
基于Hadoop集群的大数据新闻可视化平台的设计
2021-06-16 09:35王一高任耀星李嘉瑶
电子技术与软件工程 2021年7期
王一高 任耀星 李嘉瑶
(山西农业大学 山西省晋中市 030801)
随着智能推荐系统的不断发展和完善,智能推荐算法在各种软件中得到了应用。智能推荐算法在让人们毫不费力地浏览到自己关心的事物同时给软件运营商带来收益,但是长此以往,人们的视野逐渐变窄,眼里的世界不再那么丰富多彩,不能全方位了解和分析客观事物。因此本文设计了一种全新的新闻可视化平台,该平台的目的就在于帮助人们摆脱智能推荐算法,可以快速地按热词来浏览相关新闻,用最短的时间获取到最多的信息。
1 系统设计
本文所设计的大数据新闻可视化平台的系统架构图见图1。一般情况下,大数据的处理由数据采集、数据预处理、数据存储、数据分析与挖掘、数据可视化这五部分构成。本文所设计的大数据新闻可视化平台依赖于Hadoop 集群实现:数据采集部分使用分布式多进程网络爬虫采集互联网主流新闻媒体的热榜数据;之后在爬虫内部进行数据预处理,筛选或删除掉一些不规则的数据;数据存储部分使用HDFS 存储离线数据,使用MySQL 存储实时处理结果;数据分析部分分为实时数据分析和离线数据分析,通过SparkStreaming 进行实时流数据处理,通过MySQL 或HiveSQL 进行离线数据分析,其中MySQL 的数据分析结果用于数据可视化,HiveSQL 则用于海量离线数据分析。
2 系统实现
2.1 Hadoop高可用集群部署
由于单个NamNode 节点存在单点故障且面对海量数据存在压力过大的问题,一旦该节点发生宕机,整个集群都会不可用[1]。为了解决上述问题,Hadoop 在2.0 版本中引入了高可用机制,旨在消除单点故障,提供7*24 小时不间断服务。以典型的高可用集群为例,会有两个NameNode 节点提供服务,一个NameNode 处于Active 状态、另一个NameNode 处于StandBy 状态,当Active 状态的NameNode 发生宕机时,StandBy 状态的NameNode 会自动转为Actie 状态接续工作。
本文所搭建的高可用集群由3 台CPU 为2 核、内存为4GB、操作系统为CentOS 7.4 64 位的云服务器组成。主机名分别为:Cluster01,Cluster02,Cluster03。使用Xftp 将相关组件的安装包上传到服务器解压后进行安装配置。
2.2 分布式Flume日志采集
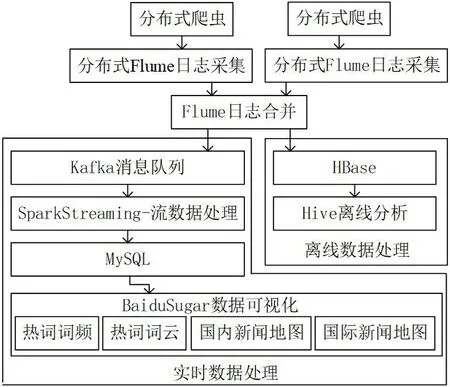
图1:系统架构图
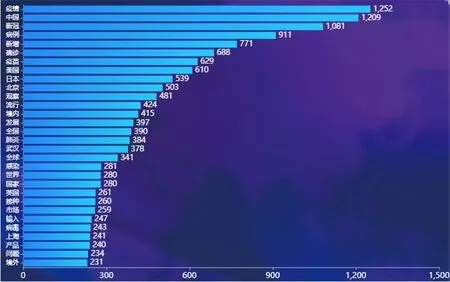
图2:词频统计图
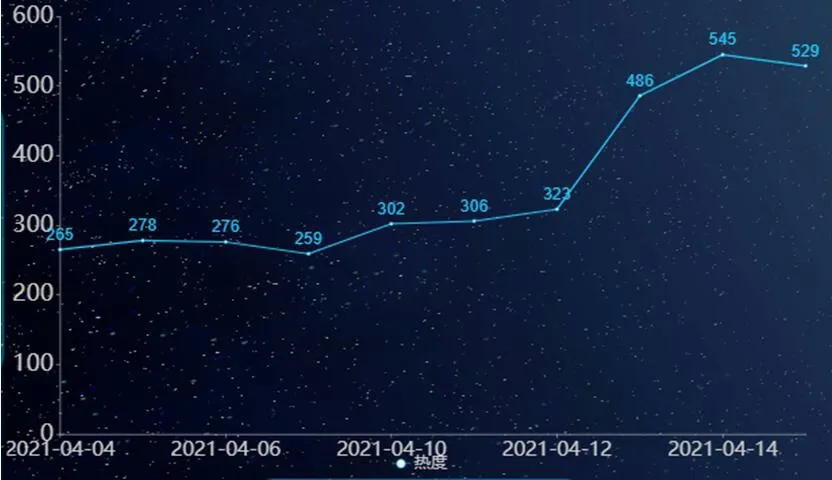
图3:热度趋势图
Flume 通常以分布式的形式部署于Hadoop 集群中,它具有高可用和高可靠的特性。Flume 的核心角色是Agent,每个Agent 的内部有三个组件:Source、Sink、Channel。Flume 可以根据用户的需求进行灵活的定制,可以是单个Agent 采集数据,也可以是多个Agent 之间进行串并联,共同采集数据。在本文所搭建的分布式Flume日志采集系统中,Cluster02 和Cluster03 的Source 是分布式多进程爬虫产生的新闻数据,Sink 均对接Cluster01 所部署Flume的Source。Cluster01 的Sink 为Hbase 数据库和Kafka 消息队列。爬虫每半小时运行一次,当Flume 监测到日志文件发生变化时会自动对日志文件的新增内容进行采集和汇总,然后分别传输到Kafa消息队列和Hbase 数据库中。
