
基于弱关系的异质社交网络推荐
2021-06-28 12:41荀亚玲毕慧敏张继福
计算机工程与设计 2021年6期
荀亚玲,毕慧敏,张继福
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
推荐系统作为一种信息过滤手段,帮助用户从大量信息中发现自己感兴趣的内容。传统推荐算法大多以与目标用户关系密切的强关系对象或者以与目标项目相似度高为标准进行协同过滤推荐,具有很好的可解释性[1-3],但强关系推荐因其本身圈子小、产生的唠叨型内容较优质内容多,往往会导致推荐的单一化[4-6]。与强关系相反,弱关系具有更为丰富的语义信息及强大的信息影响力[7,8],因此,基于弱关系的推荐,能够摆脱传统的基于强关系推荐带来的推荐类型单一、推荐项目重复性等问题。
丰富的社交网络常被建模为同质或异质结构网络,同质社交网络中节点和关系类型单一,且具有很强的不对称性和群体规模小等特征,不利于消除用户的感知偏差。而异质网络融合了更多类型的对象以及对象间复杂的交互,也可以跨网络平台融合更多丰富的语义信息。考虑弱关系的社交网络包含了很多不同类型的对象和对象之间复杂的交互。若将这些相互作用的对象建模为同质网络是很困难的,难以体现不同类型对象的特征信息差异[9],往往只能抽取实际交互系统的部分信息,或是没有区分交互系统中对象和关系的差异性,均会造成信息不完整或信息损失。因此,可以融合更多类型对象及其复杂交互关系的异质信息网络(heterogeneous information network)被引入推荐系统[10-14]。
为准确地选择推荐的主体范围及有效地利用实体间的交互信息进行有效推荐,提出一种结合弱关系的异质社交网络推荐算法,充分克服了推荐结果趋于同质性与冗余共享信息的问题。主要贡献包括:①利用用户间信任值对引入弱关系产生的大量用户节点进行有效筛选;②结合弱关系构建了一种全关系的异质信息网络模型(UI-HIN);③提出了一种最佳信任路径选择算法(BTP)。
1 相关工作
根据推荐方式的不同,传统的推荐算法主要分为3类:基于内容的推荐、协同过滤推荐和混合推荐。这些大都是建立在“强关系”上的推荐,使用“相似度系数”来衡量两个用户间的相似度,推荐具有较强的可解释性但面临着个性化缺失的问题。此外,个人隐私问题越来越受到互联网用户的关注,传统推荐方法收集用户数据越来越困难,造成“冷启动”制约推荐方法的性能,难以挖掘用户潜在兴趣。
