
基于密度自适应深度网络的点云场景语义分割算法
2021-07-09 05:19赵安铭王志成
同济大学学报(自然科学版) 2021年6期
卫 刚,赵安铭,王志成
(同济大学电子与信息工程学院,上海201804)
近年来,随着三维扫描技术的快速发展,三维点云广泛应用于无人驾驶、建筑设计、遥感测绘及虚拟现实等计算机视觉领域。作为三维场景和分析的重要课题之一,点云语义分割一直是三维视觉和计算机图形学范畴的重要研究问题,也是目标识别、场景理解和三维重建等任务的基础。由于采集过程中的传感器噪声干扰、点云密度不均匀、场景复杂多样以及物体之间存在遮挡现象等问题,三维点云场景语义分割问题研究工作极具挑战性。现有传统的点云分割方法的识别准确率还存在较大提升空间。目前,深度学习方法已广泛应用于二维图像数据,但将深度学习方法应用于三维场景仍面临巨大的挑战,有大量的基础性工作需要完成。由于深度学习方法表现出较好的高层语言理解能力,基于深度学习的点云语义分割已成为当前研究的热点。
卷积神经网络(convolutional neural networks,CNN)成功应用的一个关键因素是能够训练和应用深层神经网络。但是,最近的工作[1-3]表明,图卷积神经网络(graph convolutional network,GCN)很难扩展到深层网络。原因是叠加多个图卷积层会提高反向传播的复杂性和出现常见的梯度消失问题。由于上述限制,大多数最先进的GCN不超过4层。ResNet[4]的提出有效地改善了CNN上的梯度消失问题。ResNet通过在输入层和输出层之间引入残差连接,大大减轻了梯度消失问题。Yu等[5]提出空洞卷积(Dilated convolutions),在不增加更多计算量的同时能够增大感受野。受上述关键概念的巨大成功所启发,将上述想法应用到GCN中,使得更深层次的GCN能够很好地聚合并获得优异的性能。
为了成功训练更深层的GCN、减轻梯度消失问题,借鉴了训练深层卷积神经网络的相关概念,引入残差连接、空洞卷积等结构,训练更深层的点云分割网络。同时,由于上述工作的贡献未考虑到三维点云数据无序性、稀疏性和不规则性的特点,传统的卷积神经网络因其计算卷积时需要规则输入和输出,其不适合直接处理点云数据。为了对非均匀采样的点云数据进行卷积操作,提出了一种密度自适应方法。
1 研究背景
深度学习的发展推动了计算机视觉的进步。目前,深度学习已广泛应用于二维图像的处理[4,6-7],但是将其运用到三维数据仍面临巨大的挑战。由于点云具有不规则且无序性的问题,为了使得点云适用于卷积神经网络,研究者们将其转换成规则的结构,再输入到网络中进行处理。目前,根据输入到网络中的数据格式,基于深度学习的点云分割算法主要分为以下几类。
1.1 基于多视图的方法
受深度学习在二维图像上取得较好效果的启发,基于多视图的方法将3D点云转化为一系列的多视角拍摄的2D渲染图,将这些产生的二维图像作为训练数据,然后用成熟的2D卷积神经网络来提取特征,从而进行识别或分割任务。在这方面比较具有代表性的方法就是Multi-view CNN[8]。Multi-view CNN使用ImageNet预训练好的视觉几何组(visual geometry group,VGG)网络来提取特征,将这些特征组合在一起,再进一步输入到可训练的CNN网络中进一步进行特征学习,然后输出分类结果。Qi等[9]研究了基于视图和体积方法的三维形状分类组合。2017年,Boulch等提出SnapNet[10],其思想是使用2D神经网络分别对一系列成对的RGB图和深度图进行处理以生成3D场景的图像。为了改善分割效 果,在SnapNet的 基 础 上,Guerry等[11]提 出SnapNet-R对多个视图直接处理以获取密集的3D点标记。但是SnapNet-R对物体边界的分割精度仍有待加强。由此可见,基于多视图的点云分割方法没有充分利用点云数据的空间信息,同时对于物体的不同投影角度也会对结果产生影响。虽然这种方法取得了非常好的分类识别结果,但是这类方法容易造成三维结构信息的丢失。另一方面,投影角度的选取与同一角度的投影对物体的表征能力也不同,对网络的泛化能力有一定的影响。
1.2 基于体素的方法
