
基于学生在线学习行为特征的混合课程分类研究
2021-06-20 14:28罗杨洋韩锡斌
中国电化教育 2021年6期
关键词:聚类分析
罗杨洋 韩锡斌
关键词:混合课程;课程分类;聚类分析;在线学习行为;机器学习算法
一、引言
课程分类是课程本质属性的一部分,对于课程评价,课程设计和课程实施具有重要意义[1]。混合课程融合了在线与面授两种授课场景[2][3],课程设计和实施过程更加灵活复杂,为混合课程分类研究带来了较大挑战。现有混合课程分类研究主要从混合课程的技术应用、学习经历、课程目标、实施环境、实施主体以及活动组织形式等视角进行了探索[4-8],然而这些分类都无法为教师依据客观数据动态优化和管理教学提供帮助。混合课程的教学策略动态调整、个性化评价和教学预警等研究中关键问题的解决方法均指向数据驱动的混合课程分类[9-12]。本文旨在研究学生的在线学习行为聚类特征,据此提出混合课程的分类方法,分析该方法的稳定性,为帮助教师动态调整教学策略,个性化混合课程评价和学习预警奠定基础。
二、文献综述
课程分类是分析课程的本质特征,以一定的标准和方法将课程分类有助于发现课程某一方面的特点,在帮助教学设计、实施、管理、评价等方面具有重要意义[13]。混合课程是一种课程形式,已有文献从不同方面对混合课程分类开展研究,如:依据技术融入教学的程度将混合课程分为使能型、增强型、转换型;依据在线与面授的内容及方式分为面授讲解与在线学习结合型、在线讲解与面对面讨论结合型、虚拟现实模拟与结构化面授结合型、现场实习与在线引导结合型、现场培训与线上培训结合型;依据课程目标分为面向任务型、面向产品型、面向项目型等,然而上述研究都没有依据学生在线学习行为进行混合课程分类。有学者提出学生在线学习行为可作为混合课程分类的依据,当一门课程中主要学生群体的在线学习行为都属于某一类时,这类学生群体的学习行为特点就可代表该门课程的特征,据此将混合课程分为四类:很少使用学习平台类、在线协作类、在线讨论类和提交在线作业类[14],为本文探究基于学生在线行为数据的混合课程分类方法提供了借鉴与启示。目前基于学生在线学习行为进行混合课程分类的研究涉及三个方面:学生在线学习行为聚类研究、基于学生在线学习行为的混合课程分类研究和基于数据的分类稳定性研究。
(一)学生在线学习行为聚类研究
学生在线学习行为聚类研究的目标是采用某种聚类方法提取学生在线学习行为的典型特征,为下一步研究提供依据[15]。使用机器学习聚类算法开展聚类分析是一种无监督学习过程,其特点是无需数据的类别标识,通过学习样本之间的数据特征将样本划分为不同组别[16]。算法的选择是聚类研究的关键问题,K-means算法是目前进行学生在线学习行为聚类研究的常用算法,如有研究分析了学生的研究型学习行为记录,发现了4类不同能力水平的学生群体[17]。K-means算法虽然简单易实现,但不能保证在任何研究情境中都能获得最佳的学生行为聚类结果。因此需要围绕特定问题尝试不同算法,采用评价指标对比分析聚类结果的优劣,以求获得最佳聚类结果。使用聚类算法开展研究时所得结果的有效性对研究结论是否具有偏误具有重要影响[18],但在已有文献中极少报告聚类结果的评价指标[19]。本文将尝试不同机器学习算法对学生在线学习行为进行聚类,依据相关评价指标对比各种算法,获得最优的聚类结果,并分析不同类型学生在线学习的典型行为特征,为混合课程的分类提供依据。
(二)基于学生在线学习行为的混合课程分类研究