文献[15]在用户协同过滤的基础上通过计算活动用户与少量专家用户之间的相似度作为信任值解决用户评分数据稀疏造成的冷启动问题。文献[16]提出一种融合项目特征和移动用户信任关系的协同过滤推荐算法缓解评分数据稀疏对协同过滤算法的影响,提高了移动推荐的准确度。同传统的推荐算法相比,增加的“信任”机制虽然有效地缓解了数据稀疏问题,但根本上还是以相似度作为标准来衡量信任值,并没有改变推荐的主体,推荐重复问题没有得到解决。同强关系相反,弱关系可以是双向的也可以是单向的,因为不需要较强的互动,所以维系起来成本更低,依靠“弱关系”的力量可以扩大推荐的选择范围增加推荐的新颖性,减少了唠叨型内容,使推荐更加明确。文献[17]提出一种考虑子群贡献和兴趣活跃两个因素的动态群聚合方案集成所有子组的推荐列表,以生成该组的最终结果。文献[18]提出了基于用户评分和社会关系的隐含偏好社区的推荐模型。在基于社区推荐算法中将社交网络中的用户组织成社区的形式,社区的代表性特点就是兴趣高度一致性,这种基于社区的推荐通常会使得推荐类型过于局限,不利于用户产生对新类型项目的兴趣。
为了融合更加丰富的异构信息,基于异质信息网络的推荐算法得到了广泛关注。有学者将元图的概念引入异质信息网络推荐,采用矩阵分解和因子分解机的方法进行信息融合,获取相似元图间的潜在特征,不同元图间的有用特征生成用户和项目关系进行推荐[11]。也有一些研究人员提出将意向推荐中复杂的对象和丰富的交互建模为一个异构信息网络和元路径引导的意图推荐嵌入方法(MEIRec)学习意图推荐中对象的嵌入[12]。已有的基于神经网络的协同过滤模型(NeuACF)提取不同的元路径用户和项目的不同方面级相似矩阵,通过深层神经网络学习方面级潜在因素进行推荐[13]。基于注意的HIN嵌入元路径融合模型(AMPE)的提出,提取并学习了HIN中多个具有元路径的同质网络与注意机制融合[14]。然而,现有算法的异质网络往往又只关注异质信息,忽视了同质信息,导致推荐信息的缺失。
综上所述,弱关系可以使用户的社交网络范围会更广,接触到的内容也会更丰富,根据弱关系构建的社交网络内容比强关系产生的内容更加优质。将这种包含大量相互作用、不同类型实体的多类型网络化数据建模成异质信息网络能够充分利用网络中丰富的对象和关系的信息,使得推荐更加真实、新颖。
2 基于弱关系的异质网络推荐算法
弱关系本质上并不是强调关系的密切程度,而是信息的传递,其融合了网络中丰富的语义和交互信息,推荐的项目类型跨度较大,可以实现改善了推荐新颖性。弱关系包含用户弱关系和项目弱关系。用户弱关系是指用户之间关系并不紧密,即我们所谓的泛泛之交。项目弱关系指交互项目可能涉及不同领域,项目与项目可能没有属性上的相似性,但却同时出现在用户的历史记录里。该推荐算法首先建立基于用户弱关系的社交网络模型,借助用户间信任值筛选节点后,再引入项目节点建立异质网络模型,最后通过优化的路径优化算法选择一组最佳推荐路径。
