
SM4算法的FPGA优化实现方法
2021-07-01 14:27何诗洋李凤华
西安电子科技大学学报 2021年3期
何诗洋,李 晖,李凤华,3
(1.西安电子科技大学 大数据安全教育部工程研究中心,陕西 西安 710071;2.西安电子科技大学 网络与信息安全学院,陕西 西安 710126;3.中国科学院 信息工程研究所,北京 100093)
随着人类社会的高速发展,信息交互和数据生成总量呈井喷式增长;由此所带来的隐私泄漏、消息窃听和内容篡改等问题层出不穷,这些问题已经严重影响到社会公共秩序,甚至威胁国家安全。因此,信息安全已经成为人们关注的焦点。
数据加密是保证信息安全的重要手段之一,当前,主流加密算法主要分为对称密码算法和非对称密码算法。与非对称密码算法相比,对称密码算法具有简洁高效、部署容易、加/解密速度快等优势,被广泛应用于数据加密场景中。
在对称密码算法中,数据加密标准(Data Encryption Standard,DES)是目前全世界使用最为广泛的对称密码算法,它于1977年被正式批准作为美国联邦信息处理标准,随后该密码算法被广泛应用于军事、政治、商业等各个领域中。由于DES对称密码算法的密钥长度较短(仅为56 bit),随着人类计算能力的不断增强,该算法的安全性受到了极大威胁,美国国家保密局(National Security Agency,NSA)宣布,1998年后不再批准DES为联邦标准。2001年,美国批准使用新的对称加密算法高级加密标准(Advanced Encryption Standard,AES)替代DES,相较于DES,AES具有更长的密钥长度(128/192/256 bit)和更快的加/解密速度[1-2]。
2006年1月,在国家密码管理局发布无线局域网产品密码事宜公告中,SMS4密码算法成为中国首个被批准应用于无线局域网产品的对称密码算法[3]。2012年3月,在《祖冲之序列密码算法》等6项密码行业标准公告中,国家密码局批准《SM4分组密码算法》(原《SMS4分组密码算法》)为行业标准[4]。
