
CNN入侵检测算法在电力营销系统中的应用
2021-06-28 12:41李东升何远成叶毓廷王先培
计算机工程与设计 2021年6期
李东升,何远成,彭 翔,杨 艳,叶毓廷,王先培
(1.国网湖北省电力有限公司 营销部,湖北 武汉 430000;2.国网武汉供电公司 营销部,湖北 武汉 430000; 3.湖北华中电力科技开发有限公司 电力营销业务部,湖北 武汉 430077; 4.武汉大学 电子信息学院,湖北 武汉 430072)
0 引 言
随着互联网+战略的提出和移动端设备的不断更新,各行各业都在不断改善服务系统为客户带来更好的移动端服务体验。在这种潮流下,国网电力营销公司提出了加速营销移动作业末端融合的方案。目前电力营销移动作业需要相关人员携带手持设备到达现场进行相关业务操作,相关人员所需要的业务数据需要通过手持设备连接服务器进行获取。然而,目前电力营销各个业务之间的服务器相互独立,作业人员在获取数据时往往需要输入多个用户密码,造成了办事的效率低下,数据无法实现共享。末端融合项目是为了构建统一的电力营销信息化系统,该系统体现为统一的服务器集群,向下,该集群内数据可以共享,向上,该集群也可以连接到其它电力系统的服务端,便于电力企业对电力营销系统的统一管理[1]。基于互联网的系统开发就一定要考虑到网络开放化所引发的安全问题:移动作业进行任务请求时,数据中心与感知系统之间需要建立大量的通信连接进行繁重的通信,在通信过程中往往会与多个网络攻击混合在一起。为了解决这一问题往往采用入侵检测技术来提高网络的安全性。
目前,机器学习在入侵检测领域获得了大量应用,基本流程是首先人为提取网络流量的特征,然后通过机器学习训练大量的样本数据来建立专家系统,最后通过测试集获得模型的识别性能[2]。机器学习不需要对数据流量特征进行建模,只需要根据数据集不断学习优化现有模型的参数,就可以得到数据流量特征之间的非线性关系矩阵。因此,适合于解决网络流量识别中的复杂非线性关系。大量科研人员对上述方法做了大量改进,并且在入侵检测预测精度上获得了巨大的提高[3]。但是,网络入侵是攻击者和防御者的博弈过程,攻击者会了解入侵检测模型的训练集所使用的特征,同时进行有针对性的调整。因此传统的入侵检测模型拥有一定的弊端。
本文结合集成学习的思想,对传统的机器入侵检测模型进行改进[4],提出了攻防式CNN入侵检测模型。在传统的机器学习方法上,考虑到人为智力因素的影响,对攻击者和防守者的成本和收益进行分析,建立斯塔克尔伯格数学模型,并且通过遗传算法寻找在模型中成本与收益的均衡点,对入侵检测模型做相应的调整,从而提高检测精度。在实验部分,将本文入侵检测算法和传统入侵算法进行比较,本文算法在识别精度上获得了很好的效果。
