
孤立森林算法研究及并行化实现
2021-07-06 02:14王诚,狄萱
计算机技术与发展 2021年6期
王 诚,狄 萱
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
异常检测是近年来数据挖掘中热门的研究课题之一,被广泛应用于医保欺诈[1]、网络入侵[2]、医疗诊断[3]等领域。随着物联网、云计算等技术的不断发展,数据量日渐增长,传统单机版异常检测算法难以对大规模数据进行高效检测。因此,针对大规模数据设计相应算法,具有重要的应用价值。近年来,已有的异常检测算法分为三类,分别是基于统计[4]、密度[5]和聚类[6]的算法。Liu等[7-8]提出的孤立森林算法,通过计算测试数据在已构建的孤立森林模型下的平均路径长度代入公式求其异常值,该算法大大减少了计算时间,适用于高维数据。Liao等[9]提出一种基于信息熵的改进孤立森林算法,该算法通过计算数据集中各个特征下的信息熵,优先选择信息熵小的特征作为切割特征,并且改进了路径长度的计算公式,对噪声特征具有较强的抵抗性。Yang等[10]提出了一种基于孤立的嵌入式无监督特征选择(IBFS)算法,该算法通过计算孤立森林在训练过程中每个特征的得分,选出表现优异的特征集合进行异常检测,提高了异常检测精度。Yong等[11]根据Hadoop平台业调度机制和孤立森林算法的思想,将孤立森林算法的模型构建和异常预测两个过程进行了并行化设计,但其运算过程中需要多个MapReduce操作完成并行运算,多次读写硬盘,耗费大量时间。
孤立森林算法异常检测不需要计算距离和密度,避免了大量的计算,因此能够更好地支持高维数据的异常检测,同时孤立森林的每棵孤立二叉树的构建过程都是独立的,能够利用分布式平台对孤立森林算法进行并行化设计。孤立森林算法存在一些不足之处:
(1)在深入研究孤立森林算法过程中发现,孤立森林算法在计算测试样本的异常值时,计算的是测试样本在孤立森林的平均路径长度,而孤立森林算法的核心思想是:在一棵孤立二叉树中,若某个叶子节点的路径长度短,则认为该节点是异常点。当某棵孤立二叉树没有相对短的路径的叶子节点时,则说明其难以区分异常点。
(2)Yong等[11]指出,孤立森林算法异常检测的精度与孤立二叉树的数量有关,随着数据量的增多,所需构建孤立二叉树的数量也相应增多,从而导致耗费大量内存和时间,影响算法效率。
针对第一点不足,对孤立森林中每棵孤立二叉树的路径长度的标准差进行归一化加权,计算异常值。若标准差大,则说明该棵孤立二叉树中各叶子节点间的路径长度差异大,具有较好的异常检测能力,应赋予较高的权值,否则赋予较低的权值。通过加权计算测试样本在孤立森林的异常值,以提高异常检测的精确度。针对第二点不足,利用Spark平台实现改进算法的并行化。Spark平台是基于内存设计的,避免了Hadoop平台MapReduce操作需要频繁读写磁盘,能够加快整体的异常检测速度。
1 相关工作
1.1 孤立森林算法
孤立森林是由多棵孤立二叉树组成的,孤立二叉树的构建过程是算法的核心,孤立二叉树的构建过程如下:
(1)从数据集D中随机选择m个样本点作为生成本棵孤立二叉树的样本集Ds。
(2)从样本集Ds中随机选择一个特征f和一个切割值p。若节点N包含的所有样本在特征f下的最大值和最小值分别为f_max和f_min,则有p∈[f_min,f_max]。
(3)若样本的特征f的值小于切割值p,则将该样本分到节点N的左孩子;否则,分到右孩子。
(4)重复(2)、(3)两步,分别对节点N的左右孩子节点进行切分,生成孤立二叉树。当孩子节点中有多条相同的数据或只有一条数据或孤立二叉树已达到设置的最大高度时,停止生成孤立二叉树。
(5)孤立森林最终由用户指定数目的孤立二叉树组成。根据样本点d在每棵孤立二叉树中的路径长度h(d),利用公式(1)计算d的异常值,从而评价其异常情况。
(1)

