
面向智能语言处理的汉语句法语义知识库构建
2021-06-15 04:17史金生李静文
哈尔滨师范大学·社会科学学报 2021年2期
史金生 李静文

[摘 要]文章通过比较各种语义知识库的特点,重点讨论了基于生成词库和论元结构理论的句法语义知识体系研究及资源库构建的内容、特色,并从句法-语义接口的透明性和自然性、名词中心论建模方法的实用性、解决复杂语法问题的便捷性、情感评价色彩描述的突破性等四个方面分析了其价值,并提出了关于未来句法语义知识体系研究的几点思考。
[关键词]生成词库;论元结构;物性结构;句法语义知识库;情感评价
[中图分类号]H08 [文献标志码]A [文章编号]2095-0292(2021)02-0001-09
[作者简介] 史金生,首都师范大学文学院教授,博士研究生导师,国家语委科研基地中国语言智能研究中心副主任,中国语文现代化学会语义功能语法专委会理事长,研究方向:句法语义、汉语国际教育、语言知能;李静文,首都师范大学文学院博士研究生,研究方向:句法语义。
一、引言
自然语言处理就是研究计算机处理自然语言的过程和方法,包括形式化、算法化、程序化、实用化等步骤,其中建立语言的形式化模型,使之能以一定的数学形式表示出来,是自然语言处理的核心。自然语言处理经历了从知识驱动到数据驱动的不同发展阶段:语言知识的获取最早是基于语言学家的规则描写,即根据语言学规则来编写程序,然后发展到基于统计,即从大规模真实语料库中获取语言知识,近些年发展到基于神经网络,通过深度学习,让计算机自动获取自然语言的特征。人工智能现在已经发展到第三代,已经来到了一个重要的拐点,其路径是融合第一代知识驱动和第二代数据驱动,自然语言语义的精准理解因而成为人工智能皇冠上的明珠。
计算机要能实现准确的分析,就要具备相应的语义以及语法等知识,以及相应的常识知识和推理能力。建立句法、语义知识库之类的语言知识资源,并且映射到知识图谱之类通用的形式化的语义表示框架,可以帮助计算机理解自然语言的意义,并且在一定程度上进行常识性知识推理;相反,如果同相关的知识没有牵扯,仅仅是统计方法、机器学习,计算机就不能达到对相关语言、概念的深刻理解。面向自然语言处理的知识库可服务于自动分词、词性标注、句法分析、语义分析、机器翻译、信息提取、情感分析、文本摘要和问答系统等多个领域。构建相应的句法语义知识库成为当前自然语言处理的重要任务,而缺乏形态标记的汉语,建立相关的知识库显得更加迫切。
本文主要分析汉语句法语义知识库构建的理论基础、具体内容、特色优势,并提出未来句法语义知识体系研究方面的几点思考。
二、國内外基于不同理论框架的知识库构建
现阶段,语言知识库主要包括现代汉语语法信息词典、大规模现代汉语基本标注语料库、平行语料库、英汉和日汉对照双语语料库、多语言概念词典、现代汉语短语结构规则库等,此外,还有为上述语言知识库服务的不同种类的工具软件,这些最终构成了综合型的语言知识库。
