
基于神经网络嵌入和动态社交的新闻推荐算法
2021-07-16 08:02万梅曹琳
计算机应用与软件 2021年7期
万 梅 曹 琳
1(广州工商学院计算科学与工程系 广东 广州 510850) 2(南方医科大学基础医学院 广东 广州 510515)
0 引 言
随着移动互联网的普及,人们在许多平台均成为了社交网络的一个成员,并且许多人在多个不同类型的平台均建立了社交关系[1]。目前含有社交网络的应用平台包括网易云音乐、淘宝网、豆瓣电影和抖音短视频等[2]。近期网红经济的发展也十分迅速,一部分流量明星和网红拥有巨大的“带货”能力,对潜在消费者的购买决定具有极大的影响力。人们在社交网络上所表现出的社群特点和兴趣聚合特点,促使专家学者研究利用社交网络提高推荐系统的效果,最终最大化商品的销售量以及服务的满意度[3]。
国内外的专家学者已经提出了诸多社交网络和推荐系统结合的成功方案。文献[4]提出了企业间供应关系和推荐系统的结合方法,通过分析企业间的联系促进推荐系统的推荐多样性。文献[5]首先提取用户的社交档案和社区标签,再结合新闻的语义空间向量预测相似用户的偏好,该算法在新闻推荐问题上取得了较好的推荐准确率。文献[6]围绕社交推荐的特点,设计实现了一种社交网络评分预测方法,解决了评分预测中用户评分主观性及评分数据稀疏带来的预测不准确问题。文献[7]将传统聚类方法与蛋白质网络的新特性相结合,提出了一种竞争-抑制节点模型,该模型通过数据预处理和特征值竞争抑制机制较好地完成数据过滤,从而提高数据处理效率并提升最终推荐结果的精度。文献[4-7]均基于社交网络的静态拓扑结构,并未考虑社交网络动态演化对用户偏好的影响。然而,社交网络上的信息来源日益增多,且传播速度极快,因此需要对社交网络信息进行实时地动态分析,才能最大化社交网络信息的价值。
考虑社交网络动态演化对用户偏好的影响,提出一种基于神经网络嵌入和动态社交网络拓扑结构的新闻推荐系统。首先使用神经网络嵌入学习方法来学习用户的时域行为特征,使用无监督的图上随机游走方法学习社交网络拓扑的结构信息,利用插值法将两个嵌入向量融合成一个用户表示向量。然后,利用核映射方法将用户表示向量映射至低维空间,从而提高相似性计算的效率。基于新浪微博数据完成了新闻推荐实验,结果表明引入用户时域的行为信息能够增强推荐系统的性能,并且采用神经网络嵌入学习的效果好于传统基于概率的表示方法。
1 问题模型
本文的第一个目标是将社交网络的用户分成不重叠的社群,同一个社群内的用户应当对相似的项目内容(电影、商品、新闻等)表现出相似的时域行为,并且用户间存在密集的社交连接。
问题模型可描述为:给定一个用户集U,问题目标是将U分成不重叠的子集,每个用户u∈U属于唯一的子集。将社群分组结果表示为P={C:C⊂U,|C|>1},其中∀Ci,Cj≠i∈P:Ci∩Cj=∅。本文的目标是识别出目标P,P的每个成员Ci对目标项目的时域行为相似。
2 方法设计
本文通过三个阶段寻找目标P:(1) 基于时域行为的社交网络表示学习;(2) 神经网络嵌入;(3) 检测目标社群。
用户时域行为设为D=(U,M,T),其中U为用户集,M为用户产生的内容,例如:商品评价、评分等,T为一个时间段。将社交网络的拓扑结构建模为有向图,记为Γ=(Y,A),其节点为Y中的用户,边为每对用户的社交关系,如:(u,v)∈A表示u“关注”v的关系。
