
基于随机森林的IP地址城市级定位方法研究∗
2021-06-29 08:42尹魏昕张云纯蒋彤彤
计算机与数字工程 2021年6期
蔡 颖 张 琨 尹魏昕 张云纯 蒋彤彤 方 悦
(1.南京理工大学计算机科学与工程学院 南京 210094)
(2.国家计算机网络与信息安全管理中心江苏分中心 南京 210019)
1 引言
互联网如今已成为信息时代不可或缺的支撑部分,截至2018年12月,我国网民规模达8.29亿[1]。随着网络与用户生活的联系愈发紧密,大量的网络服务都需要在通过IP对用户进行精准定位的前提下进行。例如,在网络管理领域,网络管理员可以通过IP测量快速定位网络错误发生的位置[2];在广告投放领域,商家可以通过IP精准定位用户所在的地理位置,从而进行针对性的广告投放[3];在网络安全领域,网络监管部门可以通过IP实现对网络犯罪分子的位置定位,有效降低网络违法案件的侦破难度[4]。IP作为重要的网络基础资源,是实现网络设备映射到用户实体、网络空间映射到地理位置的桥梁,因此实现IP地址定位对网络空间精准监管具有重要意义。
IP地址定位即根据网络设备的IP确定其在地理上的位置。在研究中,将具有IP的网络设备划分为测量点、基准点和待测点三类,其中测量点是指能向目的IP发起主动测量的网络设备,基准点是指地理位置已知且可对测量点所发数据包做出响应的网络设备,而待测点则是指需要实现地理位置定位的IP即待定位的网络设备[5]。
传统的IP地址定位方法总体上可分为基于推测和基于时延两类[6]。前者一般通过查询Whois数据库,或直接根据主机名来推测当前IP设备所处位置,代表算法包括IP2LL,GeoTrack和Visual⁃Route[6~8]等。基于时延的定位算法是结合网络拓扑信息,通过测定目标主机到测量点的时延,来估测目标主机的地理位置,代表算法有GeoPing,CBG,Posit和Octant[6,9]等。
传统的IP地址定位方法存在定位准确度差,算法复杂度高的问题。基于此,立足于江苏省内真实的IP数据,本文提出了一种基于随机森林的IP地址城市级定位方法,旨在利用已有的IP地址数据,首先从IP本身具有的特点,以及IP之间存在的关系出发,定义经过路由特征和地域触发特征,后结合机器学习中分类的思想,利用随机森林进行模型训练,实现IP城市级高准确度定位,从而可以有效辅助精确的定向广告投放、网络性能优化、社交网络推荐、攻击追踪溯源等实际应用的实现。
2 数据的获取与处理
由于电信、移动、联通等运营商之间的网络建设是相互独立的,因此为减少此类情况对分类器构建可能产生的负面影响,应对IP根据其所属运营商不同进行分类,并在同一类别下选择基准点,进而发起测量并记录相关数据。
2.1 主动测量
本文以江苏省内电信持有的IP为例,从中选取了近4000个IP作为基准点,同时选择网络带宽充裕且时延抖动较小的凌晨时段[10],由测量点向其发起主动测量。
本文中选取的测量方法为TraceRoute,即路由追踪。TraceRoute命令是利用ICMP协议来定位源IP与目的IP之间的所有路由器。根据该指令,可以获得测量点向基准点发出的数据包所经过的路由器数量,以及经过的每一个路由器所返回的时延和路由器信息[11]。其测量结果如图1所示。