如果要展示词汇概念,并且描述概念和概念之间,以及概念和属性间关系,就需要文本语义了,也就是需要重新构建语义知识库。近年来,国内外比较流行的语义知识库在设计方面各具特点,但都是依据一定的语言学理论构建起来的。例如,美国普林斯顿大学WordNet知识库,将语义上紧密联系的相关词汇聚合成同义词集;美国科洛大学的VerbNet知识库,以Levin的动词分类作为理论基础,描述不同类别动词的论元结构;宾西法尼亚大学的Chinese PropBank知识库,借鉴了PropBank的理论和描述框架;纽约大学的NomBank知识库,借鉴了PropBank,Nomlex项目及支撑动词有关研究;Chinese NomBank知识库就是将英语命题库以及英语NomBank常规架构,用到了中文名词化谓词标注当中;我国台湾地区词库小组的Sinica TreeBank知识库,运用了中心语主导原则和依存语法理论;上海师范大学与山西大学联合构建的Chinese FrameNet,运用了框架语义学的理论;北京大学中文网库是在配价语法基础上提出了论元结构理论,并将这一理论运用于知识库构建;清华大学、北京大学、鲁东大学的事件描述块句法语义标注库,运用了格语法和配价语法理论。
以上语义知识词库为计算机实现自然语言的语义理解提供了可能性,但是也存在一些缺陷。比如,WordNet往往会将词语之间的组合关系以及语句段落里面共现的关系忽视掉,VerbNet知识库将动词当作核心,这样就不能够妥善地处理和解决情景式事物指称的问题,FrameNet无法准确地掌握相关词汇概念在具体语句段落里面的最常见的共现关系;ConceptNet虽然被计算机赋予常识经验,但缺少句子和语篇间的组合推断。那么,如何解决像“网球问题”等事物间情景联想的有关问题?计算机如何模仿人类进行常识推理和句法组合?一些语言学家作出了积极深入的探索。
三、基于生成词库和论元结构理论的汉语句法语义知识库
最近,北京大学袁毓林教授团队基于生成词库论和论元结构理论,对汉语实词进行了句法语义知识挖掘构建,编写了《现代汉语实词语法语义功能信息词典》(以下简称《实词信息词典》)。
1.主要内容
《实词信息词典》不仅充分地描写了动词和形容词的论元角色及其句法配置,还描写了名词的物性角色及其句法配置,把汉语有关的句法、语义及相关的常识知识纳入词项的句法、语义描述中,从而在体词和谓词之间形成了具有链接性的语义网络和句型体系。
《实词信息词典》是一个综合型的语义知识库,可以服务于自然语言处理。词典的主要内容有现代汉语常用实词的语义角色、主要句型、经典例句等。同时,还有一个配套信息检索系统,可以快速、准确地检索到所需要的信息内容。该词典由“汉语动词句法语义功能信息词典暨检索系统”“汉语形容词句法语义功能信息词典暨检索系统”“汉语名词句法语义功能信息词典暨检索系统”这三个子系统构成。该词典为实词设计了一套前后一致、互相照应的语义表示框架,揭示它们之间语义角色关系;加入情感评价色彩的描写,由此形成了相对完善的汉语语义知识体系。这一体系具有很大的优势,基于该体系,可以形成相应的语义知识库,其中具备了面向对象、可扩展的特点。特别重视语义角色,即词语之间的搭配关系和选择限制,并配有相关句型和习惯搭配。将语言知识纳入到知识图谱当中的方式,可以让人们更加容易也更加深刻地理解AI的含义。