与其他对称密码算法相比,SM4密码算法具有以下主要优势:① 安全性强。常用的对称密码算法(如DES)核心模块(S盒)的设计准则到目前还没有完全公开,是否留有陷门还无法得到证实[1],而SM4密码算法是由中国密码学家吕述望等[5]设计完成并获国家密码管理局批准的密码算法,与其他对称密码算法相比,安全性能够得到保障;② 效率高。在算法结构方面,轮密钥生成算法和加密算法结构相似;在算法加/解密流程方面,加/解密运算方法一致,只是轮密钥使用顺序相反;在算法计算方面,只包含异或、位移、置换等简单运算;③ 易于硬件实现。SM4的算法结构能够与FPGA器件的并行性、灵活性等特点充分结合,既能够采用循环型架构在资源受限的硬件设备中高效实现,又能够采用流水线型架构在资源丰富的硬件设备中高速实现。
现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)是一种可编程半定制电路,它比专用集成电路(Application Specific Integrated Circuit,ASIC)更加灵活,主要由可编程逻辑功能块、可编程输入/输出块、可编程内部互联资源等组成。FPGA具有可重复编程、灵活性、并行性、低功耗等众多优良特性,并被广泛应用于密码算法实现、图像处理、信号处理等众多领域。
SM4密码算法不仅易于硬件实现,而且能够充分利用硬件的特有优势提升效率或提高性能。在硬件实现SM4密码算法中,有很多学者进行了详细的研究和分析。具体实现架构主要分为两类:① 基于循环的电路架构,需要约32个时钟循环完成一次加/解密。该方案能够最大程度地节省硬件资源,适合部署在资源受限的设备上;② 基于流水线的电路架构,在电子密码本模式(Electronic Code Book mode,ECB)下,仅需1个时钟循环即可完成一次加解/密。它的优势是吞吐量大,能够达到20 Gb/s以上,但是资源消耗巨大,适合部署在资源丰富的设备上。
GAO等[6]提出SM4密码算法硬件实现的循环型(rolling)和非循环型(unrolling)架构。在整体架构中,加/解密使用同一套电路实现,轮密钥生成后存储在寄存器中随时取用,避免重复计算,在Straitx II FPGA平台上实现,循环型架构吞吐量可达约0.54 Gb/s,资源消耗为1 552个自适应逻辑模块(Adaptive Logic Module,ALM),非循环型架构吞吐量可达20.74 Gb/s,资源消耗为8 373个ALM。JIN等[7]提出折叠(folded)型和流水线(pipelined)型SM4硬件实现架构,在Virtex-4 FPGA平台上实现。