):
(
7)

然而,解决多目标优化问题时,每个目标函数具有不同的数量级和单位,在加权求和过程中,数量级较大的目标函数往往占有主导性,而遮盖了其他目标函数,即权重的设定可能无法真实体现出目标函数的重要程度,因此需要采用函数转换方法对每个目标函数进行标准化处理,具体处理方法如下:

(
8)


1.2 区域地下水水质监测指示性指标筛选方法
地下水水质监测指标数量多、信息量大且存在冗余,而地下水污染监测井网优化模型结果的好坏往往在很大程度上取决于监测数据的质量。为了识别冗余信息,提高监测数据的质量,减少冗余监测指标对优化模型结果的影响,本文基于地下水质量评价结果,采用随机森林算法识别对地下水水质具有重要指示性的监测指标,并将其作为后续地下水污染监测井网优化的指示性指标。
随机森林(Random Forest,RF)算法是由Breiman等提出的,该方法结合了Bagging算法和随机子空间算法,是一种分类预测算法,也是一种组成式的监督学习方法。RF算法在识别地下水水质监测指示性指标的过程中,具有以下优势:
(1) 能够充分利用地下水水质多年监测数据,通过大量长时间序列的数据建立预测模型。
(2) 可以较好地处理地下水水质监测数据缺失问题。
(3) 对于基于数值变量和因子变量所建立的地下水水质监测指示性指标重要性识别模型具有较高的准确性。
为了度量地下水水质监测指标的重要性,RF算法使用特征变量重要性进行度量,度量参数有OBB平均下降精度(Mean Decrease Accuracy,MDA)和基尼指数(Gini)。
MDA相当于均方误差,是用于衡量某一指标的值取为随机数时,RF算法预测准确性的降低程度,其值越大,表明指标的相对重要性越高。MDA的计算公式如下:

(
9)

基尼指数(Gini)为数据集中随机指标被分错的概率,用来表示节点的纯度,基尼指数越大,表明指标的相对重要性越高。基尼指数的计算公式如下:

(
10)
式中:p
表示数据集D
中第k
个指标所占的比例;y
表示指标总数;Gini(D
)表示数据集中随机指标被分错的概率。1.3 区域地下水污染监测井网多目标优化模型求解方法
模拟退火(Simulated Annealing,SA)算法,也称蒙特卡洛退火、统计冷却或随机松弛算法, Kirkpatrick等将该方法引入组合优化领域,旨在有效地解决最优解问题。SA算法是一种源于统计物理学的组合优化算法,已经广泛应用于地统计模拟和优化空间采样。
SA算法源于金属原子退火,即金属原子快速加热,然后缓慢冷却的过程。冷却(退火)过程中,金属内部原子发生改变,从而形成具有更低能量状态的金属原子网络。在地下水污染监测井网多目标优化中,SA算法中的每个金属原子对应着地下水监测井网中的单个监测井,整个系统的能量状态代表监测井网优化过程中的目标函数。SA算法在求解地下水污染监测井网多目标优化模型中,具有如下明显的优势:
(1) 针对大量的地下水水质监测数据,能够进行高效率的求解计算。
(2) 灵活性高,可以突破局部最优解,而到达全局最优解,即能够对区域地下水监测井网进行整体优化,而非局部优化。
(3) 对于多目标优化问题,该方法允许用户自定义目标函数。
SA算法的核心是需要求解优化的目标函数(金属原子内能)。针对地下水污染监测井网多目标优化问题,SA算法求解优化目标函数的步骤如下:
第一步,需通过对S
的随机扰动产生新的目标函数φ(S
+1)
,从而形成多目标优化问题的解空间S
。对于S
+1新解是否接受,则依赖于概率接受准则,即Metropolis算法。当φ(S
+1)
≤φ(S
)
时,则接受新解(S
+1)
;当φ(S
+1)>
φ(S
)
时,则需要根据Metropolis算法判断是否接受新解,见下式:
(
11)
式中:c
为退火温度;P
为接受概率。对于复杂的多目标函数,局部最优点可能与全局最优点(最佳监测井网)存在很大的差异,这种情况下搜索过程会停止在局部最优点,而通过Metropolis算法,使SA算法具有从局部最优点逃逸而获得全局最优点的能力。
第二步,在求解最佳监测井网时,需要设置相关参数,SA算法涉及的一组控制参数称为退火时间表,其中重要的控制参数有初始温度C
、初始接受概率P
、温度降低因子(即退火速率)α
等。退火速率采用最简单也是最常用的退火方式,即指数式降温,其关系式如下:C
+1=αC
(k=
1,
2,
…,N)
(
12)
式中:k
表示马尔可夫链(Markov chain);C
表示第k
个马尔可夫链的温度;C
+1表示第k
+1个马尔可夫链的温度;α
为退火速率,取值范围为0.8~0.99,一般取0.95。第三步,在模拟退火过程中,目标函数的迭代过程也需要终止条件,SA算法的退火终止条件有3个:
(1) 终止温度:若干次迭代后,若C
+1达到终止温度(设定的阈值),则迭代过程终止。(2) 目标函数:
迭代过程中,目标函数在N
次迭代中都保持不变或者变化很小时,迭代终止。(3) 接受概率:当新解不优于当前解,通过Metropolis算法计算所得的概率低于接受概率,迭代终止。
SA算法计算过程简单,通用性和鲁棒性强,可用于求解复杂的非线性优化问题。相比于其他算法,作为交互式方法的SA算法的计算量更少,尽管它不能保证找到最优解,但是可以确保找到近似最优解。
2 案例应用研究
2.1 研究区概况
本文选择北京市平谷盆地(116°55′~117°24′ E,40°01′~40°22′ N)为研究区。平谷盆地位于北京市东北部,西距北京市区70 km,东距天津市区90 km,面积约为340 km(见图1)。区内主要有4个冲洪积扇,地势东北高、西南低,按地貌形态分为侵蚀地貌、坡洪积地貌、冲洪积地貌,地层岩性主要有第四系砂砾岩、砂岩和基岩。平谷盆地含水层主要有4层,研究区中部和西北部有两个地下水源地,水质良好。平谷盆地潜水含水层共布设了地下水污染监测井32口,其中污染源监测井19口(见图1中灰色圆点),主要分布在研究区西北部、北部和中部;区域地下水污染监测井13口(见图1中黑色圆点),较均匀地分布在平谷盆地内。