2.3 分布式多进程爬虫部署
经实测爬虫每次运行会产生4-5 万条数据,普通的单线程爬虫在爬取海量新闻数据时显得力不从心,无法保证在短时间内完成数据的更新。且爬虫属于IO 密集型任务,在短时间内会进行大量的读写操作[2]。为了加快爬取速度并实现数据的及时更新,需根据爬取任务量对服务器进行负载均衡。依托于Hadoop 集群,分布式多进程爬虫得以实现[3]。其中Cluster02 和Cluster03 负责爬取数据并将每次爬取的数据写入缓存文件,与此同时,Cluster02 和Cluster03 上部署的分布式Flume 负责监督并将爬虫产生的数据传输给Cluster01 进行汇总。新闻数据具有很强的时效性,部分新闻媒体的更新频率很高,所以分布式爬虫设定每半小时运行一次。
2.4 Kafka消息队列
Kafka 是一种基于发布-订阅的分布式消息系统,其具有高吞吐量、低延迟的特性,广泛应用于消息传递、日志收集领域。Kafka 可以将消息持久化存储在硬盘上,从而规避了数据丢失的风险,并且消费者可以凭借偏移量在一段时间后实现继续消费。在本文搭建的Hadoop 集群中,Cluster01 节点的Flume 相当于Kafka 的生产者,SparkStreaming 端作为Kafka 消费者接收海量新闻数据进行实时处理。
2.5 SparkStreaming流数据处理
Spark 是一个面向大数据处理而设计的计算引擎,与Hadoop的MapReduce 相比,其内存计算的特性使得其中间结果不必反复写入磁盘,避免产生大量的IO 开销,因此可以在短时间内完成对海量数据的处理。SparkStreaming是构建于SparkCore之上的一套框架,具有高吞吐量、容错的特性,主要用来处理实时流式数据,其将接收到的实时输入数据流按照时间间隔进行切分后计算处理。其数据源可以是Kafka、Flume、HDFS 等,处理结果支持写入HDFS 或其它数据库。
在本文所设计的新闻可视化平台中,SparkStreaming 程序作为Kafka 的消费者,在取到数据之后使用Jieba 中文分词对新闻文本切分并进行词频统计,为便于数据可视化,将处理结果写入MySQL数据库中,为了避免数据冗余,MySQL 数据库在每次数据更新前都会执行清空指令。
2.6 HBase数据库
HBase 是一个分布式的、面向列的开源数据库,是BigTable的开源实现,其构建于HDFS 之上,具有高性能、面向列、可伸缩的特性,广泛应用于社交信息、搜索引擎、网络日志等的存储。HBase 支持通过JavaAPI、HBase Shell、Hive 等进行访问。将Flume 的Sink 设置为HBase 并创建相应表便可以实现HBase 与Flume 的对接。本文所编写的分布式爬虫每半小时运行一次,若每次爬取的数据都写入HBase 数据库,则会造成数据冗余,浪费存储容量,因此离线数据每日只写入一次。爬虫采集的新闻按类别可以分为:时政、经济、法律、军事、科技、文教、体育、社会等,数据的不断积累可以构建出专属的新闻语料库,这可为日后的机器学习、文本分类、NLP 研究提供数据支撑。
