
基于AdaBoost-BOA的中小企业信用评估模型∗
2021-06-29 08:42涂著刚李正军
计算机与数字工程 2021年6期
涂著刚 李正军 杨 敏
(贵阳高新数通信息有限公司 贵阳 550014)
1 引言
我国现有商业银行尚未建立较为完善的信用风险评估系统,其风险管理工作主要由信贷员完成[1],帮助商业银行规避中小企业信贷风险,构建一套科学严谨的中小企业信用评估模型,对我国经济发展的转型具有重要意义,也是我国商业银行信用风险管理的迫切需要。
商业银行对中小企业的信用评级主要可以分为两部分,第一部分为构建中小企业信用评级指标体系,第二部分为评级模型及其方法。本文首先量化处理中小企业信用信息,建立信用评级指标体系,然后将AdaBoost学习方法[2~3]与中小企业信用评级结合,采用贝叶斯优化算法[4]来构建集成信用评估模型。该模型为商业银行在中小企业的的信用风险管理工作提供了参考,提高了银行信贷人员的工作效率,降低了银行对中小企业信贷的风险。
2 中小企业信用评估指标模型
针对我国商业银行在面向中小企业的信贷风险评估管理方面尚未建立科学严谨的信用评级制度,本文对中小企业信用评估进行研究,其影响因子主要包括财务因素和非财务因素。财务因素主要来源于企业财务报表中的财务指标[5],而非财务因素涉及较广[6],对于借贷公司法人和股东的背景、社会关系难以进行定量分析,在一定程度上增加了难度。
根据国内外著名的评级机构[7~8]以及我国的商业银行的评级体系,再结合我国中小型企业的特征和发展现状,本文建立以下更适应我国国情的中小型企业信用评级指标体系。

表1 中小企业信用评级指标体系
3 构建基于AdaBoost-BOA的中小企业信用评估模型
3.1 AdaBoost集成学习算法
Freund在1995年提出了AdaBoost(Adaptive Boost)算法[9],该算法的思想是每迭代一次,增加一个弱分类器。在本文的AdaBoost[10~11]中,每轮迭代中被正确分类的样本在下一轮的训练中被选中的概率降低,而被错误分类的样本则更有可能被选中,迭代中依次训练弱分类器的权值,然后将其加权组合成一个强分类器。算法流程如下。
1)首 先 对 样 本 训 练 集X={(x1,y1),(x2,y2),…,(xM,yM)}初始化训练权值分布,其中yi(i=1,2,…,M)表示训练样本的类别标签。每一个训练样本最开始都被赋予相同的权值:wi=1/M,这样训练样本集的初始权值分布D1(i)为

2)进行迭代
(1)分别利用不同的弱分类器对训练样本集X进 行 分 类 ,创 建 新 的 样 本 训 练 集Xk={(xk,1,yk,1),(xk,2,yk,2),…,(xk,M,yk,M)},并计算其在权值分布D上的误差为
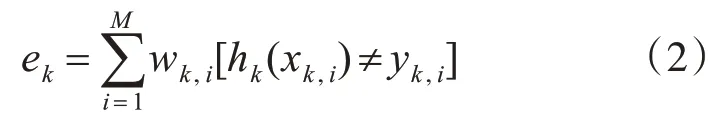
(2)选取误差最小的分类器h作为第k个基本分类器hk,计算该分类器在最终的强分类器中所占的权重:
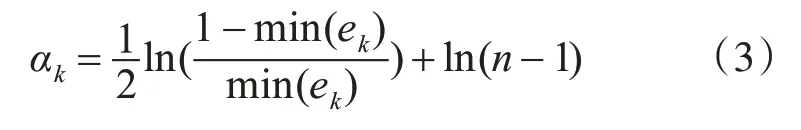
其中n表示样本的类别数目。
(3)更新训练样本的权重Dk+1:

(4)归一化Dk+1(i)。
3)按照步骤2)的公式迭代分别求出弱分类器的权重系数。最后将弱分类器加权组合成一个强分类器。
3.2 贝叶斯参数优化
贝叶斯优化算法(Bayesian Optimization Algo⁃rithm,BOA)的核心思想是基于概率代理模型[12],在函数未知的情况下,根据已有采样点以及它们之间的联系得到预估函数的最大值。该算法速度快,迭代次数少,广泛应用于机器学习和人工智能领域。
3.3 AdaBoost-BOA信用评级模型的算法流程
本文在已有研究的基础上,选择出对模型具有重要影响的参数,通过贝叶斯优化算法[13]对参数进行估值,得到最优参数组合,其后利用最优参数组合构建AdaBoost-BOA模型[14~15]。在模型中,每次迭代时样本被弱分类器分类,选择出错误率最小的分类器并计算权重,迭代结束即可得到加权组合的强分类器。算法流程如图1。

图1 AdaBoost-BOA信用评级模型算法流程
4 实验设计及结果分析
4.1 样本数据的预处理
样本数据的预处理是首先对原始数据集进行评价指标的选取和缺失值处理,然后对数据进行离散化和归一化,再将样本数据进行分组得到训练样本和测试样本。流程如图2所示。
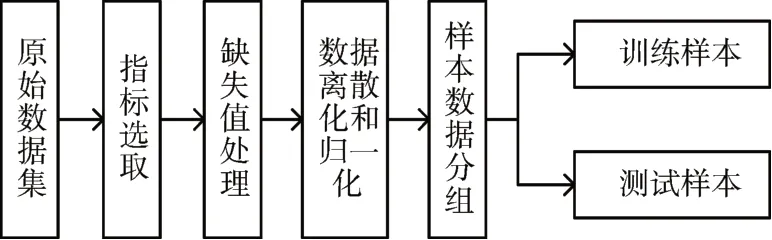
图2 数据预处理流程图
4.2 分类性能及评价指标
BS(Brier Score)是一个统计学指标,主要用来评价频率预测准确度,取值范围为0~1,其值越靠近0,预测准确度越高。
ROC(Receiver operating characteristic curve)曲线常用来评价分类器在二分类时的性能,AUC(Ar⁃ea Under Curve)是ROC与横纵坐标形成的面积,其值越大,分类性能越好。
4.3 实验结果
在本文中,选用了经典的AdaBoost、K近邻判别法(KNN)、XGBoost模型、BP神经网络以及GB⁃DT,通过利用AUC和BS这两个分类性能评价指标对这些模型与本文提出的AdaBoost-BOA进行分析对比。
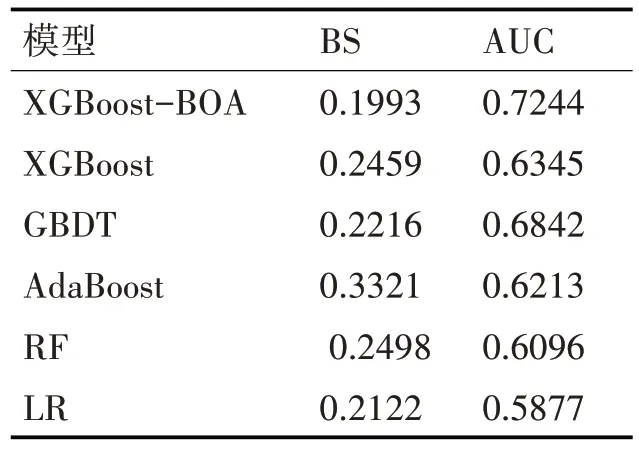
表2 信用数据集分类模型对比结果
从表2中AUC和BS这两个评价指标可以看出,本文提出的AdaBoost-BOA的分类性能最高。
5 结语
针对我国商业银行在中小企业信贷管理方面尚未建立完善的信用评估体系,本文结合贝叶斯优化算法构建了基于AdaBoost-BOA的中小企业信用评估模型。实验结果显示,与传统的模型相比,本文提出的AdaBoost-BOA能够得到更小的BS和更大的AUC,表明本文提出的模型具备优良的分类性能,比其他常见的分类模型应用到中小企业信用评级准确率更高。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
软件导刊(2017年4期)2017-06-20
股市动态分析(2016年22期)2016-12-27
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
投资与理财(2009年8期)2009-11-16
钱经(2009年7期)2009-08-12
钱经(2009年7期)2009-08-12