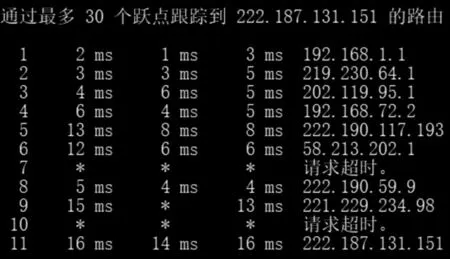
图1 主动测量示例
测量点向基准点发起TraceRoute命令,每一跳返回结果包括5项,表示为

式中,tracerti表示第i跳返回数据,routeIDi表示当前路由跳数,routeIPi表示途径路由器的IP地址 ,routeDelayi1,routeDelayi2,routeDelayi3表 示 三次发送数据包的返回时间。
测量中每次探测3次,若测量中第i跳的时延以delayi表示,则有:

式中,routeDelayij表示主动测量中第i跳第j次数据包返回时间,delayi取其最小值。因为时延包括发送、传播、处理和排队时延等,因此取最小返回时间可以进一步降低时延抖动带来的误差。
从测量点发起的路由追踪中,存在可追踪至目的IP部分路由路径,和可追踪至目的IP完整路由路径两种情况,分别采用下述两种方法进行测量数据的采集:
1)对于可追踪至目的IP完整路由路径的情况,则正常记录各跳路由跳数、时延和途径路由IP。对于追踪路径中存在的少数“请求超时”情况,此跳时延以默认时延计算,途径路由IP记作“*”。
2)对于可追踪至目的IP部分路由路径的情况,考虑到若路由可达,则一般在30跳内可以完成跳转的实际情况,因此仅记录30跳内的时延和路径。30跳内的各跳路由跳数、时延和途径路由IP的记录方法同1)所述。
经过上述处理后,得到测量点到基准点的主动测量数据为
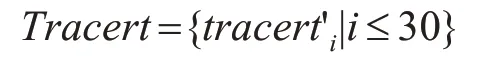
式中,tracert'i={routeIDi,delayi,routeIPi}表示第i跳测量数据。
进一步,若测量中路由跳数以routemum表示,时延以delaysum表示,路由路径以routeseq表示,则有:

式中,|Tracert|表示集合Tracert的模。
此外,在进行测量的过程中,得到的测量结果将由程序自动保存至数据库中进行存储。而为进一步训练分类器,还需要对数据进行预处理并构建标准的数据集。
2.2 特征提取
考虑到同一网络运营商往往会将连续的IP地址段分配给相同或相邻地区的实际情况,本文从IP地址本身具有的特点出发,将基准点IP以“。”字符为分隔符,分割为{ip1,ip2,ip3,ip4}四部分,作为一部分分类特征。
另一方面,从IP间的相关性出发,将测量点到基准点的时延delaysum和路由跳数routemum也纳入了训练分类器所要考虑的特征。
此外,考虑到运营商网络的拓扑以及用户的访问行为,本文将对经过路由特征和地域触发特征分别进行定义,并加入到分类特征中去。
定义1.经过路由特征。定义经过路由特征为测量点到基准点的路由路径routeseq所经过的城市骨干路由,以cityroute表示。
针对运营商网络拓扑,可以将路由器分为省级骨干网节点、市级骨干网节点和普通节点三类[4,12]。通常而言,归属城市不同的IP之间不允许互联,若跨市的两个普通节点间需要实现互访,则其数据流量必须经过骨干网节点。通过对测量得到的路由路径信息按城市进行分类,并分别采用PrefixSpan算法[13]进行关联规则挖掘,则可分析获得江苏省内13个大市的市级骨干网节点的网段特征。