2.7 Hive离线分析

图4:国内新闻地图

图5:国际新闻地图

图6:新闻来源及内容
Hive 是一个采用MapReduce 作为计算引擎,HDFS 作为文件系统的数据仓库工具,Hive 的编程语言为HiveSQL,是一种类SQL 语言,其特点是可以将SQL 查询转换为MapReduce 任务进行处理,具有简单易上手的特点。可以通过在Hive 中创建HBase 的外部表来访问HBase 中的离线新闻数据并进行大规模数据分析。
2.8 百度Sugar数据可视化
本文采用了百度Sugar 的解决方案,首先将处理后的数据写入到数据库中并开放数据库相应端口,将集群数据库添加到Sugar 中作为数据源,然后在Sugar 中设计好可视化版式并编写相应SQL 语句便可以实现数据可视化。且Sugar 支持图表下钻功能,提供了优美的界面和强大的交互体验,可以让开发者将工作重心更多地放在数据分析与处理而不是前端页面开发。
2.8.1 热词词频统计
查询数据库中词频统计结果的前30 条数据,以横向柱图的形式进行展示,见图2。点击单个柱子会自动弹框展示包含热词的相关新闻。
2.8.2 热度演变趋势
根据积累的历史数据,可以进一步展开数据分析,以横向柱图中的热词作为关键字在数据库中进行模糊匹配并按日期分组求和,可以得出该热词的变化趋势[4]。以最近的“日本决定向大海排核污染水”新闻为例,查看“日本”的热度演变趋势,由图可以看出在2021-4-12 之后,“日本”的相关热度骤然增高,见图3。
2.8.3 新闻地图
在使用Jieba 分词器完成中文分词后,分词中包含着若干地名信息,将地名信息提取统计之后显示在地图上可以构建一幅新闻地图[5]。本文的新闻地图由国内新闻地图(图4)和国际新闻地图(图5)组成。国内新闻地图以气泡图的大小反映该地区新闻数量,国际新闻地图则以色块的形式反映国家的新闻数量。点击区域或国家,均可弹框展示包含该区域或国家的新闻,通过传递参数,点击热点名会自动使用百度对该内容进行搜索,见图6。
3 总结与展望
本平台是一种使用大数据相关技术开发的大数据新闻统计分析平台,在完成新闻数据可视化的同时构建新闻语料库。通过爬取全网各大新闻媒体平台的实时数据,并对其热榜信息进行聚合,实现对新闻网站的各种信息(来源,分类,热度信息等)的分析。通过统计分析的数据,将实时新闻热点进行可视化展示。首先本平台有助于用户告别智能推荐,减少不必要信息的干扰,从而更全面的按照自己的需求查看新闻。通过聚合全网信息,客户可以用较短的时间去快速浏览、获取更多的信息,这种方案简单高效,是一种全新的新闻获取思路。并且本文所构建的新闻语料库可为后续实验和科学研究提供数据支撑。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
防爆电机(2021年4期)2021-07-28
现代信息科技(2021年21期)2021-05-07
中国特种设备安全(2021年11期)2021-05-05
铁道通信信号(2020年6期)2020-09-21
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中成药(2018年2期)2018-05-09
电子测试(2018年1期)2018-04-18
中国交通信息化(2017年3期)2017-06-08
