
基于跟驰行为谱的跟驰风险状态预测
2021-07-09 05:18涂辉招
同济大学学报(自然科学版) 2021年6期
汪 敏,涂辉招,李 浩
(同济大学道路与交通工程教育部重点实验室,上海201804)
公安部交通管理局统计[1]结果表明,我国道路交通事故中,跟驰碰撞事故数约占总事故数的1/3,特别是城市道路和高速公路,经常出现连环追尾碰撞事故[2-3],不仅造成生命财产损失,还严重影响交通有序运行。量化并实时预测车辆跟驰行驶过程中的危险程度,即跟驰风险状态,可提前预警跟驰事故,对降低跟驰事故发生概率有重要意义。
跟驰风险状态预测,常用的方法是结合实际的交通事故数据或者交通冲突数据进行致因解析,寻找对跟驰风险有显著影响的因素,再利用统计分析、机器学习等方法进行跟驰风险状态预测[2,4-6]。但是实际的事故数据往往难以获取,并且数据质量难以得到保证。也有研究结合客观分析和主观评价,通过问卷调查、专家打分、层次分析模型评定跟驰风险状态[7-8]。然而,问卷调查的方式存在较大的主观性,受打分专家的风险偏好和经验影响较大,且难以结合车端采集的数据,对跟驰风险状态进行实时动态预测。部分学者通过仿真实验进行事故模拟,进而研究跟驰风险状态[9-12]。事故仿真实验往往和实际交通情况有较大的差别,风险量化和预测的结果难以得到有效的验证。
一些能反映跟驰风险状态的跟驰风险状态指标被提出,如车头时距(time headway,THW)、碰撞时间(time to collision,TTC)、避免碰撞减速率(deceleration rate to avoid crash,DRAC)等[3,13-14]。根据这些指标从特定角度对跟驰风险状态进行量化表征、划分等级,然后利用隐马尔科夫模型[15]、机器学习模型[16-17]、时间序列模型[15-16]等进行跟驰风险状态预测。但是研究表明[18],跟驰风险状态指标在不同跟驰场景下的分布情况存在较大的差异,造成其状态划分阈值难以确定,导致跟驰风险状态量化及预测的准确性也难以得到保证。何青俊等[14]在交通行为谱和驾驶行为谱[19-20]的研究基础上,提出了能反映驾驶人在不同跟驰场景下跟驰行为特征普遍规律的跟驰行为谱概念,确定了跟驰行为谱的具体形式,构建了表征不同跟驰场景和不同驾驶风格的跟驰行为谱。将实时跟驰状态和跟驰行为谱[14]中的跟驰行为特征进行对比关联,可实现跟驰风险状态的实时评估。为了预测跟驰风险状态,本文构建6种典型跟驰场景的跟驰行为谱,基于跟驰行为谱确定跟驰风险状态阈值,利用6种机器学习模型进行跟驰风险状态预测,选取3种预测效果评价指标,基于驾驶模拟器获取的跟驰数据对预测效果进行对比评价。
1 模型与方法
模型与方法主要分为风险指标和预测模型2个部分。风险指标包括明确各项指标的名词定义和计算方法。预测模型包括训练和测试6种机器学习模型,并提出预测效果评价方法。
1.1 风险指标
1.1.1 名词定义
(1)跟驰风险状态指标:表征车辆跟驰行驶过程中危险程度的指标,如THW、TTC、DRAC等。
(2)跟驰风险状态:依据跟驰风险状态指标及其划分阈值确定的车辆跟驰行驶过程中不同等级危险程度。通常分为4或5个风险状态等级。
(3)预测时长:预测时长是预测时刻与当前时刻的时间差。考虑到数据采集的时间颗粒度,预测时长以0.5 s为间隔,即预测从当前时刻起,0.5 s、1.0 s、1.5 s、2.0 s等的跟驰风险状态。
(4)风险特征指标:车辆跟驰行驶过程中的风险与前后车辆运动学状态以及驾驶员操纵情况有关[21],因此风险特征指标指从车辆运动学参数和驾驶员操纵参数中提取、用作跟驰风险预测的指标。车辆运动学主要有本车速度、前车速度、本车加速度、前车加速度、车头间距等5个参数;驾驶员操纵主要有油门踏板受力、制动踏板受力、方向盘转角等3个参数。8个参数中每个参数提取均值、标准差、最大值、最小值,耦合成32个风险特征指标。
(5)特征指标序列时长:特征指标序列时长是上述8个参数的时间序列长度。如特征指标序列时长为0.5 s时,对于8个参数,提取过去0.5 s内的均值、标准差、最大值、最小值。为了对比不同特征指标序列时长的预测效果,同样以0.5 s为间隔,即分别取特征指标序列时长为0.5 s、1.0 s、1.5 s、2.0 s等进行跟驰风险状态预测。
1.1.2 跟驰风险状态指标
跟驰碰撞、蛇形跟驰驾驶、速度不稳定驾驶是常见的3种车辆跟驰风险。针对这3种车辆跟驰风险,分别提出跟驰风险状态指标,量化车辆跟驰行驶过程中危险程度。
跟驰碰撞风险是跟驰过程中发生追尾碰撞事故的潜在可能。常用的指标有THW、TTC、DRAC及其衍生指标如碰撞时间倒数(reciprocal of time to collision,RTTC)、碰撞时间积分(time-integrated TTC,TIT)等。选择碰撞时间倒数作为跟驰碰撞风险状态指标,其分布状态为高斯分布,便于跟驰风险状态标定。