2.1 基于弱关系的用户社交网络
社交网络被建为有向图G,G中节点代表用户,包含弱关系用户;节点Un,U′n之间的边表示关系;边上的标签代表节点间信任值V(Un,U′n),信任是不对称的(从Un到U′n的信任值不等于从Un到U′n的)。另外,没有直接信任关系的节点之间没有连接。设置最小信任阈值和最大请求长度筛选去除不符合条件的节点,建立的用户社交网络模型如图1所示。
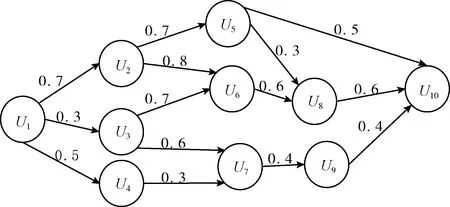
图1 用户社交网络
其中,V(Un,U′n)的获取主要来自以下信任值的结合:
(1)用户本身自带的信任值V(Un)
用户本身自带的信任值是指用户的地位、职业、资历而产生的影响力,以“法定”为支柱,可以说是一种强制性影响,我们可以分别从这3个因素考虑:
1)地位因素:根据人类传统观念,米尔拉格姆实验表明正常的普通人在权威的压力下都可以成为施虐者。大脑惰性让我们认为权威人士不同于普通人,由经验产生了对权威的服从感(比如同样是推荐一部电影,一位专业影评人的推荐比普通人更令人信服);
2)职业因素:在社会中扮演同样角色的人会产生很多必要性的推荐,不一定是用户感兴趣的,却是用户不得不用的(比如办公APP,很少人会喜欢,但又不得不用);
3)资历因素:现实生活中,人们对某领域资历较深的人更具信任感。
(2)相邻用户之间因为信息交互而产生的信任值
这种信任是指直接用户节点间的关注热度(比如微博的转发、点赞、评论、浏览),由用户行为决定。
2.2 全关系用户-项目异质网络模型
传统异质网络又只关心异质关系而忽视了同质信息,因此,通过对传统异质网络进行了拓展,引入项目节点,构建了全关系的用户-项目异质网络模型。
定义1 异质信息网络:包含多种类型的节点和边,并且具有丰富语义的信息网络。信息网络被定义为一个有向网络图G=(V,E),其中,V是所有实体结点的集合,E是所有关系边的集合。并且存在着一个结点类型的映射函数φ:V→A和一个边类型的映射函数Ψ:E→R,对于每个对象v∈V属于一种特殊的对象类型φ(v)∈A,每个链接e∈E属于一种特殊的关系类型Ψ(e)∈R,那么这种网络类型就是信息网络。当对象类型的种类|A|>1或者关系类型的种类|R|>1时,这种信息网络是异质信息网络。
