
基于FPGA的分子动力学模拟动态数据流分析
2021-06-11 05:39吴子刚柴志雷
科学与信息化 2021年15期
吴子刚 柴志雷
江南大学人工智能与计算机学院 江苏 无锡 214000
引言
分子动力学(MolecularDynamics,MD)模拟是过去几十年科研人员从微观入手研究宏观性质的重要手段之一。然而,由于MD算法的计算复杂度,在传统处理器上的一个简单生物实体模拟通常需要数周甚至数月的时间。因此对于MD模拟的加速就显得很是重要。GROMACS 能很好地利用从 SSE到 AVX512 的 X86 架构的 SIMD 指令集,从而获得较大的性能提升[1]; AMBER 则在 NVIDIA 的 GPU 上进行了大量的优化工作,成为用 GPU 模拟生物体系的代表作之一[2]。
MD模拟的关键路径是粒子间的作用力计算,具有很高的并行性。在众多的加速平台中,FPGA以低功耗和高能效而成为一种具有吸引力的解决方案。因此很多研究者也都尝试将FPGA的优势引入分子动力学模拟中。例如,S.Kasap等[3]人首次尝试将LAMMPS移植到基于FPGA的并行计算机上,取得了显著的性能提升。但是传统RTL开发的较高编程难度和设计时间,目前主流的MD模拟软件包还没有采用FPGA加速。因此,本文使用HLS探寻加速分子动力学模拟中关键路径的一些优化手段,并分析得出目前HLS还不支持动态数据流行为的描述。
1 分子动力学模拟
随着计算机的发展和算力的提高,科学研究的手段不再局限于宏观实验。当宏观实验难以进行或者很难通过宏观实验来得到满意结果时,微观模拟为科学研究提供了一个崭新的角度和方向。蒙特卡罗计算法(MC计算法)是最早对庞大系统采用非量子计算的微观模拟方法。但MC的缺点也很明显,即只能计算统计的平均值,无法得到系统的动态信息。因此目前更多地采用的是分子动力学模拟。
1.1 MD关键路径
MD模拟是在牛顿力学下分子或原子集合中的迭代应用,每次迭代中分为两个过程:①计算粒子间的受力;②更新粒子之间的速度和位置。计算的力跟模拟系统的粒子构成有关:
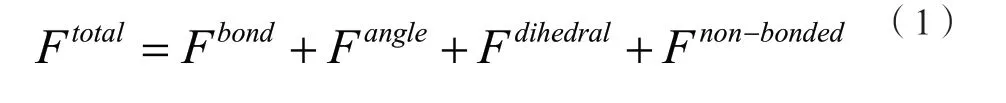
其中,公式中的前三项为键成力,最后一项为非键成力。非键成力因为引入了截断半径又分为长程非键成力和短程非键成力(RL),而RL占了整个MD的90%FLOPS,是MD中的关键路径。算法1说明了RL的计算流程。
算法1RL计算伪代码
foreach cell do
foreach neighbor cell do
foreach atom in home cell do
force = 0;
foreach atom in neighbor cell doif(distance() < cutoff radius)
compute force();
end foreach
end foreach
end foreach
end foreach