若测量点到某城市所有基准点的路由路径数据集 为RtSeqc={routeseq1,routeseq2,…,routeseqn},其中routeseqi表示一个序列。若序列freseqj是序列routeseqi的子序列,则称routeseqi包含freseqj。序列freseqj在RtSeqc中的支持度,是指RtSeqc中包含freseqj的序列个数,记作sup(freseqj)。给定支持度阈值supΔ,若sup(freseqj)≥supΔ,则称freseqj在RtSeqc中是频繁的。现寻找RtSeqc中所有频繁的最长子序列:
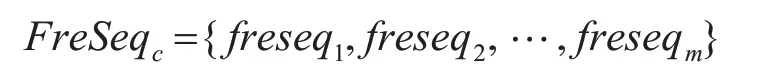
其中,c为当前城市代码,routeseqi为测量点到第i个基准点的路由路径,n为基准点总数,m为最长频繁子序列总数,且有m≤n,freseqj⊆routeseqi,i∈{1 ,2,…,n},j∈{1 ,2,…,m},FreSeqc则为该城市骨干网节点的网段特征。
进一步,判断测量点至基准点的路由路径是否经过某城市的骨干路由,即是否包含该城市骨干网节点对应网段下的IP,即:
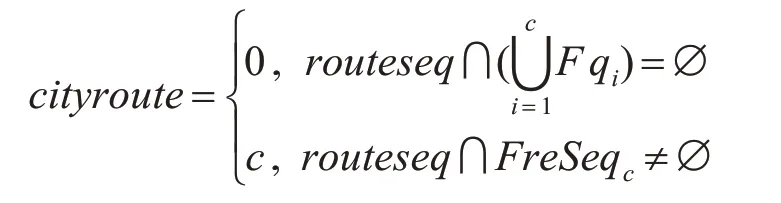
其中,城市代码c∈{1,2,…,13},如表1所示。

表1 江苏省内城市代码映射表
定义2.地域触发特征。定义地域触发特征为基准点发送的数据包中,包含的关键词所映射的城市,以cityword表示。
基于已有且真实的省内IP间传输的数据包信息,对基准点发送的数据包,提取其中与二级及三级行政区相关的关键词,并统计其出现次数,即将一个基准点发送的所有数据包处理为
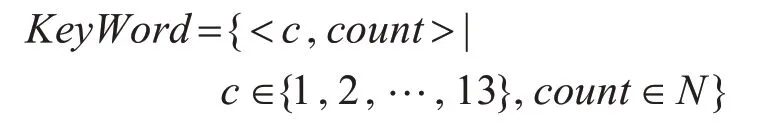
式中,<c,count>表示一个元组,c为城市代码,count为该城市对应关键词出现次数。将最大count所对应的城市代码,作为该基准点cityword的值,即:
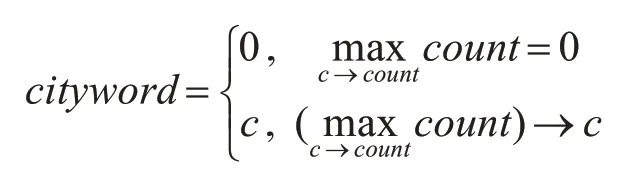
其中,c→count表示元组内城市代码和关键词出现次数的映射关系,表示count不为0时,最大count所对应的城市代码,城市代码如表1所示,城市相关关键词如表2所示。
2.3 构建数据集
综上,融合多维度特征,最终将形成包含基准点ip1,ip2,ip3,ip4,时延delaysum,路由跳数routemum,地域触发特征cityword,经过路由特征cityroute等8个特征在内,以基准点对应城市为分类目标的标准数据集合。若以D={X,y}表示该数据集,则其特征可用矩阵X表示,且有:
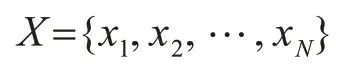
其中,N为该数据集中样本的数量,即从测量点发起主动测量的基准点总数,矩阵X中每一个行可用一个一维数组xi表示,其中包含了8个维度的特征,即有:

其中,y表示该数据集的分类目标,可用一维数组进行存储。对上述数据集使用随机森林训练分类模型并进行IP地址定位的方法将在第3节中进行详细描述。

