
基于优化算法的医院医保智能审核系统
2021-06-16 09:35周文娟王一敏李积军杨燕杜晓刚
电子技术与软件工程 2021年7期
周文娟 王一敏* 李积军 杨燕 杜晓刚
(1.甘肃省人民医院网络中心 甘肃省兰州市 730070 2.兰州交通大学电子与信息工程学院 甘肃省兰州市 730070)
1 医保智能审核系统的概述及现状
随着国家基本医疗报销比例的增加,患者医保费用增长过快,医保管理机构越来越重视医保患者的诊疗规范,及医保基金的合理使用。医保智能审核在20 世纪60年代始于美国药品管理机构,为了掌控医师和药师的医疗行为提出的医保审核思路。我国人社部在2016年起,在全国范围内推行医保智能审核机制,以国家研发的统一软件为基础,根据各地医保管理政策的差异,推行因地适宜的审核系统,各地的规则库也会有差异性[1]。
目前医保审核系统在一些发达地区可以实现同一名患者在各医疗机构就医过程的联动审核,医保专家和医院专家可以定期联合完善专家库,并且将审核工作延伸到事前提醒,事中监控及事后反馈。智能审核系统以建立规则引擎为核心构件,运用智能审核算法建立高效的医保智能审核系统,如何提高审核的精准性和效率是亟待解决的问题[2]。
2 医保智能审核系统的总体设计
为实现医保审核的及时性,建立与医疗管理机构同步的院内医保智能审核系统是实现全流程医保审核的有效解决方案。院内医保智能审核系统框架如图1 示。院内医保审核系统是基于HIS 系统构建的,通过与医疗管理机构审核系统对接,系统可以实时提醒医生开具医嘱和处方过程中违规的诊疗行为,真正实现医疗费用和诊疗行为的全面监控和审核,将违规行为控制在院内并及时解决[3]。
3 医保智能审核系统的关键技术
3.1 医保智能审核系统规则引擎
院内医保智能审核系统的设计必须允许异构兼容,规则引擎作为审核系统的核心技术,其应用着力于自定义业务逻辑规则,通过不断改进满足医保业务审核需求,以灵活高效的特点应用于医保审核系统中,从而提高系统监管和审核的综合水平。
3.2 基于规则的机器学习
医保原始数据通常是大量无标签数据和少量有标签数据组成的,在建立规则库的前提下,对部分有标签原始数据可以直接通过特征值和目标值的线性关系,建立分类模型,通过不断监督学习,达到对有标签数据的分类[8]。对无标签原始数据进行分类,通过数据的相似性,建立数据的潜在关联,快速将海量数据划分应用于复杂交叉的规则项中,再通过随机算法提高这种无监督的机器学习的效率,最终提高审核效率。
3.3 基于K-Means的果蝇算法在规则引擎中的应用
3.3.1 K-Means 聚类算法应用于无标签医保数据
医保审核系统的工作重点之一是对各类医保费用进行核查、分析、判断。审核系统需要对每一笔费用核验,但其数据挖掘模块无需涉及每一个费用项目。通过半监督学习聚类模型对无标签数据预处理,进行不断迭代自我学习,找到一定的相似性,得到最优模型,最后将无标签数据分类变成有标签的可用数据。
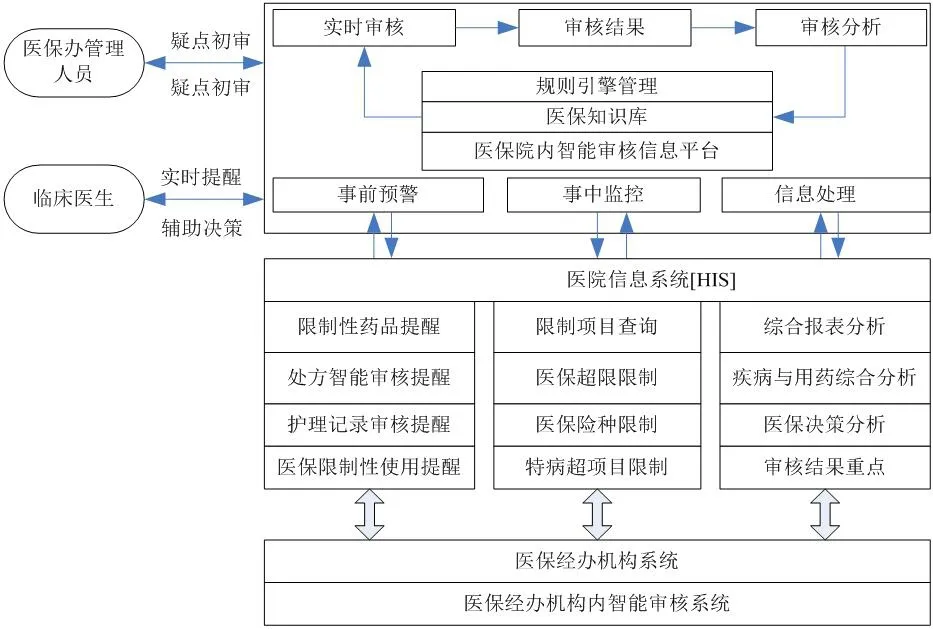
图1:智能审核系统框架图
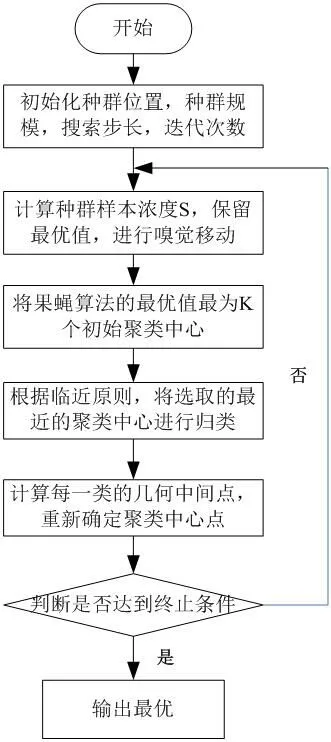
图2:算法的流程
聚类算法中K-Means 算法最为典型,K-Means 算法对挑选的初始簇中心很敏感,通过寻找与簇中心相似的样本,将样本聚集到簇中心,通过不断迭代降低数据的维度,将原始数据集分为几个样本集。
假设将数据集样本簇划分为(c1,c2,c3,…,ci),其中ui是簇ci的均值向量,质心表达式可定义为:
该算法在模型训练前需要设定簇的个数K 值,在医保审核模型中以审核规则说明的分类作为K 值选取依据。医保审核规则大致分为四类:支付政策性审核规则、诊疗合理性审核规则、临床规范性审核规则、医疗行为异常监控规则。其中规则说明包含限定医院类型级别、限儿童、限性别、中药饮片审核、超限定频次、用药安全审核、限定适应症用药、违反项目匹配等。通过政策的调整,及审核规则的增减,调整K 值的选取。
3.3.2 基于K-Means 的果蝇寻优算法