式中:IRTTC为碰撞时间倒数指标;Vb(t)为后车(behind)在t时刻瞬时速度;Vf(t)为前车(front)在t时刻瞬时速度;D(t)为t时刻前后两车之间的距离。
蛇形跟驰驾驶风险是跟驰过程中不良横向驾驶状态导致的潜在危险,表现为车辆跟驰过程中横向移动频繁或者幅度较大(但没有变道)。用蛇形跟驰风险状态指标即横向摆动系数(transverse oscillation coefficient,TOC)评 价 蛇 形 跟 驰 驾 驶风险。

式中:ITOC为横向摆动系数指标;∑|W(t)|为t时刻横向偏移累计值(1 s内);d(t)为t时刻纵向累计行驶距离(1 s内);F为数据记录频率。
速度不稳定驾驶风险是跟驰过程中速度变异性过大导致的风险,不仅影响行车安全,还会影响行驶舒适性。以1s内速度标准差与速度均值的比值即速度不稳定系数(velocity instability coefficient,VIC)作为速度不稳定跟驰风险状态指标。

式中:IVIC为速度不稳定系数指标;Vstd(t)为t时刻速度标准差(1 s内);Vmean(t)为t时刻速度均值(1 s内)。
1.1.3 跟驰风险状态
提取对应场景下各跟驰风险状态指标的统计学分位值[14],作为跟驰风险状态划分阈值。参考我国突发公共事件总体应急预案[22]对事故风险的等级划分,将跟驰风险状态划分为4个等级,如表1.

表1 跟驰风险状态划分Tab.1 Division of car-following risk status
1.2 预测模型
1.2.1 模型种类
采用有监督机器学习模型进行跟驰风险状态预测。有监督机器学习预测模型主要有分类预测和回归预测2类,都将跟驰数据集划分为训练集和测试集。训练集用来训练模型,测试集用来测试模型预测效果。有监督机器学习分类预测模型,先根据跟驰行为谱确定模型训练集数据的跟驰风险状态,对应其风险特征指标,输入分类预测模型,完成模型训练。然后用测试集风险特征指标进行模型预测,预测结果直接是跟驰风险状态。有监督机器学习回归预测模型,先根据训练集数据的跟驰风险状态指标具体数值和对应的风险特征指标完成模型训练。模型预测时,预测结果是跟驰风险状态指标数值,再根据跟驰行为谱确定预测跟驰风险状态。选取支持向量机(support vector machine)、K-近邻(K-nearest neighbor)、集成树(adaboost)3种分类预测模型,以及精确决策树(precise decision tree)、提升树(LSboost)、线性回归拟合(linear regression fitting)3种回归预测模型,进行跟驰风险状态预测。
1.2.2 模型评价
以准确率、四级风险状态召回率、平均召回率作为模型预测效果评价指标,对上述6种预测模型进行预测效果评价。
准确率表征正确预测的风险状态占比,是模型预测效果的常用评价指标。

式中:Raccuracy为准确率;Sequality为预测风险状态与真实风险状态相等的预测数据条数;Spredict为总预测数据条数。
准确率能直观反映模型的预测效果,但是当各等级风险状态的数据量相差较大,即数据不平衡时,用准确率进行模型预测效果评价具有一定的局限性。例如在1 000条数据中,其中950条都为一级风险状态,即使模型将所有数据的风险状态都预测为一级风险状态,其准确率也达到了95%,此情况下用准确率进行模型预测效果评价缺乏科学性。
因此在分类问题中还常用召回率进行模型预测效果评价,以某级风险状态为对象,计算成功预测为该级风险状态的数据条数占该类风险状态实际数据条数的比例。此指标可以分别计算各等级风险状态的预测效果。