1 电力营销系统的容入侵模型
在电力营销系统开放和复杂的网络服务环境中,通常不能完全避免网络攻击。当系统处于开放复杂的网络环境时,其面对网络攻击的可能性大大提高。如何保证系统能够识别网络攻击并且能够生存下来,继续为合法用户提供服务就是容入侵系统设计的目标。容入侵技术是针对系统开放式网络服务而提出的一种处理入侵问题的方法,并以入侵检测系(IDS)作为该方法的触发器,保证系统在收到外界入侵攻击时仍能够为用户提供可靠安全的网络服务[5]。如图1所示,入侵容忍过程如下。
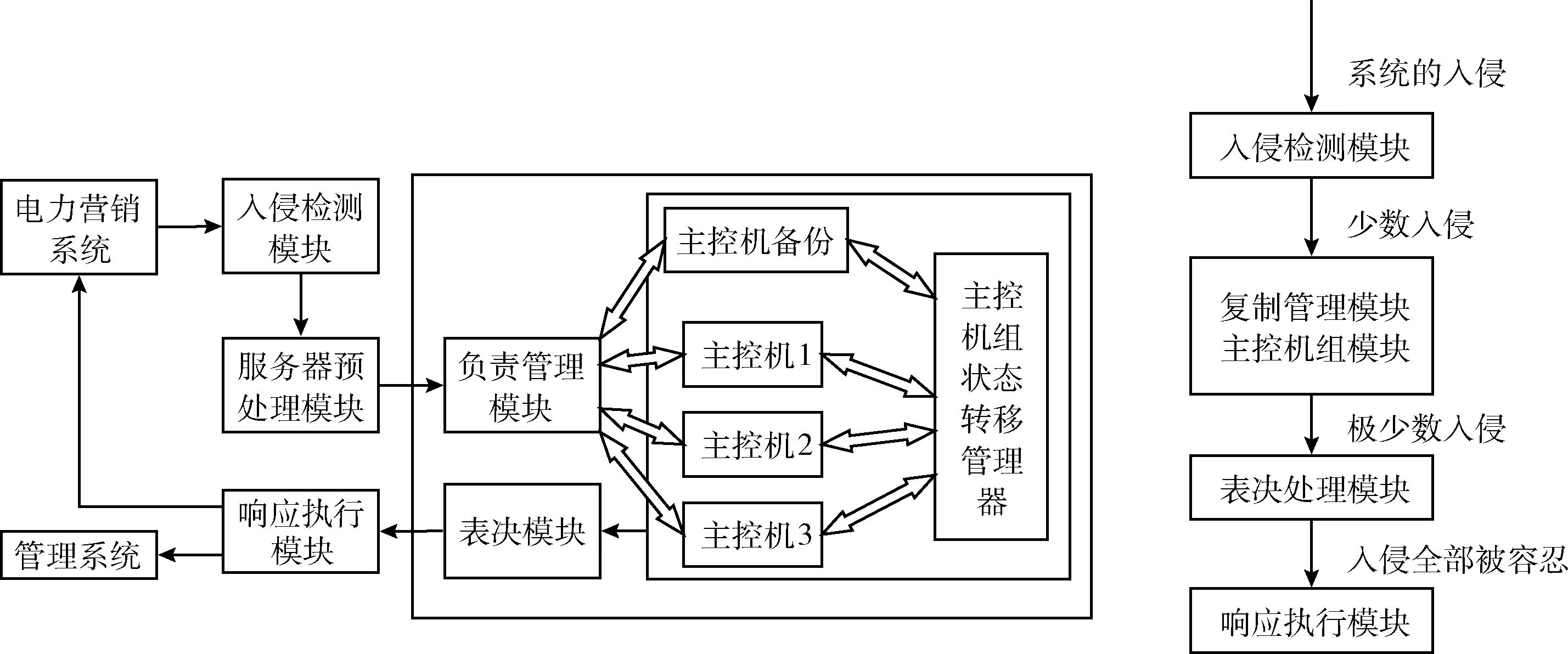
图1 电力营销系统的容入侵模型
从图1中可以看出,入侵检测模块能够屏蔽掉大多数的入侵,只有少数入侵能够进入主控机组管理模块。主控机组管理模块通过入侵检测技术和状态转移管理,对被发现有入侵的主控机进行隔离,实现一次容入侵处理,只有极少数入侵能够通过安全漏洞并产生非崩溃式错误输出。最后,通过表决处理模块,实现对非崩溃式错误输出结果的容入侵处理,最终实现入侵完全被容忍。因此,良好的入侵检测模块可以防御住大部分来自网络的入侵攻击,大大增加系统的安全性。
2 卷积神经网络
目前,已有大量学者开展了基于深度学习的入侵检测方法。Shone等使用多层非对称深度自编码器(SNDAE)进行了非监督特征学习,并结合随机森林(RF)算法进行入侵检测[6];Kim等使用深度神经网络(DNN),来检测高级持续性威胁(APT),在DNN中引入RELU激活函数在保证每层网络非线性关系的同时降低网络的稀疏性,缓解了模型过拟合问题;Javaid等构建了STL入侵检测方法,该方法在数据预处理中采用稀疏自编码器,在识别精度上得到了不错的提升[7]。Dong等将基于浅层神经网络和基于深层神经网络的入侵检测技术进行了对比,发现基于深层的入侵检测技术在多个识别指标上都取得了更好的结果[8]。
本文采用计算机视觉领域常用的卷积神经网络(CNN)算法,卷积神经网络是近年来发展起来,它一开始是为了解决复杂的图像识别,后来相关人员将卷积神经网络应用在语言识别方面上,取得了不错的成果。现在CNN已经成为许多数据识别领域的研究热点之一,为了避免传统分类算法中复杂的数据前期处理和繁多的网络模型权重数量,CNN设计的卷积网络层用于识别二维形状,结合能够提取出各种特征的通用卷积核,可以对二维图像中的各种抽象特征进行提取[9]。CNN结构如图2所示。