图1 研究区现有地下水污染监测井网分布示意图Fig.1 Overview of current groundwater pollution monitoring well network in the study area
2.2 地下水水质监测指示性指标筛选
地下水水质监测指示性指标筛选是地下水污染监测井网优化的关键,参与优化的指标不同,则地下水污染监测井网的优化结果也不同。为了评估地下水水质监测指示性指标筛选的合理性,本文对比分析了对地下水质量综合评价法和随机森林法的指标筛选结果。
2.2.1 地下水质量综合评价法的指标筛选结果


图2 研究区地下水质量评价指标的超标率Fig.2 Standard-exceeding rate of indicators for groundwater quality assessment
2.2.2 随机森林算法的指标筛选结果
尽管通过地下水质量综合评价法能够识别出研究区地下水水质监测指示性指标,但体现不出其他常规指标的重要性。本文基于地下水质量综合评价法的评估结果,采用随机森林算法构建了区域地下水水质监测指示性指标重要性识别模型,以每个监测井的地下水水质评价等级作为预测变量,17个地下水水质监测指标作为样本变量,共生成500棵传统决策树,最终得到每个监测指标的相对重要性排序结果,见图3。

图3 研究区地下水水质指标的相对重要性排序Fig.3 Ranking of relative importance of monitoring indicators of groundwater quality

2.3 地下水污染风险评价结果
地下水污染风险性越高,地下水被污染的概率就越大,监测井存在的必要性越大,监测井的密度/数量可适当提高/增加;相反,地下水污染风险性越低,地下水被污染的概率越小,监测井的密度/数量可适当降低/减少。
本文采用矩阵叠加法对研究区地下水污染风险性进行了评价,其评价结果见图4。
由图4可见,研究区王都庄、中桥水源地地下水污染风险集中在低和中等等级,冲洪积扇扇缘地下水污染风险等级为高、很高。

图4 研究区地下水污染风险评价分区图Fig.4 Zoning map of groundwater pollution risk assessment in the study area
2.4 区域地下水污染监测井网优化结果
2.4.1 多目标优化模型参数设置
模拟退火算法在退火过程中设置了相应的退火时间表,见表1。