从两个信息源建立用户表示:(1) 基于时域社交行为D=(U,M,T)的时域信息嵌入;(2) 基于社交网络拓扑结构Γ=(Y,A)的社交连接嵌入。首先,从用户的时域行为学习用户的向量表示WD,时域行为相似的用户在向量空间应当更加靠近。提出一种嵌入学习方法,通过最大化两个用户间相似性,保证两个用户在向量空间内靠近。然后,从社交网络的邻居节点学习用户的网络拓扑表示WG,采用无监督的图上随机游走[8]方法学习拓扑结构,学习的向量空间几何关系反映了原社交网络的拓扑结构。从时域社交行为和社交网络拓扑结构所学习的向量表示之间彼此独立,然后将这两个单模表示通过线性插值结合成一个多模表示。
2.1 基于时域行为的嵌入学习
将用户时域行为表示为三元组格式D=(U,M,T),其中U为用户集,M为U产生的内容,T为一个时间段。从M中检测出时间段T内的偏好项目集Z,将用户u∈U在时间段1≤t≤T内对项目z∈Z的偏好表示为一个时间序列,记为Xuz=[xuz,1,xuz,2,…,xuz,T],其中xuz,t∈P表示用户u在时间t对项目z的偏好。将所有用户的项目偏好时间序列组成一个三维结构,记为Ξ={xuz,t:u∈U,z∈Z, 1≤t≤T}。
图1给出了3个用户对于5个项目的兴趣度演化实例图,图中用户2和用户1在第1~10天对项目4表现出相似的时域行为,用户2和用户3在第5~7天对项目3表现出相似的时域行为。
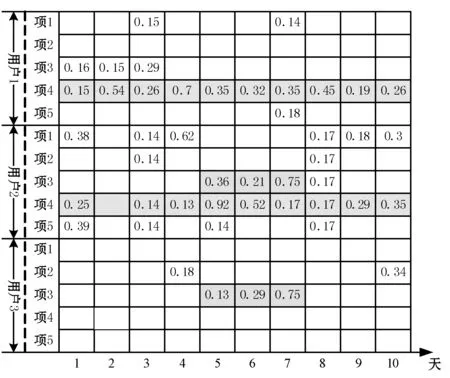
图1 3个用户对于5个项目的兴趣度演化实例
本文的多元时间序列能够准确捕捉用户对指定项目的兴趣演化过程。该方法包含两个步骤:(1) 使用LDA[9]搜索时间段T内的项目集Z;(2) 使用文献[10]的偏好模型计算每个用户在时间t对项目z∈Z的偏好,记为xuz,t。具体处理方法为:将指定用户发布的所有评价收集到一个文档中,所有用户的评价集合组成文档语料库。采用LDA主题模型技术处理该语料库,获得一个主题集Z。在本文的推荐系统中,LDA模型的主题对应推荐系统的项目,主题z∈Z是一个多项式分布,描述了每个项对主题z的贡献程度。
1) 时域行为模型。为了学习所有用户的神经嵌入表示,每个用户需要被定义在其他用户的上下文。首先将评分、评价内容以及时域行为上相似的用户作为一对用户,然后通过嵌入方法维持每对用户的相似性信息,使两个偏好相似的用户在向量空间内靠近。
根据两个用户之间的同质性和偏好相似区域的数量定义嵌入学习的目标函数,目标函数将偏好相似区域多的用户分入一个社群,将偏好相似区域少的用户分为不同的社群。将两个用户间的偏好相似区域作为神经嵌入学习的上下文。
定义1偏好相似区域。将偏好时间序列X的子空间R定义为偏好相似区域,需满足以下两个条件:(1) 子空间内的每个值具有相等的同质性;(2) 不存在其他的相似区域R′,使R⊂R′,即R为最大化的相似区域。将满足条件的子空间R记为P。
搜索偏好相似区域P的步骤为如下:(1) 搜索用户在时间t的偏好项目,获得一个二维的向量Pt, 1≤t≤T;(2) 合并所有时间t的向量,产生最终的P。
2) 基于时域行为的嵌入学习。将嵌入学习问题建模为基于用户上下文的相似用户最大似然问题,将与目标用户偏好相似区域Ρ相似的用户集作为目标用户的上下文。因此,两个用户在彼此上下文出现次数越多,那么他们之间相似度越高。采用连续词袋模型(CBOW)[11]对用户进行嵌入学习。
定义2基于时间行为的嵌入学习。假设偏好相似区域的集合为P,嵌入函数f:Y→Pd将每个用户u∈Y映射到一个d维空间[0,1]d,其中d<<|Y|。映射的目标是优化以下表达式:

(1)
为了简化分析,假设用户在偏好相似区域内是条件独立的,可得以下关系:

(2)
采用图2所示的网络结构对用户进行嵌入学习。

图2 嵌入学习用户表示的网络结构
相似偏好区域的计算式为:
R={u,v,…}×{zi,zj,…}×{i,j,…}
(3)
式中:R为相似偏好区域;u为目标用户;v表示用户上下文;z表示项目;i和j为项目编号。

(4)
结合式(2)和式(3)可将式(1)简化为:
(5)
式(4)的计算复杂度和Y的规模成正比例关系,显然不适合大规模社交网络的应用场景,因此采用分层的Softmax技术[12]来近似完全Softmax计算以提高计算效率,将隐藏层到输出层的连接矩阵变换为一个二叉哈夫曼树,用户作为叶节点。每个用户u在树中对应一条搜索路径u1→u2…→uh(u),其中h(u)为u的深度。采用哈夫曼树能够将时间复杂度从O(|U|)加快到O(log|U|)。分层Softmax条件概率Pr(u|v)的计算式为:
(6)

使用反向传播和梯度下降法训练神经网络。训练达到收敛之后获得一对偏好相似的用户,设为u,v∈U,这两个用户的嵌入向量表示Vu和Vv在时域空间D=(U,M,T)内相似。
2.2 基于社交网络拓扑的嵌入学习
设社交网络的拓扑结构为Γ=(Y,A),其中Y为用户集,A为用户间的连接集,通过嵌入学习获得用户在社交网络中的局部结构表示。
(1) 邻居上下文模型。如果两个用户的相似邻居越多,那么这两个用户属于同一个社区的可能性越大,因此这两个用户在嵌入空间内也应当靠近。实际社交网络的社区内存在一些等价结构,因此采用随机游走对目标用户的邻居进行随机采样,提高搜索过程的效率。
定义3网络邻居。用户u∈U的邻居集设为Nu。从根节点u开始在网络Γ=(Y,A)进行长度为l的随机游走,随机变量为[x1:l],如果(v,w)∈A,那么根据概率分布Pr(xl=w|xl-1=v)从xl-1的邻居中选择一个用户xl;否则将随机变量置0。
采用二阶随机游走方法,其返回参数为p,进出参数为q,偏游走方法定义为:
(7)
式中:d()表示加权图中两个用户间最短路径的距离。p值越高,更倾向于探索未知区域,q值越高,更倾向于局部开发。
(2) 基于网络拓扑的嵌入学习。获得所有用户的邻居之后,通过优化相同游走用户的条件概率,对每个用户进行嵌入学习。
定义4基于网络拓扑的嵌入学习。设邻居集为N=Uu∈YNu,嵌入函数g:U→Rd将每个用户v∈U映射到d维空间[0, 1]d,d<<|U|,对以下的目标函数进行优化:
(8)
采用图2所示的神经网络结构。隐藏层H的大小为d,输入层到隐藏层的连接表示为矩阵Wg,矩阵大小为|Y|×d,每行表示一个用户向量。输入层I为独热编码的向量,隐藏层神经元为线性映射函数;H=WTI。给定一个用户v,H是Wg中v行的转置向量,表示为Vv。隐藏层到输出层的连接矩阵W′g大小为d×|Y|。通过Softmax函数近似用户u的概率,其计算式为:
(9)
式中:V′u为u在矩阵W′g中的列。采用随机梯度下降法和反向传播训练神经网络,网络输出基于社交网络拓扑的嵌入向量表示Wg。
2.3 插值处理
上文从时域社交行为D=(U,M,T)和网络拓扑结构Γ=(Y,A)分别获得嵌入学习表示WD和Wg,然后通过插值函数h(WD,Wg)将两个向量融合为一个向量。本文的插值函数定义为:
h(WD,Wg)=αWD+(1+α)Wg
(10)
式中:α表示权重系数,用于控制不同向量的重要性。
3 子空间核心识别方法
基于嵌入学习的用户表示属于高维向量,因此需要将表示向量映射至低维空间。首先计算两个表示向量之间的最短路径,然后运用高斯核将向量映射到一个全局的相似性空间内。
3.1 子空间映射
使用稀疏线性编码将嵌入向量映射到低维空间。首先,计算每对向量几何距离Gvi,将每个用户的距离集表示为一个向量G∈Rn×n,G=[Gv1,Gv2,…,Gvn],其中n为节点数量。然后,运用以下的高斯核函数将映射距离向量,其结果作为相似性评分:
(11)
式中:σs为衰减率;⊙为一个点积运算。假设每个社群的内部连接密集,外部连接稀疏,所以社群内的最短路径数量应当少于不同社群内的最短路径。假设节点vi和其他节点的相似性为:
(12)
式中:αi=[αi(1),αi(2),…,αi(n)]为相似性系数向量,αi(j)是节点vi到节点vj的相似性;sj为式(11)计算的相似性向量。
然后使用l1正则项的稀疏线性分解寻找最优的相似性系数向量,其目标函数为:
(13)