知识库里面的每个实词的构成都是有两个部分,一个部分是语义角色,也被称作物性角色,另一个部分则是句法格式。词库生成需要有四种不同的物性结构,语义知识库则是在这四种不同的物性结构上进行了扩增,变成了10种不同的物性结构,分别是形式、构成、单位、评价、施成、材料、功用、行为、处置以及定位。这10种不同的物性结构一起组建成名词物性结构框架。这项研究针对动词、形容词等,建立了论元结构描写框架。在这个框架里面的内容主要有施事、经事、主事、与事、对象、工具、方法、原因、目标、时段、场合、起点、终点、途径等,共计22种动词语义角色。此外,还包括感事、与事、系事等合计9种形容词语义角色。利用句法格式就能够实现描写名词的物性结构与动词、形容词的论元结构的连接;并且还可以形成完整的句法语义接口知识,实现了在动态语境下意义浮现的解释和说明。这一知识库比其他语义知识库更加注重组合性、语义划分的精细化及语义结构,有利于计算机进行自动文本的常识性推理。
2.多层联动推导特征
《实词信息词典》是在调查大规模真实文本语料的基础上,通过对名词、动词和形容词等实词的物性结构和论元结构的精心设计和合理描述,把事物和跟事物相关的事件的有关世界知识及其语言表达形式表示出来,再辅之以指针链接和知识图谱(knowledge graph)等数据表示技术和拉近—推远(zoom-in and zoom-out)等便捷的呈现手段,有效地把相关的名词、动词和形容词的语义关联起来,形成了以名词(实体)为检索核心的、面向对象(object orientation)的语义知识库。
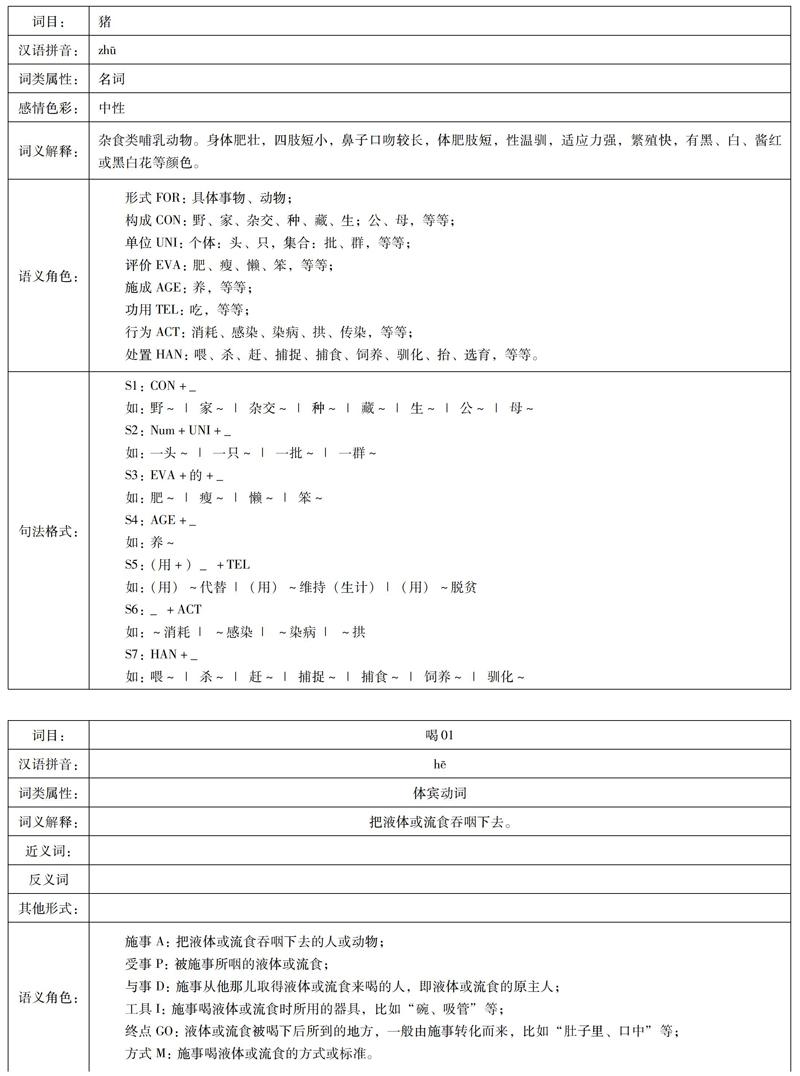
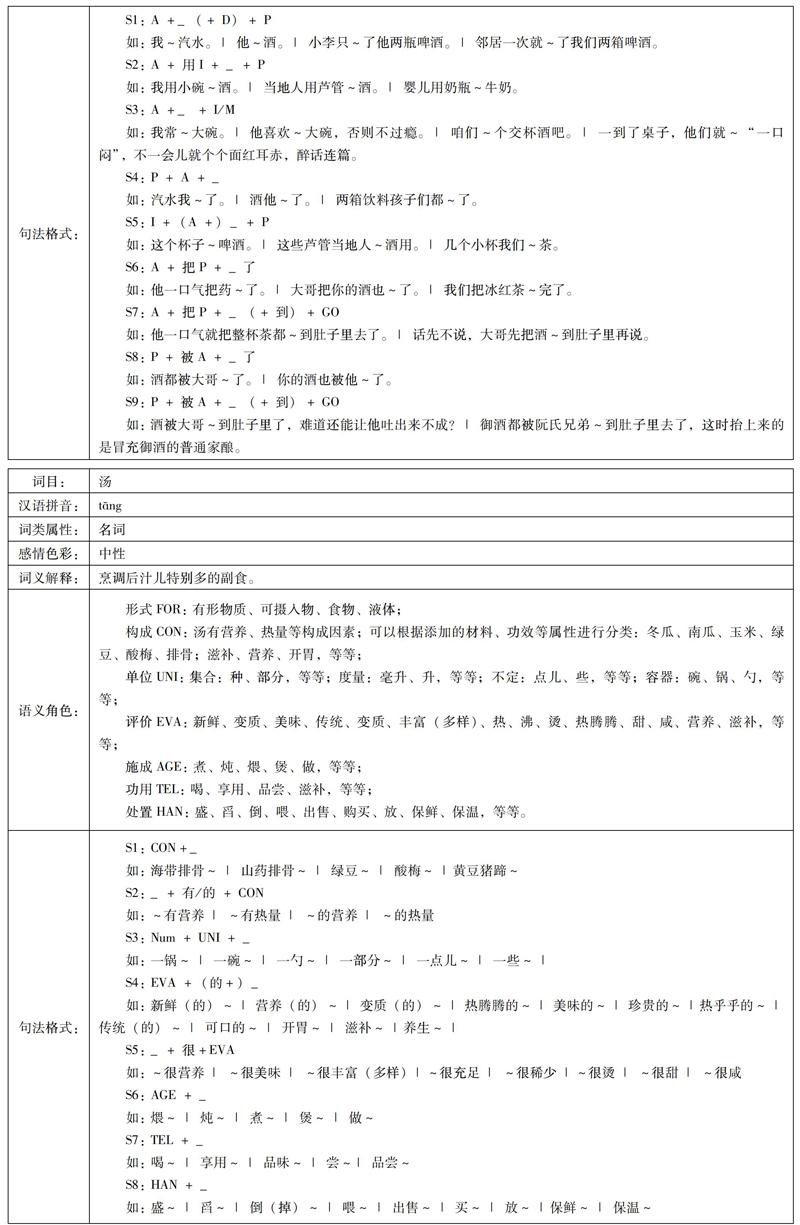
比如“猪—喝—汤”的语义角色关系及句法配置的构建:
名词“猪”的行为角色是动词“喝”,这是从名词出发看名词和动词的语义关联;反过来,从动词出发看动词和名词的语义关联,动词“喝”的施事角色是名词“猪”,同时受事角色是名词“汤”。而“汤”作为“猪”施成的条件与句子保持了句法结构的关联。“汤”功用语义角色促发了与动词“喝”进行关联。因此我们看到“猪—喝—汤”构成了一个知识网络,在知识网络中每一个节点都因语义角色的关系而相互关联,最终形成句法结构。通過对动词的论元结构和名词的物性结构的刻画,为计算机理解名词—动词之间的语义关系,提供了一种有效的知识表示。
我们再看一下名词与其他词的关联问题,《实词信息词典》解决了“馒头问题”,围绕名词进行物性角色的构建也符合沈家煊(2019)“大名词”观的思路,如:
围绕名词“馒头”可以组构成多种事件,如构成中可以与其他名词形成偏正和联合结构“杂粮馒头”“主食馒头”,处置语义角色在句法中表现为动词的宾语,如“吃—馒头”“买—馒头”,作宾语也可以是施成角色,如“蒸馒头”,“馒头”的动作行为角色也可以赋予“馒头”话题的身份,如“馒头霉变”。“馒头”的评价角色,使得馒头可以作为被修饰的成分,如“热气腾腾的馒头”“硬邦邦的馒头”“松软可口的馒头”等。可见,围绕“名词”可以关联动词“吃”“蒸”等,也可以关联名词“主食”“杂粮”等,甚至还可以关联形容词“松软可口”“硬邦邦”等。以名词为中心辐射构成了知识图谱。