1.2 Spark大数据计算框架
Spark[12-13]是加州大学伯克利分校的AMP实验室开发的一款基于内存的并行分布式计算框架。相较于Hadoop框架中的分布式计算模块MapReduce需要频繁读写磁盘I/O操作,Spark框架基于内存的设计,将每一轮的输出结果都缓存在内存中,避免了从HDFS中读取数据,更适合需要多次迭代的算法。Spark的运行架构模型如图1所示,其基本运行流程是:

图1 Spark运行架构模型
(1)Spark在驱动节点Driver端运行main()方法并创建SparkContext以构建Spark Application的运行环境,创建完成后的SparkContext向资源管理器Cluster Manager申请所需要的CPU、内存等资源并申请运行多个执行节点Executor,Cluster Manager分配并启动各个Executor。
(2)SparkContext构建有向无环图DAG以反映弹性分布式数据集RDD之间的依赖关系,并将其分解成任务集TaskSet发送给有向无环图调度器TaskScheduler。
(3)各Executor向SparkContext申请Task,TaskScheduler将Task分发给各个Executor,同时SparkContext将打好的程序Jar包发送给各个Executor,各Executor执行结束后将结果收集给Driver端[14],最终释放资源。
2 改进孤立森林算法的并行化实现
2.1 加权孤立森林的构建算法
如公式(1)所示,孤立森林在计算测试样本异常值时,计算的是测试样本在孤立森林的平均路径长度,忽略了各孤立二叉树的异常检测能力的差异性,即每个叶子节点的路径都很长的孤立二叉树难以区分异常点,而具有短路径的叶子节点的孤立二叉树能够更好地区分异常点。如图2和图3所示,图2的孤立二叉树比图3的孤立二叉树具有更强的区分异常点的能力。因此该文通过计算每棵孤立二叉树的路径长度标准差对具有更强区分异常点能力的树进行加权,同时减小区分异常点能力较差的树的权值。
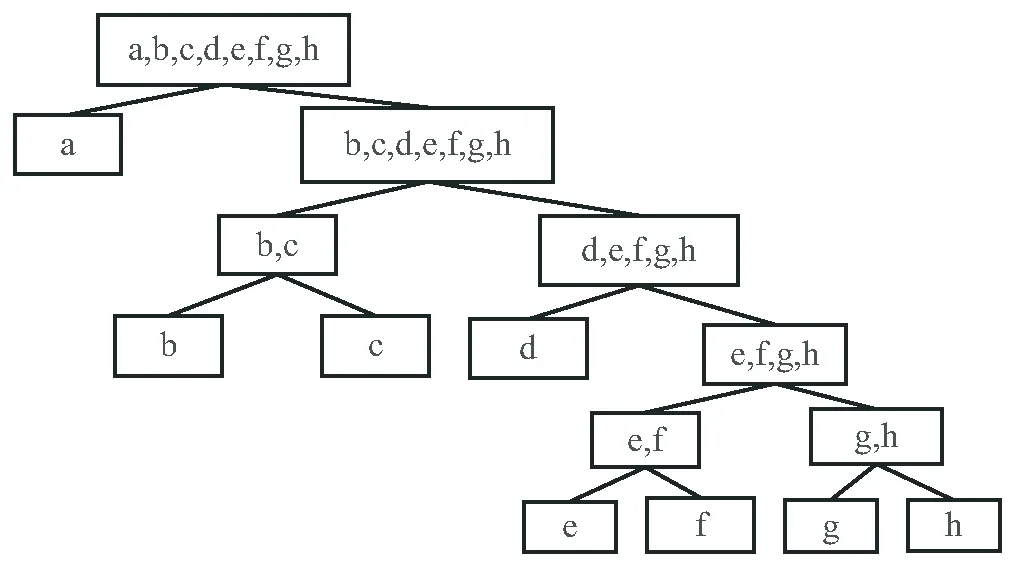
图2 区分异常能力强的孤立二叉树

