
基于深度强化学习的无人战车自主行为决策*
2021-06-11 00:52武富春王海龙
火力与指挥控制 2021年4期
张 耀,武富春,王 明,段 宏,张 昭,王海龙
(北方自动控制技术研究所,太原 030006)
0 引言
随着科技的不断进步,战争形态将发生深刻的变革。在军事智能化的趋势之下,无人化作战将成为基本形态[1]。无人战车是未来陆军实施地面突击作战的主要装备,其自主系统主要由感知、决策和控制等子系统组成。其中,自主行为决策模块,是无人战车在复杂陆战场环境中对敌目标实施快速、精确、有效打击的核心[2]。
在传统装甲装备作战过程中,完成作战任务主要靠驾驶员、车长、炮长分工协作,存在目标搜索速度慢,操作随机性大,决策时间长的问题,同时作战效能受乘员心理素质、生理状况以及战场环境的影响较大[3]。随着人工智能的不断发展,由于机器对海量信息处理能力强,反应速度快,面对动态战场环境具有独特的优势,逐渐替代人类乘员成为可能,推动无人战车的出现。无人战车按照系统控制方式可以分为遥操作控制、半自主控制和全自主控制[4]。随着无人战车智能化水平的提高,全自主控制成为其未来发展的必然方向,自主行为决策技术必将成为主要的技术推动力。
目前,对于无人战车自主行为决策的研究还处于起步阶段。相比之下,无人战斗机自主空战决策[5]学术研究成果丰硕,虽然应用场景不同,但是其行为决策方法有很大参考价值,主要包括基于规则的方法以及基于学习的方法两大类。基于规则的行为决策方法根据大量数据,以及专家知识构建动作规则库,针对不同态势制定对应的行为决策;基于学习的方法则以强化学习方法为代表,文献[6]采用强化学习中的Actor-Critic 构架,通过神经网络学习,解决连续状态空间上的空战决策问题。但是该方法存在收敛速度慢、算力要求高的缺点。
因此,本文提出一种深度强化学习结合行为树的方法解决无人战车自主行为决策问题,利用行为树的逻辑规则与先验知识降低强化学习的问题复杂度,保证算法稳定收敛,同时使行为决策模块具有学习能力。本文从未来陆战场单车的实际作战需求出发,研究无人战车自主行为决策技术。分析了无人战车自主行为决策问题;建立了自主行为决策模型;提出一种深度强化学习结合行为树的自主行为决策方法;最后,针对典型作战场景,利用无人战车对战模拟仿真环境,验证所提出的自主行为决策方法的有效性。
1 无人战车自主行为决策问题分析
无人战车是一种能感知环境并与环境交互,具有自主地面机动能力、自主精确火力打击能力的智能化装甲装备。作为无人战车“大脑”的行为决策模块,直接体现了无人战车的自主水平,对于战车快速、精确、有效地打击敌方起着决定性作用。根据无人战车执行作战的任务流程分析,无人战车采用类人自主行为决策结构,如图1 所示。无人战车自主行为决策包括自主机动决策与自主火力决策。
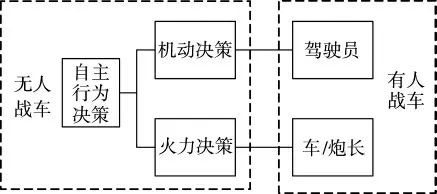
图1 无人战车类人自主行为决策
机动决策是自主行为决策的基础。无人战车的机动决策是指根据实时感知的环境信息、自身行驶状态,对随时可能出现的敌方行为作出避险或迎敌反应,无人战车自主产生合理驾驶策略的过程。自主机动决策模块对应于传统驾驶员的决策行为,连接环境感知模块和车辆底盘运动控制模块,共同实现自主行驶。主要包括自适应巡航,避障避险,通过特定区域等内容,需要不断地适应战场环境变化,调整自己的机动速度和方向,从而能够快速安全驶向目标区域。从战术层面考虑,机动能够使我方占据有利地形,无论攻守都处于有利态势。
火力决策是自主行为决策的核心。自主火力决策模块对应于传统车长和炮长的决策行为,完成目标搜索、目标瞄准、火炮控制和目标打击等使命,直接决定了无人战车整体的战斗力。现有的武器火控系统在人的操作下能够实现目标探测、火控解算和控制武器射击等使命。无人战车则需要自主火力决策与武器火控系统相配合,利用快速处理信息的能力以及学习能力,实现自主目标瞄准和自主目标打击决策,以提高首发命中率和射击反应时间。
由于战场环境复杂,动态时变,特别是对抗场景下,敌方行为具有不确定性,无人战车自主行为决策模块需要根据环境态势选择动作,通过作出多步决策,实现作战任务。其所面临的问题称为序贯决策优化问题(Sequential Decision Problem)。基于规则构建决策模型,难以适应这种动态不确定性;强化学习方法可以通过对策略的迭代,找到最优策略,对于突发事件也有较好的响应,故采用强化学习方法解决自主行为决策问题。
2 基于马尔可夫决策过程的自主行为决策模型
2.1 马尔可夫决策过程
强化学习方法是一种基于马尔可夫决策过程(Markov Decision Process,MDP)的序贯决策方法,其核心思想是交互试错[7]。马尔可夫决策过程可由元组
无人战车的自主行为决策过程可建模为一个基于MDP 的序贯决策问题。在作战过程中,无人战车需要不断观察环境态势,获取状态s,并依据策略μ(a|s)选择动作a,通过多步决策,最终完成火力打击任务。在与战场环境的交互中,无人战车通过交互试错最大化累积奖励r,使其自主行为策略收敛至最优,如图2 所示。