表1 退火时间表Table 1 Parameters annealing schedule
加权求和法在聚合单个目标函数形成新的目标函数(OF)的过程中,需设置每个目标函数的权重,用以表示单个目标函数间的相对重要程度。则目标函数OF可表示为:OF=1/2 CORR+1/3 DIST+1/6 MSSD,其中CORR、DIST和MSSD的权重分别为1/2、1/3和1/6。
2.4.2 冗余监测井识别结果
在识别冗余监测井的过程中,首先需要确定冗余监测井的数量,根据目标函数值与监测井数量之间的关系曲线(见图5),可得出不同监测井数量最优的目标函数值。
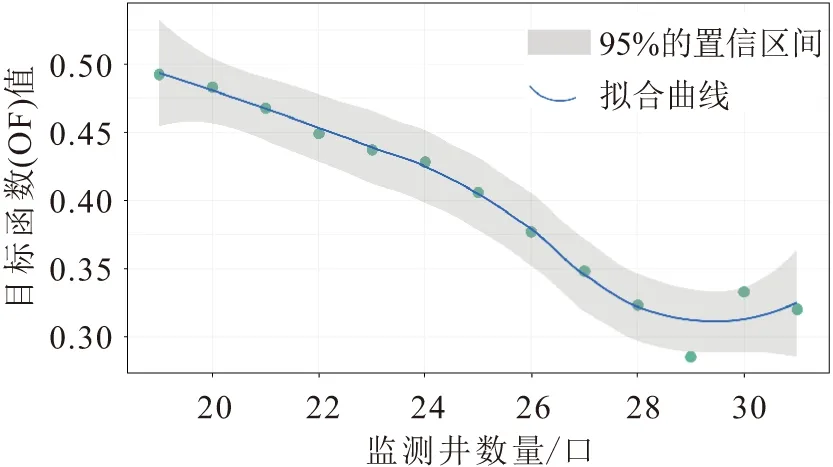
图5 目标函数(OF)值与监测井数量的关系曲线Fig.5 Change curve of objective function with number of monitoring wells
由图5可见,整体上目标函数(OF)值随监测井数量的增加呈递减趋势,当监测井数量为29口时,OF值达到最低值,即CORR、DIST、MSSD多目标组合问题达到最优解;当监测井数量大于29口,OF值随监测井数量的增加由递减变为递增趋势,因此最优的监测井数量为29口。
通过上述方法求解多目标优化模型,优化过程中每个目标函数随迭代次数的增加而递减(见图6),当迭代次数为3 000次时,目标函数CORR、DIST、MSSD以及OF趋于稳定,其中OF值为0.375。

图6 目标函数收敛图Fig.6 Convergence of the objective function
本文识别出的研究区冗余监测井位置,见图7。
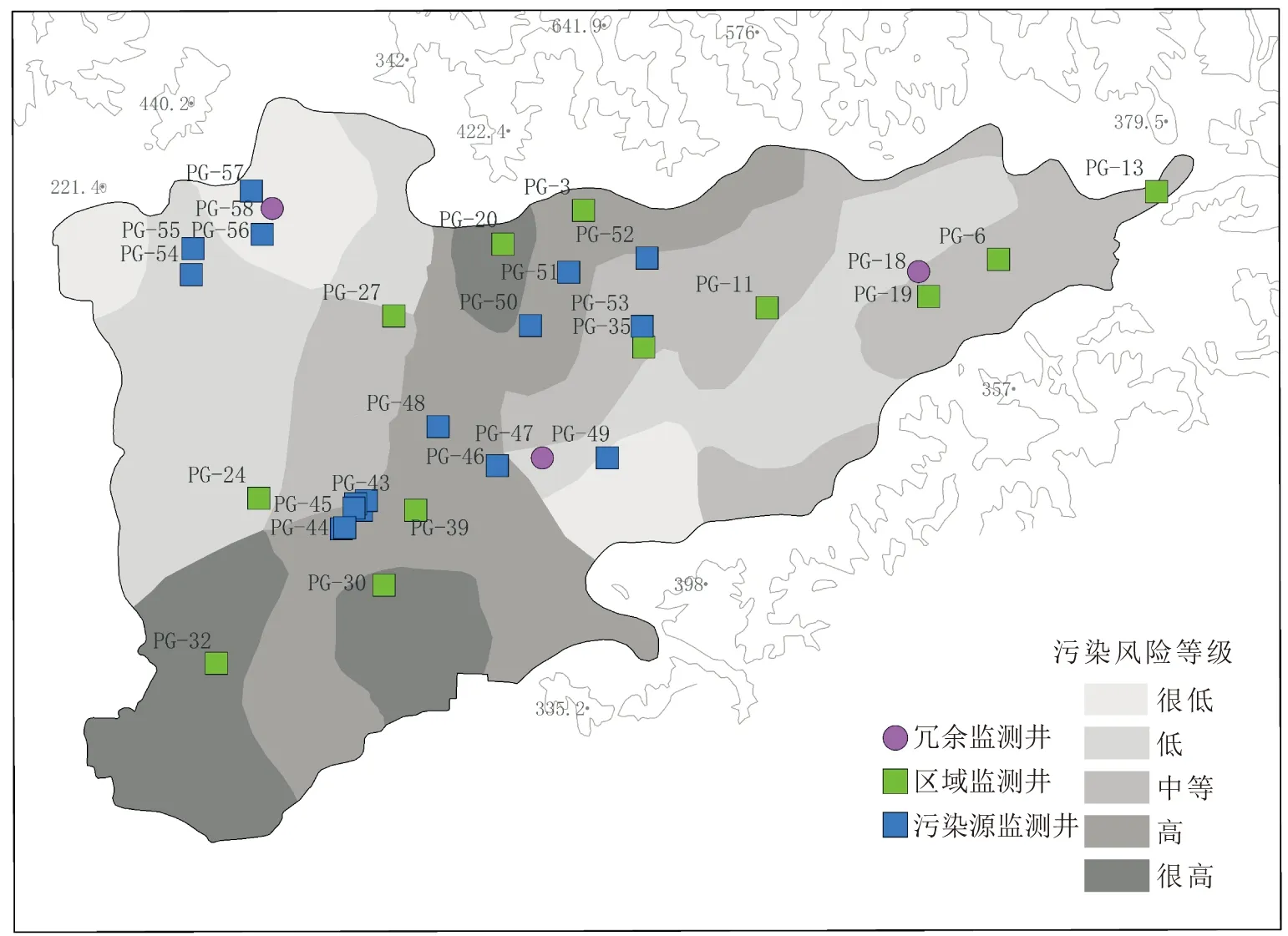
图7 研究区冗余监测井的识别结果Fig.7 Identification of redundant monitoring wells of the study area
由图7可见,研究区地下水很高污染风险区有3个区域,每个区域都至少存在1口监测井,分别为PG-20、PG-30、PG-32;研究区3口冗余监测井分别为PG-18、PG-47、PG-58(见图7中紫色圆圈),其中PG-18为区域监测井,地下水污染风险等级为低,PG-47和PG-58为污染源监测井,地下水污染风险等级为低和很低,因此3口冗余监测井都位于地下水低污染风险区。

