
面向网络论坛的文本数据获取与存储方法研究
2021-06-28 01:04曹惠茹成海秀连松耀王毅
现代信息科技 2021年1期
关键词:数据存储
曹惠茹 成海秀 连松耀 王毅

摘 要:针对网络论坛文本数据的特点与网络论坛的结构,提出了一种网络论坛文本数据获取与存储方法。先采用Browser/Server架构云构建网络论坛数据系统框架,再依托网络爬虫技术实现对网络论坛数据的收集,然后基于Bi-LSTM网络搭建主题相关性文本数据过滤系统,最后采用MySQL和MongoDB数据库,构建数据存储方案。系统设计表明所提出的方法可行,为网络论坛舆情的研究与引导提供了依据。
关键词:网络论坛;文本数据;数据获取;数据存储
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2021)01-0007-06
Research on Text Data Acquisition and Storage Method for Network Forum
CAO Huiru1,CHENG Haixiu2,LIAN Songyao3,WANG Yi1
(1.Guangzhou Institute of Technology,Guangzhou 510075,China;
2.School of Computer Science and Engineering,South China University of Technology,Guangzhou 510640,China;
3.College of Nanfang,Sun Yat-Sen University,Guangzhou 510970,China)
Abstract:According to the characteristics of the text data of network forum and the structure of network forum,a method of acquiring and storing the text data of network forum is proposed. Firstly,the data system framework of web forum is constructed by using Browser/Server architecture cloud,then the data collection of web forum is realized by relying on web crawler technology,and then the topic related text data filtering system is built based on Bi-LSTM network. Finally,the data storage scheme is constructed by using MySQL and MongoDB database. The system design shows that the proposed method is feasible,which provides a basis for the research and guidance of public opinion in network forum.