另外,计算机在处理情感评价系统的时候存在输出的困难,如何识别句子的隐藏特征成为需要解决的问题。我们在考察《实词信息词典》的形容词部分找到了相关的证据。
比如:
我们可以看到“好”是对主事和范围的评价,比如“这把伞的质量好”,也可以用于比较结构“这把伞的质量比那把伞的质量好”,但是我们发现,事件结构也可以用“好”进行主观评价,比如“猪喝汤好”,“好”评价了前面的“猪喝汤”这一事件结构。如果借用化学上原子化合和配价的说法,那么形容词就是语句组合的核心,像主体、方面等伴随成分就是配价成分。不同的形容词有不同的配价功能,支配不同数量和不同性质的配价成分,构成不同形式的短语和句子。袁毓林、曹宏(2019)“形容词信息词典”就是从这样一种“情境语义学”( situation semantics) 和“配价语法”( valence grammar) 的角度,通过对大规模真实文本语料的调查和分析,全面、准确、简明地描写形容词在情境意义和搭配用法上的关键性特点,使读者“观其伴,会其意; 明其价,知其用”,即让读者在查阅到一个形容词条目以后,可以了解该形容词通常与哪些伴随成分一起出现,从而从搭配关系上理解该形容词的意义、明白其配价组合方面的特点,并掌握其基本的常用句式,进而根据这些句式,模仿相关实例,理解相关的其他句子。
形容词在修辞上生动优美、意蕴丰富,但是它的意义又显得空灵朦胧,使用起来不太好把握火候。那么,怎样才能比较切实地了解形容词的意义、掌握形容词复杂多变的用法呢?其实,了解一个词和了解一个人有相似之处。通常,我们看一个人跟什么人来往,就可以知道他大概是一个什么样的人。同样,要了解一个词的意义和用法,最好的办法莫过于观察它跟什么样的词语搭配。
另外,如“很+NP”类评价构式中的NP的语义角色关联还需要继续考虑,这就与词典中“艺术”不能受到“很”“不”等副词修饰相冲突,那么计算机如何识别“整体大于部分之和”的构式性问题还需要进一步思考。如:
四、句法语义知识库构建的意义和价值
Halvorsen(1988)特别提出计算语言学其实是模拟了人类社会的语言接受和处理的能力。这种能力其实就是典型的人工智能方法,其最大优势是实现了计算机同人类之间的转化。即将人类思维成功转化为相应的模型,使得人类的整个认知过程通过所建立的计算机模型进行实现。他曾经试图使用计算范式去模拟人类学习、获取、储存、使用知识的全部流程。
通过运用语言知识资源,让机器更加准确地理解语义,并进行一些常规的推理和推断,这正是众多计算机专家、语言学家们普遍关注和想要探究明白的问题。如何解决自然语言处理中的语义表示和理解技术,逐渐提上日程。总体而言,基于认知的《实词信息词典》,创建了具有链接性的语义网络,把语义知识加入知识图谱,利用计算机信息技术和语言知识资源建构了基于情感计算和常识计算的语义知识库,解决了像“网球问题”“他是老狐狸”等需要人类常识经验参与的语义知识问题,具有语言知识与常识推理互动沟通的创新性和信息技术开发的前沿性。