表2 研究区冗余监测井的N-N浓度估计精度Table 2 Estimation accuracy test of N-N concentrationin redutant monitoring wells
2.4.3 新增监测井预设方案
研究区内某些地区缺乏地下水监测井,如马昌营、夏各庄等地区,造成区域内地下水信息不确定性较大,因此需要在这些区域内增加新的监测井。但新的监测井缺乏地理信息和监测信息,并且含水层的边界不规则且变化幅度大,而MSSD函数可以较好地解决这一问题,该函数可降低地下水污染监测井网的不确定性,形成分布更为均匀的地下水污染监测井网。在缺乏地理信息的情况下,首先通过GIS随机在区域内生成300个监测点,以随机监测点作为新增监测井的候选点;然后通过模拟退火算法建立目标函数MSSD的地下水污染监测井网优化模型,其迭代计算过程见图8。

图8 MSSD目标函数的迭代计算过程Fig.8 MSSD function iterative
地下水污染监测井网的监测精度随监测井数量的增加而提高,监测成本也随之增加。本文为了提高地下水污染的监测精度,在研究区内新增了5口监测井,研究区地下水污染监测井网优化后的点位分布见图9。

图9 研究区地下水污染监测井网优化后的点位分布图Fig.9 New scheme after optimizing for monitoring well network
由图9可见,地下水污染监测井点均匀分布在平谷盆地内,其中地下水污染很高风险区内新增1口监测井,地下水污染高风险区内新增2口监测井。
3 结 论
(1) 针对地下水水质监测指标信息量大而存在冗余的问题,采用随机森林算法筛选出对地下水质量具有重要指示性的监测指标。
(2) 结合水文地质分析法和模拟退火算法,基于地下水水质监测指示性指标的识别结果,提出了以监测成本最低、监测精度最高、不确定性最小为目标函数的多目标组合优化模型,为识别冗余监测井和新增监测井提供参考,实现了以最低成本的地下水污染监测井网获取最多地下水信息的目的。
(3) 平谷盆地案例应用研究表明:基于设有32口井的初始监测井网,运用模拟退火算法求解多目标优化模型,得到每个目标函数和效用函数的Pareto最优解,并综合考虑研究区地下水污染风险性的评价结果,得到优化后研究区地下水污染监测井数量为29口,识别出冗余监测井3口,再通过普通克里金法分析了3口冗余监测井的合理性,最终保留PG-47监测井,去除PG-18和PG-58监测井。此外,针对研究区内部分区域监测井不足的情况,提出了新增监测井的预设方案。
猜你喜欢
航天返回与遥感(2022年4期)2022-09-03
中老年保健(2022年6期)2022-08-19
皮革制作与环保科技(2021年22期)2022-01-18
今日农业(2021年17期)2021-11-26
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
儿童故事画报·发现号趣味百科(2015年10期)2016-01-20
新高考·高二数学(2015年7期)2015-10-22
世界文学评论(2014年2期)2014-04-12
祝您健康(1989年5期)1989-01-06