表2 城市相关关键词
3 基于随机森林的IP地址定位方法
在机器学习中,随机森林(Random Forests)是指利用多棵决策树对样本进行训练并预测的一种分类器,其输出类别是由所有树输出类别的众数而决定的。该算法最早由Leo Breiman和Adele Cutler发展和推论形成[14],近年来因其在预测准确率方面存在的优势,随机森林算法被广泛应用于市场营销建模、医疗保健预测等多个领域[15~16],具有广阔的应用前景。
本文基于前期采集和处理得到的数据集,受此算法思想启发,提出了一种基于随机森林的IP地址定位方法。
3.1 算法描述
在随机森林算法中,“森林”是指决策树的集成。随机森林是在具有N个样本的数据集中,每次随机且有放回地抽取K个样本训练产生相应的决策树。由此,经过M次抽样后,便可得到M棵决策树。
对于本文所提算法中的任意一棵决策树而言,其构建的核心在于特征选择,即从样本数据的特征中选择一个作为当前节点的分裂标准。本文中,衡量分裂质量的性能采用了Gini不纯度函数。
对于第2节中处理得到的数据集D={X,y}而言,假设当前抽取出用于训练决策树的样本集为Di,则其分类后Gini不纯度为

对于Di包含的F个特征而言,若以特征fea⁃ture为分裂特征,则Di分裂后的Gini不纯度为

式中,c为城市代码,category为分类总数,在本文中即城市数量,pj为样本属于类别j的发生概率,Dij表示Di分裂后的一个子集。
进一步,遍历F个可能产生分裂的特征feature,分别计算按当前特征对Di进行划分后的Gini不纯度,按其值最小的特征分裂。
在本文所提算法中,而由于样本选取采用了随机抽样的方式,因此这M棵决策树之间是相互独立的,将这些决策树聚集在一起便形成了随机森林,其定位结果是由M棵决策树通过投票产生的。
值得注意的是,若原始数据集中每个样本的特征维度为F,则应指定一个常数f,每次随机地从F个特征中选取f个特征子集,当前决策树应从这f个特征中选择最优的特征进行分裂。模型训练流程如图2所示,其中{D1,D2,…,DM}表示第M次抽取出来用于训练决策树的样本集。
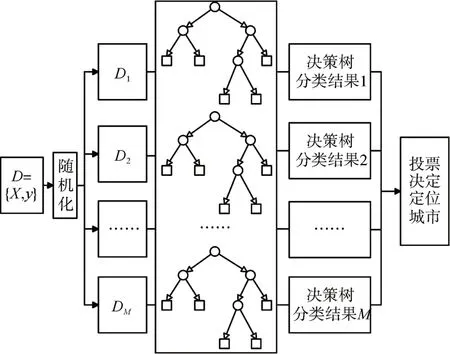
图2 模型训练示意图
由上可知,随机森林中每棵决策树的训练都是独立的。因此,虽然每棵树的分类能力有限,但是随机森林产生了大量随机树,相较于传统的决策树算法,具有更高自适应性。
综上,对于前期测量获得的大小为N的数据集D,基于随机森林的IP地址定位方法具体描述如算法1所示。
算法1.基于随机森林的IP地址定位算法
Input:数据集D,决策树数目n_estimators,单棵树样本数n_samples,特征选择标准criterion,特征总数F,特征选择个数max_features,待测点的特征xpre
Output:待测点的城市级定位结果ypre
S1:对数据集D包含的N个样本数据,每次随机有放回地抽取n_samples个样本作为一个样本集
S2:重复S1抽取n_estimators次,生成n_estima⁃tors个含有n_samples个样本的样本集