混合课程分类对学生评价、学习预警和教学优化都十分重要,然而以往研究的混合课程分类方法或框架未有帮助上述目标实现的功能[20]。当前为混合课程分类的研究主要从混合课程的要素构成和自身属性出发,有学者从教师在教学设计中融合技术开展混合教学模式改革角度讨论了三种课程的混合方式,分别是使能型混合,即将混合的重点放在课程的接入性和学习便利性上,使学习的灵活性最大化。增强型混合,即利用在线课程内容补充面授课程的内容,不从根本上改变课程。转换型混合,即从根本上变革课程设计,将学习者从信息的接受者变更为一个可通过动态交互自主建构知识的模型。该分类能够指导教师在混合课程中整合技术,帮助学生更好的学习,但对学习预警没有帮助。还有学者从学习经历的角度出发也定义了一种二维的混合课程分类方法。该方法的两种维度分别是传递信息的中介以及课程内容的属性。在不同的维度下混合课程的核心学习活动会有极大差异。具体来说,为适应教师的教学目标,满足学生的学习偏好,即使是相同的混合课程也有可能在课程设计的呈现方式和知识偏好上有所不同,从而引导学习者出现相应的学习活动。该分类框架虽然面向学生的学习经历,但没有关注学生在混合课程中的学习投入特征,无法为学生评价和课程评价提供帮助。另外还有研究分别从混合课程实施环境、课程实施主体以及课程活动組织形式的视角提出了混合课程分类方法。以上分类方法没有涉及师生在混合课程实施中的教学活动特征,对教学优化、学习预警、学习评价等研究没有直接的指导作用。
近年来有学者提出学生在线学习行为可作为混合课程分类的依据,并通过记录的学生在线学习行为数量进行了标记,区分学生在不同在线学习行为指标中的活动特征,以此划分不同类别的混合课程。该研究认为基于学生在线学习行为的混合课程分类可反应出混合课程的真实运行状态,帮助院校管理者干预混合课程的实施状态,并通过网络教学平台为混合学习提供更好的支持。该方法从混合课程实施过程的数据出发,提出了一种将学生在线学习行为特征转化为混合课程分类方法的思路,且该方法关注不同学生在线学习行为的特征,为后续研究基于客观数据的动态教学管理、个性化评价和学习预警奠定了基础。可以看出,以往的混合课程分类研究只有少量从过程数据的视角开展研究,虽有学者基于学生在线学习行为数据对混合课程分类,但该分类方法的稳定性如何尚不清楚。
(三)基于数据的分类稳定性研究
采集学生在线学习行为数据并以此为依据为混合课程分类,是一种依赖数据的分类方法。这种分类的目标是从样本数据中提取一个分类函数或分类模型,当有新数据时根据已有分类函数或模型将新数据映射到给定类别的某一类中[21]。这种分类方法通常要面临新数据加入后分类稳定性的问题。好的分类方法应具有良好的稳定性,稳定性是指分类方法可以适用于构建分类方法相似的新数据,并将新数据完整分入每个类别中,且每个类别内部的数据特征类似[22]。机器学习领域的学者指出,在数据集不平衡的情况下,分类器可能出现部分样本分类准确率高而另一部分样本准确率较低的情况[23]。从混合课程中提取的学习过程数据一般是不平衡的,然而混合课程样本各部分分类准确率差异较大的结果则是不可容忍的。类似的问题在数据科学研究中也引起了学者的关注,且一直未取得突破性的进展[24]。
三、研究问题及研究方法
本文根据以上文献分析提出以下研究问题:
问题1:采用何种算法才能获得最优的学生在线学习行为聚类结果?每类学生在线学习行为的典型特征什么?
问题2:基于学生在线学习行为特征对混合课程进行分类的结果是什么?
问题3:基于学生在线学习行为特征的混合課程分类方法的稳定性如何?