式中:Rrecall(i)为i级风险状态(i=1,2,3,4)召回率;Sequality(i)为预测风险状态为i级且真实风险状态为i级的数据条数;Sreal(i)为真实风险状态为i级的数据条数。
高等级风险状态(如四级风险状态)的召回率反映着模型对危险状态的预测能力,对模型性能评价更有意义。为了对模型预测性能进行整体评价,并解决数据不平衡对模型评价有效性影响的问题,对各个等级风险状态的召回率进行平均,得到能反映模型整体预测性能的指标—平均召回率。

式中:Rarecall为平均召回率。
震损水库渗漏常见大坝下游及坝内输泄水结构出口。常见表现为震后渗漏量增加,浑水出现一段时间后又变清,渗漏量趋于稳定。如汶川地震后,紫坪铺大坝渗漏量较震前有所增加,但总量不大,渗流水质在震后的1~2天较震前浑浊,并夹带泥沙,后水质变清。在某些情形下,震后渗漏量比震前持续增加,一直出现浑水,疑大坝坝体可能出现集中渗漏,可能是坝体产生横向裂缝或坝内涵管出现变形损坏等。如四川省梓潼县联盟水库左右两坝肩震前就长年漏水,绕坝渗漏明显,地震后渗流量显著增大。
除了准确率和召回率外,常用的模型预测效果评价指标还有精确率,是正确预测为某级风险状态的数据条数占所有预测为该级风险状态数据条数的比例。如四级风险状态精确率为正确预测为四级风险状态的数据条数占所有预测为四级风险状态数据条数的比例。由于风险预测的实际意义在于预测高等级风险状态,故不将精确率作为模型预测效果评价指标。
2 实例分析
2.1 数据来源
2.1.1 数据采集设备
利用同济大学8自由度驾驶模拟器采集驾驶数据[23]。该设备由运动系统、视景系统、声音系统、数据采集系统、操作及反馈系统、安全控制系统组成,具有高逼真的视觉模拟及反馈效果,如图1所示。模拟器通过SCANeRTM软件来控制,提供3D场景设计、仿真实验、数据导出和分析等功能。

图1 驾驶模拟器示意Fig.1 Diagram of driving simulator
2.1.2 场景搭建
城市道路类型:主干道、次干道、支路。
交通流状态:依据基本交通流理论,车辆平均速度低于限制车速1/2判定为拥挤交通流。以不拥挤作为对照。
特殊前车行为:前车突然减速。以前车正常行驶作为对照。
依据道路类型、交通状况、前车行为进行场景组合,搭建6种典型的城市道路跟驰场景。如表2所示。

表2 6种典型跟驰场景Tab.2 Six typical car-following scenarios
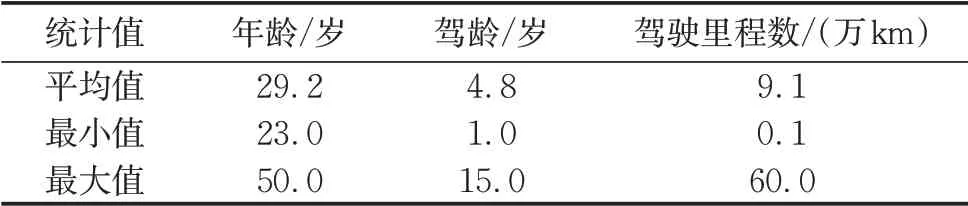
表3 驾驶员基本统计信息Tab.3 Basic statistics of drivers
每位驾驶员被告知应遵守的操作规范,10 min熟悉驾驶模拟器的操作,休息5 min后,开始正式实验。
实验过程中,每位驾驶员在不了解实验目的情况下驾驶模拟车辆依次通过6种场景,数据采集系统采集到车辆运动学指标和驾驶操纵指标,经过数据预处理剔除异常数据后,得到6种场景下的驾驶数据集。
计算32种风险特征指标,并确定跟驰风险状态,各等级跟驰风险状态数据量如表4所示。

