
基于SIFT和HOG特征融合的视频车辆检测算法∗
2021-06-29 08:41关晓斌李战明
计算机与数字工程 2021年6期
关晓斌 李战明
(兰州理工大学电气工程与信息工程学院 兰州 730050)
1 引言
静态技术下的车辆检测算法相对成熟,但是考虑到实用性,视频技术下对车辆检测[1]的正确性和快速性能够更加广泛应用到实际领域,在科研方面也具有更加重要的意义。近年来,视频技术下车辆检测得到广泛研究,研究方法主要分为特征提取和特征分类两部分[2]。文献[3]中使用HOG作为特征提取,结合SVM来检测车辆,训练样本检测效率很高,但实际使用中仍会受到误差影响。为了解决特征的单一性,随后的研究人员多提取不同特征来满足复杂的实际应用。如文献[4]中使用HOG+Haar-like作为特征提取,结合AdaBoost来检测车辆。文献[5]使用HOG+LBP作为特征提取,结合SVM来检测车辆。
本文选择HOG特征和SIFT特征相结合的方法做特征提取[6]。HOG特征主要提取物体轮廓信息,应用到车辆检测上效果良好,缺点是对光照遮挡等容忍性较差。而SIFT特征主要提取关键点的局部信息,对光线、噪声等容忍度较强,二者结合可以产生更加良好的检测效果。在检测验证阶段,考虑到是二分类问题,而SVM处理二分类问题相当出色,所以使用SVM作为本文的车辆检测分类器。
2 特征提取
2.1 图片预处理
首先需对训练集样本图片预处理,因为颜色信息在HOG特征提取[7]中用处不大,所以将训练样本灰度化处理。具体转化公式为
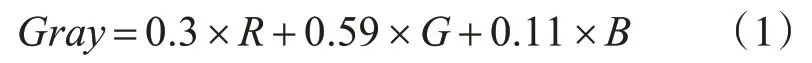
然后利用Gamma校正的方法提升图片的整体亮度,以此来降低图片阴影或光照变化产生的误差。具体使用了像素值平方根的方法,公式为

其中,I(x,y)是图像中某点的像素值,γ是变换系数。
2.2 HOG特征提取
HOG特征主要用于检测物体的轮廓信息,它可以通过目标的形状等特征[8]以梯度或边缘的方向密度分布描述,因此在图像处理领域和机器视觉领域都有很好的研究价值。
2.2.1 各像素梯度计算
对图像预处理之后,需要计算图像的梯度、梯度方向及幅值,以此来捕获图像的轮廓信息。以水平方向[-1,0,1]及垂直方向[-1,0,1]T上分别完成对图像梯度的计算。计算公式为

其中,Gx(x,y)与Gy(x,y)分别是点(x,y)位于水平方向和垂直方向上的梯度,I(x,y)是图像中点(x,y)的像素值,θ(x,y)为梯度方向,G(x,y)为梯度幅值。
2.2.2 单元内梯度方向直方图
实际处理中将以单元格作为基本单位,因此构造8×8像素大小的单元格,并且单元格之间不能出现重叠。以9个BIN的直方图对单元格内的梯度信息作出统计,将像素的梯度作为权重,对各个梯度方向在直方图中加权投影,便可形成每个单元的描述子[9]。
2.2.3 直方图归一
实际应用中光照或者背景的变化可能会引起梯度值发生变化,所以通过构建2×2的单元块做归一化操作,以此弱化局部变化对梯度值产生的影响。最终,将所有的块组合起来,生成的信息即为图像的HOG特征[10]。图1为HOG特征处理车辆图片的效果图。

