
融合因子分解的上下文推荐算法研究∗
2021-06-29 08:41圣文顺
计算机与数字工程 2021年6期
乔 雨 圣文顺
(南京工业大学浦江学院 南京 211200)
1 引言
传统的推荐系统通常只考虑用户本身的行为信息和待项目的基本信息,而随着互联网的发展,各类信息量都呈快速增长状态,利用单一的“用户-项目”信息产生推荐已经不能够满足用户的需求[1]。因此,为了使推荐系统更好地发挥其信息过滤的作用,精准地定位用户感兴趣的点,融合上下文情景的推荐系统应运而生[2~3],即推荐系统中除了要考虑基本的“用户-项目”二元信息外,还需要实际应用场景中所处的上下文状态信息对推荐结果的影响。基于上下文情境的推荐系统的实现原理是:根据收集到的用户基本信息、评分信息、上下文情景等信息,进行“用户-项目-上下文信息”三维信息的挖掘,来分析出用户可能的兴趣点,并给出对应的推荐结果。
2 相关技术介绍
2.1 奇异值分解
在需要考虑上下文信息的推荐系统中,常用奇异值分解[4](Singular value decomposition,SVD)技术来对用户行为信息矩阵进行分解,实现高维度矩阵的降维,但是这样的奇异值分解技术在应用中会面临由于矩阵过于稀疏(稀疏性达到95%以上)需要填充的数据量过于庞大,并且数据难以得到有效存储的问题[5];其次,该问题也会导致该方法无法适应互联网背景下的大数据级别的应用场景;再者,奇异值分解技术在利用Spark等工具进行训练时,存在着数据利用率不足的情况。因此,对于融合多维上下文情景的推荐系统,奇异值分解的方法显得过于繁重。
2.2 多项式回归
多项式回归(Polynomial Regression)被应用到推荐算法中,是能够利用其线性回归的特征来弥补奇异值分解技术的劣势,利用因变量与自变量之间的相互作用[6],将上下文信息用线性关系进行表示,避免由于数据矩阵过于庞大而导致的存储和计算效率问题。但是另一方面,多项式回归为了尽可能地拟合数据,采用增加高次自变量的方式来对训练数据集进行逼近,容易形成过度拟合[7],进而带来训练不准确的问题。
本文对多项式回归算法进行了深入的研究,针对其存在的计算复杂度较高的问题进行分析并尝试着改进,提出了融合因子分解的上下文推荐算法(Context-aware Recommendation based on Factoriza⁃tion Machines,FM-CR),该算法利用因子分解的方式将多项式回归中变量之间的相互作用进行分解[8],进而达到降低计算复杂度的目的。式(1)给出了二阶因子分解模型,其中w0∈R,v∈Rn×k,n×k表示整体数据维度;参数w0,wi和vi是模型经过训练学习得出的[7];式(2)为引入的损失函数,用来防止过度拟合。
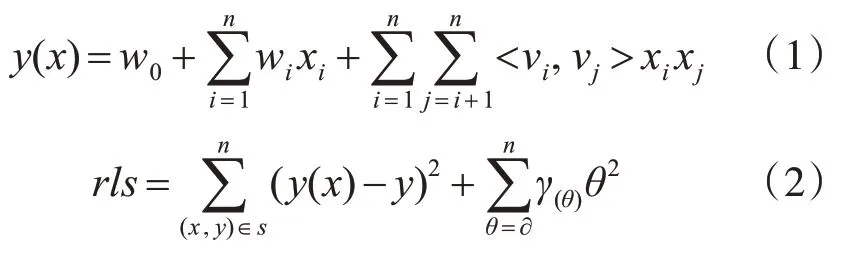
3 FM-CR算法介绍与分析
3.1 FM-CR算法步骤
基于上下文情景的推荐在考虑基本的用户行为信息外,还需要尽可能地考虑用户所处的实时状态信息[9~10],本文提出的FM-CR算法可描述为三个核心步骤。
步骤1:确定上下文特征信息
在含有上下文信息的推荐系统中,由于包含了除用户、项目之外的多种有关上下文情景的信息,因此将预测评分用式(3)表示:
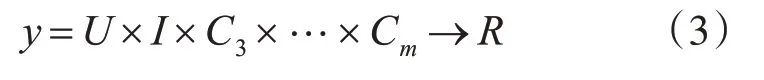
值得说明的是,式(3)中的上下文属性下标是从3开始的,这是因为将“用户”和“项目”分别看成了“上下文”特征信息中的第1项和第2项[11],达到统一数据格式的目的。其他的上下文信息,如用户所处的时间、心情等属性都可以根据系统需要作为“上下文”输入到推荐算法中进行训练,以电影推荐系统为例,纳入用户的观影项目I={movie1,mov⁃ie2,movie3}、观影心情C3={happy,sad,normal}、观影 地 址C4={p1,p2,p3}、观 影 同 伴C5={friend1,friend2,friend3}这四类因素来组成用户所处的上下文情境。
步骤2:抽象上下文信息的特征向量
基于步骤1所述,将各“上下文信息”抽象为特征向量z进行表示,此向量z包含了5个特征信息,分别是用户、项目、心情、地点和同伴。例如,用户u1与f3在心情愉快的情况下,于p2地看了电影mov⁃ie3,并且给了5分的评价;那么电影项目向量表示为z(2movie)=(0,0,1),心情向量可表示成z(3hap⁃py)=(1,0,0),地址向量可表示为z(4p2)=(0,1,0),同伴向量表示为z(5friend3)=(0,0,1)。因此,用户u1的上下文信息向量如式(4)所示,综合评分矩阵如式(5)所示。