选择某高校2018年秋季学期的2456门混合课程和2020年春季学期的1851门混合课程中学生的在线学习行为日志为研究样本数据。其中,2018年秋季学期的数据用于构建基于学生在线学习行为的混合课程分类方法,2020年春季学期的数据用于检验基于学生在线学习行为的混合课程分类方法的稳定性。
研究过程与方法如下:(1)收集数据和预处理阶段,收集2018年学生在线学习行为日志,将日志转换为学生学习行为数据并对行为数据进行预处理;(2)学生在线行为聚类阶段,采用聚类分析研究学生在线学习行为,得到不同聚类标签的学生群体;(3)混合课程分类阶段,分析每门课程中的学生在线学习行为,尝试使用课程中包含的学生聚类标签为课程分类,取分类准确率最高的标签作为课程分类结果,将相同分类的课程归为一类,分析每类课程特征;(4)混合课程分类验证阶段,使用2020年新数据验证课程分类方法的稳定性。
(一) 收集数据和预处理阶段
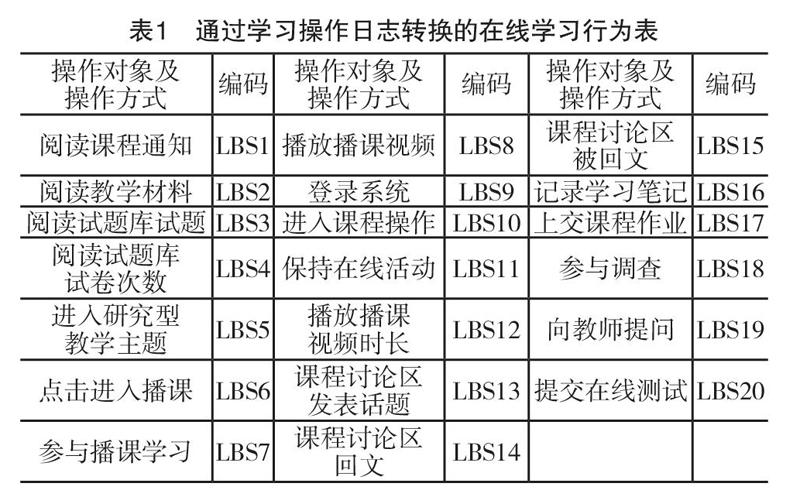
本研究中的学生采用优慕课?综合教学平台V9开展混合课程的在线学习活动。网络教学平台中存储的日志数据记录了学生的学习行为,按照学习者对网络课程各模块的操作方式分离日志中的行为数据,再按频次和时长累积计数[25][26]。据此得到的一条数据包含一名学生在一门课程中一个学期的历史在线学习行为。为使用机器学习算法识别上述数据项,对每项数据进行编码,形成的学生在线学习行为数据集编码如表1所示。
从表1中可以发现当学生使用网络教学平台时,数据项都具有不同的量纲。且数据项内部存在嵌套关系,如,生生交互学习活动中,若学生课程讨论区中被回复的计数,则在课程讨论区中发表话题计数至少有1,但反之则不然。为消除数据项之间量纲的差异及数据项之间的嵌套问题,在聚类分析前需对每一个在线学习行为数据字段进行最大值最小值归一化处理。通过最大值最小值归一化操作后,各项数据都在保留其代表学生在该操作中与其他学生差异特征的前提下,减小了数据的离散化程度,增加了数据的内聚性。经过简单探索发现,虽经过归一化处理,样本集中仍然存在大量极值,这些具有极值的学生并非均匀分布在每一门课程中,且极值也不是简单聚集在某几项行为中,因此在预处理时没有删掉样本集中具有极值的学生行为数据。经过上述数据处理后,将2456门混合课程中的学生行为日志处理为229796条行为数据。
(二) 学生行为数据聚类阶段
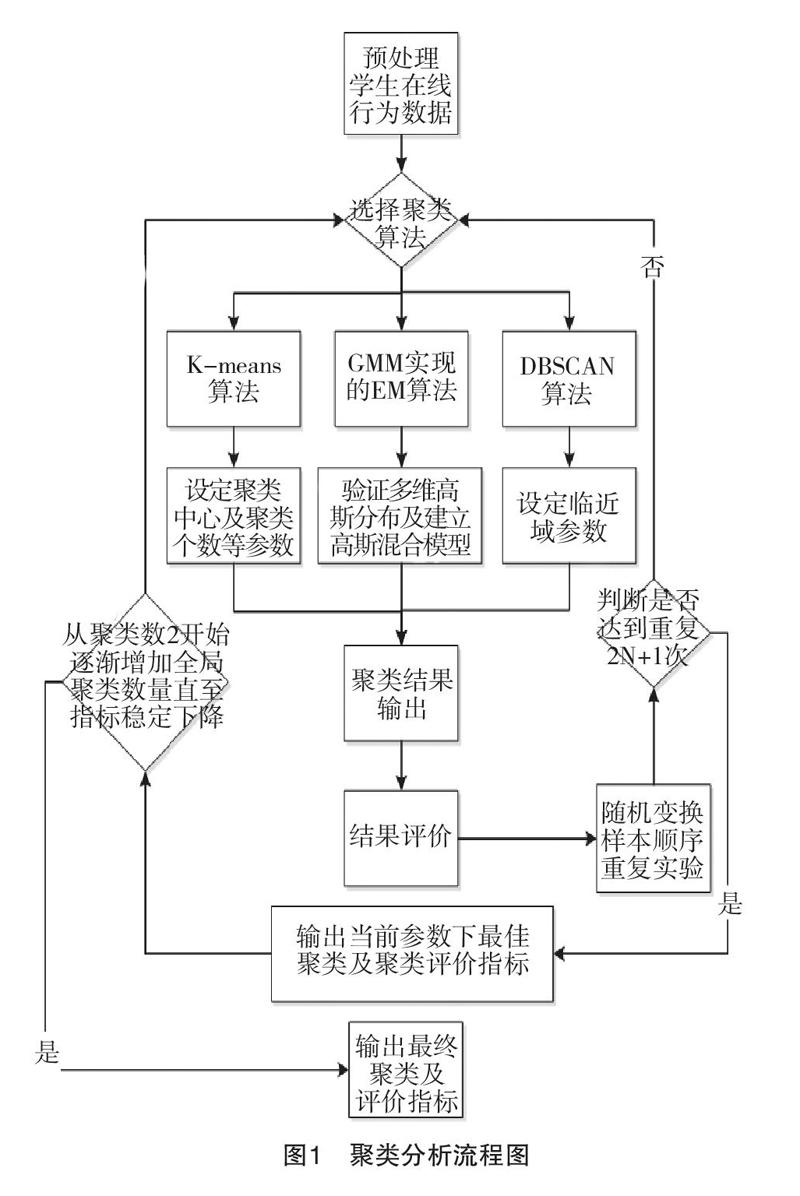
为识别学生的在线学习行为特征,聚类分析将在线学习行为数据作为输入项,聚类分析流程如图1所示。