基于体素的方法,通过把不规则和无序的点云数据进行体素化操作,使点云数据变成规则化的三维栅格结构,然后使用三维的卷积神经网络架构进行训练。Wu等[12]于2015年提出一种基于体素的三维深度信念网络3D ShapeNets。该算法将点云数据表示为一系列的三维栅格,然后用卷积神经网络进行训练。Maturana等提出一种面向三维体素的三维卷积神经网络VoxNet[13]。基于体素的方法通过网格化点云数据提供了点云结构信息。但是这种方法只使用了点云结构信息,丢失了点云的颜色信息、法向量信息等其他重要特征。而且,三维卷积运算的计算时间复杂度高,造成网络效率低下。因此,为了减小网络的计算量,通常会减小体素的分辨率,如同图像中减小图像输入尺寸,但是这样操作会造成量化误差的问题。针对上述问题,一些研究人员提出了改进的方案。Klokov等[14]提出采用KD树(kdimensional tree)来规则化点云数据的深度网络模型,称为Kd-Net。Gernot等[15]利用非平衡八叉树来表征点云结构,提出OctNet网络模型。Tchapmi等提出一个3D点级分割的端到端框架SEGCloud[16],该框架将点云细分为体素网格,结合了卷积神经网络、三线性插值和全连接条件随机场的优点。这些方法虽然对基于体素的方法做了不同方面的改进,但是对于体素化造成的量化误差没能解决。
1.3 基于点云的方法
点云数据本身具有很多特征信息,如果能直接利用这些信息,不仅能减少预处理的过程,而且能更充分地挖掘点云特征信息。因此,近几年基于原始点云的深度网络模型逐渐被提出。Qi等在2017年提出第一个直接对点云数据进行处理而不做预处理的深度学习网络架构PointNet[17]。PointNet通过对称函数来处理点云的无序性,使用空间变换网络解决物体姿态变换不变性。虽然PointNet在点云特征提取方面取得了突破性的进展,但是PointNet没有充分利用点云数据的局部特征。为了解决上述问题,PointNet++[18]提出一种局部特征提取方案。它根据距离度量将点集划分为重叠的局部区域,然后利用PointNet网络结构提取局部区域的点云特征,然后把局部区域进一步分组为更大的单元,并进行处理以生成更高级别的特征。虽然该模型改善了局部特征提取的问题,但是点特征是以独立和孤立的方式学习的,忽略了与相邻点及其特征的相对关系。Engelmann等[19]在PointNet的基础上,为了合并更大范围的空间上下文信息,提出了输入级上下文和输出级上下文2个扩展,成功应用于室内和室外点云语义分割任务当中。为了使CNN更好地处理无序的点云数据,PointCNN[20]提出学习一种X变换算子,即通过深度网络学习一个置换矩阵,对输入数据进行排序和加权。针对处理大场景三维点云语义 分 割 的 需 求,Landrieu等[21]提 出 超 点 图(superpoint graph,SPG),具有丰富的边缘特征,可对3D点云中对象部分之间的上下文关系进行编码,可以处理大规模的点云场景。Wang等[23]提出动态图卷积神经网络(dynamic graph CNN,DGCNN),首次使用了图卷积神经网络来改进点云中的特征提取工作。该算法构建了EdgeConv算子,用于提取中心点的特征和中心点与K近邻域点的边缘向量。Su等[24]于2018年提出针对点云处理的稀疏点阵网络SPLATNet(SParse LATtice Networks)。SPLATNet直接将点云数据作为输入,并使用稀疏而高效的点阵滤波器来计算分层和空间感知的特征。此外,SPLATNet允许将2D信息轻松映射到3D,用于点云和多视图图像的联合处理。Jiang等[25]受到传统图像中的尺度不变特征变换(SIFT)的启发,设计了一种可用于点云特征提取的模块PointSIFT。该模块用于对三维点云在不同方向上的信息进行编码,具有尺度不变性。
2 算法思想
设图G=(V,E)表示点云的局部结构,其中V是无序顶点的集合,E是表示顶点v∈V之间的连通性的边的集合。如果ei,j∈E,则顶点vi和vj通过边ei,j彼此连接。
2.1 局部特征