S3:针对每个样本集,随机抽取max_features(max_feature<F)个特征作为决策树的分类特征,并采用criterion为标准在每个节点上选取特征分裂,直到节点不可分为止
S4:重复S3直到所有样本集都被训练,从而得到n_estimators棵自由生长的决策树
S5:重复S1-S4直到模型准确率达到阈值,将n_estimators棵决策树组合成随机森林分类模型RFModel
S6:将待测点特征xpre输入RFModel,记录每棵树的分类结果,并投票产生分类结果ypre
在训练本文所提算法的分类模型时,应该使每棵树都尽最大程度的自由生长,且无需剪枝过程,即随机森林在训练过程中,每棵树的训练样本及分类特征都是随机选取的,同时分类结果并不由单棵决策树决定,因此随机森林相较于传统的决策树分类算法,并不容易陷入过拟合,并且具有更强的抗噪能力。
3.2 模型优化
随机森林的优化主要有特征选择和参数优化两个策略。本文所提算法在第2节中创新性地对经过路由特征和地域触发特征进行了定义,优化了特征。而此处将进一步对模型的参数进行优化。
基于随机森林的IP地址定位模型训练主要涉及到的参数包括框架参数和决策树参数两类。其中框架参数包括生成决策树总数n_estimators,特征选择标准criterion以及表示是否采用袋外样本评估模型的参数oob_score共3个。决策树参数主要包括特征选择个数max_features,最大深度max_depth,叶子节点最少样本数min_samples_leaf等共14个。其中,最主要的参数为n_estimators和max_features,这两个参数决定了模型的好坏以及训练的效率。
一般而言,n_estimators取值过小易过拟合,过大易欠拟合,同时训练过多的决策树也会导致耗时过长和浪费内存。而对于max_features而言,取值越大训练过程中模型能学习到的信息越多,但也会降低单棵决策树的多样性和训练速度,从而导致模型准确率下降。
为了优化算法,本文将数据集划分为训练集和测试集,而后分别改变n_estimators和max_features取值,重复训练,以模型的分类准确率为依据进行参数优化,其具体结果将在第4节中详细阐述。
4 实验验证
为验证本文提出的基于随机森林的IP地址城市级定位方法,本节将从模型评价及基于真实准确的IP地址数据集交叉验证两个方面,对所提定位方法进行实证分析。
4.1 数据描述
本文实验数据来源于南京理工大学与国家计算机网络与信息安全管理中心江苏分中心联合建立的江苏省研究生工作站。实验部分以南京某IP为测量点,对江苏省内共3994个基准点发起了主动测量,其部分数据库表信息如图3所示。
包含基准点ip1,ip2,ip3,ip4,时延delaysum,路由跳数routemum,地域触发特征cityword,经过路由特征cityword等8个特征在内,以基准点对应城市city为分类目标的数据集D,其数据组成如图4所示,其中横坐标为城市,纵坐标为对应数据量。

图3 数据库中存储的部分测量数据

图4 数据集组成
4.2 参数优化