图3 区分异常能力差的孤立二叉树
若一棵孤立二叉树的叶子节点集合为Node={node1,node2,…,noden},叶子节点的路径长度集合为Hnode={h1,h2,…,hn},则该棵树的路径长度标准差σ的计算公式为:
(2)
其中,n为叶子节点的总个数,μ为该棵树所有叶子节点路径长度的均值。
若孤立森林中所有孤立二叉树的路径长度标准差集合为σ={σ1,σ2,…,σn},其中最大值为σmax,最小值为σmin,对路径长度标准差集合进行归一化,公式为:
(3)
若数据集D中每个样本点d在每棵孤立二叉树中的路径长度为集合Hd={h1,h2,…,hn},孤立二叉树的权重集W={w1,w2,…,wn},则样本点d的异常值计算公式为:
(4)
具体算法实现如下:
算法1:加权孤立森林的构建算法。

输出:孤立森林,权重集W。
(1)对数据集D进行随机采样,抽取m个数据放入集合Ds中。
(2)调用孤立二叉树生成算法,并传入相关参数,生成单棵孤立二叉树。
(3)利用公式(2)计算当前生成的孤立二叉树的路径长度标准差。
(4)重复1、2两步,直到生成n棵孤立二叉树及路径长度标准差集合。
(5)利用公式(3)对路径长度标准差集合进行归一化,生成权重集W。
(6)返回由n棵孤立二叉树组成的孤立森林及权重集W。
算法2:样本点异常值计算流程。
输入:数据集D,权重集W;
输出:数据集D的异常值集N。
(1)计算数据集D中每个样本点在每棵孤立二叉树中的路径长度集合Hd。
(2)利用公式(4),加权计算每个样本点的异常值,并合为异常值集N。
(3)返回数据集D的异常值集N。
2.2 改进孤立森林算法的并行化设计
该文利用Spark平台实现改进孤立森林算法的并行化。主要步骤包括:数据抽样、模型构建和异常预测。整体框架如图4所示。

图4 改进孤立森林算法并行化框架
(1)数据抽样。
单机版的孤立森林算法需要对原始数据集进行随机抽样,利用抽样后的数据集生成孤立二叉树。而Spark平台数据存储核心RDD是分布式数据集,如果直接对各个分区的数据进行定量随机抽样,不能保证抽样后得到的数据集是全局随机的。虽然Spark提供了sample抽样算子,但会导致非确定性大小的采样样本集。因此,该文设计从HDFS中读取数据文件,转化成RDD记为RDD_data,在Driver端首先利用count算子计算RDD_data数据总量,创建RandomData-Generator类,根据RDD_data数据总量、孤立二叉树数量、随机采样样本数量,随机生成包含行号索引值的二维数组,并将其映射为(rowId(行号),treeIdArray(该行数据对应的孤立二叉树ID集合))的格式,最后将该形式的变量广播到各个Executor端,以减少Shuffle成本。利用zipWithIndex算子,为RDD_data添加全局索引号,在各个Executor端利用广播来的变量中的行号对RDD_data数据内容筛选过滤,并通过flatMap、reduceByKey算子生成(treeId(孤立二叉树ID),ContentArray(构建此ID孤立二叉树所需的数据集))格式的数据集:RDD_sample。
(2)模型构建。
将RDD_sample数据集map到各个Executor端进行孤立二叉树的并行同步构建并计算各个孤立二叉树的路径长度标准差,数据格式分别为:(treeId(孤立二叉树ID),tree(孤立二叉树))、(treeId(孤立二叉树ID),stdPath(路径长度标准差))。利用collect算子将多棵孤立二叉树及各自的路径长度标准差收集到Driver端,并将多棵树的路径长度标准差合并归一化成一个数据格式为(treeId(孤立二叉树ID),weight(权重))的权重集。最后将构建好的模型及权重集分别存入RDD_model和RDD_weight中。
(3)异常预测。
将构建好的模型RDD_model广播给各个Executor,测试数据集并行遍历每一棵孤立二叉树,得到每一个测试数据样本在模型下的路径长度集合,集合中元素的数据格式为(treeId(孤立二叉树ID),pathLength(路径长度)),利用权重集RDD_weight对每一个测试数据样本的路径长度集合进行加权计算,得到每一个测试数据样本的异常值,从而评价其异常情况。
3 实验设计与结果分析
3.1 实验数据集
实验数据集选取自威斯康星州数据集Breastw、UCI数据集Shuttle和KDD CUP 99数据集Http[15],数据集的具体信息如表1所示。

