
高校录取过程中学生信息获取行为的分析
2021-06-16 09:35康宏伟
电子技术与软件工程 2021年7期
康宏伟
(西南大学计算机与信息科学学院 重庆市 400715)
1 引言
教育是一个国家发展进步的基石,高校招生录取制度作为一种高校的人才选拔制度,事关数千万考生的前途命运,决定了素质教育平稳健康地开展,也体现了教育资源分配的公平公正[1]。而高考改革是当前教育界讨论的热点话题,关于高考科目、高考内容、高考录取模式、高校招生计划分配等问题是其中的重点议题。其中涉及了高考是否公平、高考命题和录取模式是否合理、招生计划分配是否合理等等许多理论及技术层面上的问题[2]。
这些年来,我国的高考制度在不断改革完善自身的过程中前进,力求为国家与社会公平选才、科学选才,其时序性、梯度性与价值性都发生了变化,公平性也日益加强[3]。但同时,高考录取机制也暴露出不少问题,比如“高分低就”和“高分落榜”等,从“平行志愿”到“志愿优先”的高考改革在很大程度上改善了这两种现象,提高了学生的选择空间以及被录取的机会。但是,“平行志愿”也存在明显不足,比如唯分数论、退档风险、专业满意度低、高校自主权减弱、强化高校之间的等级之分等[4]。基于此,不少学者对高校录取机制进行了研究,文献[5]讨论了填报志愿时间不同时高考录取机制产生“高分低就”现象的原因,表明当考生的偏好是考生的私人信息时,知分填报时也存在均衡时发生“高分低就”的可能。之后,文献[6]进一步分析了“志愿优先”录取机制,提出择校机制文献中的Gale-Shapley 机制可以应用在高考录取中,并分析了中国高考平行志愿是一种分数独裁机制, 这种机制是Gale-Shapley 学生最优机制的一种特殊形式,并给出了分数独裁机制的算法。也有学者分析了平行志愿录取机制,认为相对于传统的“志愿优先”机制,平行志愿录取机制对于全体考生来说不是帕累托改进,认为增加平行志愿数目对低分考生不利[7]。刘驰结合Gale-Shapley 机制,对以往文献的“一档多投”模式的录取算法进行了改进,认为这种录取算法更能够凸显院校的专业特色,促进院校特色专业的发展[8]。
高校录取机制的实质是双边匹配机制的一种,给定学生和高校各自的偏好排序,学生与高校之间的匹配是一个经典的机制设计问题,可以采用Gale-Shapley 机制、Boston 机制以及TTC(Top Trading Cycles)机制等来完成这一匹配。在Gale-Shapley 大学招生模型中,学生和学校都是积极的参与者,每个学生对所有大学有一个偏好排序,每个大学也对所有学生有偏好排序。对于学校和学生任意的偏好,通过Gale-Shapley 机制都能产生学生和大学的组合,使得录取的结果是稳定的且是帕累托最优的[9]。学校录取机制中的另一个重要问题是其抗策略的性质,Dubins and Freedman 证明了Gale-Shapley 机制是抗策略的[10]。在此之后,Roth 的一系列论文较全面地讨论了Gale-Shapley 机制的帕累托最优和稳定性等问题[11,12]。Gale-Shapley 机制并不是唯一可以达到帕累托最优的学校录取机制,Shapley and Scarf 在其分析住房市场的论文中首先提出了Top trading cycles 机制的思想[13]。Abdulkadiroglu 和 Sönmez 扩展了Top trading cycles 机制,并证明了该机制也是帕累托最优和抗策略的,还讨论了在约束条件下两种最优机制的运用[14]。Chen 和Sönmez用实证的方法比较了Boston 机制、Gale-Shapley 机制和Top trading cycles 机制,得出的结论是后两种机制要远优于Boston 机制,但Gale-Shapley 机制在实际运用中效果最好 。
