
上声变调在语音识别中的实证研究*
2021-06-11 05:39杨静
科学与信息化 2021年15期
杨静
华中师范大学文学院 湖北 武汉 430079
引言
在语流中,音节与音节相连时有些音节的声调发生改变,与单念时调值不同,这种变化称为变调。在众多的变调现象中,上声变调最常见,也最容易出现语音缺陷和语音错误现象(宋扬,2015)。上声连读变调受语言学界广泛关注,主要集中在对变调调值、调类的探讨。
上声调只在单念、词句末尾念全上调值214度。当两个上声相连时,前一个上声是否与阳平为同一个调类,也有学者就此展开争议。赵元任 (1948)认为“要是一个上声字后头跟着另一个上声字, 第一个字就变成阳平”。但有学者指出前一个音节只是近似阳平,应视为直上(安英姬,1981)。三个上声相连时,吴宗济(1985)指出在单双格中,中间字一般变为阳平,首字变为半上;双单格中,首字变为阳平而中间字成中降的过渡调,过渡调的调值为42,末字则维持本调,调值比原先低。
目前对上声变调的研究主要有声学实验与感知实验两种形式,前者采用精确仪器进行测量,后者注重母语者的听辨感知,语音识别既不同于仪器测量,也不同于听辨感知,它是人机交互的重要形式,通过用户输入声音,系统在集合中选择最佳匹配项进行文字输出。本文以科大讯飞公司开发的讯飞输入法为工具,探求上声变调在语音识别中的错误类型与错误成因,并进行适当的对策分析。
1 研究方法与过程
1.1 发音合作人
合作人一名,性别女,21岁,本科学历,普通话等级一乙。
1.2 实验材料
本文的上声字组材料来源于《现代汉语词典》(第七版),选取所有A~H开头的上声字组,其中双音节上声字组共360个,将其按照使用频率、使用范围分为常用字组与生僻字组。三音节上声字组9个。
1.3 过程方法
发音合作人在安静的自然环境中对着手机麦克风使用讯飞输入法进行语音输入,同时利用录音笔进行录音。由于讯飞输入法的输入结果会受到上下文环境的影响,因此在测试时,要求发音合作人以自然语速读出字组,且每个字组都要有4秒的间隔[1]。
2 实验结果与分析
2.1 双音节字组
双音节字组共360个,识别结果完全正确(识别结果与预期结果一致)的有234个,识别结果错误的有126个,其中部分错误(音完全相同但字不同,如管保—管饱)的有90个,完全错误的有36个。由于本文不涉及同音字组,因此排除部分错误字组情况,对36个完全错误字组进行错因的类别整理[2]。
2.1.1 按照错误类型分类。双音节上声字组中识别错误的字组占35%,识别结果完全错误的上声字组占总数的10%。讯飞输入法对上声语流音变的识别结果大致理想,但也存在较为普遍的问题。
对36个完全错误的字组进行错因分析,前字错误的比例远大于后字错误,而且声调错误均为前字错误与后字错误的主要原因,由于发音合作人的发音标准无方言口音,可以排除发音合作者的口音因素。同时,在上声变调的语音识别中,前字错误的主要问题为上声变阳平,而后字错误则主要为上声变去声。由此可知,双音节上声字最主要识别错误类型是前字声调变阳平,其次是后字声调变去声。
2.1.2 按照常用字组与生僻字组分类。完全错误常用字组在总常用字组中占比较小,仅7.88%,而完全错误生僻字组在总生僻字组中占比33.33%。总体来看,生僻字组的错误率远高于常用字组。
2.2 三音节字组
三音节上声字组共9个,正确率100%。
3 Praat实证分析