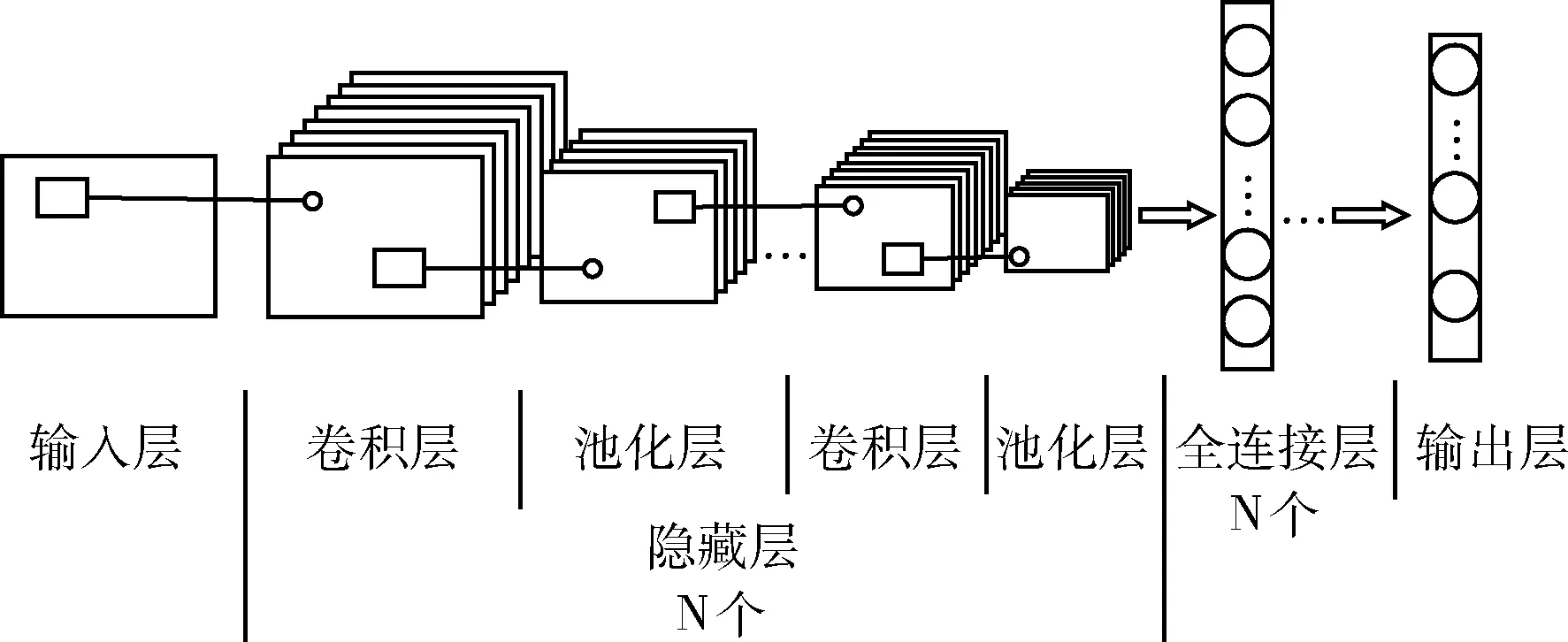
图2 卷积神经网络结构
如图2所示,卷积神经网络包括多个数据处理层,每层在识别过程中分别承担着不同的功能。深度卷积网络的卷积层、池化层和全连接层的个数一般大于1个,著名的LetNet5卷积模型共7层,其中包括了3个卷积层[10]:第1层卷积层用于提取低层次的简单特征即边缘特征,第2层卷积层,将简单特征组合成复杂一点的特征,第3层,将第2层的特征组合起来得到更加准确的识别效果。
3 攻防式CNN入侵检测模型
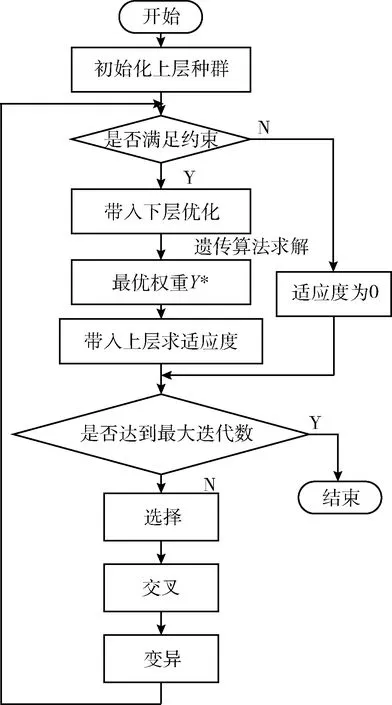
使用机器学习算法进行入侵检测时通常结合集成学习方法来提高泛化性能[11]。因此本文根据这个思想提出了基分类器的概念。网络中,各种实时的数据流量特征是在不断变化的,这种变化对于仅有单分类器的入侵检测模型而言,会对识别精度产生不可预测的影响。为消除这种影响,我们为每个网络流量特征都训练一个基本分类器。本文定义基分类器为:将数据集的每条网络流量去除一个特征,将余下的特征输入到CNN模型中,得到的多个分类器,表示为C=(c1,c2,…,ci,…,cn),其中ci代表将数据集中的第i个特征去除后训练得到的分类器。我们定义yi为基分类器ci的权重,该权重表示每个特征对入侵检测系统识别精度的影响程度。最后通过权重矩阵Y=(y1,y2,…,yi,…,yn)对所有基分类器的结果做进一步处理。具体流程如图3所示。
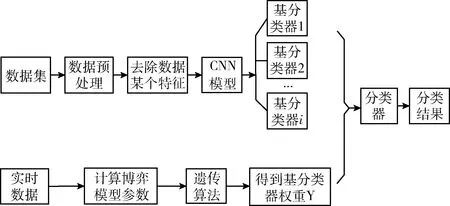
图3 攻防式CNN模型流程
攻防式CNN入侵检测模型流程如图3所示,其中,数据预处理模块是对数据集进行特征提取,特征提取完成后需要对数据进行归一化和标准化的处理,保证量纲不对识别精度产生影响。图3中的CNN模型采用深层网络检测的数据集进行分析,从而获得识别率较好的基分类器。
假设机器学习使用网络流量集所选取的特征数量为n,定义θ为数据流量的数据集,对于每一条流量数据S∈θ。我们把每条网络流量数据写成一维矩阵模式,形式如下:S=(x1,x2,…,xi,…,xn),其中xi是网络流量的第i个特征。
基分类器定义后,接着建立斯塔克尔伯格模型。该模型用于在入侵检测中攻防双方博弈中找到均衡解。模型主要依据的是,在入侵检测的博弈的过程中,攻击方如果想要通过检测,会对数据流量特征做适当的更改;防御方如果想要识别出攻击方的更改的流量数据则需要对训练好的机器学习模型进行权重调整。模型的建立分为下面3个部分。
3.1 攻击方模型