综上所述,国内外相关学者对高校录取问题进行了广泛的研究和讨论,但是在他们的研究中,都假设学生有着确定的、成熟的偏好,未考虑学生通常会花费大量的时间和精力来获取不同学校的信息以确定自己偏好这一实际情况,实际上很多学生由于不能充分获取、利用信息,极大地浪费了社会教育资源,降低了社会福利。本文在已有模型的基础上,以Gale-Shapley 机制为例,引入了信息获取模块,研究学生在参与匹配前,为了提高自身的匹配收益,主动花费成本获取院校、自身偏好等信息。
2 模型描述
2.1 基本模型
为全面分析信息获取对学生匹配收益的影响,本文在已有高校录取模型的基础上,把引入信息获取模块的高校录取模型定义为:
(1)所有学生的集合S={s1,s2,…,sm}。
(2)所有学校的集合C={c1,c2,…,cm}。
2.2 Gale-Shapley机制
第一轮:考虑每个学生si的第一志愿,学校ci将第一志愿报考本校且偏好排序上最好的前个学生进行预录,其他学生进行退档。如果第一志愿的学生人数不足,则预录所有学生;
第二轮:考虑上轮被退档学生的第二志愿,学校ci将第二志愿报考本校的学生和上轮中己预录的学生一起比较,将最好的个学生进行预录。其他学生进行退档,如果学生人数不足,就留下所有的学生;
第k 轮:考虑上轮被退档学生的第k 志愿,学校ci将第k 志愿报考本校的学生和上轮中已经预录的学生一起比较,将最好的个学生进行预录。其他学生进行退档,如果学生人数不足,就留下所有的学生。
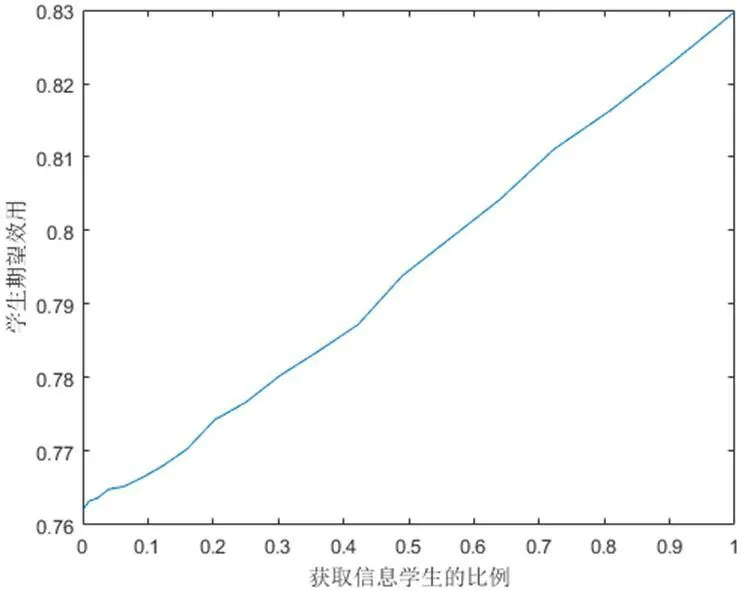
图1:免费获取信息
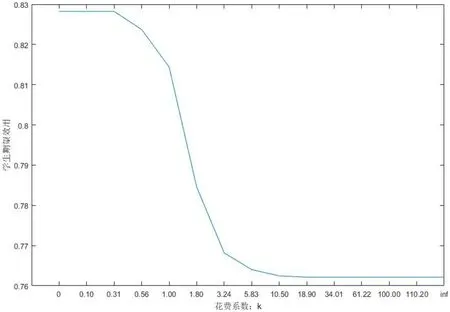
图2:获取信息时学生的期望效用
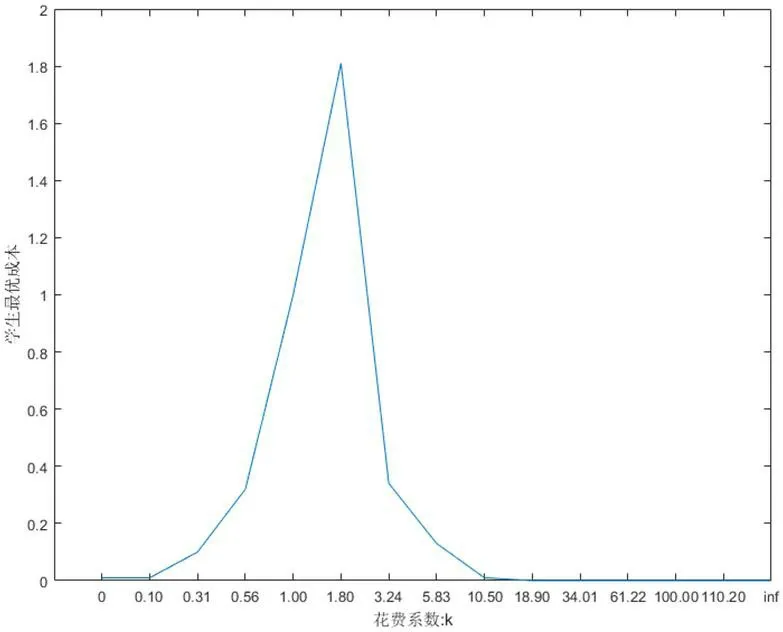
图3:获取信息时学生的最优成本
当没有学生被退档,所有的学生都分配到最终位置时,这个算法结束。由于学生和学校的数目有限,这个过程一定会在有限步后停止,所有预录考生最后就被学校正式录取。如果一个学生被所有的学校退档,意味着这个学生落榜。
3 理论分析
Gale-Shapley 机制中,学生填报自己的真实偏好是占优策略,而在参与匹配前,为了确定自己的真实偏好,有动机获取自身偏好信息,但为了获取信息愿意花费多少成本是不确定的,假设学校对学生的偏好是基于学生分数排名,当考虑到学校的招生名额和学生自己的排名时,部分学生是有动机获取他人偏好信息的,本文利用下面的简单例子进行说明。
例:假设有两所学校A 和B,每所学校2 个招生名额,即=2;有5 名学生,按照分数严格降序排序s1,s2,…,s5,学生排名、学校招生名额和学校效用分布是公共信息,但学生对学校的偏好是私人信息,如下所示:

uiA为学生si对学校A 的收益认知,表示学生si被学校A 录取后所获得的收益,uiB类似;其中ξiA、ξiB独立同分布于N(0,1),表示学生在获取信息后对学校效用的更新,若学生未获取信息,则ξiA=ξiB=0。每名学生只能被一所学校所录取,未被录取的学生收益为0。