1.实现了句法-语义的自然对接
为计算机研究语言,主要以自然语言为对象,并对其具体的结构、意义规律进行不断的深入挖掘,从中得到相应的规则,包括语法以及句法等。同时这些规则具有一定的特点,即相对容易实现形式化、算法化。基于上述理念建立的相应的理论模型,主要作用就是更好地组织各种规则。《实词信息词典》里面实词语义结构的构成有两大部分,一个部分是语义角色,也叫作物性角色,另外一个构成部分就是句法格式。语义角色可以表述事物语义特点;后面句法格式则是表示实词和语义角色句法结合的特征。语义结构网络在与常识性知识建立聚合联系的同时,也关注句法结构、语境浮现和篇章链接的组合性关系和配置模式。这个知识库构建了一个新的动作指针链接,最终就成为一个“谓词—论元”式的语义关系图式。基于生成词库理论,整合了VerbNet、FrameNet、ConceptNet等知识库的优点,形成了动词、形容词论元结构知识库和名词物性结构知识库互动的模式。
2.突出了名词中心论建模方法的实用性
基于生成词库和论元结构形成的句法语义知识库具备一定的优点,具体来讲就是对相关词语所反映的知识进行突出表现,不但包括常识知识,而且有百科知识,特别是名词的描写,是在“物性角色”基础上,实现对相关的百科知识、语义结构进行详细的描述,从而解决了对“围棋是什么?”等相关问题的解释。更重要的是,该语义资源还可以和计算机视觉技术相结合,让计算机进行常识推理。例如,可以实现“如何选用某种工具(铲子)来完成铲土之类工作?”等等相关的判断和推理。
从另一方面来说,该知识库通过描写事物间的关系,构建了名词的框架结构;又基于论元结构建立了动词和形容词框架结构,并从句法角度刻画了名词与动词和形容词论元结构的选择限制和搭配关系,演化为语义关联、互动推导,而且都是以名词作为核心,包括动词、形容词以及名词,构建了属性、动作和事物间的语义网络。比如,名词“网球”的施成角色是动词“制作”等,这是从名词的角度来对名词、动词之间的语义关联进行分析;同理,从动词的角度,网球这一名词实际上就是动词“打”等的受事角色。因此,这种以名词为中心的语言建模和概念建模具有较强的实用性。
3.解释了一些复杂的语法现象
构建有足够精细度的句法语义知识库,有利于为计算机处理复杂的语法现象提供资源和解释。例如,汉语里有“名词+的+名词”歧义的问题,像“鲁迅的书”就可以理解为“鲁迅拥有的书”以及“鲁迅写的书”两种意思。针对自然语言处理,可以给计算机一个指令规则,即当NP1表示人或机构、NP2表示物品时,其中NP1和NP2之间隐含获得义,但是“鲁迅的书”却没办法用规则来说明,而利用语义知识图谱恰好能够消解这种隐含动词的歧义现象。在《实词信息词典》中检索“鲁迅”的百科知识,查到其身份是作家,再调用“作家”的物性角色,查到其功能角色是“写”,从而消解了歧义。其次,可以通过物性角色去给有价名词构建模型。