定义2 关系用户-项目异质网络:一个包含(用户,用户)、(用户,项目)、(项目,项目)节点对以及节点对间不同类型关系的带权有向图G=(U,I,E(Un,U′n),E(Un,Im),E(Im,I′m),V(Un,U′n),V(Un,Im),S(Im,I′m)),其中U代表用户的集合,I代表U使用的项目集合,E(Un,U′n)代表用户与用户信任关系的有向边,E(Un,Im)代表用户与项目的使用被使用关系的有向边,E(Im,I′m)代表项目与项目关系的有向边,V(Un,U′n)代表用户之间的信任值,V(Un,Im)代表用户对项目的信任值,S(Im,I′m)代表项目间信任值。
图2为一个典型的全关系异质信息网络模型,其中,S(Im,I′m)的大小和方向由关联规则的知识确定,首先依靠关联规则挖掘频繁项集,然后根据支持度确定关联的大小和方向,具体的求解过程如下:

图2 用户-项目异质信息网络模型
(1)根据项目-项目的历史数据挖掘潜在的频繁项集,如频繁N项集{Ip,…,Ip+n,…,Ip+N};
(2)计算频繁N项集中每个项目存在条件下存在其余项目的概率S(Ip,Ip+n),S(Ip+n,Ip)
(1)
(2)
(3)特别地,针对在用户的评价矩阵中得分较高但没有出现在由(1)获得的频繁N项集中的项目,通过该项目出现在用户记录中的属性信息,挖掘具有相同属性信息的项目与其的关联,构造相应的项目-项目关联边(方向指向该项目,大小为用户评价矩阵中对该项目的平均评价值),得到相应的频繁N项集。
2.3 BTP算法思想与相关定义
异质信息网络中边的权值描述了具有直接关系的节点间不同类型的信任关系,为了挖掘具有间接关系的节点之间的推荐影响力,应用节点间的信任传递特性发现,具有间接关系的两个节点之间可能会存在一条或多条连接路径。由图1可知节点U1到U10有6条路径:U1→U2→U5→U10,U1→U2→U5→U8→U10,U1→U2→U6→U8→U10,U1→U3→U6→U8→U10,U1→U3→U7→U9→U10,U1→U4→U7→U9→U10,如果考虑所有从U1到U10的路径,虽然使用了网络中的所有可能信息,但由于节点数量的庞大,不同节点之间的信任值不同,对每一组节点对分别设置最大请求长度(MTL)和最小信任阈值(MTT),无疑增加了工作量,如果使用固定长度的路径会损失有价值信息。
定义3 最佳信任路径L:对于每条L满足RL<
BTP算法流程可分为3部分:①根据重启随机游走算法(ppr)的思想得到目标节点与其余节点的相关度矩阵,去除相关度低的节点;②对于具有相同终止节点的可能信任路径,求取它们的平均请求长度(ARL)和平均信任总值(AVT)作为最佳信任路径的筛选依据
(3)
式中:RL代表路径的请求长度,β≥0表示当路径的请求长度大于以相同节点为终止节点的路径集合的ARL时,所能接受的最大请求长度差值;RVT代表路径的信任总值,γ≥0表示在路径请求长度小于以相同节点为终止节点的路径集合的ARL时,允许路径的信任总值小于AVT的最大值;③对于从源节点到目标节点只有一条路径的情况,因为在①筛选终止节点用户时就避免了请求长度过长、信任值过小的情况,所以直接将这种类型路径作为最佳信任路径。