为了平衡适中地选择最佳参数,以达到本文3.2节中所述模型优化的效果,在实验过程中,对数据集按7∶3的比例划分训练集和测试集,并分别改变n_estimators和max_features取值,重复随机森林模型训练,以测试集的分类准确率为依据进行调参。
实验中除n_estimators和max_features外,crite⁃rion='gini'表示以Gini不纯度作为特征选择标准,bootstrap=True表示构建决策树时采用随机有放回的方法抽取样本集,max_depth=None表示每棵决策树会分裂至所有叶子纯净,oob_score=True表示使用袋外样本来估计模型的泛化精度,剩余11个参数取default值。测试集准确率随参数变化情况如图5所示。
如图5(a)所示,当指定max_features为7时,测试集的准确率随n_estimators的增大而上升,当n_estimators变化至500左右时,测试集准确率趋于稳定。
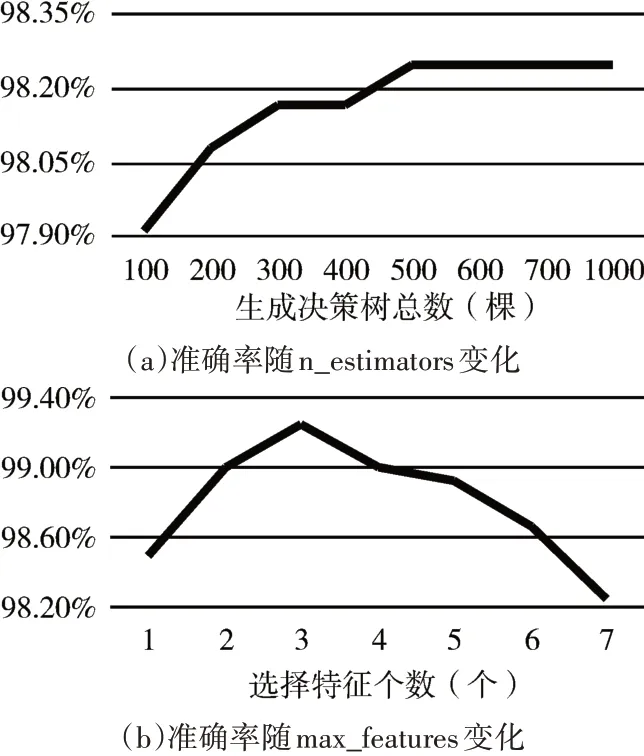
图5 测试集准确率随参数变化示意图
如图5(b)所示,当指定n_estimators为500时,测试集的准确率在一定范围内随max_features的增加而上升,但当max_features大于3时,单棵决策树的多样性逐渐降低,大量决策树趋于相似,从而导致模型准确率开始下降。
综上,经过参数优化后,本文实验将在n_esti⁃mators=500和max_features=3的前提下进行。
4.3 结果及分析
取n_estimators=500和max_features=3,训练集与测试集的数据量比例为7∶3,其余参数与调参过程中的取值一致。通过多次重复实验,得到的袋外分数及测试集准确率如图6所示,其中横坐标表示实验的次数。
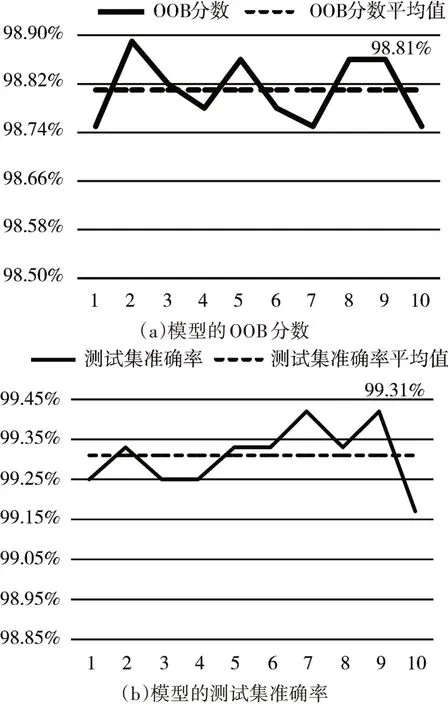
图6 算法模型性能
图6中的OOB分数即为随机森林训练模型的袋外分数。由于在随机森林算法中,构建决策树采用的是有放回的随机抽样,因此根据概率论可知,数据集中约有1/3的数据是没有被选取的,这部分数据也被称作袋外数据(Out Of Bag,OOB)。在模型训练的过程中,可以将OOB作为测试样本来衡量模型的好坏,在样本数量确定的情况下,袋外分数越高说明模型的泛化能力越好,性能更佳。
另外,通过衡量不同特征时的袋外分数,得到的基准点ip1,ip2,ip3,ip4,时延delaysum,路由跳数routemum,地域触发特征cityword,经过路由特征cityroute等8个特征的重要性如图7所示。
由图7可知,本文所定义的8个特征中,按重要性降序排列依次为经过路由特征cityroute,ip2,时延delaysum,ip3,ip1,ip4,路由跳数routemum和地域触发特征cityword,这说明IP定位结果与运营商网络拓扑、数据包传输时延和运营商分配IP的习惯关联性更大。
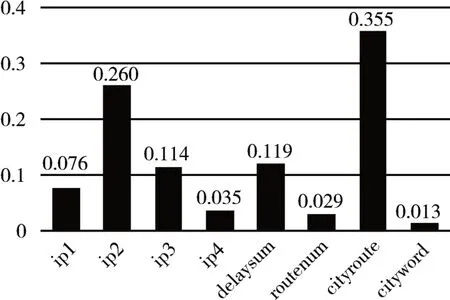
图7 特征重要性示意图
而由图6数据可知,本文所提出的基于随机森林的IP地址定位方法,模型泛化能力好,且在城市级的定位中平均准确率可达99%以上,完全满足实际应用中对于定位准确度的要求。