折叠型硬件架构每36个时钟循环完成一次分组加密,其中4个时钟循环用于缓存,32个时钟循环用于计算,共消耗380个逻辑单元(SLICE)和4个块随机存取存储器(Block Random Access Memory,BRAM),加密吞吐量达0.74 Gb/s,流水线型硬件架构消耗9 500个SLICE,吞吐量可达24.32 Gb/s。随后,YAN等[8]基于超大规模集成电路(Very Large Scale Integration,VLSI)平台设计实现SM4算法折叠型硬件架构,在0.13 μm CMOS技术下消耗22 000个门电路,加密吞吐量能够达到800 Mb/s。在前人的工作基础之上,GUAN等[9]考虑在性能和资源方面进行权衡,提出了包括Resource-first、Balance-4、Balance-8、Balance-16、Speed-first等5种实现架构方案,并针对不同架构进行了设计优化。其中Resource-first架构采用Moore型状态机控制整个迭代加/解密计算,密钥生成和加密操作同时进行;Speed-first架构采用32轮流水线迭代,在每层迭代电路间插入32 bit的寄存器保证流水线结构。在Straitx IV FPGA平台上实现,Resource-first架构消耗687个查找表(Look Up Table,LUT)和448个触发器(Flip Flop,FF),每33个时钟循环完成一次加/解密,吞吐量可约达0.82 Gb/s,Speed-first架构消耗7 667个LUT和5 438个FF,每1个时钟循环完成一次加/解密,吞吐量可约达27.153 Gb/s。ZHAO等[10]考虑采用软硬件结合的方式实现SM4密码算法,轮密钥生成与加密计算分开进行,使用主机完成32个轮密钥的计算,使用FPGA完成加密操作。在加密模块中,作者创新性的提出双层蝶形架构,将32轮迭代循环从32个时钟循环消耗压缩为16个时钟循环消耗,大幅度提升加密效率,作者在Kintex UltraScale平台上实现该架构,共消耗1 365个LUT和1 351个FF,吞吐量可达1.9 Gb/s。