PointNet网络[17]仅对点进行孤立的特征提取,从而缺乏对局部点云特征的学习。PointNet++[18]在PointNet基础上对点云进行区域采样,并使用PointNet作为区域特征提取器,逐层提取并整合局部特征至全局特征。然而PointNet++中仍然用到了PointNet,意味着在采样的区域内,点的特征是单独提取的,对于局部特征的学习仍然不够充分。
EdgeConv[23]提出获取点云局部特征的一种方法。不是直接聚合邻域特征,而是建议首先通过从中心特征中减去中心顶点的特征来获取每个邻域的局部邻域信息。然而网络的深度限制了对于更细粒度特征的提取。为了训练更深的GCN,向EdgeConv添加残差连接和膨胀图卷积。将中心点的特征与两点的特征差串联后输入多层感知机(multi-layer perception,MLP),这样边特征就融合了点之间的局部关系与点的全局信息。
2.2 残差连接
传统的卷积神经网络存在致梯度消失问题,导致无法训练很深的神经网络。He等[4]提出的ResNet在一定程度上解决了上述问题,它设计了一种跳跃连接(skip connection)结构,使得网络具有更强的恒等映射(identity mapping)的能力,从而拓展了网络的深度,同时也提升了网络的性能。借鉴残差学习在CNN的成功应用,将该结构用于图卷积网络当中,解决图卷积网络层数不能过深、梯度消失的问题。
考虑通过卷积网络由L层组成,每层实现一个非线性变换Hl(·),其中l表示网络第l层。定义Hl(·)可以是诸如卷积(Conv)、池化(Pooling)、校正线性单元(ReLU)[26]或批处理规范化(BN)[27]等操作 的 函 数。分 别 用Gl=(Vl,El)和Gl+1=(Vl+1,El+1)表示网络第l层的输入和输出。网络第l层的输出作为第l+1层的输入,然后经过第l+1层得到Gl+1=Hl(Gl,Wl),其中Wl是第l层可学习的权重参数集合。在这里,提出了一种图残差学习框架,该框架通过拟合另一个残差映射F来学习所需的底层映射H。在Gl通过残差映射F转换后,执行逐点加法得到Gl+1。

如图1所示,残差映射F学习将图作为输入,并为下一层输出残差图形。

图1 残差连接示意Fig.1 Residual connection
2.3 空洞卷积
传统卷积神经网络通过池化层进行下采样来减少图像大小,同时增大感受野,然后再通过上采样操作将图像恢复成原大小。但是,下采样会降低图像分辨率,造成空间信息损失。Yu等[5]提出的空洞卷积(dilated convolutions)可以在一定程度上避免这个问题。空洞卷积是在普通的卷积核内加入空洞,相当于在卷积核相邻2个元素直接加入零元素。空洞卷积网络本质上实现了去掉下采样操作的同时不降低网络的感受野。将空洞卷积的思想应用于图卷积神经网络当中,以减轻由池化聚集操作造成的空间信息损失。
首先需要构建一个扩张领域,在每一个GCN层后使用扩张K近邻(dilated K-NN)去寻找扩张领域,并构建了一个扩张图(dilated graph)。具体来说,对于一个扩张K近邻的输入图,用d表示扩张率,扩张K近邻通过跳过每一个d邻域,返回k×d邻域内k个最近邻居。最近邻是根据预先定义的距离度量确定的,在实验中,使用L2距离,即欧几里得距离(Euclidean Distance)。
让N(v)定义为顶点v的d-dilated的邻居,如果(u1,u2,…,uk×d)是排序了的前k×d近的邻居,那么顶点是顶点v的d-dilated的邻居。因此,输出图的边定义在一组d-dilated顶点邻域上,如图2a所示。具体地说,存在一个从顶点v到每个顶点的有向边,其中GCN聚合和更新函数是基于Dilated k-NN创建的,应用于获得所有顶点的输出顶点的特征,如图2b所示。将更新后的顶点表示为v′,然后由具有扩张率为d的扩张图卷积(dilated graph convolution)生成的输出图中均匀抽样邻域以很小的概率执行扩张聚合,从而进行随机聚合。

图2 图像中的空洞卷积和GCN中的空洞卷积Fig.2 Dilated convolutions of image and dilated convolutions of GCN
2.4 密度自适应