建立攻击方模型就是得到攻击方的成本和收益的函数表达。攻击者为了使自己的网络流量不被分类为异常攻击,需要对网络流量的特征做出更改,网络流量特征值的改变同时会影响入侵攻击的效果。例如:KDD-99数据集中的serror_rate特征表示2 s内,出现“SYN”错误连接的百分比,如果减少该特征的值,攻击者的Dos攻击可能通过检测但入侵效果会大大降低。因此,在此基础上,我们定义攻击方的攻击成本costa为数据S的n个特征值变化的平均值,即
(1)
上述公式只是对于已经归一化处理过的数据的计算方法,但是对于很多网络数据并没有归一化,从而对识别精度造成很大影响。因此本文选择离差标准化法,对攻击成本做进一步描述:攻击方将网络流量S=(x1,x2,…,xi,…,xn)的第i个特征xi的特征值进行改变,定义特征值的改变量为Δxi。定义
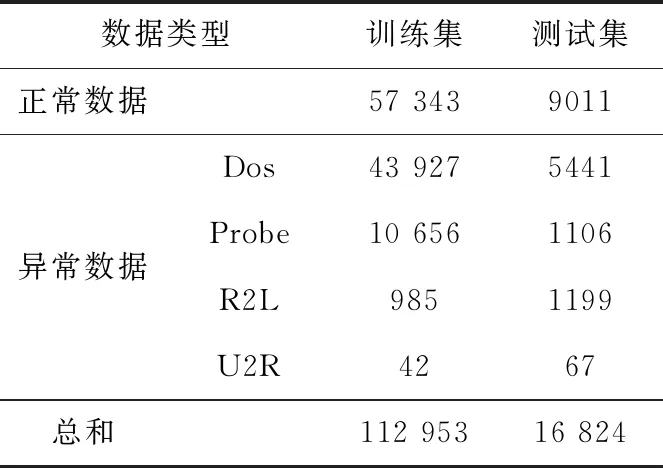
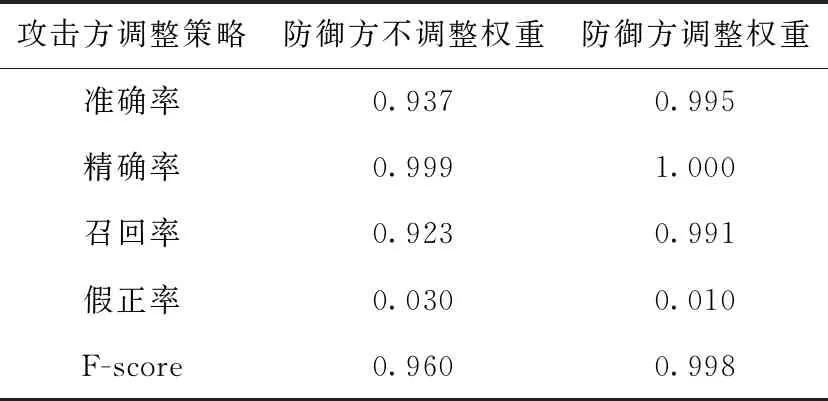
ximin (2) 式中:ximin与ximax分别为网络流量的第i个特征在样本集合θ中的最小值和最大值。则该特征的改变量范围为 ximin-xi<Δxi (3) 按照离差标准化将Δxi归一化可得 (4) 最终得到归一化后所定义的攻击成本为 (5) 虽然攻击方改变网络流量的特征值会削弱攻击强度,但同时被检测方检测到的概率也降低了,即防御方将攻击方修改后的网络流量分类为正常流量的可能性增加。本文对攻击方的收益做如下定义 profita=P(C(x+Δx,w)) (6) 式中:profita为攻击方收益,P为防御方的基分类器识别修改后数据流量的概率,这个概率与防御方的基分类器的分类结果(0或1)有关。C(x+Δx,w)表示基分类器的结果,这个结果与训练样本特征值x和分类模型得到的权重矩阵w有关。 在入侵检测系统整个博弈过程中,防御方需要对每条数据进行动作,该动作的目标是修改不同基分类器的权重Y,使分类效果达到最佳。和攻击方一样,这个动作跟两个因素有关:防御方的成本和防御方的收益。我们分析由于修改特征权重几乎不耗费任何资源,所以定义防御方成本为0。即 costb(Δx)=0 (7) 防御方通常会使用某种常用的分类指标来查看模型的分类效果,从而评判某个模型的好坏。我们定义当样本里的所有特征都存在所获得的分类器为C的分类指标为I(C(x+Δx,w))。