SM4密码算法作为国家密码局批准的对称密码算法具有安全性强、效率高和易于硬件实现等特点,在数据加密方面受到了广泛的关注。但是在面对不同应用场景下,SM4算法的高效实现和部署还有进一步提升和优化的空间。文中面向资源节约型优化、资源平衡型优化和加密性能型优化等3个方面,提出并设计了1种循环型硬件架构和3种流水线型硬件架构。在循环型架构设计方面,硬件架构中轮密钥生成模块和加密模块并行执行,既提升了加密效率,同时又将新鲜的轮密钥直接用于加密,无需设计额外寄存器存储轮密钥,能够节省大量寄存器消耗;与当前先进的硬件架构相比,性能提升,且资源消耗下降明显。该架构拓宽了在资源受限场景下(如移动终端设备、物联网设备等)SM4算法的部署和应用。在流水线型架构方面,文中提出基于LUT、BRAM、BRAM+REGISTER等3种架构,在BRAM流水线型架构中,文中以消耗33个BRAM的代价,将LUT的消耗量降低为原来的约30%,进一步平衡了硬件资源使用,提高了资源利用率,使SM4算法能够部署在更多硬件平台上,进一步拓宽了SM4算法部署的广泛性。在BRAM+REGISTER流水线型架构中,进一步优化关键路径,提高运行频率,使加密吞吐量达到42.10 Gb/s,解决了在加密性能要求较高的场景(如云服务器、大数据加密等)下,SM4算法的高效应用和部署问题。
1 SM4密码算法原理
SM4算法是一个分组加密算法,消息分组和密钥长度均为128 bit,主要包括密钥扩展算法、加密算法和解密算法。算法采用32轮非线性迭代结构,加密和解密算法结构相同,只是轮密钥使用顺序相反。
1.1 SM4中的主要参数和术语
文中所用的符号说明见表1。

表1 符号说明
(1) 轮函数F。
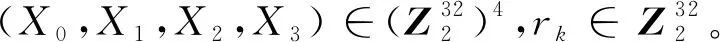
输出:F(X0,X1,X2,X3,rk)=X0⊕T(X1⊕X2⊕X3⊕rk)。
(2) 非线性变换τ。
输出:τ(A)=(Sbox(a0),Sbox(a1),Sbox(a2),Sbox(a3))。
(3) 线性变换L。
输出:L(B)=B⊕(B<<<2)⊕(B<<<10)⊕(B<<<18)⊕(B<<<24)。
(4)线性变换L′。
输出:L′(B)=B⊕(B<<<13)⊕(B<<<23)。
图1所示为S盒的结构图。
图1 S盒结构
1.2 SM4中的主要算法
(1) 加/解密算法。
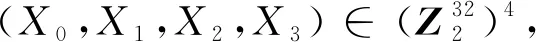

①Xi+4=F(Xi,Xi+1,Xi+2,Xi+3,rki)=Xi⊕T(Xi+1⊕Xi+2⊕Xi+3⊕rki),i=0,1,…,31,连续迭代32轮。