当前传感器采集到的点云密度分布差异非常大。考虑到传感器采集到的3D点云的不均匀性,提出使用密度函数对学到的权重进行加权。点云表示为一组3D点,其中每个点Pi是其(x,y,z)坐标加上额外特征通道(例如颜色、法线等)的向量。为简单起见,除非另有说明,这里仅使用(x,y,z)坐标作为点的通道。在邻域G中,3D点的 相 对 坐 标 表 示 为(xμ,yμ,zμ)。函 数F(x+xμ,y+yμ,z+zμ)是以点p=(x,y,z)为中心的局部区域G中一个点的特征。在每个局部区域,(xμ,yμ,zμ)可以是局部区域中的任意一点位置。连续函数W(xμ,yμ,zμ)表示每个点对应的特征F的权重,其输入是以(x,y,z)为中心的邻域内的点的相对坐标。函数W可以使用多层感知器(MLP)来近似。定义密度系数函数D(xμ,yμ,zμ),它的输入是点的密度,它的输出是每个点对应的密度系数。

文献[28]考虑了权重函数的近似,但没有考虑对采样密度的近似,因此不是连续卷积算子的完全近似。本文提出的权重函数通过多层感知机从三维坐标中近似,密度函数利用一个核密度估计[29]以及一个非线性变换(MLP)近似实现。MLP在所有点之间共享权重,可以保持排列不变性。为了计算密度尺度估计函数D(xμ,yμ,zμ),首先使用核密度估计离线估计点云中每个点的密度,然后将密度输入MLP以进行一维非线性变换。
2.5 网络架构与分析
提出的网络模型(如图3所示)由GCN模块、融合模块和MLP预测模块组成。GCN主干块将具有4 096个点的点云作为输入,堆叠28个具有动态k-NN的EdgeConv层,每个层都与DGCNN[22]中使用的层相似。通过应用连续的GCN层以聚合局部信息来提取特征,并输出具有4 096个顶点的学习图形表示。然后,在每一个GCN块中添加动态膨胀k-NN和残差图连接。融合和MLP预测块遵循与PointNet++[18]和DGCNN[23]类似的架构。融合块用于融合全局和多尺度局部特征。它从每个GCN层的GCN主干块中提取出的顶点特征作为输入,并将这些特征连接起来,然后将它们传递给1×1卷积层,然后进行最大池化。后一层将整个图形的顶点特征聚合到单个全局特征向量中,而后者又与来自所有先前GCN层的每个顶点的特征(全局信息和局部信息的融合)串联在一起。MLP预测块将3个MLP层应用于每个点的融合特征,以预测其类别。实际上,这些层是1×1卷积。

图3 网络架构Fig.3 Network architecture
3 实验
为了评估本文提出的网络结构的有效性,对点云分割任务进行了广泛的实验。从实验结果可知,本文方法可以显著提高分割准确度。此外,还进行了全面的消融研究,以显示框架中不同结构的效果。
3.1 三维模型零件分割实验
零件分割是一项具有挑战性的点云识别和分割任务。同样在ShapeNet数据集上进行零件分割实验。ShapeNet数据集包含来自16个类别的50个零件的16 881个形状。该任务的输入是点云数据,任务的目标是为点云中的每个点分配一个零件类别标签。给出了每种形状的类别标签。通常,通过使用已知的输入3D对象类别,将可能的零件标签缩小到特定于给定对象类别的部分标签。而且,还将每个点的法线方向计算为输入特征,以更好地描述基础形状。
使用点“交并比(IoU)”来评估的网络,与PointNet[18]、PointNet++[19]和其他一些点云分割算法相同。结果显示在表1中。从表格数据可以看出,网络架构获得的实例平均交并比为86.0%;最差的结果出现在对“火箭”的分割结果上,为60.2%;最好的结果出现在“笔记本电脑”,为95.8%。若以单独某个分类的零件分割结果的IoU作为评判标准,表1中列出的分隔结果中,16个分类中有5个分类取得了最好的效果。在其他未取得最好效果的分类中,其分割结果与最佳结果的差距小于3个百分点。网络架构在ShapeNet零件分割任务中取得了较好的结果。

表1 ShapeNet零件数据集[30]上的零件分割结果Tab.1 Result of part segmentation in ShapeNet dataset[30]
将ShapeNet数据集上零件分割的部分结果可视化,如图4所示。从可视化结果可以看出,模型的分割结果与真实标注接近,对于零件分割的任务表现得较好。