图2 强化学习原理图
2.2 状态空间与动作空间
针对无人战车自主机动决策问题,本文选取我方战车位置、战车速度、机动目标位置、碰撞检测等参数描述状态空间Sm,如表1 所示。动作空间Am由方向、油门、刹车的连续控制量组成,如表2 所示。

表1 自主机动决策状态输入

表2 自主机动决策动作输出
针对无人战车自主火力问题,本文选取目标距离、战车方位角、目标毁伤程度、我方战车毁伤程度等参数描述状态空间Sf,如表3 所示。动作空间Af由火炮高低角、方位角和是否开火描述,如表4 所示。
2.3 奖励函数与约束条件
奖励函数是强化学习算法评估当前动作好坏的直接指标,也是指导策略迭代优化方向的关键因素。奖励函数的设计,直接影响到算法的学习效率和最终策略。

表3 自主火力决策状态输入

表4 自主火力决策动作输出

3 深度强化学习的自主行为决策方法
3.1 深度强化学习
深度强化学习算法有众多分支,本文采用DDPG(Deep Deterministic Policy Gradient)算法,针对连续的状态空间和动作空间,适用于无人战车的自主机动控制、火力打击等连续变量控制问题。DDPG算法采用了双神经网络的Actor-Critic 框架[8],其算法框架如下页图3 所示。

图3 DDPG 算法框架图
首先,Q 函数(也称为动作值函数)定义为针对特定动作at的累积奖励期望:



对于Actor 网络,算法同样利用卷积网络来近似策略函数,故Actor 网络又称为策略网络,其输入为当前状态s,输出为动作a。而策略网络的参数更新主要是朝着值函数网络输出增大的方向进行,梯度可以近似转化计算。
为了加速DDPG 算法稳定收敛,本文采用经验回放机制[9],先将交互数据存入缓存区中,再均匀随机采样,打破数据之间的关联,使策略更快地稳定收敛。通过引入软更新技巧,对Actor 和Critic 分别设置在线网络和目标网络,实现目标网络参数的平稳更新。公式如下:


3.2 深度强化学习结合行为树自主行为决策方法
虽然深度强化学习方法具备上述优点,但在解决无人战车自主行为决策问题时面临着收敛速度慢、奖励函数设计难度高、对训练数据和计算能力要求高等缺点,故考虑将基于规则的方法行为树与深度强化学习方法相结合,划分任务空间,提高鲁棒性。
行为树是一种遵循一定遍历顺序的决策模型,具有逻辑清晰、模块化、可扩展性好等特点[10]。如图4 所示即为行为树的遍历方式。每个控制周期开始时,都将行为树的根节点作为起始点,自顶向下、从左到右遍历行为树的各节点。行为树节点可分为:行为节点、选择节点、顺序节点、并行节点。其中,行为节点是行为树中的叶节点,负责输出最终的行为;选择节点会在其子节点中选择一个遍历;串行节点按照从左到右的顺序遍历其全部子节点;并行节点每次同时遍历所有子节点。