② (Y0,Y1,Y2,Y3)=R(X32,X33,X34,X35)=(X35,X34,X33,X32),将迭代结果顺序进行翻转,得到加密密文。
解密算法与加密算法过程相同,轮密钥的使用顺序相反,为(rk31,rk30,…,rk0)。
(2) 密钥扩展算法。

输出:轮密钥rki,i=0,1,…,31。
① (K0,K1,K2,K3)=(MK0⊕FK0,MK1⊕FK1,MK2⊕FK2,MK3⊕FK3)。
②rki=Ki+4=Ki⊕T′(Ki+1⊕Ki+2⊕Ki+3⊕CKi),进行32轮迭代运算,得出32个轮密钥。
2 SM4密码算法的硬件实现
针对SM4密码算法的硬件设计,分为循环架构和流水线架构两种。循环架构面向资源节约优化,使SM4密码算法能够轻易部署在资源受限的硬件设备上;流水线架构面向加密性能优化,分别采用基于LUT、BRAM、BRAM+REGISTER的架构设计,使SM4密码算法能够部署在对吞吐量要求较高的场景中。
2.1 面向资源节约优化的循环硬件架构
循环硬件架构主要由控制模块、轮密钥生成模块、加密模块等3个模块组成。整体架构如图2所示。该设计架构在控制模块的协调下,轮密钥生成模块与加密模块并行执行,能够带来多种优势。首先,轮密钥生成模块产生的新鲜轮密钥直接传递给加密模块进行迭代计算,不需要使用额外的寄存器来存储轮密钥,大约能够节省32×32=1 024个FF;其次,两个模块并行执行,当密钥更新时,轮密钥生成模块可以实时计算最新的轮密钥,加密模块无需等待,整个加密过程能够连续进行;最后,轮密钥生成模块和加密模块在整个分组数据加密过程中所需要的时钟循环为常数,能够有效抵抗侧信道攻击。该设计架构完成1次分组数据加密需要轮密钥生成模块和加密模块循环执行32次,加密模块比密钥生成模块晚启动1个时钟循环,完成1组数据加密共需32个时钟循环。
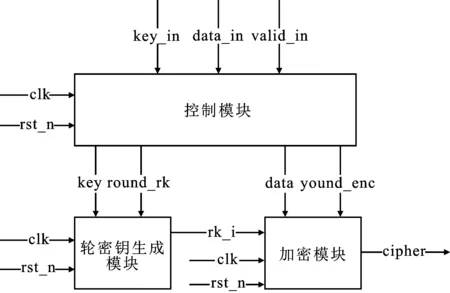
图2 循环型架构
控制模块主要由计数器和Moore型状态机构成,负责根据输入密钥、待加密数据和控制信号等,生成round_rk和round_enc信号控制轮密钥生成模块和加密模块,进行32轮迭代加密计算。
轮密钥生成模块主要由S盒模块、CK参数模块、多路选择器、异或电路和寄存器等构成。架构如图3所示,其中S盒使用4个并行的LUT组合逻辑实现,能够进一步简化电路,减少资源消耗;CK参数模块同样采用LUT组合逻辑实现。在控制模块round_rk信号控制调节下,轮密钥生成模块每个时钟循环完成一次迭代运算,生成当前的轮密钥rki,并传递给加密模块,用于下一步加密计算。