表4 各等级跟驰风险状态数据量Tab.4 Data volume of car-following risk status at different levels
将数据集划分为70%训练集和30%测试集,针对RTTC、TOC、VIC这3种跟驰风险状态指标分别进行模型训练和预测。
2.2 预测效果对比
2.2.1 不同模型预测效果
对比精确决策树、集成数、线性回归拟合、支持向量机、K-近邻、提升树6种模型预测效果,以准确率、平均召回率、四级风险状态召回率为评价指标对预测效果进行评价;固定预测时长为0.5 s,特征指标序列时长为0.5 s。以过去0.5 s的特征指标序列预测未来0.5 s的跟驰风险状态。各种模型预测效果对比如图2、3、4所示。

图2 各预测模型碰撞时间倒数预测效果Fig.2 Prediction effects of reciprocal of time to collision of each prediction model
图2为不同预测模型对RTTC的预测效果。结果表明,用精确决策树模型进行预测时,准确率和平均召回率均处于所有预测模型首位,且准确率达到了95%以上,平均召回率达到了85%以上。四级风险状态召回率也超过80%。线性回归模型预测的准确率和平均召回率不高,特别是准确率,处于所有预测模型的末位,整体预测效果较差。K-近邻模型的整体预测效果仅次于精确决策树。提升数、集成树以及支持向量机的预测效果较差,平均召回率和四级风险状态召回率均在60%以下。
图3为不同预测模型对TOC的预测效果。结果表明,精确决策树模型的准确率、平均召回率、四级风险状态召回率均处于所有预测模型首位,其中准确率超过95%,平均召回率达到88%,四级风险状态召回率达到85%。其他模型整体预测效果依次是K-近邻、提升数、集成树、线性回归拟合以及支持向量机。其中线性回归拟合以及支持向量机的召回率和四级风险状态召回率很低,在25%以下(25%相当于随机精度),因此这2种模型对TOC没有预测能力。

图3 各预测模型横向摆动系数预测效果Fig.3 Prediction effects of transverse oscillation coefficient of each prediction model
图4为不同预测模型对VIC的预测效果。结果表明,精确决策树模型的准确率、平均召回率处于所有预测模型首位。其中准确率超过95%,平均召回率达到84%。另外四级风险状态召回率也达到78%,稍次于K-近邻模型和提升树模型。除此之外,K-近邻模型、提升树模型、集成树模型以及支持向量机的整体预测效果相差不大,次于精确决策树模型。线性回归拟合模型整体预测效果较差,其中平均召回率以及四级风险状态召回率均在60%以下。

图4 各预测模型速度变异系数预测效果Fig.4 Prediction effects of velocity instability coefficient of each prediction model
综上,精确决策树模型对跟驰风险状态的预测效果最好。基于跟驰行为谱,利用精确决策树模型可实现跟驰风险状态的有效预测。本文后续对比分析中主要采用精确决策树来预测跟驰风险状态。从模型评价指标来看,在大多数预测模型中,四级风险状态召回率低于准确率和平均召回率,说明模型对高等级风险的预测难度更大。集成树、线性回归、支持向量机对四级风险状态的预测效果较差,但是预测准确率也在85%以上,主要是因为一级风险状态数据条数较多,远高于高等级风险状态数据条数,存在各等级跟驰风险状态数据不平衡问题,因此此时用准确率进行模型评价难以区分模型预测效果。平均召回率能解决数据不平衡问题,后续对比分析中主要用其进行模型预测效果评价。
2.2.2 不同场景预测效果
选取预测效果最好的精确决策树模型,以平均召回率为评价指标,进一步对比不同跟驰场景下跟驰风险状态预测效果。利用非参数秩和检验进行预测效果差异显著性检验,如图5和表5所示。

图5 不同跟驰场景模型预测效果Fig.5 Prediction effects in different car-following scenarios

表5 不同跟驰场景预测效果差异显著性Tab.5 Significant difference of prediction effects in different car-following scenarios
对比6种典型场景的模型预测效果可见,拥挤交通流下支路跟驰场景的碰撞时间倒数平均召回率在85%以上,横向摆动系数平均召回率达到88%,速度变异系数平均召回率为84%,模型预测效果显著好于其他场景。其他场景预测效果无显著差异,各风险状态指标的平均召回率都在80%~85%间。
2.2.3 预测效果随预测时长变化
不同的预测时长下,模型的预测效果也存在一定的差异。图6和图7分别是特征指标序列时长为0.5 s和3.0 s时,各场景下3种跟驰风险状态指标平均召回率随预测时长变化情况。当特征指标序列时长为0.5 s时(图6),预测效果随着预测时长的增大而变差。在预测时长为0s时(相当于实时风险评估),各跟驰风险状态指标平均召回率超过90%;当预测时长为3.0 s时,平均召回率均下降到80%以下,其中VIC的下降程度最明显;在特征指标序列时长为3.0 s时(图7),预测效果随着预测时长的增大而变差趋势变缓。且各场景下,TOC预测效果最好,在预测时长为3.0 s时,平均召回率能维持在80%以上。VIC预测效果最差,但是各种场景下平均召回率也能维持在70%以上。RTTC的预测效果介于TOC和VIC之间,平均召回率维持在75%以上。