Keywords:web forum;text data;data access;data storage
0 引 言
網络社区舆情是一种对各类信息进行汇集、分类、整合、筛选等技术处理,并在此基础上对形成的网络热点和网民意见等进行实时统计和引导干预的过程[1-3]。目前,国内外网络社区以网络论坛为主,其已经成为网络信息传播的重要渠道[4,5]。
网络社区信息主要通过论坛、贴吧、微博等载体的多种类型数据进行传播,其中以文本数据为主[6,7]。对网络社区舆情进行研究与引导,获取网络论坛文本数据成为了关键前提条件[8,9]。因此,对网络论坛相关数据获取与存储进行研究是当前网络舆情分析的重要环节,通过对相关数据的分析与研究,可以正确引导网络舆情发展,形成良好的网络环境。
网络论坛文本数据的获取可以通过各种不同方法得到,如:从网络社区服务器抓取与舆情主题相关网页内容。针对不同的获取方法,国内外许多学者进行了研究,赵璐[10]根据环保舆情信息源的特点,设计了一个分布式爬虫系统;针对不同的舆情源设计了不同的数据获取策略,实现数据信息更快、更准确的获取。丁晟春等[11]提出了一种基于知识库和主题爬虫的网络舆情监测方法,通过将领域本体知识库与主题爬虫相结合,用以扩大主题爬虫的搜索范围并提高其搜索精确度。谭啸[12]结合了本体论的基本知识,使用开源软件Protégé来构建基于网络本体语言(OWL)的本体模型。Boukadi等[13]基于本体论思想,提出了一种面向云服务发现的网络社区内容获取爬虫算法,以达到节省搜索时间和更好地提供相关信息服务。Suebchua等[14]采用已经下载的Web页面,估计目标Web页面的优先级进而建立网页邻居特征,以此特征为基础构建了高效网页数据获取方法。尽管上述文献为网络社区数据获取提供了相关基础并表明了可行性,但存在算法复杂,数据相关性低等不足,仍需要构建能提高网络社区舆情数据获取效率、主题相关性与有效性的方法[15,16]。
针对网络论坛数据的特点和获取数据主题关联性等新挑战,本文以笔者主持的科研项目为支撑,针对网络论坛中的相关文本信息进行收集,通过数据清洗、提取关键词、对关键词进行聚类等步骤,提出了一种网络论坛文本数据获取与存储方法。采用经典的B/S(Browser/Server)架构云服务器构建了网络论坛数据系统框架;依托网络爬虫技术,实现对网络论坛数据的收集;基于Bi-LSTM网络搭建主题相关性的文本数据过滤系统;采用MySQL和MongoDB数据库,构建了数据存储方案。该研究为网络论坛舆情的相关研究与引导提供了可靠的依据。
1 论坛文本数据系统架构设计
本系统根据功能分为三个子系统:数据收集子系统、数据分析子系统、数据可视化子系统。系统采用B/S(Browser/Server)架构,只需通过有浏览器的终端就可以访问本系统。
数据收集子系统主要负责从互联网静/动态网页采集到数据,后对数据进行自动去重操作,并将数据存储到数据库中。
数据分析子系统主要负责将收集到的数据进行分析,经过数据过滤、关键词提取、主题提取等步骤获取热点主题并存储到数据库中。