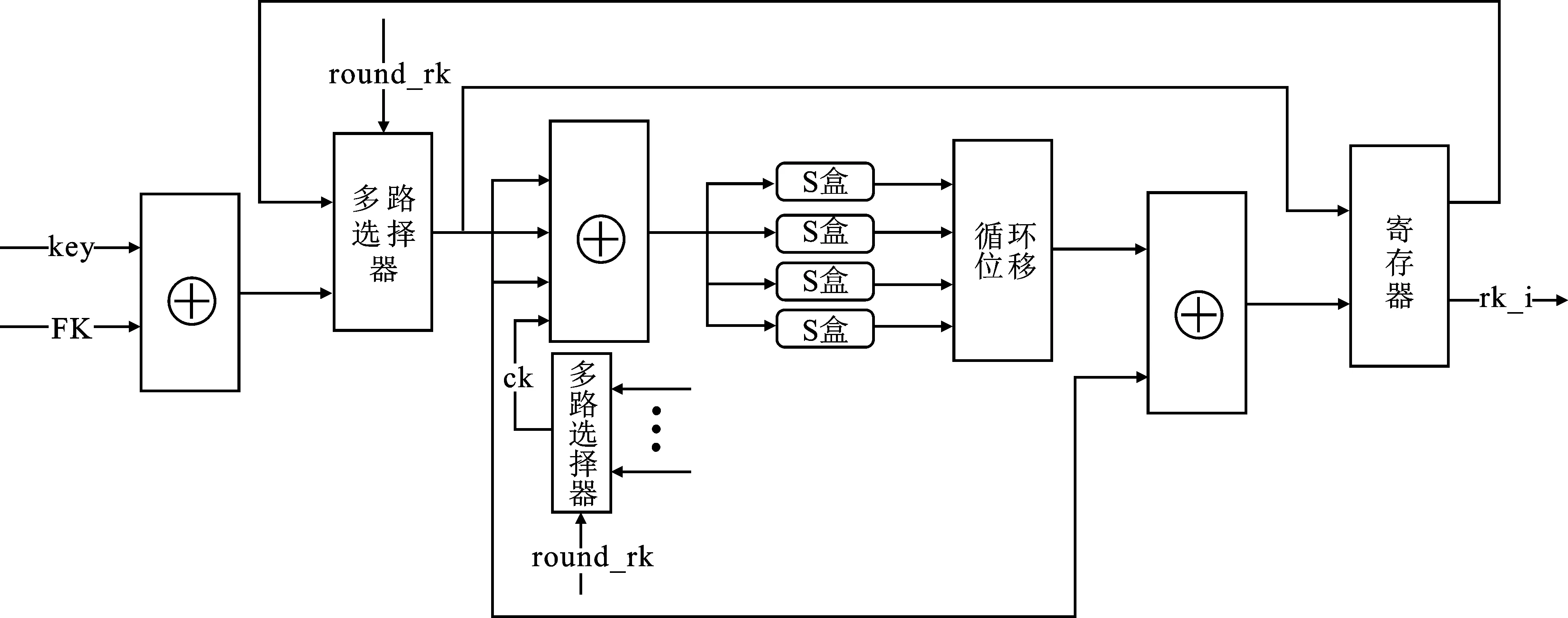
图3 循环型轮密钥生成模块架构
加密模块与轮密钥生成模块类似,主要由S盒模块、多路选择器、异或电路、寄存器等构成。架构如图4所示,S盒使用4个并行的LUT组合逻辑实现,能够进一步简化电路,减少资源消耗。在轮密钥生成模块的输出信号rki和控制模块round_enc信号控制调节下,加密模块每个时钟循环完成一次迭代运算,32轮迭代运算后输出密文。
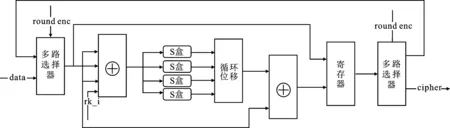
图4 循环型加密模块架构
2.2 面向性能优化的流水线硬件架构
流水线硬件架构主要由控制模块、轮密钥生成模块和流水线加密模块构成。整体架构如图5所示。
与循环硬件架构不同,并行流水线硬件架构面向性能优化,主要体现在:① 增加了轮密钥寄存器,轮密钥生成模块将32轮轮密钥存储在寄存器中,每个时钟循环都可以向加密模块输入当前轮密钥,保证流水线加密不间断;② 流水线加密模块实例化32套迭代加密电路,每套迭代电路间插入寄存器以保证加密过程流水线运行;③ 在S盒电路设计方面,文中采取3种方案。第1种是基于LUT的设计架构,第2种是基于BRAM的设计架构,第3种是基于BRAM+REGISTER的设计架构。第2种设计架构能够在BRAM用量增加不多且性能相差不大的前提下,大幅度降低LUT资源的使用。第3种设计架构采用带有输出寄存器的BRAM,同时对加密模块进行少许优化,在增加部分寄存器和32个额外时钟时延的代价下,能够约减关键路径,提高运行频率,进一步提高性能。由于采用流水线架构,在等待32(64)个时钟时延后,每个时钟循环即可完成一次分组数据加密,加密速度快,吞吐量大。
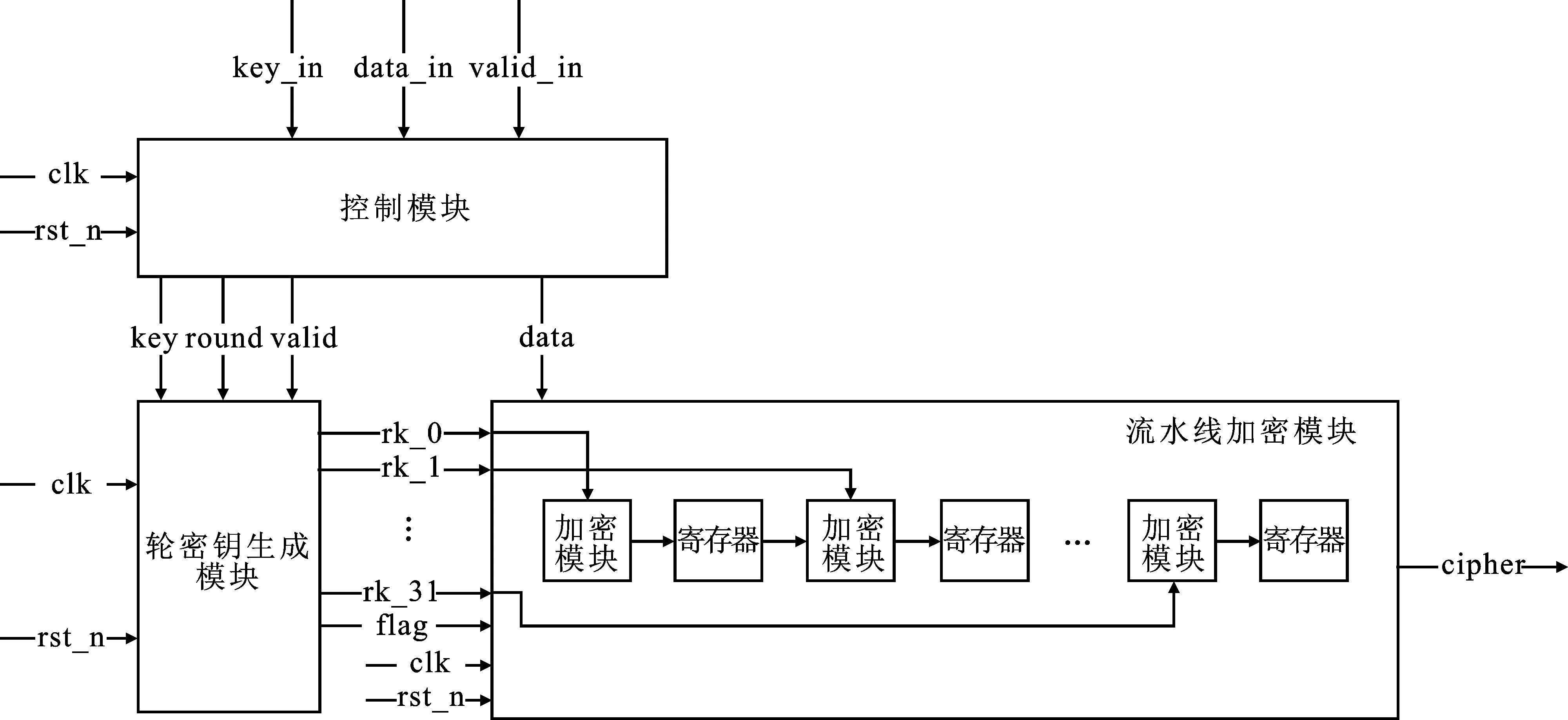
图5 流水线型架构
控制模块主要由计数器和Moore型状态机构成,负责根据输入密钥、待加密数据和控制信号等,生成round和valid信号,控制轮密钥生成模块进行32轮迭代加密计算并存入寄存器,间接控制流水线加密模块启动数据加密。