对照组结果显示讯飞输入法对“上声+上声”与“阳平+上声”的识别正确率极低,同时发音合作人反馈,在朗读的过程中并没有很明显地感受到对照组的区别,这一定程度上说明双音节上声前字的变调与阳平具有极大的相似度。为了更加精准地显示二者存在的异同,笔者利用Praat对“凡响”与“反响”的音高进行分析[3]。
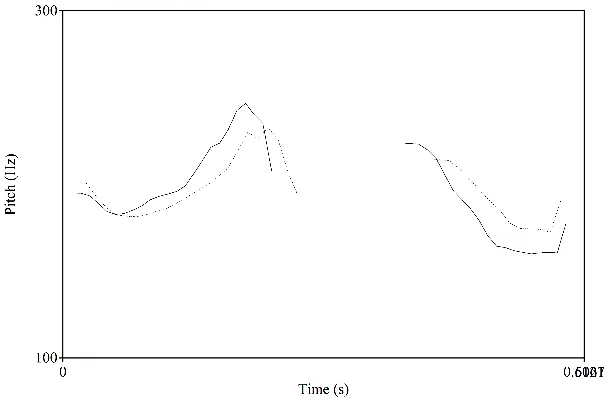
图1 “凡响”与“反响”的音高变化对比(实线为“凡响”音高,虚线为“反响”音高)
“反响”与“凡响”的前字调型为凹调,音高曲线走向基本一致,前字音高经历了先降后升再降的趋势,后字音高为先降后升。“凡”与“反”经历了明显的先降后升再降过程,与“凡”相比,“反”的调域更小,持续时间较“凡”长。响凡与响反也有先升后降的变化趋势,响凡的上升持续时间更久,整体基频值也比响反高。
4 影响因素
4.1 语流音变中的上声变调
两个上声连读在语音识别中的主要错误类型包括前字被识别为阳平与后字被识别为去声,且前一种情况导致的错误率极高,可以看作是语音识别中的难点,需要了解上声变调的原因.国内外学者也展开广泛的探讨,其中自主音段理论与优选论较有启发性。自主音段理论认为语音的各类音段有各自的独立性,声调是能独立于音段的“自主音段”,也就是声调与音段分属于两个不同的层面,将声调独立出来后就其内部构成展开探讨,发现调素脱落的物理实质是语流中相对时长的限制。优选论则以制约条件的交互作用处理音系现象,通过把普遍趋向的制约条件进行不同层级排列来分析解释[4]。(陈佩娟,2013)
因此,若是能够对音调内部的制约条件进行有效的归纳、分析,将有利于进一步提高语音识别的正确率。
4.2 同一音节中上声与阳平并存
由于前字被识别为阳平是导致高错误率的主要原因,若是前字的音节既存在阳平形式又存在上声形式,那么被识别错的概率将会更大。只存在上声形式而不存在阳平形式的音节在语音识别中的错误率极低,由此可以进一步缩小研究对象范围,重点针对既存在阳平形式又存在上声形式且合成的字组为常用词的音节。
4.3 字组的使用频率与使用范围
生僻字组与常用字组识别正确率的差异说明字组的使用频率与使用范围也会影响识别的正确率,由于语音识别基于大量的语料,因此往往更偏向由构词能力强的字所构成的使用次数多且使用范围广的字组,导致大量生僻字组在发音完全正确的情况下被替换为更加符合日常场合的字组。进一步完善统计方法、扩大语料库将有效提高识别的正确率。
由于此次研究对象为非连续性文本,因此没有考虑上下文语境的影响,客观来说,生僻字组如果放在合理的语境中,将降低识别错误率[5]。
5 结束语
本文就上声变调的语音识别进行实证研究,选取《现代汉语词典》中两个上声相连与三个上声音节相连的词,通过发音合作人获取讯飞输入法识别结果与录音。通过统计与语图分析发现影响其识别正确率的因素包括语流音变,尤其是前字上声被识别为阳平;音节形式;使用频率与范围。对以上几种原因都提出相关对策,但根本措施应该是有效提高声学模型精度,这就需要进一步研究上声变调前字的发音类型。
猜你喜欢
科普童话·神秘大侦探(2022年1期)2022-05-31
小雪花·初中高分作文(2021年3期)2021-08-27
小学生学习指导(爆笑校园)(2020年3期)2020-06-05
小雪花·小学生快乐作文(2020年12期)2020-05-17
检察风云(2020年22期)2020-01-28
参花(下)(2019年10期)2019-11-13
小哥白尼·野生动物画报(2019年12期)2019-02-28
电脑爱好者(2018年7期)2018-04-23
电脑爱好者(2018年7期)2018-04-23
中国知识产权(2016年11期)2016-11-11