2.4 BTP算法描述
输入:由重启随机游走算法(ppr)得到的高相关度节点集合Tn;Tn的个数N;源或目标节点Sn
基于稳定农户的宅基地占有使用权、充分保障其在农村的基本居住权,笔者认为未来应探索建立农村宅基地差别化有偿使用制度。具体而言,一方面针对农村集体经济组织成员,要坚持首次申请无偿取得、福利分配制度,即延续当前以“一户一宅”“面积控制”为特征的初次无偿分配、永久使用宅基地制度,继续发挥宅基地使用权的保障功能,但若其宅基地使用面积超过地方规定标准,则需要缴纳超额使用费。另一方面,城镇居民或非本集体经济组织成员因买卖农村房屋而使用农村宅基地的,可以认为买方与房屋所在的集体之间建立了土地租赁关系,也应向集体经济组织缴纳宅基地有偿使用费。
输出:最佳信任路径集合PATH
算法过程:

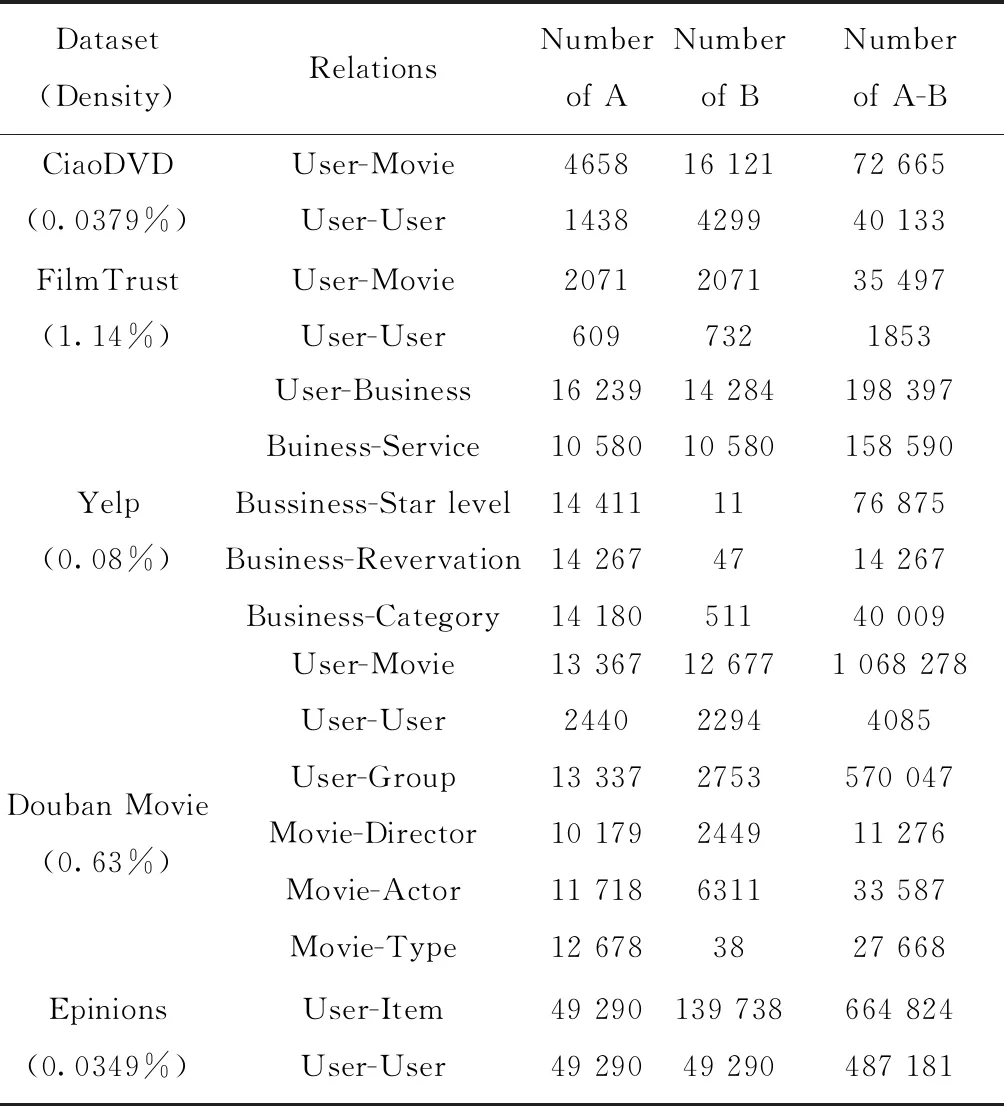
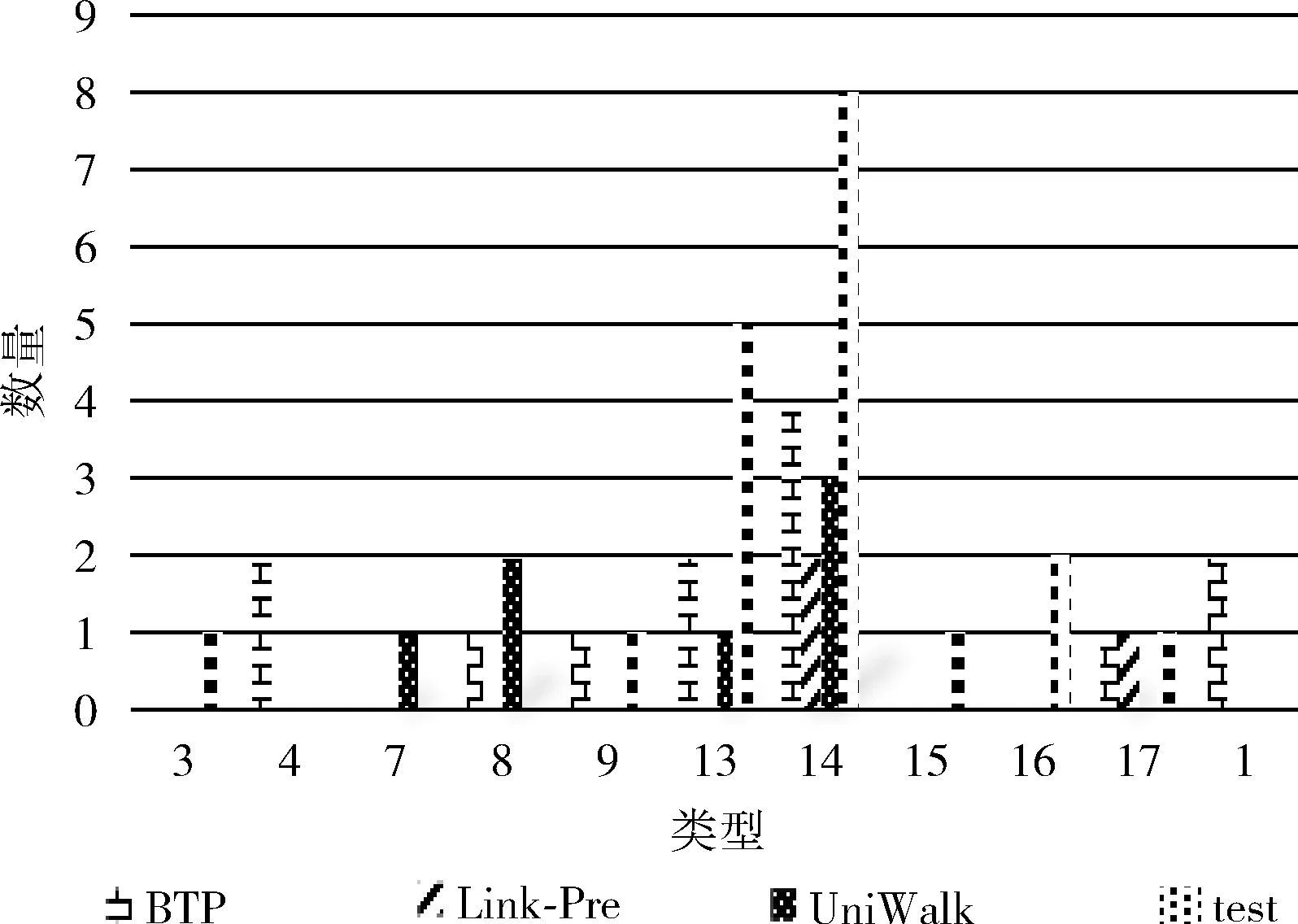
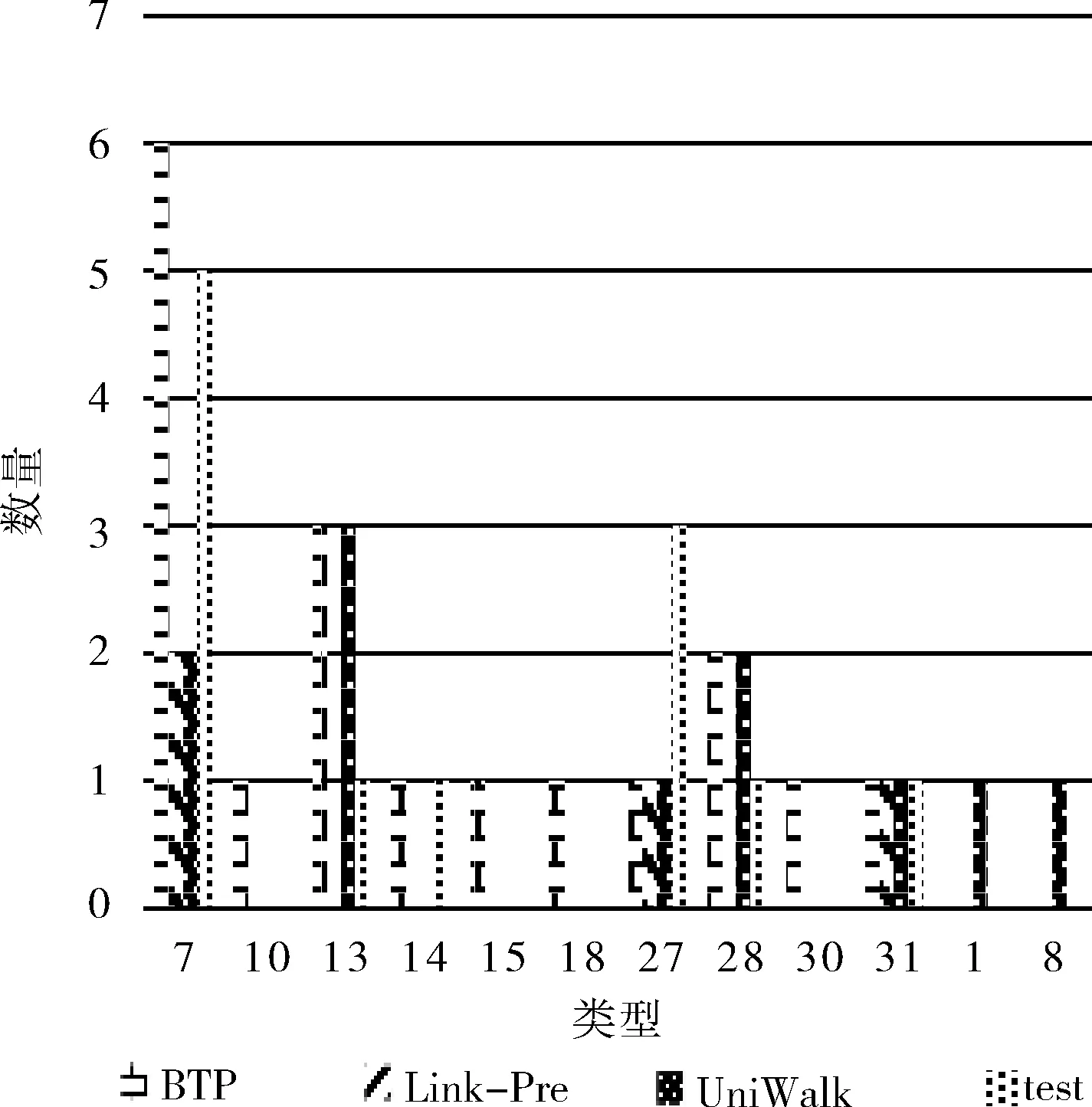
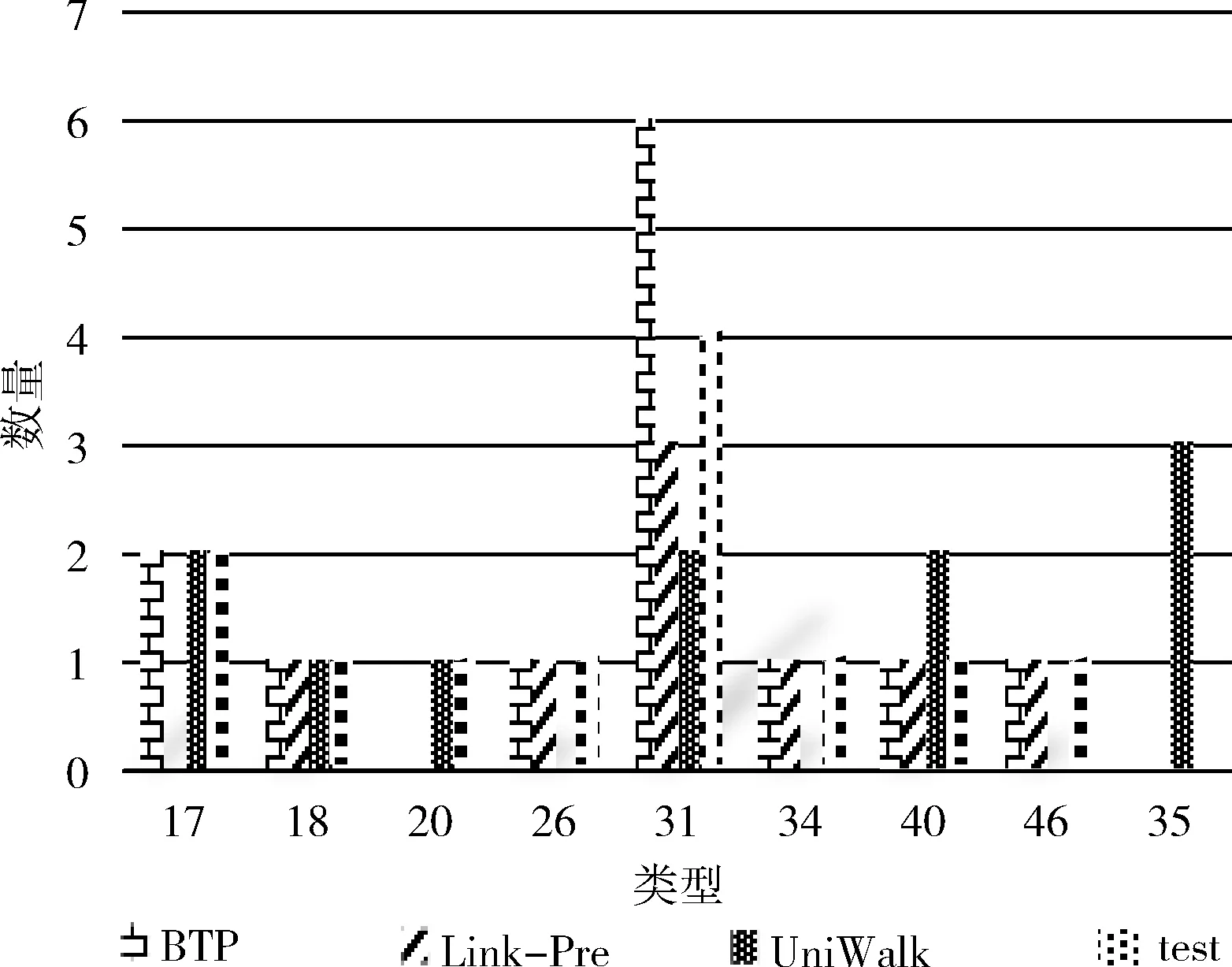
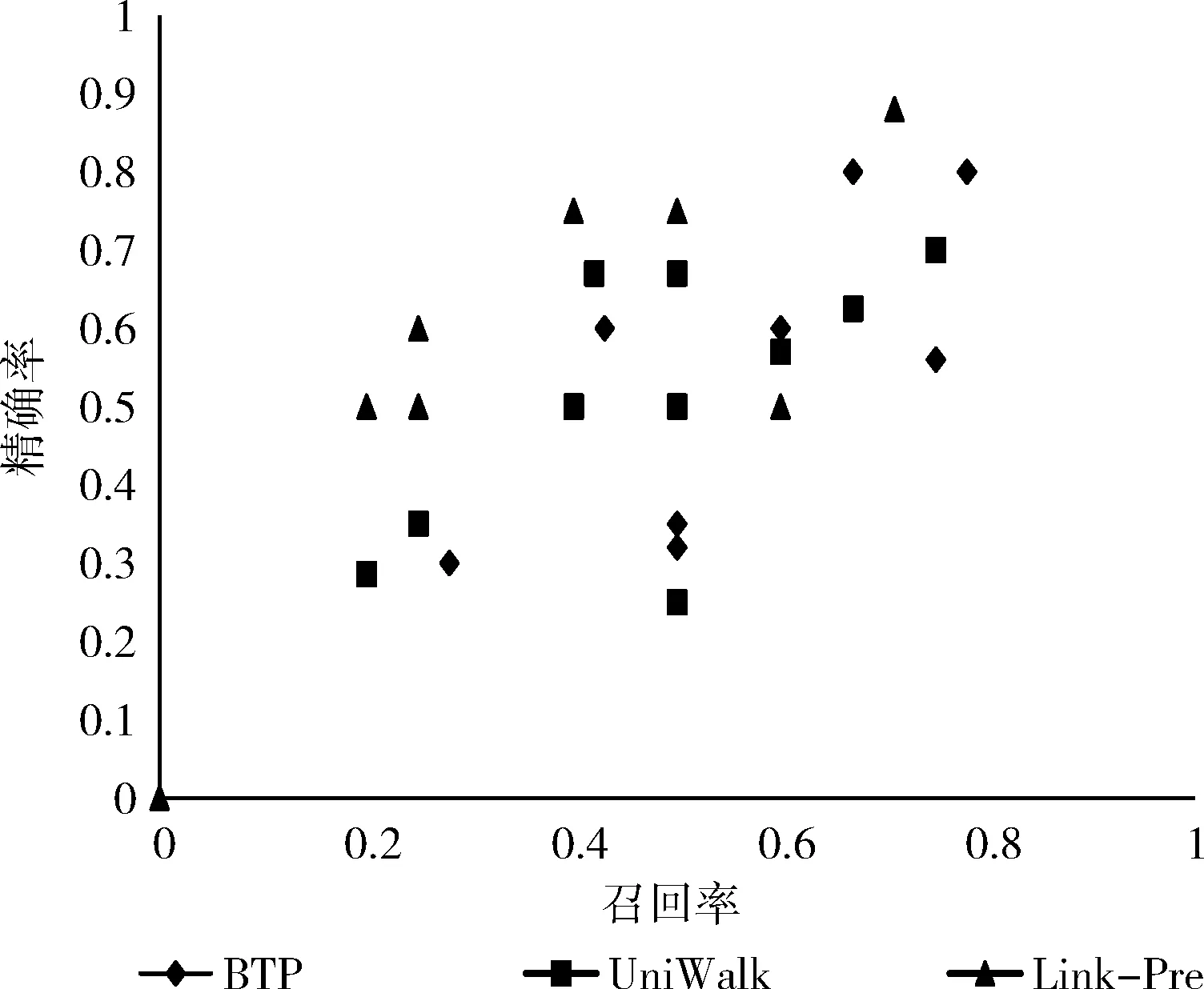
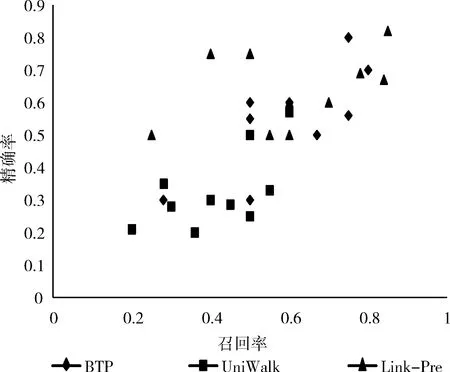
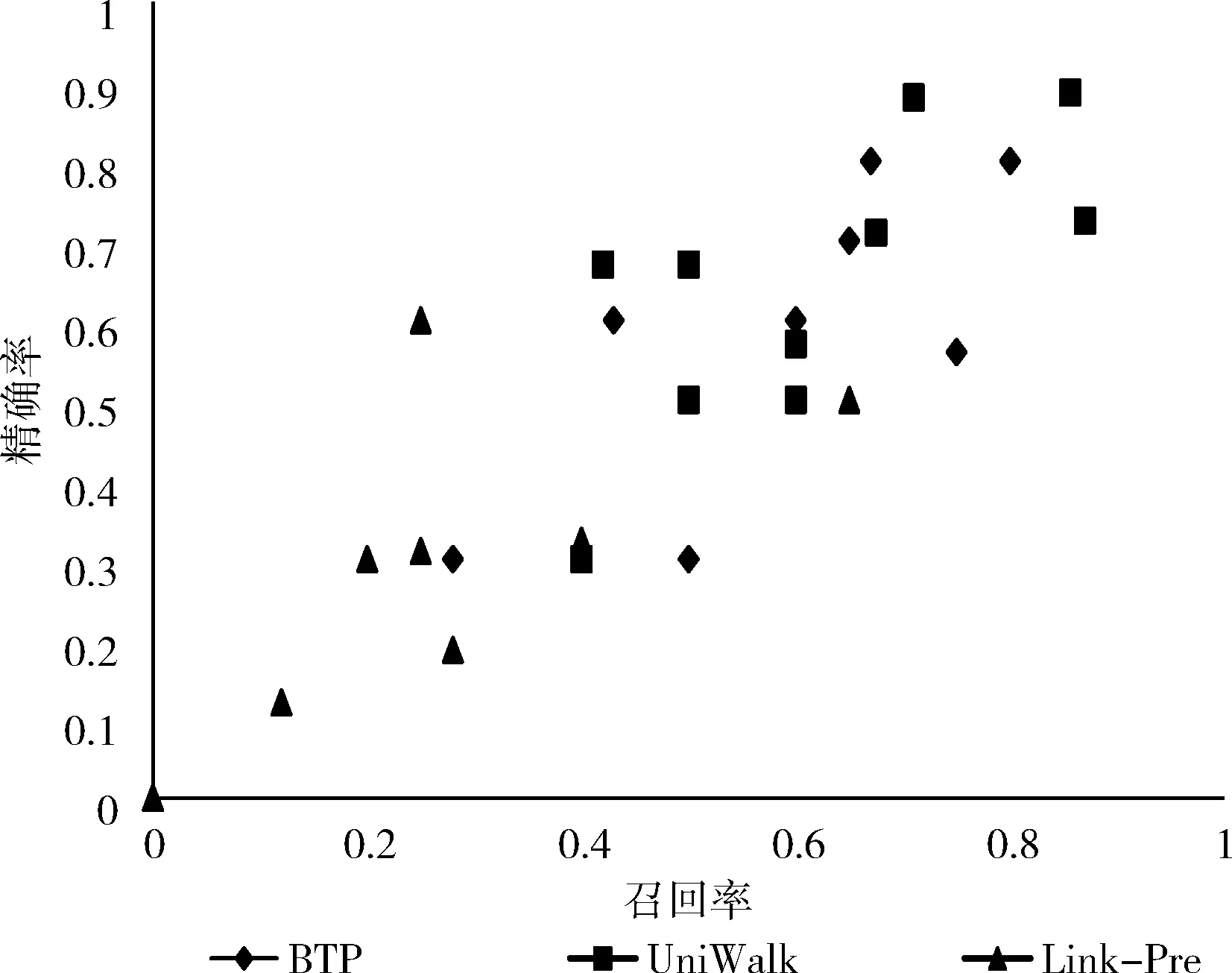
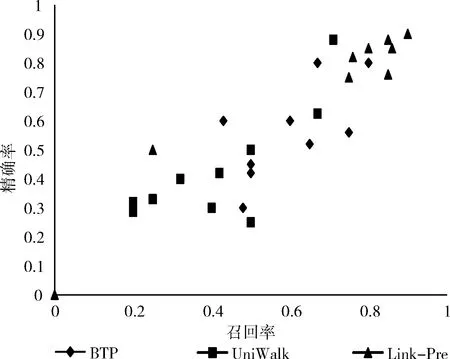
(1) EnQueue(Q,Tn); (2) For i in range(N): (3)If Q.front==Q.rear (4) return error; (5)DeQueue(Q,e); (6) ptp(Sn,e) /*ptp()用来查找得到节点e和Sn间的所有路径*/ (7) path←e; /*path存放已构路径,e为路径的起点*/ (8) R←[path, Sn]; /*R存放节点e和Sn之间的所有路径*/ (9) P=0; /*算法开始定义节点间路径数量为0*/ (10) ADJ←getadj(adj,getLast(path)); /*将已构建路径最后节点的邻居adj放入ADJ中*/ (11) For each adj in ADJ (12) if adj∈getadj(Sn) then /*若adj不属于终止节点的邻居节点则将adj加入当前路径*/ (13) add(adj,path); (14) ptp(Sn,adj); (15) else /*否则当前路径将作为节点间的路径*/ (16) add(adj,path); (17) P++; (18) R←[Sn,path]; (19) End For (20) While P /*筛选R中路径得到最佳信任路径*/ (21) if (RL>ARL&&RL-ARL≤ (22) β &&RVT≥AVT) (23) PATH←[Sn,R[p]]; (24) else if (RVT 通过动态规划求最短路径的思想确定BTP算法中的β、γ值,动态规划的思想解决的最基本的一个问题就是:寻找有向无环图(篱笆网络)当中两个点之间的最短路径,也就是各边上权值之和最小的路径。所以,先将有着相同终止节点的路径上的信任值取倒数,这样得到的“最短路径(SP)”其实就是信任值最高的路径。β,γ的值定义为 β=|getLength(SP)-ARL| (4) γ=|getValue(SP)-AVT| (5) 在5个真实数据集上实验验证BTP算法的有效性。 实验数据集包括:DVD类别数据集CiaoDVD、电影推荐网站FilmTrust、豆瓣电影数据集Douban Movie、Yelp商业数据集以及社会化电子商务网站Epinions。数据集均包含了用户对项目的评分信息和用户之间的信任信息。数据集的基本特征信息见表1,其中Dataset(Density)字段记录了数据集名称及其稀疏度,Relations表明了该数据集中的对象类型以及其交互类型,Number of A和Number of B分别对应于Relations字段的前后交互对象的数目,而Number of (A-B)表示该交互关系的交互历史记录数。 表1 数据集的统计特征 尽管用户访问推荐的某一刻,其兴趣是单一的,但用户往往具有广泛的兴趣,推荐列表的多样性将会增加用户找到更多兴趣项目的概率。而给用户推荐其以前未听说的物品,即新颖的推荐,有助于发掘长尾商品和商家的项目推广。预测准确率和召回率是度量一个推荐系统或者推荐算法预测用户行为的能力,是最重要的推荐系统离线评测指标。因此,实验从多样性、新颖性和准确率召回率3个方面进行了算法性能评价。对比算法如下: Shikhar Sharma等提出的广义复用网络的链路预测算法[19]:封装了各种异构关系,通过层与层之间的似然度量给出链路预测结果。 UniWalk:XiongCai Luo等提出基于monte carlo的方法UniWalk[20],以实现对大型图的快速top-kSimRank计算。 