为获得学生在线学习行为最优聚类,研究分别选取了三类聚类方法中最具代表性、应用最多的典型算法:K-means聚类算法(KM)、GMM实现的EM聚类算法(EM)和DBSCAN算法。研究采用python语言中的scikit-learn数据挖掘工具包开展聚类分析处理。虽然EM算法和DBSCAN算法都无需设定聚类个数,但通过设定聚类个数可比较不同聚类算法聚类结果的优劣,因此每项聚类算法的起始聚类个数从2开始并逐渐增加聚类个数(设为N),直到聚类的倾向指标霍普金斯统计量(Hopkins Statistic Index,HSI)显示聚类分离明显,无需继续划分聚类为止。完成三种聚类算法的参数设定后,为得到不受样本顺序影响的聚类偏差,每种聚类算法在完成参数设定后都会重复运行当前聚类设定的两倍加一次(2N+1),每次运行聚类算法前样本顺序会进行随机变换。每次聚类算法执行后,记录聚类结果和聚类评价指标。在重复聚类完成后样本点的聚类标签以标记标签占多数的情况决定,如某学生的学习行为在KM算法设定为2个聚类时,重复5次有3次为第一类,其余2次为第二类时将该学生记录为第一类。对聚类结果的评价指标则以所有重复次数完成后的平均值表示。
(三)混合课程分类阶段
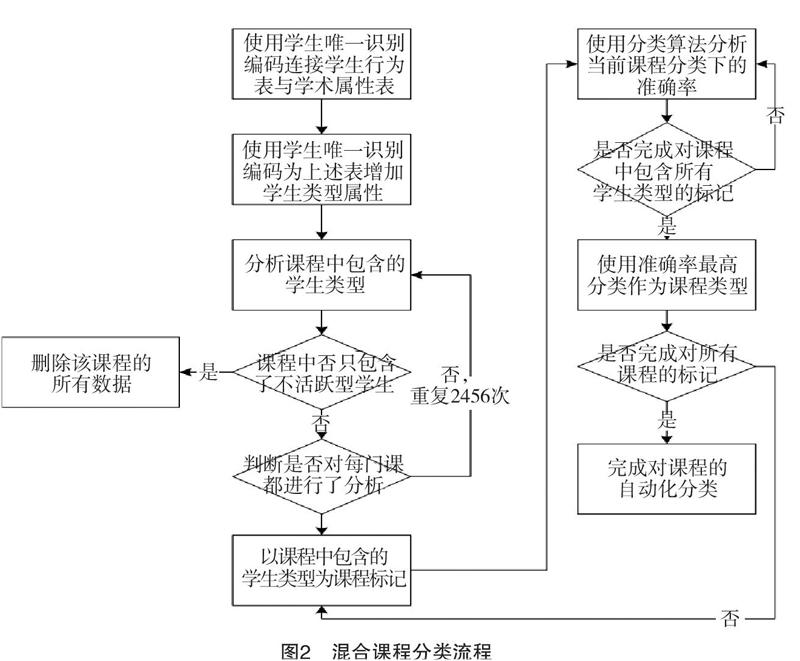
使用混合课程的学生在线学习行为及每类学生的聚类标签为混合课程分类的基本思路是:首先,将学生的行为数据表与学生的聚类标签连接,得到每一门课程中包含的各类学生。然后分析每一门课程中各类型学生的聚类特征,去除只包含不活跃类型学生的课程。最后以课程中包含的学生类型依此为课程标记类型,用分类算法确定分类准确率最高的类型作为该课程的类型(如图2所示)。
课程的分类流程衔接和其中的每一步都可以使用程序自动完成。在具体流程中删除只包含不活跃型学生课程。在将学生类型作为标签对课程进行标记时,执行步骤是首先以课程中其中一类学生的类型作为标签进行课程标记。然后采用分类算法,以该课程中标记的学生行为数据和聚类标签为输入项对当前标记的课程进行分类,并记录分类准确率。分类准确率以标记正确的个数占课程标记的总数百分比计算,每次选出不同的学生类型标记课程,并记录分类准确率,直到课程中不再有其他学生类型。比较每种类型标记课程得到的分类准确率,以准确率最高的类型记录课程分类。对课程进行分类时采用随机森林算法,并采用5折交叉检验。为保证课程分类不受课程中学生数据的顺序影响,每门课程采用随机森林算法完成分类后会通过重新乱序排列课程中的学生数据并重复10次。最终获得混合课程分类结果。
采集上述高校2020年春季学期的1851门混合课程中的学生行为日志,重复收集数据和预处理阶段、学生行为数据聚类阶段和混合课程分类阶段的所有操作,分析混合课程分类方法对新数据分类的稳定性。
四、研究结果与讨论
(一)学生在线学习行为聚类的算法选择及其结果分析