另一种情况,若u1是与同伴friend2和friend3一起观看的电影movie3,那么这里的同伴向量可以表示为z(5{friend2,friend3})=(0,0.5,0.5),这是因为当某一“上下文”是分类变量的集合时,就将该信息进行归一化处理,使得此分类向量的权值总和为1。基于对这两种情况,最终的特征信息可以通过连接映射成如式(6)所示的向量x。
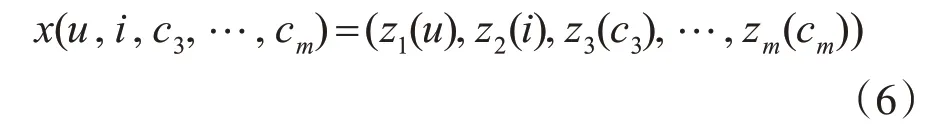
步骤3:通过预测产生目标推荐
确定好信息特征向量后,将向量数据输入到libFM工具中进行参数的训练。libFM是一款用来训练数据的开源工具,利用它可以快速地实现参数的学习和评分预测[12],信息特征向量中的行表示一个实例,“1”表示特征值存在,“0”表示特征值不存在。本实验采用libFM中的随机梯度下降算法进行实验数据的训练。训练过程如式(7)所示,其中参数(x,y)是样本中的数据;μ∈R指迭代的学习效率,并且μ的取值要适中来避免造成模型无法收敛或者收敛速度过慢的情况;γθ表示正则化系数,它是经过实验确定的,并且θ和γ通常取相同的值。此时基于因子分解模型(如式(1)所示)的过程可将评分预测表示为式(8)。
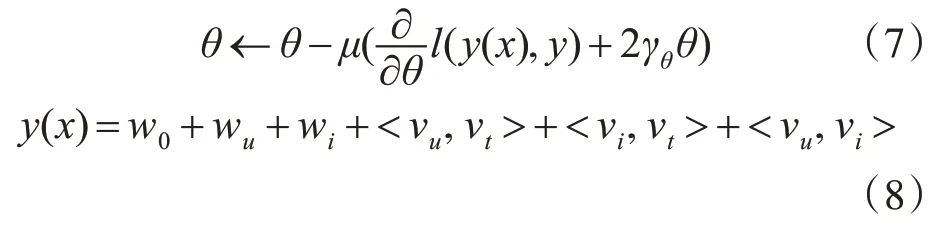
3.2 FM-CR算法时间复杂度分析
在传统的推荐系统中,若采用多项式回归进行学习,考虑特征数量为k,上下文因素的维数n,则需要学习的参数量为k(k-1)/2[13];而因式分解模型需要学习的参数量为k×n,并且上下文影响因素的维度n通常情况下是远低于特征数量k的,因此可认为该方法的一次完整迭代时间复杂度为O(nk)。
4.1 实验环境与实验数据
1)实验环境
实验环境是基于虚拟机VMWare10中的Ubun⁃tu操作系统,利用libFM软件中提供的SGD方法对数据进行学习训练,产生实验结果。
2)实验数据
实验采用由新浪提供的在线测评数据集,是目前公开的大规模数据集之一,通常用于用户社交关系的推荐研究。该数据集包含2300000位用户,6000个项目,108000000条数据记录,分为用户基本信息、用户关注的信息、关键词信息、行为信息、待推荐信息等[6]。
4.2 实验结果分析
1)准确度分析
本实验采用平均准确率MAP(Mean Average Precision)指标来衡量推荐的准确度,该指标体现了所推荐的结果中被用户接纳的比例[14~15]。计算方式如式(9)所示,式中N表示推荐列表中的项目数,这里取值为5,表示推荐列表中有5个项目,并计算出整体的平均准确率。n表示待推荐的项目集合,则ap@n表示用户对于推荐系统的总体接受程度,ap@ni表示用户对推荐集合n中第i个推荐对象的接受度,采用ap@ni=(i-1)/i的计算方式,表示待推荐项目集合n中的前i项均被用户考虑并且存在实际的接受项目;需要注意的是,当推荐列表中的第1项(即i=1时)就被用户接受时,此时ap@n1=1/1=100%。