果蝇算法是一种新兴启发式算法, 模拟自然界果蝇的觅食活动寻求目标函数的最优解, 算法的核心参数有种群位置,搜索步长,种群规模和迭代次数。在聚类算法的寻优过程中,为解决陷入局部最优达到全局寻优的目标,选取聚类初始化中心对聚类结果的具有重要影响[8]。
基于K-Means 聚类算法和果蝇算法的结合,在每次迭代过程中,首先利用果蝇算法寻找聚类中心点,确保聚类结果的质量,再将每一个聚类中心点进行一次K 均值优化,两种算法交替进行,直到聚类结束[9]。通过K 均值优化加快收敛速度,融入果蝇算法降低对聚类中心点的依赖性。有效地提升医保无标签数据利用率,增加医保审核的准确率。改进后的融合算法流程如图2 所示。
4 应用效果

表1:医保审核系统部分项目分析
通过优化改进审核系统的规则匹配算法,大幅度的提高了违规数据的审核的精准率,对系统的运营监管和医保控费都有显著的成效。结合2019年和2020年度医保监管部门反馈的扣罚情况,较上一年相比,在用药违规方面,没有出现用药重复超量、中药饮片超量等问题。在项目违规方面,违反限定条件适应症(条件)用药,违反项目匹配、用药安全审查、超限定频次等指标均有下降。限定就医方式、限儿童等指标显著下降。从整体情况来看,通过不断扩充匹配规则,院内审核系统对违规诊疗行为的精准匹配,确实帮助医生在事前规范了诊疗行为,违规现象有所减少。
4.1 数据分析
选取两年内有代表性的三项违规指标作统计学分析,对超限定频次、违反项目匹配、用药安全审核三项违规率数据进行卡方检验(X2)分析,卡方检验结果的P 值小于0.05,则具有统计学意义上的显著差异性。
2019年与2020年三项指标卡方检验结果P 值均小于0.05,证明规则匹配算法的优化在对这三项违规指标的监管问题上是具有统计学意义上的显著差异。在2020年三项违规率均有降低, 达到提高医保审核的精准性和效率,减低违规率的目的,对三项违规指标的数据分析见表1 医保审核系统部分项目分析。
4.2 应用先进性
医保审核系统不仅应用于医保管理科室,而且贯穿于临床科室的诊疗过程中。通过对整个诊疗过程的监控,对结果统计分析,不断改进不规范的诊疗行为,使得对临床科室规范医保管理更具有针对性[13]。
4.2.1 规范诊疗行为
通过制定临床路径规则,医嘱规则,药品规则,护理规则等相结合,审核系统在诊疗环节会给医护人员给予医嘱规范指导和违规提示,使得医生作出满足患者需求又符合医保政策的诊疗行为。
4.2.2 规范审核流程
审核平台通过事前对医生诊疗行为的干预和提示,事中对审核结果的查阅,事后对不合规项目申诉。最终实现统一的审核标准,规范了审核流程,在整个医保管理过程中形成完整的PDCA 精细化管理流程[14]。
4.2.3 提高审核质量
医保智能审核系统包括规则引擎和规则库,其中规则库包含医保政策预设的审核规则,同时根据管理部门需要,可不断完善充实系统规则体系。审核规则采用分级制的建立,全面覆盖涉及医保管理的每一个细节,平稳完善了智能审核规则。借助人工智能机器学习的智能算法技术,通过对海量数据指标的筛查,提高审核速度的同时极大地保障了审核的精准性和有效性。
5 结论
2019年11月国家医保服务平台公布开通,全国首张医保电子凭证在济南申领成功,建立与国家医保服务平台同步的院内医保审核系统势在必行。将K-Means 算法和果蝇算法结合的优化算法在医疗保险审核领域中的初步探索,快速准确的筛查违规项目,规范了医护的诊疗行为,降低了诊疗过程的违规率,提高了医院医保监管能力。
猜你喜欢
廉政瞭望·下半月(2022年4期)2022-05-12
学苑创造·A版(2022年3期)2022-03-29
烟台果树(2021年2期)2021-07-21
中国石油石化(2021年9期)2021-07-17
学苑创造·A版(2019年6期)2019-07-11
测控技术(2018年7期)2018-12-09
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
作文通讯·高中版(2017年12期)2017-02-06
公民与法治(2016年10期)2016-05-17