轮密钥生成模块和加密模块整体架构与循环型中两模块架构类似,主要不同在于S盒的设计。文中采用3种设计方法并在论文后半部分进行对比。第1种是基于LUT的设计,该方案与循环型架构中S盒的设计思路一致,均采用组合逻辑设计;第2种是基于BRAM的设计,该方案中,轮密钥生成模块和加密模块整体架构如图6和图7所示,通过引入双口BRAM资源,在增加33个BRAM资源消耗的代价下,能够直接减少32×4=128套S盒的LUT使用,进一步平衡资源利用;第3种是基于BRAM+REGISTER的设计,该方案总体架构与第2种类似,不同之处在于选取带有输出寄存器的双口BRAM,顺势将加密模块外的寄存器巧妙地插入模块中,不仅能够确保流水线系统的正常运行,而且可以进一步缩短关键路径,极大提高运行频率,但代价是增加部分寄存器消耗和增加32个时钟时延。

图6 流水线型轮密钥生成模块架构
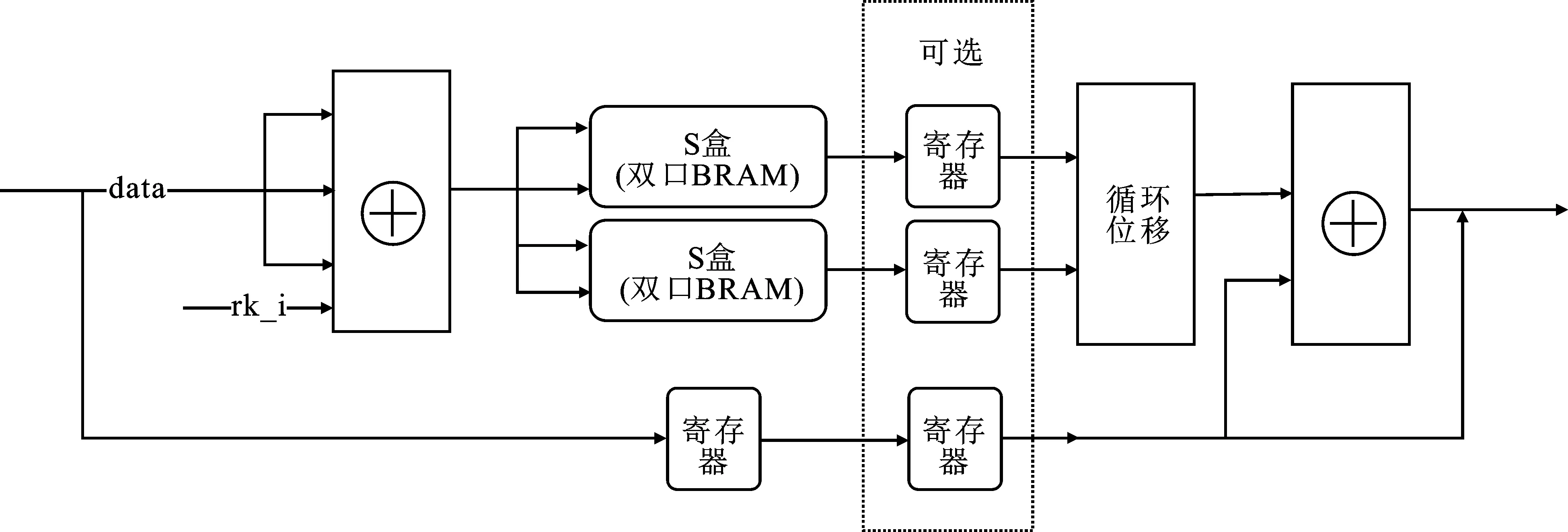
图7 流水线型加密模块架构
3 性能分析和比较
针对SM4密码算法设计和优化了循环型、LUT流水线型、BRAM流水线型和BRAM+REGISTER流水线型等4种硬件架构。并在XILINX KINTEX-7 XC7K325TFFG 900上实现,设计电路经过综合布局布线后,资源消耗和性能详见表2。
方案中的循环型架构设计主要采用1套轮密钥生成电路、1套加密电路和控制电路构成,整个架构消耗193个SLICE,运行频率约为333 MHz,吞吐量能够达到1.27 Gb/s,适用于对吞吐量要求不高且资源受限的场景。与先前学者提出的循环型方案相比(详见表3),该架构方案在资源消耗和吞吐量方面优势明显。首先,文中方案加密模块无需等待所有32个轮密钥生成后再启动,而是在轮密钥生成模块开始一个时钟循环后即启动加密,两个模块几乎并行执行,极大地提升了运行效率。与其他方案相比,吞吐量提升约54.9%;其次,文中方案中,轮密钥生成模块生成的当前轮密钥直接传递给加密模块进行加密。与其他方案相比,轮密钥无需储存,避免大量寄存器使用,能够节省约40.2%的FF消耗;最后,文中方案中,轮密钥生成和加密运行时钟循环消耗为常数,能够有效抵抗侧信道攻击。

表2 资源消耗和性能表现

表3 循环型架构资源消耗和性能对比