图1 HOG特征处理车辆图片的效果图
2.3 SIFT特征提取
SIFT特征主要用于处理图像的局部特征,其优势是处理过程中可以减少图像的尺度缩放、旋转、亮度以及噪声等问题的干扰。同时,SIFT具有很好的扩展性[11],导致它和其他特征提取方法结合使用时具有很好的亲和度。
2.3.1 构造DOG尺度空间
由于计算机视觉并不能提供图像中物体的尺寸大小,所以要通过建立尺度空间[12],将不同尺度下的图像提供给计算机,使计算机做出认知。
首先建立图像金字塔(如图2)。即先对样本图片进行平滑处理,再进行降采样,由于采样率的差异,得到一系列像素点和尺寸不断变小的图像,一般每一层图像的长和高都是上一层的一半。然后使用高斯卷积处理图像金字塔每层的图像得到LOG图像,本来的图像金字塔每层的图像在卷积之后又增加了多张模糊图像[13]。卷积公式为
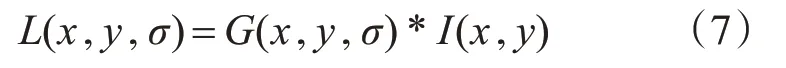
L(x,y,σ)为图像的高斯尺度空间,G(x,y,σ)为高斯核函数。由于卷积产生的图像过多,将相邻的图像减法处理,重新构建得到图像金字塔,即DOG尺度空间[14]。
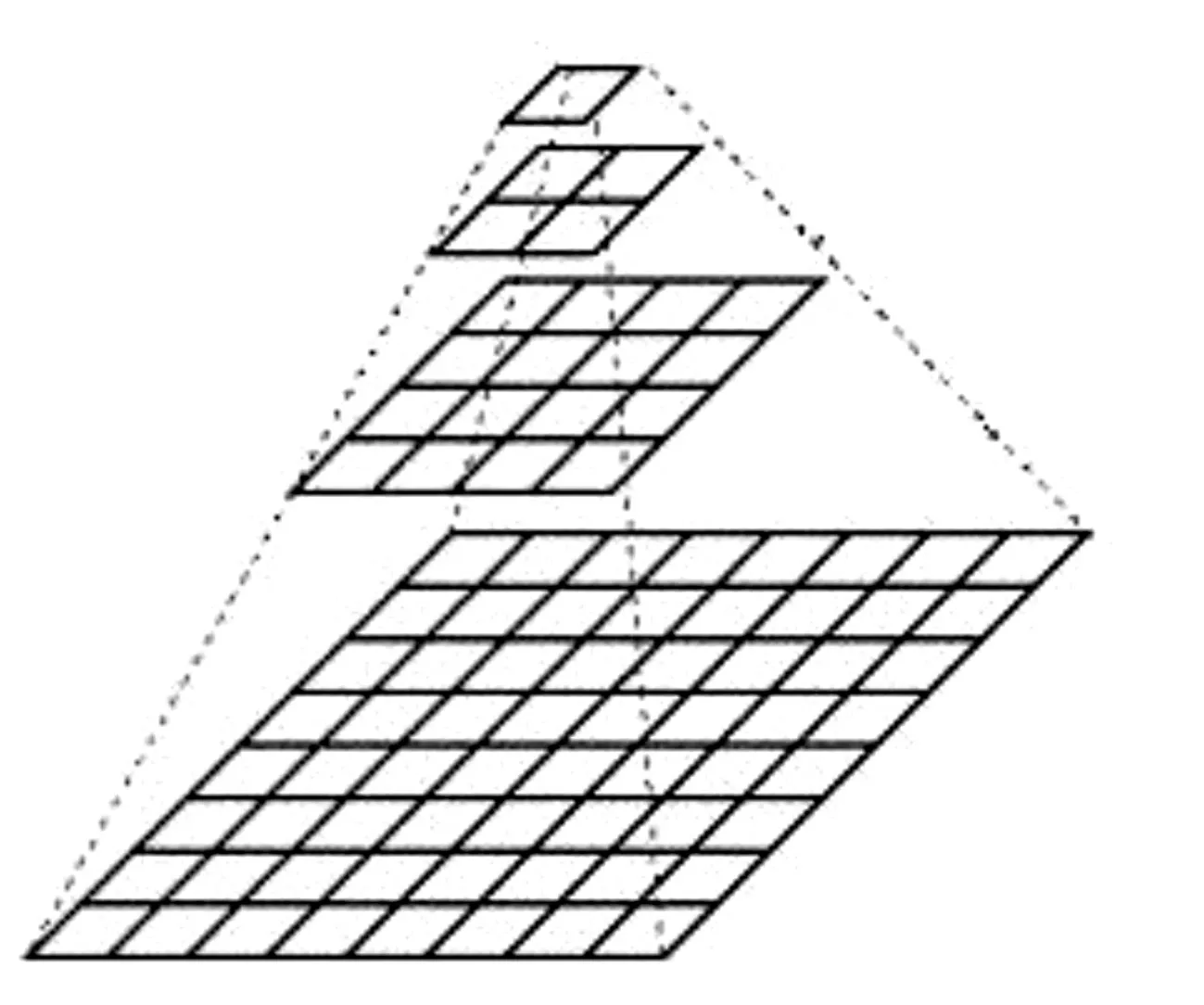
图2 图像金字塔
2.3.2 关键点搜索和精确定位
接下进行极值点的检测和定位,当某个点的像素值大于或者小于周围所有点的像素值时,该点极有可能是寻找的极值点,通过曲线拟合剔除掉两类极值点:降低对比度的极值点和不稳定的边缘响应点,得到真正的极值点,即特征点[15]。
2.3.3 生成特征方向及描述子
确定特征点之后,通过对这些特征点的方向进行赋值以此来实现图像的旋转不变性。以梯度分布确定最终的方向参数,获取稳定的特征点方向[16]。将这些特征点作为中心,选取16×16的窗口采样,以8个方向的直方图来统计每个块,以此形成一个128维的特征向量。图3为SIFT特征处理车辆图片的效果图。