本研究采用4个指标评价聚类结果:聚类轮廓系数(Silhouette Score,SI),聚类紧密度(Calinski-Harabaz Index,CH),戴维森堡丁指数(DaviesBouldin Index,DBI)和霍普金斯统计量(HopkinsStatistic Index,HSI)。SI度量聚类中同类样本之间的距离与该类樣本和其他类样本之间的距离的比值,该值越接近1则聚类结果越好;CH度量聚类中心点和全部样本的中心点平方和(分离度)与聚类中的样本和聚类中心的平方和(紧密度)的比值,数值越大则聚类结果越好;DBI量化每个聚类之间的最大相似度均值,该指标越接近0则聚类结果越好。HSI用于评价聚类个数是否最优,该指标使用数据样本所构成的向量空间判断其中的数据分布类型,当该指标越接近1时则样本聚类个数越趋近于最优[27]。
使用三种聚类算法对2018年混合课程和2020年混合课程中学生在线学习行为数据进行聚类,每项聚类算法的起始聚类个数从2开始逐渐增加,当个数达到8时,倾向指标HSI显示样本随机化明显,无需继续增加。表2呈现了三种聚类算法聚类个数为5时所得结果在4个评价指标上的取值。表中第1列是三种算法,如KM5即代表采用KM算法将学生在线学习行为数据聚类为5类;第2—5列显示的是某种算法将2018年混合课程中学生在线学习行为数据聚类在4个评价指标的值,而6—9列则是2020年数据聚类的评价指标取值。
观察表2可知,2018年与2020年的混合课程学生数据都在聚类为5类时,结果最佳。且EM算法和KM算法的聚类结果在4项评价指标的数值上差异不大。因此选择这两种算法将在线学习行为分为5类是最优结果。
根据上述聚类结果将2018年混合课程中的学生分为五个类别,每个类别学生的20项在线学习行为指标的均值和标准差如表3所示。
从图3中可以看出五类学生在线学习行为有非常明显的区别,其典型特征如下:
(1)聚类编号为0的学生在线活动非常少,在表征学生在线学习行为的20项指标中,有17项均值为0,只有3项指标均值大于0.001。据此将该聚类编号的学生命名为“不活跃型学生”。
(2)聚类编号1的学生相比聚类编号0的学生活跃,但没有一项在线学习行为指标数据的均值高于其他类,有12项指标的均值小于0.01,其中8项为0。据此将该聚类编号的学生命名为“低活跃型学生”。
(3)聚类编号2的学生在线学习行为集中在两项活动上,他们的上交课程作业(LBS17)和保持在线活动(LBS11)两项指标均值是最高的,同时该类学生几乎没有其他在线学习行为,有13项小于0.001。据此将该聚类编号的学生命名为“任务型学生”。
(4)聚类编号3的学生更加关注视频材料的学习,点击进入播课(LBS6),参与播课学习(LBS7)、视频观看时长(LBS12)、记录学习笔记(LBS16)和提交在线测试(LBS20)等指标均值是所有类别中最高的,其他指标中只有3项均值小于0.01。据此将该聚类的学生命名为“阅览型学生”。
(5)聚类编号4的学生在线学习行为特征是其大多数行为指标均值最高,在21项指标中的12项均值是最高的。据此将该聚类的学生命名为“高活跃型学生”。
各类型学生在所有学生中的占比分别为,“不活跃型学生”77%,“低活跃型学生”15%,“任务型学生”6%,“阅览型学生”1%,“高活跃型学生”1%。
(二)基于学生聚类结果分类的混合课程特征