学生s1知道自己的排名最高,按照Gale-Shapley 机制他将被分配给自己的第一选择,所以他只需选择自己最喜欢的学校,提交真实偏好就是他的占优策略,所以学生s1有动机获取自身偏好信息,以便确认自己最喜欢的学校;学生s2知道自己的排名是2,且每所学校招收2 名学生,所以无论他最喜欢的学校是否录取了学生s1,这所学校都至少仍有一个招生名额,所以提交真实偏好是他的占优策略,他也有动机获取自身偏好信息;对于学生s3而言,如果学生s1和学生s2都最喜欢学校A,按照Gale-Shapley 机制学生s3只会匹配给学校B,此时他没有意愿去获取自身偏好信息(学生s1和学生s2都最喜欢学校B 类似),若学生s1和s2一者喜欢A 一者喜欢B,那么学校A 和B 都至少还有一个招生名额,学生s3为了确定自己喜欢哪所学校,有动机去获取自身偏好信息,所以学生s3总是倾向于获取学生s1和s2的私人偏好信息,再来决定他下一步是否获取自身偏好信息;学生s4与学生s3类似;而对于学生s5而言,在Gale-Shapley匹配机制下,学生s5总是落榜,他没有动机去获取信息。
对于学生而言,策略的选择是为了最大化他们的匹配收益,在免费获取信息的情况下,真实填报自身偏好是优势策略。但当获取信息时需要花费成本时,为了获取自身偏好信息,学生愿意花费多少成本呢?
假设ci为学生si为获取学校A 与B 的信息所花费的成本,c't为学生si为了获取他人偏好信息所花费的成本。
从前文的分析得知,学生s1和s2是有动机获取自身偏好信息的,对于学生s1,若u1A>u1B即那么他最喜欢的学校是A,其次是B,此时学生s1的真实偏好和学校初始排名相同,学生s1最优花费成本为c1=0;当u1A<u1B即时,学生s1最喜欢的学校是B,其次是A,在获取信息前,他的志愿偏好是{A,B},所以会被学校A 录取,而他的真实偏好为{B,A},若他填报真实偏好会被学校B 录取,所以学生s1为了获取信息所愿意付出的成本的最大值为(学生s2类似)。对于学生s3,若他人偏好信息能够免费获取,即c'3=0,当学生s1和s2最喜欢的学校相同时,学生s3没有获取信息的意愿,c3=0;当学生s1和s2最喜欢的学校不同时,若u3A>u3B,则 c3=0,若u3B>u3A,则当他人偏好信息不能免费获取时,即c'3>0,由Gale-Shapley 机制抗策略性分析可知,学生s3的优势策略是不获取他人偏好信息,获取自身偏好所花费成本的分析与学生s1类似(学生s4类似);学生s5由前文分析可知没有获取信息的意愿,也不会花费成本。
由上述分析可知,当获取自身偏好信息需要花费成本时,学生愿意花费成本的最大值取决于获取信息后匹配收益与获取信息前匹配收益的差值。
为了对上述分析进一步验证,本文做了以下仿真分析:
4 仿真实验
4.1 实验设置
为了验证信息获取对学生匹配收益的影响,本文利用matlab 语言建模,对学生获取信息的行为进行仿真,实验设置1300 名学生、100 所学校,每所学校招收10 名学生,学生与学校的匹配过程采用Gale-Shapley 算法,未被录取的学生落榜。学校对学生的偏好按学生的分数排序,学生的分数为系统随机产生,学生可以观测到彼此的分数,学生对学校的初始偏好为学校初始效用的排序,学校初始效用为系统随机产生,所有学生都可以观测到。而学生的真实偏好及被学校录取后的真实效用是学生的私人信息,学生彼此不知道对方的真实偏好,且学生的真实偏好需要学生花费成本去学习,学生不论是否学习到自身真实偏好信息,被学校录取后的所获得的效用均为学校的真实效用,未被录取的学生数获得的效用为0。