比如“小明对小红的意见”中“意见”作为二价名词,可以在“物性角色”中的“构成”中,展现其降级“施事”和降级“受事”,解决有价名词的句法语义问题。再如,有些结构是动词中心论无法解决的问题,如“自行车骑起来很轻松。”如果我们转换视角,用名词中心论就更容易解释,如把“骑”看成是名词“自行车”的功用角色,后面的形容词是名词的直接评价角色,或者把“形容词”看成名词直接是从功用角色承继下来的评价角色( [骑自行车]轻松)。另外,针对无根话题,如“大象,鼻子长”,通过在《实用信息词典》中检索“大象”,其构成角色为“鼻子”,这样就找到了与前面的无根话题的联系。最后,像“他打篮球打得好”转变为“他的篮球打得好”的限制条件可以用语义知识图谱解释为,形容词“好”是修饰“他打篮球”整个事件的,事件内“打”是后面宾语“篮球”的施成角色。可见,把名词的物性角色与动词、形容词的论元角色整合起来,能够为解决复杂的语法现象提供方便。
4.突破了情感评价色彩描述的难题
人类日常语言中的感情色彩表达常常是通过褒贬词实现的,反过来说词语的情感色彩表达了人类对相关事物的情感评价。《实词信息词典》对于汉语的实词采用五级标度的方式表示其感情色彩。具体就是褒义(+2)、积极(+1)、中性(0)、消极(-1)、贬义(-2)。五级标度的方式避免了对情感色彩区分颗粒度过大或者过小的毛病,且有一定的阶梯性。除此之外,还加入了副词的考虑,如“很”“非常”等词在与情感色彩词搭配时,感情色彩将增强和减弱的情况。
另外,语义知识库还结合通俗的“七情”分类和心理实验,将情绪词分为快乐、喜好、悲哀、惊恐、愤怒、厌恶等六类,让计算机处理自然语言时具有了情感分析能力。所以,这种带有情感评价色彩的描述,在自然语言处理当中是有很大的突破意义的。
五、结语
当前,语义计算已经从词汇经句法转向篇章,出现繁荣发展的趋势。要准确地进行语义关系标注,不仅要描述论元结构,还要更加完整地把握命题结构甚至命题之外的时体、情态、篇章特征。如何标注清楚事件论元关系?如何在“谓词—论元”结构中整合“时体—情态”结构?特别是“事件”已成知识图谱新制高点的当下,怎样让静态性语义知识库和动态性事件框架更好地融合起来?这些问题都是需要更深入地探讨的内容。
从语言本体而言,加强语言理论研究,逐步完善语义描述体系和词典构架,使语义资源建设能够更好地为知识图谱和语义计算服务。要深入地联合人格心理研究实验,探索人格评价词语所具有的情感倾向,并将这种倾向展开进一步细化。要重视语义角色的精细化等级,从数量和分类方面,寻找适合的语义角色颗粒度。总之,要想把语义资源与计算机技术推向深入,使得多层神经网络的深度学习技术突出重围,帮助计算机真正“智能”起来,“弄懂”人类语言,还需要更进一步的探索。
[參 考 文 献]
[1]Chomsky & G. A. Miller.Introduction to the formal analysis of natural languages[M].Wiley, New York,1963.
