
基于TextCNN的中国古诗文分类方法研究
2021-07-05 12:00史沛卓陈凯天钟叶珂雷向欣
电子技术与软件工程 2021年10期
史沛卓 陈凯天 钟叶珂 雷向欣
(华东理工大学 上海市 200000)
1 引言
“渭城朝雨浥轻尘,客舍青青柳色新”——清晨的细雨润湿了尘土,杨柳也显得青翠清新。如此明朗清新的诗句,一眼看去好像十分明快,但实际上这却是诗人王维以乐景抒悲情的手法。正是因为美妙的景色无法与朋友一起欣赏,王维才写出来以反衬自己对友人的惜别之情,这就是中国古诗文婉转曲折、含蓄蕴藉之处。一直以来,对中国古诗文进行风格分析都是一个有趣但困难的课题。仅仅凭借人的主观判断,很有可能对古诗句产生错误的理解,而机器学习在分类上具有优良的应用效果。计算机学界在这一领域也已经有一些相关的研究,我们能否尝试用机器学习和深度学习的方法,构建一个专门针对中国古诗文进行分类的模型呢?这正是本文进行探究的出发点。
当前,机器学习领域内对文本分类的应用大多数针对的是现代文本,而对古诗文领域进行研究的相关工作并不密集,这是因为针对古诗文构建分类模型具有更多的困难,有相关文献提到:文言文的字数少、语句精练,分类特征不显著,并且在经过数据预处理后得到的特征向量更少[1]。
在这一研究领域,文献[2]使用了朴素贝叶斯方法针对宋词进行风格判别,且使用信息增益和遗传算法进行特征选择,最高准确率达到88.5%,不过该研究的语料库和参数设置比较有限,并且朴素贝叶斯方法也属于比较老的方法。文献[3]应用了Scikit‐learn 工具包提供的多种机器学习方法实现了对宋词的豪放、婉约风格二分类,并进行了比较和回溯分析,但在数据集的选择上仍有缺陷:该文献提到,在他们进行数据处理时将公认为豪放派作家的作品视为“豪放”类,同样“婉约”类数据也是如此,但实际上豪放派作家也有少量作品是婉约风格,该文献的结语认为这样的数据处理方法引入了噪声。
文献[4]分别使用了基于卷积神经网络的TextCNN 方法、基于循环神经网络的TextRNN 方法和基于注意力机制的Bi‐LSTM+Attention 模型进行特征选择,能够对文本的局部关联特征进行捕捉,也可以很好地掌握上下文信息,提高了特征提取的质量以及分类器的精度。文献[5]提出的TextRCNN‐TextCNN 混合模型在英文数据集下能够很好地解决文本分类问题。我们可以看到,相比传统的机器学习方法,一些专用于文本分类的深度学习方法也具有良好的效果。
利用深度学习的方法,文献[6]使用TextCNN 构建模型,将古典诗词分为“爱国”和“其他”两类,并将其与经典的机器学习方法SVM 构建的分类模型进行比较,确定TextCNN 方法具有更好的效果,但是该文献仅仅进行了二分类。本文认为探讨多分类可能会具有更高的应用价值。
本文认为,我们旨在构建一个古诗文多分类模型,将上文提到的情感或风格作为有监督学习的标签会带来数据集构建的困难。情感或风格是主观性较强的标签,经过检索,我们无法找到数据量大到可以避免过拟合的以情感为分类标签的诗句,文献[1]甚至在数据处理阶段对950 首唐诗采用人工手动标注,而我们不具有这样的能力。基于以上的考虑,我们在kaggle 等社区检索后,决定选用GitHub 的chinese‐poetry 数据集,其已有的主要分类标签包括唐诗、宋词、花间集等。我们选用五种诗文出处作为分类标签,包括唐诗、宋词、论语、诗经和四书五经,基于比较新兴的TextCNN 方法构建分类模型。