RL又包含了LJ势能作用力和短程库仑力。两者都是粒子对之间的作用力。为了简化问题突出本质,以液氩(不带电)为研究对象。因此只需要考虑LJ势能作用力。
LJ势能作用力可以写成公式(2)形式:
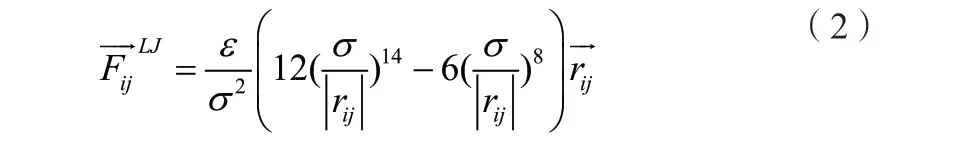
1.2 晶胞法
在分子动力学模拟中通常采用截断半径来将降低非键成力的计算复杂度,即只计算中心粒子和截断半径以内粒子之间的力。在引入截断半径后,有两种方法来进行邻域索引:邻接列表法和晶胞法。
邻接列表法的做法是对每个粒子都将其截断半径内的所有粒子保存在这个粒子的邻接表中。这样做虽然可以获得100%的效率,但是邻接列表的构造会消耗大量的存储和时间。尤其是截断半径很大的情况下,每个粒子的邻接表中会有上千个粒子。
晶胞法是将模拟空间划分成边长一样的三维晶胞。一般截断半径等于晶胞边长,使用晶胞法的效率为15.5%。这样粒子只需要跟所在晶胞的其他粒子以及相近晶胞中的粒子进行力的计算。同时晶胞的构造只需要遍历一遍模拟空间的位置信息。
因为晶胞法所体现出的空间局部性,结合FPGA的有限片上资源,晶胞法成为FPGA加速MD的首选方法。
2 HLS介绍
FPGA是一个可编程器件。它由查找表(LUT)、寄存器(FF)、连线资源以及I/O等组成。传统的RTL级别开发使用的是HDL硬件描述语言,主要分为VHDL、verilog以及system Verilog。HLS以FPGA为执行结构,使软件工程师能够优化代码的整体性能、功耗和延迟,而不需要解决单个内存空间和有限计算资源的性能瓶颈。
3 RL计算的HLS加速
目前HLS在缩短加速器设计时间和工程成本方面取得了巨大的成功。然而,在HLS中将C/C++程序映射为想要的硬件架构仍然需要开发人员具有足够的FPGA架构知识和优化技术。本文针对MD关键路径RL的计算,讨论了HLS下的实现手段,分析了RL计算中的动态数据流行为。
3.1 HLS加速
对于RL的计算可以简单分为三个模块:①粒子数据预取模块;②粒子间距离计算模块;③计算RL力的模块。为生成HLS加速器,首先考虑对图一中算法的最内层循环进行流水线设计,包括粒子间距离的计算和力的计算两个模块。此时的计算结构如图1(a)。
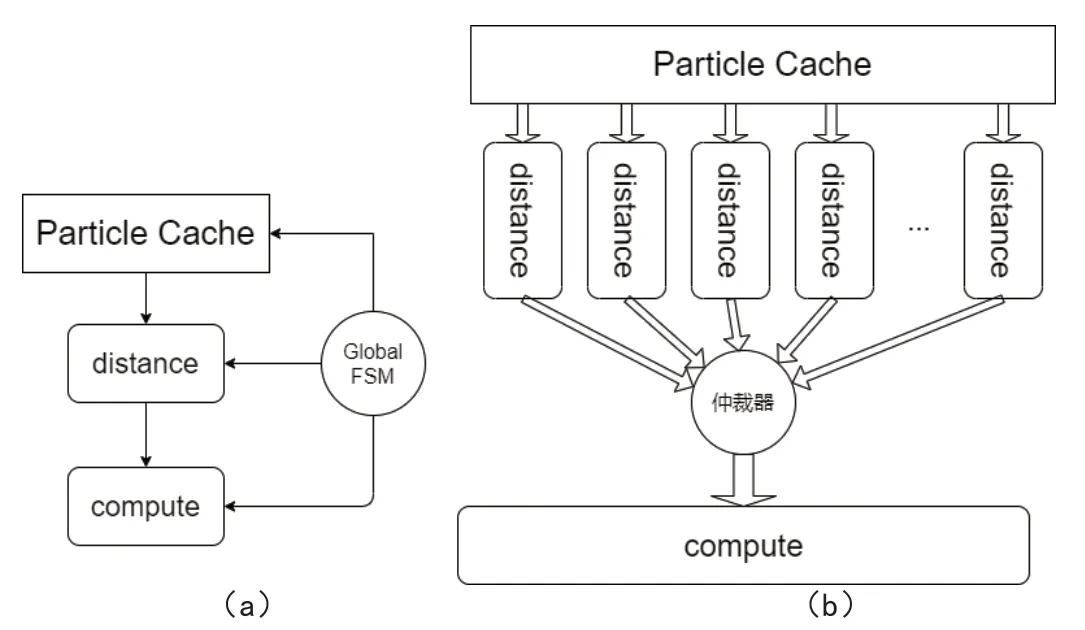
图1 RL计算架构
图1 (a)中距离计算模块和力计算模块虽然都经过了流水线设计,但都达不到很高的效率。因为采用的是晶胞法,粒子距离计算模块的效率仅为15.5%。粒子距离计算模块每个时钟周期都会从粒子数据缓存模块中读取一个粒子对,但不会每个周期都输出粒子对,从而使力计算模块的效率也仅为15.5%。
3.2 力计算模块的优化
粒子i和粒子j的相互作用力可以由公式(2)简化成公式(3)的形式。
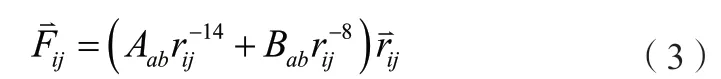