数据可视化子系统分为前端和后端,后端分为三个部分,CMS(Control Manager Service)负责MinIO对象存储管理、Elastic Search数据导入、统一异常处理;DMS(Data Manager Service)负责数据的管理和统计,包括主题热点数据、网络论坛的帖子数据、网络论坛的回复数据、网络论坛的用户数据;UMS(User Manager Service)负责登录验证、权限控制、用户中心。后端的三个部分之间穿插着日志服务记录,用于记录所有请求日志。
系统的整体框架如图1所示。
2 网络论坛数据收集系统设计
数据收集子系统主要是依托网络爬虫技术,实现对网络论坛数据的收集。由于论坛具有很高的自由度,信息条目和话题更新速度快且数量较多,为了减少资源浪费,减轻对目标网站的压力,本系统采用增量更新的策略。即对于每条数据存储时设置更新标志位updates,有更新时更新updates的值,只有更新标志位为1时,才对相关数据进行更新,否则不更新数据。
数据收集子系统分为三个Spider:帖子数据,帖子一级回复数据,一级回复内下二级回复。帖子数据的收集流程如图2所示。
帖子内一级回复数据的收集主要取决于帖子数据的更新标志位updates,当updates为1时,才对该帖子进行一级回复数据的收集,如果updates的值不为1,本次收集省略该帖子。其收集流程如图3所示。
帖子内二级回复数据的收集主要取决于帖子数据的更新标志位updates,当updates为1时,才对该帖子的二级回复数据进行收集,如果updates的值不为1,本次收集省略该帖子。其收集流程如图4所示。
3 基于主題相关性的数据过滤系统设计
数据分析子系统的功能主要包括:数据的过滤、热点主题的提取、数据统计三个部分。数据分析后的结果将保存到数据库,为后面的数据可视化子系统提供数据资源。
数据过滤是数据分析的一个重要前置步骤,只有筛选出真正有效的数据,后面分析出来的结果才是准确的结果。本系统基于Bi-LSTM网络搭建了一个具有文本分类功能的模型,当模型的输出结果为GOOD时,表示该语料为有效数据;当模型的输出结果为BAD时,表示该语料为无效数据,应当删除,不能计入下一步分析的范畴。数据过滤的流程图如图5所示。
热点主题的提取主要基于关键词提取算法(TextRank)和关键词聚类算法(AP聚类)实现,共分为六个步骤:
(1)对帖子进行分帖操作;
(2)计算用户的知名度、帖子的权重;
(3)根据关键词提取算法从语料中获取若干个用于表示主题的关键词;
(4)构建共词矩阵;
(5)对共词矩阵采用关键词聚类算法进行聚类操作,从而得到以多个关键词表示的热点主题;
(6)根据用户的知名度、帖子的权重计算出相应热点主题的热度值。
4 网络论坛文本数据存储系统设计
数据库设计关系到整个系统的执行效率,一个好的数据库设计,不仅可以提高系统的执行效率,缩短数据响应时间,减少流量损耗,而且还有利于日常数据的更新维护。
4.1 文本数据库E-R模型
本系统采用MySQL和MongoDB数据库相结合的方式,MySQL用于存储结构化的数据,MongoDB用于存储重要性不高,类JSON的数据格式。系统总共13张表,按照模块分类,可以分为两类:网络论坛数据(DMS模块)、用户权限(UMS模块)。
网络论坛数据一共有5张表,分别为:网络论坛帖子信息表(dms_note),网络论坛一级回复信息表(dms_message),网络论坛二级回复信息表(dms_comment),网络论坛帖子权重信息表(dms_note_weight),网络论坛用户信息表(dms_user)。网络论坛数据(DMS模块)的E-R图如图6所示。