由于每个数据集的稀疏差异,分别设置不同的实验比率并根据数据量随机生成N个评估集,把结果取平均值作为最后的表现,其中test项为目标用户的历史行为数据。数据集CiaoDVD、Yelp和DoubanMovie包含了项目的类型信息,因此对这3个数据集实验进行推荐的多样性和新颖性评估。将Ciao DVD数据集随机分成10个评估集,分别随机抽取20%的DoubanMovie和Yelp数据随机生成10个评估集。实验结果如下。 3.2.1 推荐的多样性评估 推荐多样性要求推荐列表覆盖用户不同的兴趣领域的同时能够满足用户的主要兴趣。为了对算法推荐的多样性进行评估,我们记录实验推荐的项目类型以及每种类型的数量,并与目标用户的历史项目类型、数量进行比较。实验结果如图3~图5所示。 图3 CiaoDVD数据集的推荐多样性评估 图4 Douban Movie 数据集的推荐多样性评估 图5 Yelp数据集的推荐多样性评估 实验结果发现,3种算法的推荐列表中既包含与目标用户历史兴趣相似的项目又含有目标用户未涉及的项目。Link-Pre算法和UniWalk算法仅依据用户社交网络的历史交互记录,没有考虑用户以及项目节点之间的权值信息,使得推荐结果更加趋近于目标用户的历史兴趣。但BTP算法较其它两种算法推荐涉及的项目类型更丰富,而且考虑到了用户的主要兴趣。 实验结果表明,Link-Pre算法因为过于依赖用户历史记录导致去除与目标用户相同或相似历史项目后出现无推荐项目的情况,与BTP算法相比,虽然会出现UniWalk和Link-Pre的推荐新颖性优于BTP算法的情况,但推荐的多样性较差。 3.2.2 推荐的新颖性评估 新颖的推荐是指给用户推荐那些他们以前没有听说过的物品,而且越不热门的物品越可能让用户觉得新颖。因此,如果推荐结果中物品的平均热门程度较低,那么推荐结果就可能有比较高的新颖性。在将目标用户之前在网站中对其有过行为的物品从推荐列表中过滤掉的基础上,利用推荐结果的平均流行度进行推荐新颖性评估。实验结果如表2所示为Douban Movie数据集中编号为“288”的用户的推荐新颖性评估结果。其中,新颖性评估公式为 表2 推荐的新颖性评估数据 (6) 式中:Pop代表项目在当前数据中的用户热度(即被使用过的记录条数),Rec(U)表示推荐列表,Test(U)表示目标用户的历史项目集合,SimTest(U)表示与目标用户历史项目相似的项目集合,N表示去掉Test(U)和SimTest(U)的项目个数。 3.2.3 推荐的准确率召回率 准确率和召回率是度量一个推荐系统或者推荐算法预测用户行为的能力的重要指标,图6~图10展示了在5个不同数据集上各个算法的召回率和准确率分布。 