表1 数据集具体信息
3.2 异常检测精确度
该文使用表1中的三个数据集对三种算法进行实验对比分析。其中,三个算法的参数均为:孤立二叉树数量n=100,随机采样样本数量m=256,树的高度限制l=8。采用ROC曲线下的面积AUC指标来评价算法异常检测精确度。AUC值的范围为[0,1],其值越接近1则说明算法的检测效果越好。具体的实验结果如表2所示。

表2 三种算法的AUC值
从表2中可以看出,对于Breastw、Shuttle和Http三个数据集,改进孤立森林算法相对于原始孤立森林算法的AUC值分别提高了2.22%、2.51%、1.65%,这是因为改进孤立森林算法改进了异常值计算公式,为高异常检测能力的孤立二叉树赋予更高的权值,从而让异常点更为突出。并行化改进孤立森林算法与改进孤立森林算法的AUC值没有明显差异,因此并行化改进孤立森林算法在异常检测精度上能与改进孤立森林算法保持一致。同时,改进孤立森林算法由于需要计算路径长度标准差并归一化为权重集,相对于原始孤立森林算法增加了些许时间开销,但在小规模数据集上可以忽略不计。并行化改进孤立森林算法相较于单机的改进孤立森林算法耗费了更多的时间,这是由于数据规模小时,集群初始化、任务调度及节点间的数据通信时间远大于算法本身的运算时间。
3.3 并行性能实验
实验环境是基于Spark平台的计算集群,该集群共有4个节点,每个节点的CPU核数为1核,内存为2 G,硬盘为30 G,Java版本为1.8.0,Scala版本为2.11.0,Hadoop版本为2.7.6,Spark版本为2.4.0。实验数据集是由Breastw数据集构造的行数为100万行、300万行、500万行、800万行的大规模数据集。分别对这四个大规模数据集进行对比实验,其中自变量为孤立二叉树数目,分别为100棵、200棵、300棵、400棵、500棵。同时计算当孤立二叉树数量为100时,改进孤立森林算法在Spark集群下的加速比,评价其并行性能。实验结果如图5~图6所示。
从图5中可以看出,在不同数据规模下,随着孤立二叉树数目的不断增加,单机和并行化的孤立森林算法的运行时间都呈线性增加,单机算法的增幅更陡峭,并行算法的增幅平缓。当数据量达到800万行、孤立二叉树数目为500棵时,单机运行时间是并行化后的运行时间的4.34倍。从图6中可以看出并行化改进孤立森林算法总体上有很好的加速比。随着数据量的不断增大,加速比随着节点数的增加而明显增大,当数据量达到800万行、节点数为4时,加速比提升到了2.88。因此,并行化改进孤立森林算法能够更高效地处理需要构建大量孤立二叉树的大规模数据集。

图5 不同规模数据集下运行时间对比

图6 100棵孤立二叉树下的加速比
4 结束语
该文针对孤立森林算法在计算测试样本的异常值时,忽略了孤立二叉树间检测异常能力差异性以及大规模数据下构建大量孤立二叉树需要耗费大量内存时间这两点不足进行改进,加权计算测试样本在孤立森林中的异常值并基于Spark平台设计实现并行化改进孤立森林算法。通过多个对比实验结果表明,并行化改进孤立森林算法能够加快大规模数据集下的异常检测速度,同时提高了异常检测精度。下一步将把该算法与实际应用场景相结合,检验其实际应用价值。
猜你喜欢
数学学习与研究(2018年14期)2018-10-29
领导决策信息(2018年16期)2018-09-27
作文大王·低年级(2017年11期)2017-12-05
中学生数理化·八年级物理人教版(2017年2期)2017-03-25
数学学习与研究(2017年3期)2017-03-09
学苑创造·A版(2017年1期)2017-01-19
电脑知识与技术(2016年7期)2016-05-19
计算技术与自动化(2014年1期)2014-12-12
中学数学杂志(初中版)(2014年1期)2014-02-28
西南学林(2013年2期)2013-11-12