用户权限一共有8张表,分别为:用户表(sso_admin),角色表(sso_role),角色与用户的映射表(sso_admin_role_relation),权限表(sso_permission),角色与权限的映射表(sso_role_permission_relation),路由表(sso_router),角色与路由的映射表(sso_role_router_relation),用户操作日志表(ums_log)。UMS模块的实体具体属性如图7所示。
4.2 数据库逻辑设计
数据库逻辑设计就是把概念设计的结果E-R模型图转换为选用的数据库管理系统产品所支持的数据类型。在进行逻辑设计的过程中,要尽可能遵守数据库设计三大范式。
第一范式:表中的每一个字段不能再进行分解;
第二范式:在满足第一范式的情况下,要确保表中的每一个非主键字段与主键都要有关联,不关联的应进行拆表;
第三范式:在满足第二范式的情况下,确保表中的每一列都与主键直接相关,间接相关的应分表存储并通过外键进行连接。
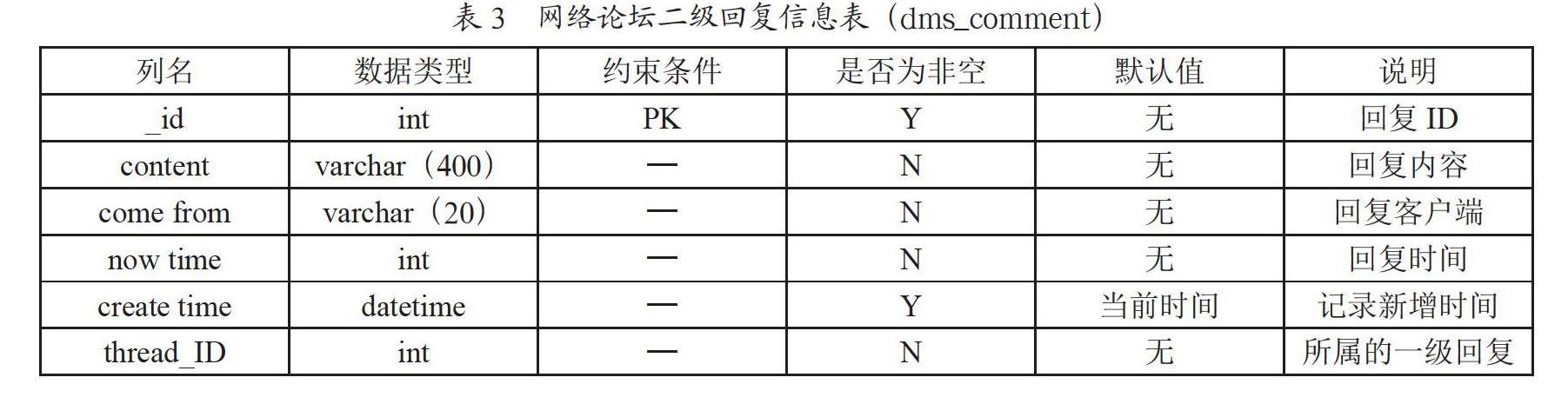
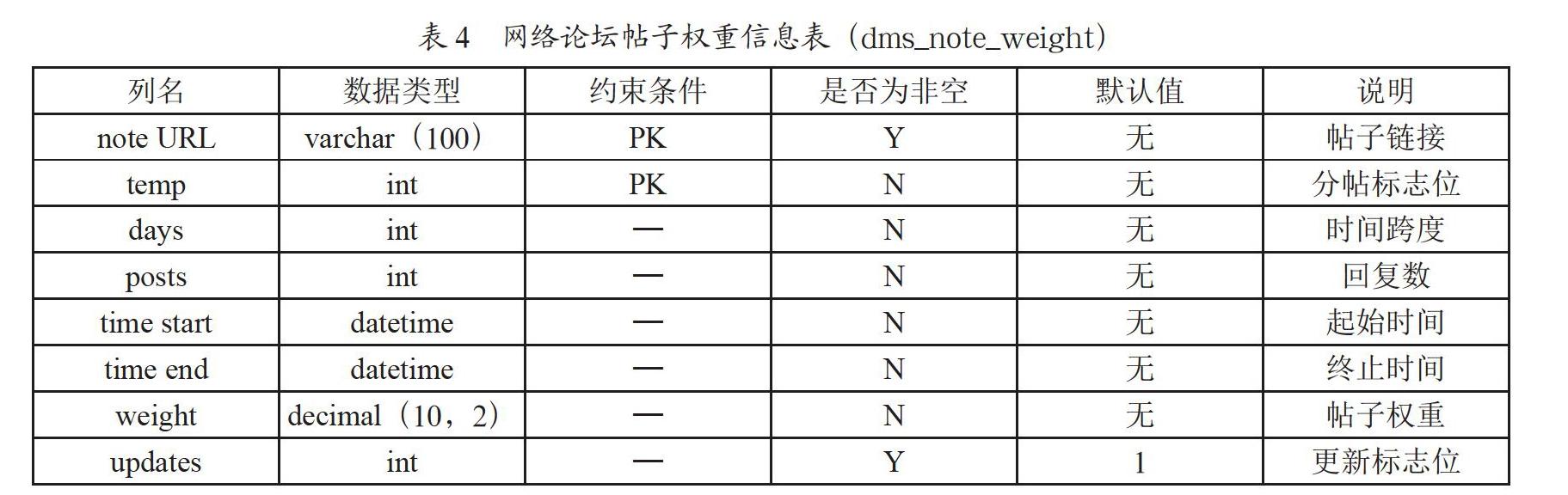
本系统采用MySQL数据库作为主存储,MongoDB数据库作为辅助存储,MongoDB数据库主要存储的是类JSON的数据或者并不是特别重要并且数据量大的数据。本系统所涉及的数据表有13个,其中使用MySQL数据库存储的表有11个,采用MongoDB数据库存储的表有2个(网络论坛二级回复信息表和用户操作日志表)。网络论坛数据所涉及的5张表如表1至表5所示,表1为网络论坛帖子信息表,采用MySQL数据库存储。表2为网络论坛一级回复信息表,采用MySQL数据库存储。表3为网络论坛二级回复信息表,由于涉及到JSON数据的存储,采用MongoDB数据库。表4为网络论坛帖子权重信息表,表5为网络论坛用户信息表,采用MySQL数据库存储。
表6为用户表,采用MySQL数据库存储。表7为用户操作日志表。在线上的运行服务中,需要记录下用户的请求记录,在发现问题或系统报错时,可以查看其具体的报错信息或运行记录。通常会采用文本的形式记录下日志,然而如果需要对日志进行分析,存在数据量大,分析成本高,采用传统MySQL数据库存储并不划算。因此本系统采用MongoDB数据库来存储用户的访问记录。其余用户权限中的6张表不在此赘述。
5 结 论
本文以大数据环境下的网络论坛文本数据为研究对象,基于网络论坛的结构,提出了一种网络论坛文本数据获取与存储方法。首先,基于采用经典的B/S(Browser/Server)架构云构建了网络论坛数据系统框架。其次,依托网络爬虫的技术,实现对网络论坛数据的收集。再次,基于Bi-LSTM网络搭建主题相关性的文本数据过滤系统。最后以采用MySQL和MongoDB数据库,构建了数据存储方案。系统设计表明,该网络论坛文本数据获取与存储方法是可行的。同时,本文所提出的相关方法为网络论坛舆情的相关研究与引导提供了可靠的依据。
参考文献:
[1] 林云,曾振华,曾林浩.微博社区网络结构特征对舆情信息传播的影响研究 [J].情报科学,2019,37(3):55-59.