(14)
式中:D为线性系数的低维映射结果。
3.2 识别社群核心
假设局部高密度区域的中心是每个区域的核心。首先,计算每个节点的全局影响值,然后,基于影响值识别社群的意见领袖。节点vi的影响值计算式为:
(15)
式中:di为D的第i行。式(15)同时考虑了网络的密度和几何距离,从时域和网络拓扑两个上下文识别局部的核心。将子空间内影响值最大的节点作为候选核心,节点vi的子空间定义为:
sub(vi)={vj|∀j=1,2,…,n,j≠i,D(i,j)>β}
(16)
式中:β定义了每个节点的影响范围。
算法1所示是子空间核心的识别算法,每个核心均为该子空间内影响值最高的节点。然后利用每个子空间的核心进行协同过滤推荐处理。
算法1子空间核心的识别算法
输入:β,D,S。
输出:子空间核心cc。
1.Pt= 计算节点的全局影响值;
//式(15)
2.cc= NULL;
//初始化cc变量
3.for eachifrom 1 toN
4.subspace(vi)=vi的节点;
//式(16)
5. for each 节点vjinsubspace(vi)
6.tag=TRUE;
7. ifinfluence(vj)>influence(vi) then
//影响力比较
8.tag=FALSE;
9. end if
10. if (tag== TRUE) then
11.cc=cc∪{vi};
12. end if
13.end for
4 实验与结果分析
4.1 实验准备
1) 实验数据集采集。利用公开的新浪微博数据集MicroblogPCU(下载网址:archive.ics.uci.edu/ml/datasets/microblogPCU)采集实验的数据集,原MicroblogPCU的目标是探索微博中的spammers(发送垃圾信息的人),对该程序进行修改,忽略MicroblogPCU程序中数据集属性列表(weibo_user.csv)的属性“is_spammer”,利用关键词搜索属性“topic”相同的用户列表,采集本文实验所需的benchmark数据集。
Benchmark数据集的采集方法为:利用LDA算法[9]搜索用户的偏好项目,将LDA算法的偏好项目数量设为30。为每个用户计算每日的项目偏好时间序列,过滤其中值始终小于0.1的用户。最终的Benchmark数据集共包含140 000个用户在2019.7.20—2019.8.20期间发布的3 000 000条微博。每条微博的信息包括微博内容、用户ID和发布时间。图3提取了三个微博用户对国产动画电影《哪吒之魔童降世》的热度变化情况。