图4 行为树遍历方法
本文提出了深度强化学习结合行为树的无人战车行为决策方法,实现基于规则方法和基于学习方法的优势互补。该决策方法将DDPG 决策模块作为行为树的行为节点,利用行为树模型的逻辑规则和先验知识将任务划分为多个子任务,模块化地使用强化学习方法,降低状态空间和动作空间的复杂程度,加速策略收敛,降低算力要求;同时,采用DDPG 决策模块,具备一定的泛化能力和学习能力[11]。

图5 深度强化学习结合行为树的决策方法
下页图5 所示即为所提出的无人战车行为决策方法原理图。在每一个行为决策周期中,无人战车首先会更新自身状态,并按照自顶向下、从左到右的顺序遍历整个行为树。1)当运行到机动顺序节点时,无人战车首先从环境中获取态势信息,判断是否到达目标位置。若到达,则停止机动,若未到达,则更新目标位置,顺序执行路径规划和机动决策DDPG 节点,实现全局规划和局部避障功能。2)当运行到火力打击顺序节点时,无人战车首先从环境中获取目标信息并跟踪目标,之后进入机动决策DDPG 节点,对敌方行为作出避险或迎敌动作。最后,判断目标是否被击毁。若尚未被击毁,则进入火力决策DDPG 节点,自主瞄准目标,并控制火炮的高低、方位角以及开火动作。与单独使用强化学习方法完成作战过程中的自主机动和火力决策相比,该方法利用行为树机制将机动任务和火力打击任务解耦,简化状态空间与动作空间的元素组成,降低复杂程度,从而加速算法收敛,提高鲁棒性。
所提出的深度强化学习结合行为树的决策方法算法流程如下:

DDPG 机动决策节点与火力决策节点算法流程如下:

4 仿真验证
4.1 仿真场景搭建
本文基于UE4 仿真环境构建了无人战车作战场景,以单对单无人战车作战想定为例,验证本文提出深度强化学习结合行为树的无人战车自主行为决策方法的有效性。敌方目标战车采用基于规则的行为决策方法,我方无人战车采用本文所提出的深度强化学习结合行为树自主行为决策方法,完成机动和火力打击任务。
首先,以城市作战为背景,搭建模拟仿真环境。设置敌方无人战车围绕基地自主巡逻,在侦察到我方无人战车后能够及时反应,给予火力打击。我方无人战车在基地附近,与敌方无人战车开展对抗,多轮次运行来训练无人战车自主行为决策模块。然后,加快敌方无人战车反应速度,统计10 次敌我对抗测试结果。
实验场景参数设置如表5 所示。

表5 实验参数设置
根据所设置的实验场景,进行仿真验证。如图6所示,我方无人战车训练过程中击中敌方无人战车。

图6 无人战车仿真场景
4.2 仿真结果分析
经过5 000 轮训练,其累计奖励如图7 所示。

图7 累计奖励关于训练轮次变化图
由于探索行为仍在发生,累计奖励出现波动,训练后期,无人战车自主行为决策通过策略优化迭代实现收敛。我方无人战车与加快反应速度后的敌方无人战车进行10 次对抗测试,结果显示,我方无人战车有9 次能够击毁敌方无人战车,由于敌方无人战车采用基于规则的方法,有一定自主能力,说明深度强化学习结合行为树的方法在本场景中优于基于规则的方法,能够有效解决无人战车自主行为决策问题。
5 结论
本文提出一种基于深度强化学习结合行为树的无人战车自主行为决策方法,解决无人战车自主行为决策问题。针对高动态强对抗环境下,无人战车完成作战任务时的序贯决策优化问题,状态空间大,策略难以稳定收敛,应用深度强化学习结合行为树方法,突破无人战车自主行为决策技术,提高无人战车的学习能力和智能化水平。通过仿真实验验证深度强化学习结合行为树的无人战车自主行为决策方法的有效性。下一步研究工作将围绕仿真环境展开,丰富作战动态场景,建立更加完善的测试机制,便于进行算法验证。
猜你喜欢
军事文摘(2022年17期)2022-09-24
小哥白尼(军事科学)(2022年4期)2022-07-08
军事文摘(2022年9期)2022-05-30
考试与评价·高二版(2021年1期)2021-09-10
政工学刊(2021年8期)2021-07-31
房地产导刊(2020年7期)2020-08-24
当代陕西(2019年12期)2019-07-12
汉语世界(The World of Chinese)(2019年1期)2019-03-18
汽车杂志(2018年6期)2018-06-25
数学大王·中高年级(2015年3期)2015-07-31