采用第三节中所述方法将所有课程进行分类后,基于学生在线学习行为典型特征,可获得每门课程按照其包含学生类型标签的准确率列表。表3显示部分课程通过分类后得到在五种学生分类标记下的结果准确率。
从表3中可见采用分类算法对不同课程依据学生典型行为标记为五种类型后,其准确率存在差异,将准确率最高的类别作为该课程的类别标记。将每门课程标记完成后,同样标记的课程归为一类,可得到每个课程类型包含学生的占比分布图(如下页图4所示)。
分析每类混合课程中的学生占比构成,可发现每类课程的典型特征如下:(1)有1403门课程被分类为不活跃型课程中,该类课程中不活跃的学生占83.2%,任务型学生中占13.5%,而剩余的3.3%学生则分布在低活跃型,阅览型和高活跃型三类学生中。说明不活跃型课程中,不活跃型学生都占大多数。不活跃型课程在每个学院中均有出现,且在体育学院和外国语学院开设课程中占比较高。
(2)有113门课程被分类为低活跃型课程中,该类课程中有58.1%的学生是低活跃型,17.1%的学生属于任务型,不活跃型学生占12.2%,高活跃型学生占10.8%,阅览型学生占1.7%。低活跃型学生占大多数。低活跃型课程只在全校27个开课学院中的10个学院中出现,同样在外国语学院开设课程中占比较高。
(3)有880门课程被分类为任务型课程,该类课程中有73.7%的学生属于任务型,15.5%的学生属于不活跃型,低活跃型学生占5.1%,高活跃型学生占4.3%,阅览型学生占1.3%。任务型学生占大多数。任务型课程分布在22个开课学院中,且在计算机科学与技术学院开设课程中尤为集中。
(4)有38门课程被分类为阅览型课程,该类课程中有56.7%的学生属于阅览型,有19.2%的学生属于低活跃型,12.2%的学生属于任务型,10.9%的学生属于高活跃型,1.1%的学生属于不活跃型。阅览型学生占大多数。阅览型课程只出现在3个开课学院中,且主要属于建筑工程学院开设的课程。
(5)有22门课程被分类为高活跃型课程,该类课程中有高活跃型学生72.9%,有15.7%的学生为低活跃学生,4.5%的任务型学生,3.88%的阅览型学生,3.55%的不活跃型学生占比。高活跃型课程主要集中在生命科学院、电气与电子工程学院和法学院开设课程中占比较高。
本研究结果与以往研究者的结论相比,分类结果同样发现了有大量混合课程属于不活跃型,但从方法上来看,本研究实现了无需人工干预的自动化混合课程分类。
(三)基于学生在线学习行为聚类特征的混合课程分类方法的稳定性
在采用学生在线学习行为聚类结果为混合课程分类时,学生行为聚类结果的稳定性也会影响混合课程分类的结果。好的分类方法应具有良好的稳定性,稳定性是指分类方法可以适用于构建分类方法相似的新数据,并将新数据完整分入每个类别中,且每个类别内部学生学习行为特征类似。本文对比分析了2018秋季和2020春季两学期学生行为的聚类结果,结果发现2018年与2020年的混合课程中各聚类编号下的学生在线学习行为特征相似。