图3 SIFT特征处理车辆图片的效果图
3 特征分类
常用的分类器有SVM(支持向量机)、adaboost分类器、贝叶斯分类器等[17]。考虑到是二分类问题,本文选择以SVM作为分类器。SVM在学习过程中会提供监督模型,把训练样本划分为训练集与验证集,图片训练完成后验证集去检测训练效果。
3.1 SVM线性分类器
SVM线性分类器主要实现二分类问题,即把需要分类的样本分为正类和负类[18](如图4)。同时寻找出最佳分类的超平面,如图中g所示,能够正确地区分正负样本,并且使得正负样本之间的距离最大[19]。其中超平面:

w为超平面的法向量,b为截距,分类决策函数[20]为
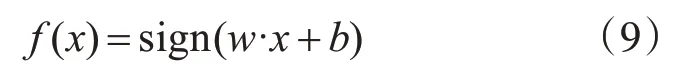

图4 SVM二分类
3.2 核函数实现线性不可分
处理非线性可分问题时,使用核函数把非线性问题当做是线性问题[21],再以线性可分的方法去解决。常见的SVM核函数如表1。

表1 SVM核函数
4 仿真实验
4.1 实验环境及数据来源
本文实验部分通过台式计算机完成,操作系统为Window10,CPU为i3-4160,编程语言使用py⁃thon3.7,编程软件pycharm,同时结合使用了opencv库、scikit-image库、sklearn库等配合完成。组合使用部分GTI数据集和KITTI数据集作为机器学习阶段的训练库,图片训练使用了8797张车辆图片和8970张非车辆图片。其中正样本包括不同颜色的不同车型,包括越野车、轿车、卡车等,如图5所示。负样本包括路边树木、高速公路、防护栏等不同图片,如图6所示。使用SVM时设置训练集与验证集8:2,训练完成之后验证集自动验证,得到具体的训练检测率。