可以看到需要计算 r-8和 r-14两个高次幂。为了减少DSP的消耗,使FPGA芯片上运行更多的流水线,本文采用插值的方式来得到这两个高次幂的值。先沿着X轴把函数分成几段,并使后一段为前一段的2倍,然后在每段中等间距地取得一些离散点,得到相应的区间。这个过程被称为插值,在一段中插入的离散点越多,采用插值方式获得的高次幂就越精确。
为了避免开方操作,使用r2作为X轴。计算中如果r2的值落在由相邻离散点A和B构成的区间(A,B)之中,在使用一阶线性插值时r-k的值可由公式(4)得到:
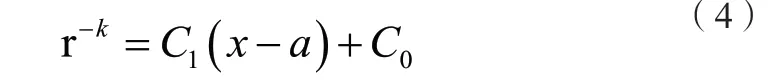
公式中的x就等于 r2,a就等于A点的横坐标。参数C0和 C1预先计算好并分别存放在两个查找表中。计算时使用 r2的值来生成查找表的地址。因为使用的是一阶插值,所以在每段中需要插入足够多的离散点,得到足够多的区间。本文在每段中会有256个区间。
3.3 动态数据流
为此通常会为力计算模块配备多个距离计算模块,以使力计算模块的效率达到接近100%,从而提升整体性能,如图1(b)。在距离计算模块和力计算模块之间加入了一个仲裁模块。仲裁模块使用FIFO存储距离计算模块输出的有效粒子对,并决定传输哪个距离计算模块输出的有效粒子对到力计算模块。
由于距离计算模块不是每个时钟都会有输出且输出的时间是没有规律的,图1(b)中距离计算模块、仲裁器和力计算模块三者构成的数据路径就是动态数据路径。
虽然现在HLS工具在综合静态数据流和规则算法时会取得很好的效果,但是在综合描述动态数据流行为的算法时通常都会是很差的效果。这是因为现在绝大多数HLS工具都假定了模块每接收一个输入就会产生一个输出。在这种假定下就不会产生动态数据流行为。因此无法直接使用HLS很好地实现图1(b)中描述的结构。
值得注意的是,除了上述原因外使用HLS还会出现全局状态机(FSM)的问题。在图1(a)中只生成了一个全局FSM,这导致了三个模块之间的强制顺序执行。图1(b)如果只使用一个全局FSM,那么实现的系统显然是低效的。理想的情况应该是各个模块都有自己独立的FSM来控制处理逻辑,而不是只使用一个HLS生成的全局FSM。这样各个模块都是并行运行的。
4 结束语
本文讨论了在FPGA上利用HLS工具对于MD算法关键路径的加速,发现关键路径中存在动态数据流行为,分析得到了这限制了加速器的性能。
猜你喜欢
空气动力学学报(2022年4期)2022-08-23
北京航空航天大学学报(2022年7期)2022-08-06
中学生数理化(高中版.高考数学)(2022年2期)2022-04-26
黑龙江大学自然科学学报(2022年1期)2022-03-29
中学生数理化(高中版.高考理化)(2019年11期)2019-11-30
中学生数理化(高中版.高考理化)(2019年11期)2019-11-27
中学生数理化(高中版.高考理化)(2019年10期)2019-11-08
中学化学(2019年1期)2019-06-29
中等数学(2018年8期)2018-11-10
中学物理·高中(2016年8期)2016-08-08