2 TextCNN模型
卷积神经网络早期是主要应用在计算机视觉的一个算法,近年在各个新领域都涌现出研究成果,其中就包括本文的文本分析领域,这将在下文提到。典型的卷积神经网络由输入层、卷积层、池化层(下采样层)、全连接层、输出层组成[7],它们的原理如下。
卷积层利用卷积核对图阵列进行特征提取,通过卷积核与图像对应像素相乘求和得到神经元的输出值;在算力不充足的情况下可以进行池化下采样,池化层对特征进行选择、进行信息过滤,常用的是maxpooling 和average pooling,即最大值池化和平均值池化(值得一提的是,采用池化下采样的操作已经越来越少,因为池化滤除的信息过多,可能包括有用的信息,更好的方法是卷积下采样);全连接层类似于传统前馈神经网络的隐含层,将特征图展开为向量并通过激励函数,即对特征进行非线性组合。卷积神经网络的优势就在于其能够良好地捕捉局部特征。
而文本也是可以被表现为类似于图片像素阵列的形式的(例如词语在字典中的位置以及词语在句子中的位置形成的矩阵),因此文本分类理论上也是能由卷积神经网络完成的。
2014年Yoon Kim 提出的TextCNN 首次运用卷积神经网络进行文本分类:
输入层的形式是一个句子中的单词以及单词对应的词向量形成的n*k 矩阵,其中n 为句子的单词数,k 为词向量维度。因此输入层的每一行都是一个单词对应的k 维词向量,并且为了保证词向量长度一致,矩阵会进行padding 操作(即边界填充)。
卷积层与传统CNN 的卷积层原理一致,但是卷积核的宽度一定等于词向量大小(即上文提到的k),因此卷积核只会进行高度方向的移动,每次步进都会划过完整的单词,保证了词语作为语言中的最小粒度(粒度如果需要降低还需其他操作)。

表1:sklearn 打印的分类报告结果
池化层与传统CNN 的池化层也基本一致,方法包括1‐MAX池化、K‐MAX 池化(选出每个特征向量中最大的K 个特征)和上文提到过的平均值池化等。
3 实验设计
在实验之前进行比较常规的数据预处理。实验数据集来自上文提到的Chinese‐Poetry 库,库内收录了从从先秦到现代的共计85 万余首古诗词。其中供本次训练使用的有唐代诗词281378 首,宋代诗词270066 首,论语文本31116 段,诗经诗词78606 首,四书五经文本56925 段。我们建立数据集中五种类型的映射,读取json 文件后进行dataframe 的拼接。古诗词中有一些生僻字,这些生僻字属于 utf8mb4 字符,在许多设备中无法显示,故而使用“?”来替代,鉴于该类生僻字在古诗词中所占比例极小(在词袋中,含有“?”的词仅占总词数的2.9456e‐03%),因此在此次训练中忽略其影响。
随后,使用sklearn 提供的split 方法将古诗词按0.25 的比例生成训练集和测试集,并通过使用word2vec 方法,将古诗文进行分词后转化成词向量。在分词过程中,我们认为,数据集内已经比较干净,不需要去除停顿词之类的操作,以免发生有些繁体字取掉后识别会不精准的情况。