说明依据学生在线学习行为聚类特征对混合课程分类时两学期的聚类特征较为稳定,为混合课程分类方法的稳定性奠定了基础。依据2020年学生在线学习行为聚类特征为混合课程分类后,可获得不活跃型课程(841门),同样在每个学院中均有出现,主要集中在体育学院中;低活跃型课程(232门),该类课程较为平均的分布在每个学院中;任务型课程(314门)该类课程分布在16个开课学院中,同样在计算机科学与技术学院开设课程中尤为集中;阅览型课程(413门)该类课程分布在18个学院中,除建筑工程学院外,还集中在材料科学与工程学院及交通与车辆工程学院开设的课程及高活跃型课程(51门)该类课程除集中在2018秋季学期的三个学院外还新增了管理学院和数学与统计学院。研究进一步对比了2018年混合课程各类学生构成与2020年混合课程各类学生(如图5所示)。
对比图4和图5可知,依据学生在线学习行为聚类特征分类后依然可将2020年的全部混合课程分类到五类课程中,且每类课程的典型特征一致。
由此可见,基于学生聚类特征的混合课程分类方法完整的将某高校2018年秋季学期的混合课程与2020年春季学期的混合课程分入了五个类别之中,每个类别的典型特征相同,分类标准和结果并未因样本数据不同而变化。本研究首次通过相同学校的不同学期数据验证了基于学生在线学习聚类特征的混合课程分类方法的稳定性。
五、研究结论及教育意义
混合课程情境下,如何依据学生在线学习行为进行分类,是解决混合课程动态优化、管理,个性化评价及教学预警的基础问题。本文提出了一种依据学生在线学习行为特征对混合课程进行分类的方法,结果表明:(1)该方法首先通过机器学习算法对混合课程中的学生在线学习行为进行聚类并分析每类学生的典型特征,依据学习行为的典型特征将混合课程分为可以自动识别的五种类型:不活跃型课程、低活跃型课程、任务型课程、阅览型课程和高活跃型课程;(2)采用该方法对同一个高校两个学期的混合课程进行分类,结果都归入了五个类别之中,且每类课程中学生学习行为的典型特征相同,由此验证了该方法具有良好的稳定性;(3)该方法不依赖人工事先标注,便于计算机自动化分类,能发现课程中的学生群体行为特征,分析学习过程差异,为教师动态设计、管理混合课程,及时预警学生,实现个性化混合课程评价奠定基础。
本研究将学生行为特征转换为混合课程的分类依据,获得了五个类型的混合课程,具有良好的通用性,适用于不同院系、不同学科、不同教师、不同规模的课程,对教学实践具有以下指导意义:
(一)精确指导混合课程建设和实施
本研究发现在案例院校4307门混合课程中有大量课程仍属于不活跃型(52.1%),这些课程还处于混合教学实施的早期阶段[28]。从开课学院来看,体育学院并不适用于传统线上线下结合的混合课程,学院需进一步分析体育类课程的特点,建设适合的线上教学内容,探索适用于体育类课程特点的线上教学形式。低活跃型课程则显示出传统面授课程向混合课程改革过渡的特征,说明这些课程中的师生正在积极尝试混合课程。