图6 Douban Movie数据集的召回率和准确率分布 由实验结果可以观察到,进行对比的3种算法的准确率和召回率是交织在一起的,并且同数据的稀疏程度有关。Link-Pre算法的准确率和召回率在Yelp、CiaoDVD和Epinion数据集中表现较好,因其仅依赖于用户与项目的历史记录将数据分层进行链路预测生成推荐,数据稀疏时,层与层之间会出现较多的缺失链路使推荐准确率和召回率较高。反之,数据层之间缺失信息较少导致无链接预测,就会造成准确率和召回率为0。UniWalk算法在FilmTrust和Douban Movie数据集中的准确率和召回率较好是因为该为与历史记录相似的项目,准确和召回率较高,反之,准确率和召回率较低。BTP算法的准确率和召回率在5个数据集中分布较居中,这主要是因为BTP算法利用节点间的异质信息进行推荐,不同于以上两种算法,BTP算法考虑了用户对项目的评分信息和用户间的信任信息改善了数据稀疏情况下的冷启动问题,使得算法推荐既注重用户历史兴趣,又能帮助用户挖掘潜在兴趣,因此不论数据是否稀疏,推荐的准确率和召回率都亚于其它算法。 图7 Yelp数据集的召回率和准确率分布 图8 FilmTrust数据集的召回率和准确率分布 图9 CiaoDVD数据集的召回率和准确率分布 图10 Epinions数据集的召回率和准确率分布 在线社交网络日益庞大而复杂,传统基于强关系的信息过滤方式,往往注重“人脉”,导致推荐结果单一且毫无新意。融合由信任关系信息产生的用户间的信任度构建目标用户所处的异质社交网络,再综合目标用户自身的偏好和异质网络中其余节点的影响力生成推荐,为推荐研究提供了新思路。当然,异质信息推荐算法仍有继续研究和探索的空间,如考虑异质网络中相同以及不同请求长度下节点间的推荐影响,时间因素下节点间关系动态更新模型、融入社会网络中的上下文信息、探索用户间不信任关系对推荐产生的作用等。3 实验结果与分析
3.1 评估数据集
3.2 实验结果及分析


4 结束语
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
桃之夭夭B(2017年2期)2017-02-24
云南师范大学学报(自然科学版)(2015年5期)2015-12-26
中国卫生(2015年12期)2015-11-10
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
物理实验(2015年10期)2015-02-28
高中生·青春励志(2014年11期)2014-11-25
公务员文萃(2013年5期)2013-03-11