图5 车辆图片

图6 非车辆图片
由于图片训练一共使用了8797张车辆图片和8970张非车辆图片,验证集占据了20%,即使用了1759张正样本和1794张负样本作为验证集。假设正样本为PS(Positive sample),负样本为NS(Nega⁃tive sample),正样本检测正确的为CP,所有错检与漏检为FA,则检测率为CP/PS,误检测率为FA/PS+NS。
4.2 不同核函数训练对比
核函数的选择是SVM分类器最关键的部分,由于实际数据类型十分复杂,本文对线性分类器和不同的核函数分类器做出实验,确定最为有效的方法。由确定的核函数和训练样本的特征向量,构造决策函数,利用决策函数对验证集做出判断。
本实验最先选取了LinearSVC的线性SVM分类器,没有kernel参数。需要设置参数max_iter:即需要运行的最大迭代次数,默认设置为1000,在实际使用中程序报错显示需要增加迭代次数,本实验设计max_iter为10000。
使用SVC来处理非线性核函数的实验。具体使用参数如下。
1)kernel:首先是核函数的确定,核函数可以将非线性问题转化成为线性问题,本实验验证了RBF(高斯核)、Sigmoid核及Poly(多项式核)的检测效率。
2)C:该参数为惩罚系数,用来控制损失函数。当参数值设置越高,则越对误差难以容忍,而且会出现过拟合。参数设置越低时,也容易造成欠拟合。其一般设置区间为[0.1,100],本实验使用惩罚系数为32。
3)gamma:核函数系数,该参数作用于RBF,Poly和sigmoid。gamma值设置较大,会导致高斯分布又高又瘦,而且相应的模型会依赖在支持向量周围;gamma值设置越小,会导致高斯分布过于平滑,实际训练中效果会大打折扣。本实验设置gamma为5。
4)max_iter:最大迭代次数,在SVC中默认是-1,即没有限制。但是当训练次数饱和,不论训练的标准和精度有没有达到要求,训练都会停止(与LinearSVC中的max_iter默认值不同,在SVC训练中使用默认参数)。
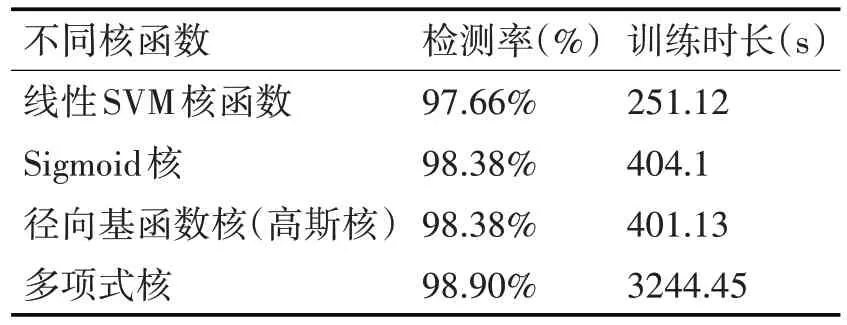
表2 核函数对比
多项式核函数是将低维的输入空间映射到高维的特征空间,虽然默认映射到三维空间,但是该过程依然大大提高了训练的时长,检测效率虽有提高,但训练时长大大增加导致本文抛弃使用多项式核函数。比较之下,高斯核函数训练时间较短,而且检测效率高,因此选择高斯核作为本文的SVM核函数。
4.3 算法比较及视频验证
本文算法与其他传统算法的训练效率做对比如表3所示。
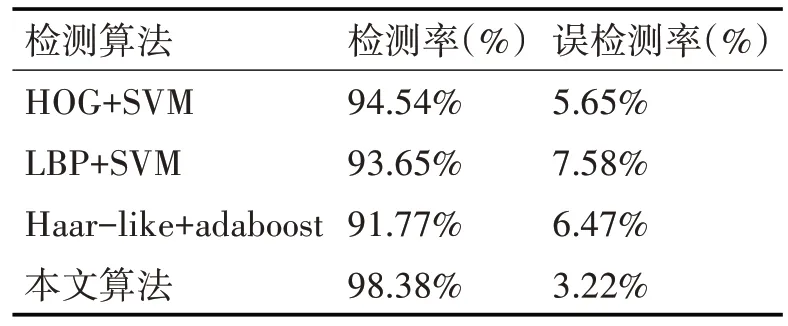
表3 算法对比
图片的训练结束之后,使用SVM处理需要检测的视频。本实验使用的检测视频是行车记录仪高速公路的视频图像以及城市道路中的视频图像。视频处理结果可以看到,完成了对单独车辆和多车辆的检测,但是在夜视情况下车辆检测仍然受到干扰,较远行驶的车辆未检测出来,而且会出现延迟,实际效果仍有待提高。视频截图如图7所示。

图7 处理后视频截图
5 结语
本文结合使用了HOG特征与SIFT特征,以此减少特征单一导致的检测率差的问题。然后结合SVM分类器利用不同核函数对同一样本集作训练对比,得到高斯核函数情况下车辆检测率更高,同时训练时长也最短。实验数据表明,车辆检测率较传统算法有所提高。最后,以高斯核函数的训练模型处理视频文件对实际训练结果做出验证,视频文件反映出夜视情况下车辆检测仍有问题存在,有些车辆不能被检测,本文认为主要原因在于车辆训练样本仍然较少,希望后续可以增加训练样本并继续改进算法,将该算法更有效地应用到实际中。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
电机与控制学报(2018年9期)2018-05-14
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
计算机应用(2016年10期)2017-05-12
数学学习与研究(2017年3期)2017-03-09