例如,在5个待推荐的候选项目中用户实际接受了两个,分别是第1、4个,那么ap@5=(1/1+3/4)/5=0.35,即可认为用户对于当前的推荐结果接受度为35%;以此类推,当计算出所有用户的MAP值后,就可得出系统的整体推荐准确度,如式(10)所示。当整体的MAP值越大时,表示推荐的项目被用户接受的程度就越高,系统的推荐就越有效。
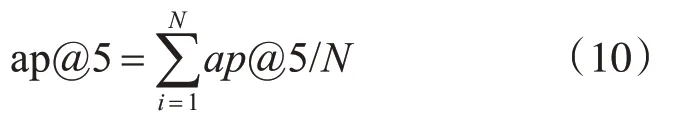
在将各上下文信息作为整体考虑的情况下,分别确定用户所具有的各类属性信息所占的权值。具体做法是:首先,通过交叉验证的方式计算出各个用户特征的权重,在本实验中是选取了用户的邻居数f1、用户的粉丝数f2、用户所处的上下文情景f3作为特征信息。其次,利用线性叠加的形式(式(11))得出用户的偏置参数B[16],其中fi表示特征i,θi表示特征fi所占的权重。

本文在基于上下文属性的影响程度的基础上,将结合因子分解的推荐算法与多项式推荐进行精确度比较,以此验证算法的有效性,比较结果如图1所示。从图中可看出基于多项式回归的推荐算法与本文提出的融合因子分解的推荐算法在推荐准确度方面差距不是很大,峰值出现在θ3取值为0.5(即“上下文”特征信息的权值为0.5)时,两者的MAP值相差最大,但是差值小于0.05;因此也可认为融合因子分解的推荐算法在考虑上下文特征信息的推荐精确度上基本与多项式回归的推荐算法相持平。
2)时间复杂度比较
本实验将融合因子分解的上下文推荐算法分别与基于奇异值分解的推荐算法和基于多项式回归的推荐算法在时间运行方面进行比较,结果分别如图2和图3所示。从图2中可以看出基于奇异值分解的推荐算法在耗时上明显高于本文提出的FM-CR算法,这是因为奇异值分解方法对于矩阵数据的训练需要大量的时间;而图3中FM-CR算法与基于多项式分解的算法在运行时间的差距上就相对缩小了很多,尤其是在上下文属性维度小于3时两者的差距并不明显,当属性维度大于3时,运行时间上才有了较为明显的差距。因此可以得出,当推荐算法中考虑的属性维度达到一定程度的时候,融合因子分解的推荐算法运行效率上较优于基于多项式回归的推荐算法。

图1 融合因子分解的推荐算法与多项式回归推荐算法的准确度比较
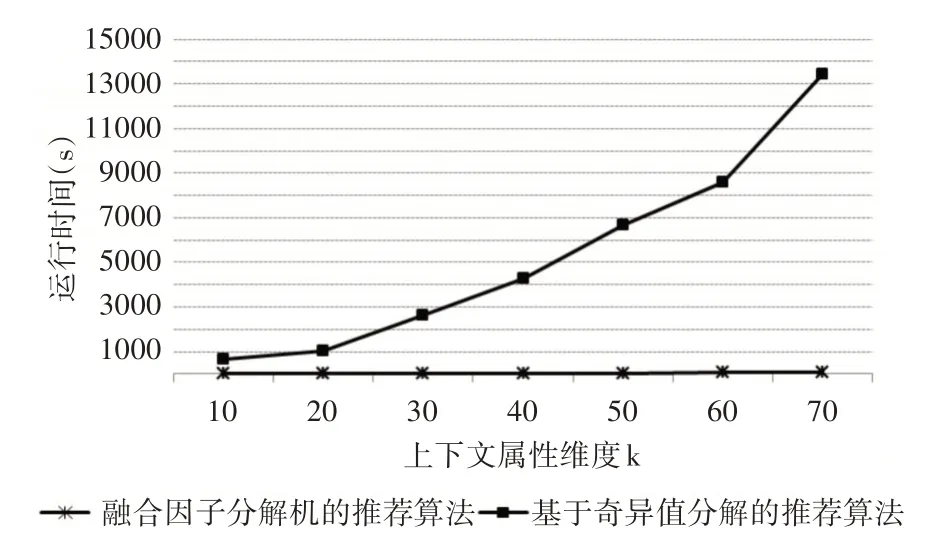
图2 融合因子分解的推荐算法与基于奇异值分解的推荐算法运行时间比较

图3 融合因子分解的推荐算法与基于多项式回归的推荐算法运行时间比较
5 结语
本文针对包含上下文信息的推荐系统进行了调研和研究,通过分析上下文情景推荐中常用的奇异值分解技术和多项式分解技术的特点与过程,针对其存在的问题进行新技术的尝试,提出了融合因子分解技术的推荐算法,并设计了验证用户对于推荐结果接受率和算法运行时间的实验,实验结果表明该算法具有一定的有效性,并且在时间复杂度方面有了较为明显的改善。未来的研究工作中,纵向上可以在此基础上继续研究不同的上下文特征信息对推荐结果准确性的影响程度,研究是否可以抽象出相关的规则来覆盖多种场景;其次,在时间效率方面,可以采用不同的数据处理平台,横向对比算法的性能变化特征,进一步提升算法处理的效率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
华人时刊(2018年17期)2018-11-19
数学学习与研究(2018年7期)2018-05-16
山东青年(2017年11期)2018-03-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
都市丽人(2015年4期)2015-03-20