像3.1节所论述的,样本S具有n个特征,我们分别去除样本的第i个特征,得到n个基分类器,此时去除第i个特征获得的Ci基分类器的分类指标为I(Ci(x+Δx,w)),此时可以得到第i个基分类器的分类指标的差异ΔIi ΔIi=I(C(x,w))-I(Ci(x,w)) (8) 式中:ΔIi的值大小与第i特征对分类效果的影响有关。因此,本文定义防御方的收益为 (9) 含义是防御方得到的权重与这组分类指标差异的相关系数为防御方的收益。 攻防双方都是想要以最小的成本来得到最多的收益,经过以上对攻防双方博弈过程的分析,我们得到了多个函数表达。因此,我们组合得到攻击方对每个网络流量的优化目标为 (10) 同样,防御方对每个样本的优化目标为 (11) 在网络入侵的过程中,通常是攻击者首先发送攻击的数据流量,然后防御者调整基分类器的权重而执行相应的防御动作,然后攻击者继续更改策略进行攻击,防御方继续做出响应动作,这是一个相互博弈的过程。本文是攻击方先动,防御方随其动,攻击方更改策略动作描述为Δxi,防御方响应动作描述为ΔY,即攻击方修改网络流量特值,防御方修改基分类器权重。建立斯塔克尔伯格模型的数学模型如下 (12) 模型建立完成后,对于上述复杂的非线性模型,本文选择遗传算法寻找上述模型的最优解Y。 本文选择NSL-KDD数据集,该数据集针对KDD99数据集固有问题做了改进。包括:删除了冗余记录和重复记录,保证分类器不会偏向于更频繁的记录;训练集和测试集中各个类型的数据数量设计更加合理,保证了不同的机器学习方法的分辨率在更宽的范围内变化。尽管NSL-KDD数据集还是拥有一些问题,但它仍然是有效的基准数据集,被大量研究人员使用,并取得了良好的效果。NSL-KDD数据集具体见表1。 表1 NSL-KDD数据集 NSL-KDD数据集将异常数据分为4类,可以对该数据集进行五分类:Dos,Probe,R2L,U2R,正常。在多篇文献中都对该数据集的五分类和二分类问题做了对比,结果显示CNN模型对于二分类问题有更好的识别效果。本文的入侵检测采用二分类,只将数据分为正常和异常两种。 NSL-KDD数据集的每条流量记录拥有41个特征,其中包含38个数字表示的特征和3个字符串表示的特征,对于这些特征需要分别进行预处理。 (1)符号型特征数值化 采用one-hot编码,将源文件行中3种协议类型转换成数字1,2,3;将源文件行中70种网络服务类型转换成数字1到70;将源文件行中11种网络连接状态转换成数字1到11;将源文件行中23种网络攻击转换成数字1到23。 (2)数值型特征归一化 本文归一化的思想是计算其每个样本的p-范数,然后对该样本中每个特征元素除以该范数,处理数据的目的是使得每个处理后样本的p-范数等1。 