图6 特征指标序列时长为0.5s时预测效果随预测时长变化Fig.6 Variation of prediction effects with duration of prediction at a duration of feature index sequence of 0.5s

图7 特征指标序列时长为5.0s时预测效果随预测时长变化Fig.7 Variation of prediction effects with duration of prediction at a duration of feature index sequence of 5s
2.2.4 预测效果随特征指标序列时长变化
随着特征指标序列时长的增大,模型得到的先验信息增多,模型预测效果也存在差异,分别分析预测时长为0.5 s和3.0 s时,模型预测效果随特征指标序列时长变化情况如图8和图9所示。
当预测时长为0.5 s时(图8),模型预测效果随特征指标序列时长变化不显著,说明当进行极短时跟驰风险状态预测时,难以通过增加特征指标序列时长进一步提升模型预测效果。而当预测时长为3.0 s时(图9),模型预测效果随特征指标序列时长增加而变好。说明进行较长时的跟驰风险状态预测时,可以通过增加特征指标序列时长提升模型预测效果。

图8 预测时长为0.5s时预测效果随特征指标序列时长变化Fig.8 Variation of prediction effects with duration of feature index sequence at a duration of prediction of 0.5s

图9 预测时长为3.0s时预测效果随特征指标序列时长变化Fig.9 Variation of prediction effects with duration of feature index sequence at a duration of prediction of 3s
2.2.5 预测时长与特征指标序列时长的交互关系
预测时长和特征指标序列时长影响了预测效果,为了进一步分析二者对预测效果的交互影响,图10给出了模型预测效果受预测时长和特征指标序列时长共同影响下的三维热力图。表明预测时长越长,特征指标序列时长越短,预测效果有变差的趋势,预测越困难。因此实际应用中可根据预测时长和预测效果需要,选定特征指标序列时长进行预测,以达到实时、准确、高效预测的目的。另外,不同场景下的整体预测效果变化情况存在差异。

图10 预测效果变化三维热力图Fig.10 Contour map of prediction effects
3 结语
基于跟驰行为谱,提取了反映前后车辆运动学状态以及驾驶员操纵情况的8个参数耦合的32种风险特征指标,选取碰撞时间倒数、横向摆动系数、速度变异系数为跟驰风险状态指标,采用6种机器学习预测模型进行模型训练与跟驰风险状态预测,以精确率、四级风险状态召回率、平均召回率为模型评价指标进行模型预测效果评价。基于6种典型跟驰场景下驾驶模拟实验数据,分析结果表明:
(1)选择的6种预测模型中,精确决策树对跟驰风险状态预测效果最好。
(2)拥挤交通流下支路跟驰的预测效果显著好于其他场景,其他5种场景下的预测效果无显著差异。
(3)模型对横向摆动系数预测效果最好,对速度变异系数预测效果最差。说明驾驶员驾驶车辆行驶过程中,横向摆动前兆性较强,相对容易预测;而速度变化随机性较强,增加了预测难度。
(4)模型预测效果随着预测时长增大而变差,但可以通过增加特征指标序列时长减缓变差趋势。
针对不同跟驰场景风险状态分布存在较大差异导致跟驰风险预测准确性难以保证的难题,提出32个指标,是基于常用且容易观测的车辆运动学参数和驾驶员操纵参数的常用统计指标,利用精确决策树模型实现了不同跟驰场景下跟驰风险状态的有效预测,为不同跟驰场景下车辆主动安全预警与防控提供了有力的技术支撑。本文暂没有考虑驾驶员本身的差异性,后续研究可以考虑驾驶员的驾驶经验和驾驶风格,作为模型输入,进行不同跟驰场景下风险状态预测,进一步验证模型预测的有效性和可靠性。
作者贡献说明:
汪敏:数据处理、模型构建、实证分析、结果讨论;
涂辉招:总体架构、研究方法、结果讨论、论文润色;
李浩:研究方法、思路梳理、结果讨论、论文润色。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
控制与信息技术(2021年2期)2021-07-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
小学生作文(低年级适用)(2019年5期)2019-07-26