[2]Chomsky. Formal properties of grammar[M].Wiley, New York,1963.
[3]Daniel Jurafsky & James H. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition [M].Upper Saddle River, New Jersey, Prentice Hall, 2000. 中文译本:冯志伟, 孙乐翻译.自然语言处理综论[M].北京:电子工业出版社,2005.
[4]Grishman, Ralph .Computational Linguistics:An Introduction[M]. Cambridge University Press,1986.
[5]Halvorsen, Per-Kristian .Computer applications oflinguistic theory, in F. J. Newmeyer (ed.) Linguistics: The Cambridge Survey, Vol. II, Linguistic Theory: Extentions and Implications[M]. Cambridge University Press,1988.
[6]Manaris. Natural language processing in the view of man-machine interchange[J].Advances in Computer, Volume,1999(47).
[7]白硕.语言学知识的计算机辅助发现[M].北京:科学出版社,1995.
[8]冯志伟.计算语言学对理论语言学的挑战[J].语言文字应用,1992(1).
[9]冯志伟.自然语言的计算机处理[M].上海:上海外语教育出版社,1996.
[10]沈家煊.超越主谓结构[M].北京:商务印书馆,2019.
[11]袁毓林.信息抽取的语义知识资源建设[J].中文信息学报,2002(5):8-14.
[12]袁毓林.语义资源建设的最新趋势和长远目标——通过影射对比、走向统一联合、实现自动推理[J].中文信息学报,2008(3):3-15.
[13]袁毓林.面向信息检索系统的语义资源规划[J].语言科学,2008(1):1-11.
[14]袁毓林.汉语配价语法研究[M].北京:商务印书馆,2010.
[15]袁毓林.基于生成词库论和论元结构理论的语义知识体系研究[J].中文信息学报,2013(6):23-30.
[16]袁毓林.汉语名词物性结构的描写体系和运用案例[J].当代语言学,2014(1):31-48.
[17]袁毓林,李强.怎样用物性结构知识解决“网球问题”[J].中文信息学报,2014(5).
[18]袁毓林.怎样利用语言知识资源进行语义理解和常识推理[J].中文信息学报,2018(12).
[19]袁毓林,曹宏.“汉语形容词句法语义功能信息词典暨检索系统”知识内容说明书[J].辞书研究,2019(2).
[责任编辑 薄 剛]