文中方案中的流水线型硬件架构主要采用1套轮密钥生成电路、32套加密电路和控制电路构成。在S盒的设计方面,采用基于LUT的设计方法和基于BRAM的设计方法。LUT流水线型架构共消耗7 466个LUT和5 158个FF,吞吐量为30.52 Gb/s。BRAM流水线型架构共消耗2 261个LUT、4 945个FF和33个BRAM,吞吐量为27.74 Gb/s,与LUT流水线型架构、GAO等[6]、JIN等[7]和GUAN等[9]架构相比,BRAM流水线型架构在吞吐量差别不大的前提下,以增加33个BRAM消耗为代价,大幅度节约了LUT资源,如将LUT消耗降低为LUT流水线型架构的约30%(减少5 205个LUT),平衡了硬件资源使用,提高了资源利用率。
在BRAM流水线型架构的基础上,文中进一步优化电路结构,提出BRAM+REGISTER流水线型架构,采用带有输出寄存器的BRAM,并在流水线加密模块架构中插入寄存器以保证流水线结构。与表4中其他方案相比,此方案极大地简约了关键路径,运行频率与原BRAM型流水线型架构相比,提升约51.5%,加密吞吐量可达42.10 Gb/s。但是由于电路中插入部分寄存器,增加了2 791个FF的消耗和32个时钟循环时延。
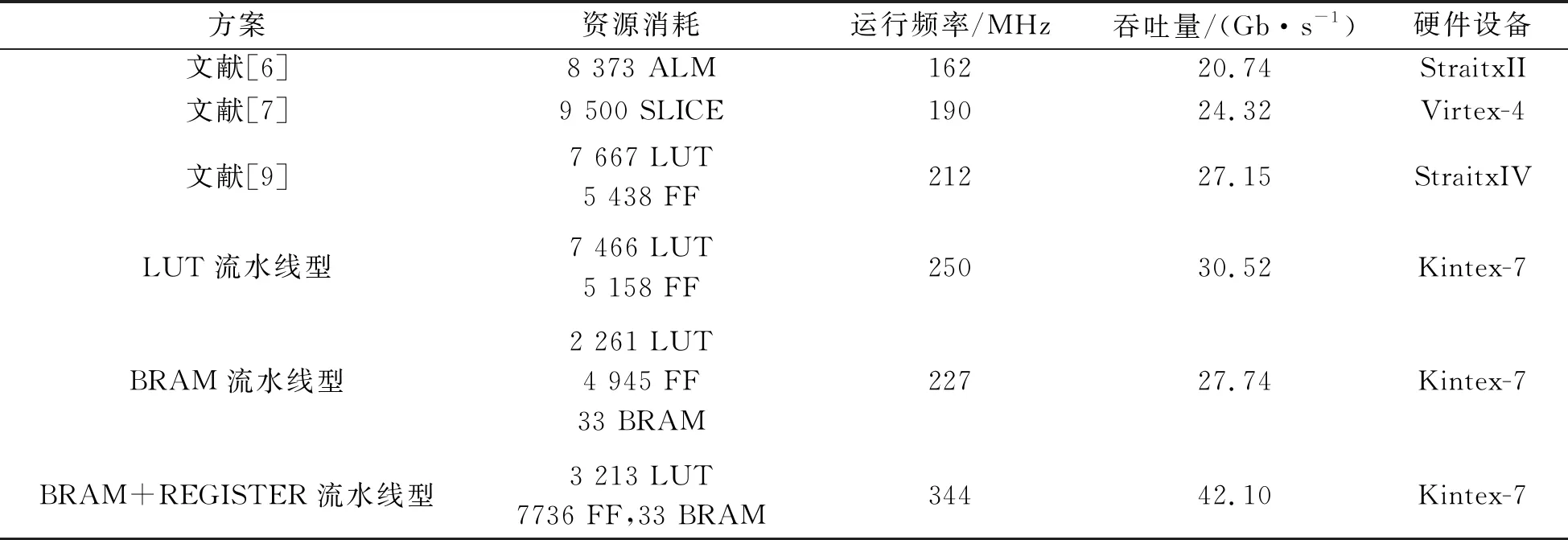
表4 流水线型架构资源消耗和性能对比
4 结束语
针对不同应用场景,笔者提出4种SM4密码算法硬件机构设计,包括面向资源优化的循环型架构和面向性能优化的流水线型架构。这4种硬件架构均在XILINX KINTEX-7 XC7K325TFFG900上实现。在循环型架构设计方面,文中方案轮密钥生成模块与加密模块几乎并行执行,寄存器资源节约明显;在流水线型架构设计方面,文中方案采用基于LUT、BRAM、BRAM+REGISTER的设计方案,不论是在资源消耗、权衡资源使用、性能等方面,对比先前学者提出的方案,都具有较为明显的优势。
猜你喜欢
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
当代工人(2020年4期)2020-05-11
儿童故事画报(2019年8期)2019-08-14
汽车工程师(2019年7期)2019-08-12
科技创新与应用(2018年23期)2018-09-13
计算机与网络(2018年2期)2018-09-10
电子技术与软件工程(2018年1期)2018-03-22
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