为了简化实验,本文将获取所有学校信息所花费的成本统一为c,假设学生花费成本后要么获取到所有学校的全部信息,要么完全没有获取到信息。假设学生花费成本c 后获取到信息的概率为未获取到信息的概率为花费成本越多,获取到信息的概率越大,其中k 为花费系数,表征学生获取信息的难易程度,当k值较小时,学生很容易获取到信息,当k 值较大时,学生获取到信息的难度变大。学生决策的目的是最大化自己的收益,他需要决定是否花费成本获取信息以及花费多少成本。
4.2 学生免费获取信息时匹配收益变化的仿真分析
为了研究信息对学生匹配收益的影响,首先假设政府提供院校全部信息,学生有着确定的偏好,即学生获取信息不需要花费成本,当获取信息的学生比例增加时,所有学生的期望收益的变化情况。当学生获取信息的比例由0%增加到100%时,学生的期望收益上升了约7 个百分点(见图1)。
结论1:当学生能免费获取信息时,随着获取到信息的学生比例的增加,学生整体期望收益也在逐步提高,也就是说,免费提供信息能显著提高学生的匹配收益;
4.3 花费系数与学生期望收益关系的仿真分析
花费系数 表征学生获取信息的难易程度,k 值越大学生越难获取到信息,此仿真实验中花费系数k 值按对数尺度增大,取值,当k=0 时,学生获取信息不花费成本,此时学生有较高的期望收益,随着k 的增大,学生为了成功获取信息需要花费更多的成本,学生期望收益逐渐下降,当k>10.50 时,学生的收益与未获取信息时的收益持平,说明此时学生没有动机花费成本获取信息(见图2)。
结论2:在花费成本获取信息情况下,当获取信息难度较低时,学生愿意花费一定成本获取信息以提高收益,而当获取信息的难度很大时,学生没有意愿花费成本获取信息。
4.4 花费系数与学生最优成本关系的仿真分析
在获取信息需要花费成本的情况下,学生需要决策是否花费成本以及花费多少成本来获取信息。在k<1.8 时,学生的最优花费成本随着k 值的增大而增大,学生的优势策略是花费成本直到成功获取信息为止;当1.8<k<10.50 时,学生的最优成本随着k>10.50 值的增大反而逐渐下降,表明学生此时有一定的意愿花费成本去获取信息,但不愿意付出太高的成本;当 时,学生没有意愿去获取信息(见图3)。
结论3:在获取信息难度较低的环境中,学生有很强的获取信息的意愿,其优势策略是花费成本直到成功获取信息为止,当获取信息难度较大时,学生会尝试花费成本去获取信息,但不会花费太高的成本,而在获取信息难度很大的环境中,学生的最优策略是不花费成本。
5 结束语
针对目前高校录取机制研究中缺乏的信息获取模块,本研究致力于探究引入信息获取模块后学生匹配收益的变化情况。通过理论分析和实验验证,说明信息获取是高校录取过程中必不可少的一个步骤,且会显著影响学生的匹配收益,所有学生都有意愿获取自身偏好信息,且部分学生在特定情况下也有动机获取他人偏好信息。此研究有利于进一步完善高校录取模型,指导学生获取更充分的信息,更好地利用信息,同时也可以为政府信息提供政策作指导,提高社会福利。
猜你喜欢
公民与法治(2022年11期)2022-12-06
东方剑·消防救援(2022年3期)2022-04-01
今日农业(2020年20期)2020-12-15
小学生学习指导(中年级)(2020年12期)2020-12-04
海峡姐妹(2017年6期)2017-06-24
公民与法治(2016年18期)2016-05-17
金色年华(2016年1期)2016-02-28
中国卫生(2015年3期)2015-11-19
土木建筑工程信息技术(2013年4期)2013-10-17
中学英语园地·教学指导版(2008年3期)2008-07-15