在textCNN 网络结构上,我们在经典的一层卷积的卷积神经网络上添加了两层卷积层和一层全连接层,其中两个全连接层分别采用relu 和softmax 激活函数,以进行五分类。随后参考文献[8]中的方法进行参数调整。在多次实验和比较后,根据结果选定filter 大小为[3,4,5],每层卷积核个数均为128,dropout rate 为0.4,池化策略为GlobalMaxPooling,激活函数为relu 和softmax,达到取得较高准确率的五分类结果的目的。
4 结果
使用sklearn 打印分类报告,在训练集和测试集上得到的结果如图1 和图2所示。
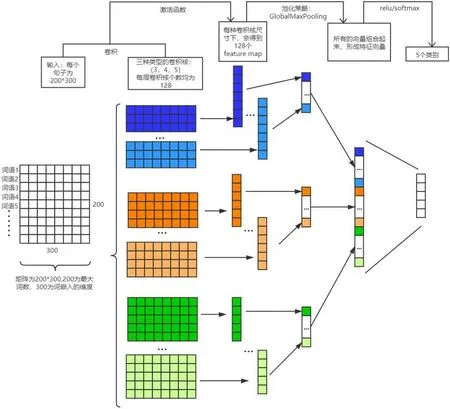
图1:本文采用的模型训练原理
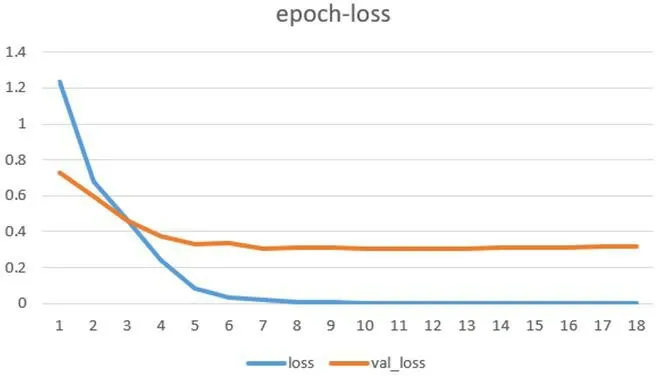
图2:随迭代次数增加loss 的变化
可以看到loss 不断下降直到趋于稳定,accuracy 不断上升直到趋于稳定,训练过程符合深度学习的迭代规律。最终sklearn 打印的报告给出了0.94 的macrof1 分数和0.87 的weightedf1 分数。

图3:随迭代次数增加accuracy 的变化
5 结论与展望
本文提出了一个基于TextCNN 构建的中国古诗词文本分类模型,并在在GitHub 的chinese‐poetry 数据集上进行五分类。最终加权后的f1 得分为0.87 表明该模型可以有效应用于中国古诗文的文本分类。
运用该模型,我们已能在基本的古诗文出处分类上获得较高的准确度,例如“孔子之去鲁,曰:‘迟迟吾行也,去父母国之道也。’”这样的句子被神经网络划为了“四书五经”类。如果仅凭人的主观判断,可能会认为其出自《论语》(备注:数据集中“四书五经”类不包含《论语》,两者是分开的类,现实中《论语》是四书五经的一部分),因为《论语》内包含大量的孔子所说的话,但实际上这个句子的确是出自四书五经中的《孟子》。其实神经网络将这个句子划为“四书五经”类,也并不违反直觉,因为熟悉《论语》和《孟子》的人也会很快地辨认出来:《论语》中常用的句式是“子曰”,但《孟子》常用的句式是简单的“曰”,并且《孟子》中也时常会在引用人物的语言之前交代一些背景,比如“孔子之去鲁,曰:……”“庄暴见孟子,曰:……”,但《论语》中往往直接由“子曰”开头。
上述的例子是本文的模型对古诗文文本在朝代、出处上进行分类的应用,针对佚名诗文和来源模糊的诗文可以进行出处上的参考。不过,我们认为进行情感和风格上的分类或许会有更高的应用价值,这也正是本文的不足之处。但是正如引言中提到的,我们缺少足够的数据集,也没有能力进行大量的人工手动标注,不过使用本文的思路,如果配合足够良好的数据集和特征工程,相信也能构建出在情感、风格以及其他方面效果良好的分类模型。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
计算机技术与发展(2019年1期)2019-01-21
新世纪智能(语文备考)(2018年9期)2018-11-08
小学生必读(高年级版)(2017年9期)2017-12-13
小学教学研究(2016年33期)2016-06-22
新课程研究(2016年18期)2016-02-28
语文教学与研究(2014年10期)2014-02-28
语文教学与研究(2014年9期)2014-02-28