本文使用的识别分类方法是基于卷积神经网络模型,因此,本文搭建的卷积神经网络模型如下:网络总共有6层,包括输入层、2个卷积层,卷积层使用的卷积核都是选择3×3的矩阵、单个Max池化层、单个全连接层、输出层。卷积神经网络处理数据的过程如下:输入层输入的数据统一为一个7×7的二维矩阵,分别经过2层卷积和1层池化后,提取得到23维的抽象特征向量,最后在输出层通过softmax分类器进行分类。同时在模型建立过程中,添加了优化措施:为解决过拟合问题,并减小错误率,一种有效的方式是在网络的各层中加入Dropout,本文对全连接层连接一个p=0.5的Dropout层,除了输出层之外,其余各层激活函数均为ReLU。 CNN模型建立完成后,需要对基分类器的分类指标做一个选择,从而确定防御方的目标优化函数,常用的机器学习分类指标为 (13) (14) (15) (16) (17) 其中,TP表示预测为正常,实际为异常的数据;TN表示预测为异常,实际为异常的数据;FP表示预测为正常,实际为异常的数据;FN表示预测为异常,实际为正常的数据。 本文模型中选择假正例率(TPR)作为基分类器的分类指标,则防御方目标优化函数可以写成 (18) 本文采用遗传算法来求解斯塔克尔伯格数学模型的最优解,攻击方目标优化函数为上层函数,防御方目标优化函数为下层函数。遗传算法执行步骤为首先需要得到初始化Y种群,对初始种群带入限制条件进行判断,不符合时重新选择初始种群;符合时依次将初始群中个体代入下层函数,用遗传算法求解下层优化[12],找出每个种群中的最优个体Y*,然后再用遗传算法将Y*代回上层优函数,求解上层优化。遗传算法流程如图4所示。 图4 遗传算法流程 经过以上分析后,我们建立了攻防式CNN模型,为验证所提方法的有效性,数据处理与4.1节基本一致。在数据预处理阶段,先对数据集中的3个文本特征数值化(每个文本特征转换为相应的整数值),然后将41个特征的数据样本扩展为49个,进而转换为7×7的二维数据。将训练数据中80%作为训练集,20%作为验证集。共进行300次迭代训练。训练完成后使用测试集进行测试。实验结果见表2。 表2 权重调整实验结果 由表2中可以看出,当攻击方调整网络流量特征值时,防御方未调整防御策略与防御方调整策略相比,调整后的模型分类指标有了显著的提升,由此可以看出,对抗式斯塔克尔伯格数学模型在提高入侵检测的检测能力上有很好的效果。 由于文献[15]中的dNN算法也是对CNN算法进行改进,并且在多个识别指标上都获得了提升,因此本文选择dCNN算法进行二分类问题实验结果的比较。