除此之外,实验中还将使用基准点之外的一组IP,通过对比本文所提方法的定位结果,与主流IP定位工具的定位结果之间的重合率,进一步衡量本文所提方法的可信度和实用性。
在江苏省内13个大市中每个城市随机选择电信IP进行测量(其中可追踪到完整路由路径和可追踪到部分路由路径的IP至少各一个),并使用本文所提算法进行了定位,其结果与主流IP定位工具的定位结果,在城市级上完全相同。部分结果如表3所示,由于IP自身的敏感性,因此对于选取IP的详细信息进行了脱敏处理。由定位结果比对可知,在城市级定位上,本文所提方法的定位结果与主流IP定位工具的定位结果精确度一致。
因此,本文所提的基于随机森林的IP地址定位方法在对IP进行城市级定位的需求下,定位准确度高,具有较高的可信度。
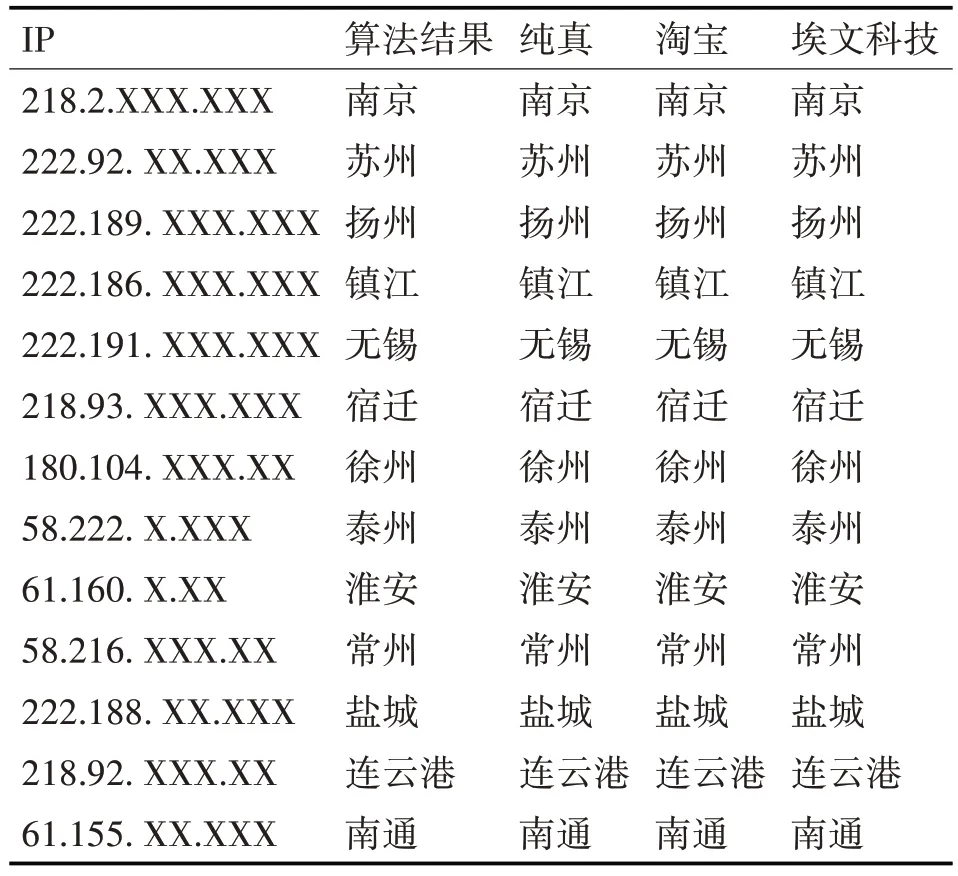
表3 定位结果对比
此外,本文所提出的基于随机森林的IP地址城市级定位方法,其时间复杂度为O(M(mnlogn)),其中n为样本数,m为特征数,M为决策树棵数。进一步,通过对模型训练时长和IP定位响应时长进行统计,可以得到,利用随机森林算法对包含3994个样本的数据集进行模型训练平均耗时约2.32s,而根据输入特征对单个IP进行城市级定位平均耗时约为0.06s。因此,本文所提的基于随机森林的IP地址定位方法在对IP进行城市级定位的需求下,反应快耗时短,具有较高的实用性。
5 结语
针对传统IP地址定位方法定位准确度差的缺陷,本文立足于江苏省内真实的IP数据,提出了一种基于随机森林的IP地址城市级定位方法。该方法旨在利用已有的IP地址数据,从IP本身具有的特点,以及IP之间存在的关系出发,创新性地定义了经过路由特征和地域触发特征,后结合机器学习中分类的思想,利用随机森林进行了模型训练,从而实现了对IP所处城市的准确定位。
实验结果表明,本文基于随机森林算法训练的分类模型准确率可达99%以上,并且基于该模型得到的定位结果与主流IP定位工具的定位结果一致。同时由于随机森林算法具有模型训练时间短且无需进行复杂调优的特点,本文所提方法实现IP城市级定位的响应时间可达毫秒级别,因此可高效适应定向广告投放、网络性能优化、社交网络推荐、攻击追踪溯源等实际应用的需求。
总体而言,本文所提出的基于随机森林的IP地址城市级定位方法准确率高,运行耗时少,但其定位精度仅到城市级别,因此本文下一步工作将致力于研究如何利用已有数据实现IP地址更高精度定位,如定位至区县街道。
猜你喜欢
科学与信息化(2019年28期)2019-10-21
山东工业技术(2017年24期)2017-12-29
西部资源(2017年3期)2017-07-05
敦煌研究(2017年3期)2017-07-05
科学与财富(2016年32期)2017-03-04
中国信息技术教育(2015年22期)2015-09-10
新课程·上旬(2014年6期)2014-08-22
决策与信息·下旬刊(2013年1期)2013-03-11
网络与信息(2009年7期)2009-07-11
中国三峡建设(2004年1期)2004-01-11