[2] 丁晟春,王鹏鹏,龚思兰.基于社区发现和关键词共现的网络舆情潜在主题发现研究——以新浪微博魏则西事件为例 [J].情报科学,2018,36(7):78-84.
[3] ZHONG Z F. Internet public opinion evolution in the COVID-19 event and coping strategies [J].Disaster medicine and public health preparedness,2020:1-7.
[4] ZAMANI M,RABBANI F,HORICS?NYI A,et al.Differences in structure and dynamics of networks retrieved from dark and public web forums [J].Physica A:Statistical Mechanics and its Applications,2019,525:326-336.
[5] PARK S,WOO J. Gender Classification Using Sentiment Analysis and Deep Learning in a Health Web Forum [J].Applied Sciences,2019,9(6):1249.
[6] BRADLEY A,JAMES R J E. Defining the key issues discussed by problematic gamblers on web-based forums:a data-driven approach [J/OL].International Gambling Studies,2020:[2020-07-30].https://www.tandfonline.com/doi/full/10.1080/14459795.2020.1801793.
[7] 沈明珠,刘辉.面向技术论坛的问题解答状态预测 [J].计算机研究与发展,2020,57(3):474-486.
[8] 贺敬杰.网络表达与公共讨论:基于“林松龄事件”中论坛回帖文本的情感分析(英文) [J].国际新闻界,2015,37(9):109-132.
[9] 滕云,陈玲.网络舆情特点的实证研究——基于高校BBS论坛的文本分析 [J].山东社会科学,2014(3):181-186.
[10] 赵璐.网络舆情监控系统关键技术研究 [D].西安:西安电子科技大学,2014.
[11] 丁晟春,龚思兰,周文杰,等.基于知识库和主题爬虫的南海舆情实时监测研究 [J].情报杂志,2016,35(5):32-37.
[12] 谭啸.基于本体的网络爬虫设计及应用 [D].成都:电子科技大学,2016.
[13] BOUKADI K,REKIK M,REKIK M,et al. FC4CD:a new SOA-based Focused Crawler for Cloud service Discovery [J].Computing,2018,100:1081-1107.
[14] SUEBCHUA T,MANASKASEMSAK B,RUNGSAWANG A,et al. Efficient topical focused crawling through neighborhood feature [J].New Generation Computing,2018,36(2):95-118.
[15] KIM Y Y,KIM Y K,KIM D S,et al. Implementation of hybrid P2P networking distributed web crawler using AWS for smart work news big data [J].Peer-to-Peer Networking and Applications,2020,13:659-670.
[16] PRAMUDITA Y D,ANAMISA D R,PUTRO S S,et al. Extraction System Web Content Sports New Based On Web Crawler Multi Thread [C]//International Conference on Science and Technology 2019.Surabaya:IOP Publishing,2020.
作者簡介:曹惠茹(1981—),女,汉族,陕西渭南人,副教授,硕士研究生,主要研究方向:大数据,无线网络。
猜你喜欢
文理导航(2017年2期)2017-02-16
办公室业务(2016年11期)2017-01-09
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年12期)2016-06-14
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年11期)2016-06-03
电脑知识与技术(2016年8期)2016-05-19
科技视界(2016年4期)2016-02-22