实验使用英特尔i7-4510U处理器,采用16 GB的内存,加装GEForce840M的显卡,在Spyder的环境下运行。我们选取多个分类指标,分别统计得到的结果见表3。 表3 实验结果 从表3实验结果可以看出,与dCNN算法相比,攻防式CNN算法在多个识别指标上都有所提高。 由于NSL-KDD的测试集中的数据流量有部分是测试集中没有的攻击类型。而在测试集上,攻防式CNN模型精确率能达到100%,并且其它指标与训练集的差距小于dCNN模型。这表明本文方法对于攻击方修改后攻击类型有很好的检测能力。 本文针对目前电力营销系统升级过程中存在的网络安全问题提出了攻防式CNN入侵检测模型。该模型首先提出基分类器的概念,通过CNN模型建立的多个基分类器,并对入侵检测攻防双方成本与收益进行分析,建立斯塔克尔伯格博弈模型,最后使用遗传算法求解出最优的基分类器权重Y。实验选定多个参数,搭建了实际的入侵检测模型,利用NSL-KDD数据集上对本方法进行了实验。从实验结果来看,当实时的网络流量特征值发生变化时,防御方根据遗传算法求得的最优权重调整防御策略后,检测性能有了明显的提升。其次,基于对抗式CNN的入侵检测模型在多个指分类标上优于传统的STL分类模型,从而验证了本方法的有效性。3.2 防御方模型
3.3 斯塔克尔伯格博弈模型

4 实验与分析
4.1 实验数据集
4.2 对抗式CNN模型参数选择
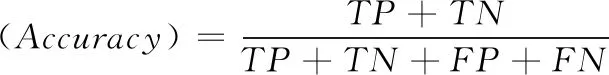
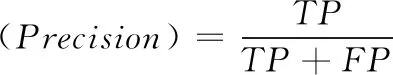
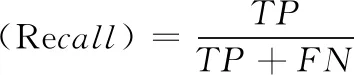
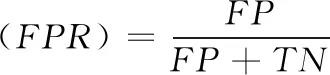
4.3 遗传算法求解
4.4 实验结果与对比

5 结束语
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22微型电脑应用(2021年3期)2021-03-31北京航空航天大学学报(2017年7期)2017-11-24石油地球物理勘探(2017年2期)2017-11-23中央民族大学学报(自然科学版)(2017年1期)2017-06-11统计与决策(2017年2期)2017-03-20光学精密工程(2016年4期)2016-11-07光学精密工程(2016年3期)2016-11-07智能系统学报(2015年4期)2015-12-27电测与仪表(2014年15期)2014-04-04