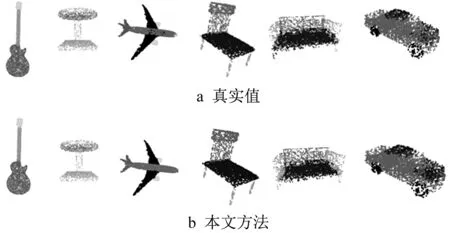
图4 ShapeNet零件分割结果Fig.4 Result of part segmentation in ShapeNet dataset
3.2 三维模型场景分割实验
斯坦福大学大型3D室内空间S3DIS数据集[31]从3个不同的建筑物(包括271个房间)中提取了6个文件夹的RGB-D点云数据。每个点都有来自13个类别的标签注释。按照文献[17]的k折策略将其分为训练和测试集。表2中显示了总体精度和平均交并比。可以看到,本文方法获得了64.6%的平均交并比、75.7%的平均准确率。实验效果比PointAGCN效果更好。使用本文方法得出的预测值与真实值对比如图5所示。

图5 S3DIS数据集[31]上语义分割的可视化结果Fig.5 Visual result of semantic segmentation in S3DIS dataset[31]
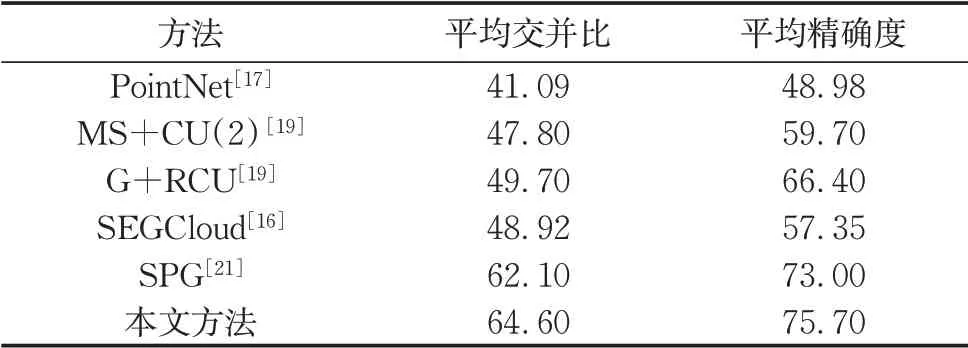
表2 S3DIS数据集[31]上的三维语义分割结果Tab.2 Result of 3D-semantic segmentation in S3DIS dataset[31]
3.3 对比实验
调查了不同的结构的性能,例如残差连接、空洞卷积、密度自适应;研究了不同参数的影响,例如k-NN邻居数(4、8、16),滤波器数(16、32、64)和网络层数(7、14、28、56);进行了20个实验,并将其结果显示在表3中。其中,模型1是基准模型,没有添加残差图连接和空洞卷积,k-NN邻居数为16,滤波器值为64,网络层数为28,作为对比实验的基线。

表3 S3DIS斯坦福数据集[31]上不同变量的对比实验Tab.3 Comparison of different variables in S3DIS dataset[31]
(1)残差连接:从表3中的实验1和2可以看到,在添加残差连接之后,平均IoU提升了5.49%。实验表明,残差图连接在训练更深的网络方面起着至关重要的作用,因为它们往往会导致更稳定的梯度。
(2)空洞卷积:表3中的实验1和3结果表明,加入空洞卷积之后,平均IoU中占比提高了6.37%,这主要是由网络感受野的扩展引起的。当同时添加残差连接和空洞卷积时,性能会进一步得到提高。
(3)K值:表3(K值)中的结果表明,更多的邻居通常对网络有帮助。随着邻居数量减少到原来的1/2或1/4,性能分别下降2.15%和3.79%。
(4)网络层数:按照表3的网络层数一栏所示,将网络层数设为7、14和56进行对比实验。实验结果表明,增加网络层数可以提高网络性能,网络层数越大意味着网络深度增大。当网络层数减小时,实验结果会受到影响。
(5)滤波器数:表3中的结果表明,滤波器数量增多会获得与增加层数类似的性能提升。通常,较高的网络容量可以让网络学习到更深层次的特征。
4 结语
为了成功训练更深层的GCN网络,减轻梯度消失问题,借用了成功训练深层CNN的相关概念,引入残差连接、空洞卷积等结构,训练更深层的点云分割网络。同时,由于3D点云是一种不规则且无序的数据类型,传统的卷积神经网络难以处理点云数据。提出一种密度自适应的方法,可以高效地对非均匀采样的3D点云数据进行卷积操作,该方法在多个数据集上实现了优秀的性能。
作者贡献说明:
卫刚:论文撰写,深度神经网络设计。
赵安铭:论文撰写,深度神经网络设计与程序设计。
王志成:深度神经网络设计与数据分析。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年11期)2021-11-27
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
北京航空航天大学学报(2020年10期)2020-11-14
学生天地(2020年18期)2020-08-25
北京航空航天大学学报(2019年9期)2019-10-26
故事作文·高年级(2017年2期)2017-03-01
中学生数理化·高一版(2009年6期)2009-08-31