院校管理者需加强这类课程的管理,防止师生因片面理解混合课程的意义,将教学撕裂为线上和线下互相独立的活动,导致教学效果降低的问题。阅览型和任务型课程则几乎全部出现在工科学院开设的课程中,说明工科学院将混合课程的线上内容更多理解为课程呈现和任务完成的环境,还需进一步挖掘混合课程的潜力,以促进学生协作和反思能力的培养。对于高活跃型课程,管理者可以分析课程特点,总结典型经验,探索推广方式,构建教师互助体系,全面推进混合教学改革。
(二)构建更有效的学习预警体系
构建学生成绩预测模型是实现学习预警重要方法,以往研究指出不存在一种适用于所有混合课程的成绩预测模型,构建具有较高预测结果准确率的混合课程成绩预测模型前提是对混合课程分类。本文提出的混合课程分类方法依据学生的学习过程特征,构建了分类混合课程的依据,可成为按类型构建混合课程成绩预测模型,提升预测结果准确率的基础。从而帮助混合课程中对大规模学生实时预警系统的构建,提升教师和教学管理者学情分析的效率和准确率。
(三)有利于为教师动态优化教学提供依据
在混合教学实施过程中,学生的学习行为特征通常具有阶段性差异[29]。以往教师只能基于学生的历史学习过程和学习成绩,在学期末反思自己的教学过程,优化下一学期的教学。本文提出的混合课程分类方法可随时收集学生数据,发现课程中大多数学生线上学习的偏好,帮助教师动态调整混合教学策略,改变学生的线上学习状态,促进学生增加某类活动中的学习投入,按教学设计完成混合课程目标。
(四)有利于为混合课程提供个性化评价依据
以往研究指出,欠缺数据驱动课程分类方法是研究混合课程个性化评价中的瓶颈问题。分析学生学习过程数据,获取个性化评价依据有助于以评促学[30]。本文提出的混合课程方法可发现课程中存在的差异化学生行为特征,帮助研究者了解学生群体在混合课程中学习行为特征差异,发现学习群体特性,对不同学习群体开展精准的个性化评价提供基础。如对不活跃型和低活跃型混合課程,评价应重点关注线下学习过程;对任务型和阅览型混合课程,评价应关注某类学习活动的质量;对高活跃型混合课程,评价应全面覆盖学生在线学习活动。另外,本文提出的课程分类方法可帮助院校管理者分析全校混合课程的真实运行状态,在开展课程评价时,比对教学设计中在线学习的安排与课程类型的差异,从而形成数据驱动的个性化混合课程评价。
本研究结论从一所学校两个学期的数据中获得,提出的方法是否能够实现跨学校、跨平台的混合课程稳定分类还有待进一步验证。另外,基于这种分类构建的学习成绩预测模型是否具有更好的准确率也需要开展研究。
猜你喜欢
软件导刊(2016年11期)2016-12-22
科技创新导报(2016年21期)2016-12-17
对外经贸(2016年8期)2016-12-13
数学学习与研究(2016年19期)2016-11-22
商场现代化(2016年26期)2016-11-21
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