图3 三个用户对项目的兴趣变化曲线
2) 模型建立和参数设置。在时域行为的嵌入学习中,训练神经网络的学习率设为0.025,每个epoch衰减为0.002,共设200个epoch。训练的窗口大小为2,设置三个向量大小:d={100,200,300}。
在社交网络拓扑的嵌入学习中,因为图卷积网络(Graph Convolutional Networks, GCN)具有较低的时间复杂度O(|A|),并且能够处理冷启动的用户,所以选择GCN作为嵌入学习的神经网络。每个节点完成5个长度分别为40和80的随机游走,训练的窗口大小为5。学习率和epoch数量分别为0.002和200,随机游走的参数p和q均设为缺省值1。
插值嵌入程序的参数α设为0.1,0.2,…,1。通过试错实验决定子空间核心识别程序的β参数,发现β<0.3的性能差于β≥0.3,并且β≥0.3时性能差异较小,因此将子空间核心识别程序的参数β设为0.3。
3) 对比方法选择。本文算法的特点包括:① 引入用户时域行为增强推荐系统的性能;② 通过神经网络嵌入学习用户的表示。为了验证上述两点的有效性,选择了以下的对比方法。
(1) 基于社交网络拓扑结构的推荐系统[14]。该方法不包含对用户时域行为的分析和利用,将其简记为LDA。该方法可验证第①个特点的有效性。
(2) 基于多元时间序列的推荐系统[15]。该方法利用概率模型将用户的时域行为建模为多元时间序列,将其简记为TLUCI。该方法可验证第②个特点的有效性。
(3) 基于用户时域演化和社交网络拓扑结构的推荐系统[16]。该方法利用概率模型建模用户的行为历史,将其简记为MFG,其参数候选项目数量分别设为10、20、30。该方法可综合验证本文方法的有效性。
4.2 实验方法
新闻推荐实验的步骤为:(1) 分割每个时间t(0~32)的社群,搜索每个时间的总项目列表;(2) 通过协同过滤为每个用户产生相应的推荐列表。
采用两个常用指标评价新闻排列系统的推荐性能,分别为精度P-k和平均倒数排名(Mean Reciprocal Rank, MRR)[17]。P-k评估了推荐项目的准确性,MRR评估了推荐列表的排列效果。
P-k的计算式为:
(17)
式中:tu为top-k推荐列表中用户u相关的新闻数量,P-1表示top-1列表的推荐精度,P-10表示top-10列表的推荐精度。
MRR的计算式为:
(18)
式中:ranku是用户u第1个相关新闻内容的排列位置。
4.3 结果分析
图4是不同推荐系统的平均推荐结果,图中NR(News Recommendation)为本文算法的简称。LDA的推荐精度和MRR均较低,可看出用户的时域信息对于推荐性能具有较大的贡献。MFG在候选项目数量为20时获得了较高的推荐性能,其效果好于TLUCI,但是当候选项目数量为10和30时,其性能衰减的幅度较大,因此该算法受参数影响较大。NR系统在向量长度为200时取得了最佳的推荐效果,而且向量长度为100和300时也并未出现大幅度的性能衰减。
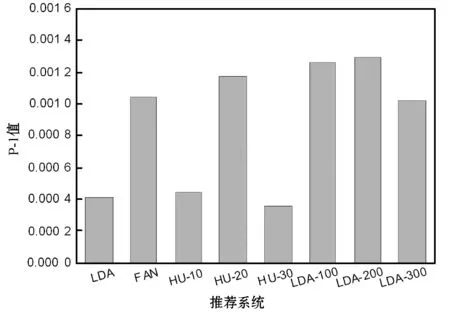
(a) P-1精度结果

(b) P-10精度结果

(c) MRR的实验结果图4 新闻推荐的平均实验结果
随之测试了图上随机游走对于NR推荐性能的影响,将游走长度l分别设为40和80,嵌入学习的向量长度设为200。图5是不同推荐模型的性能关于插值嵌入程序参数α的变化曲线,图中NR40和NR80分别对应l为40和80的推荐系统,NR0为仅包含时域行为(不包含社交网络拓扑结构信息)的NR推荐系统。从结果发现随机游走的长度越长,所提取的社交网络拓扑信息越准确,其推荐性能越好。通过设置合适的α值,NR40和NR80的推荐性能均能够明显好于NR0,因此,验证了结合时域行为信息和社交网络拓扑结构信息的效果好于单独采用时域行为信息的模型。
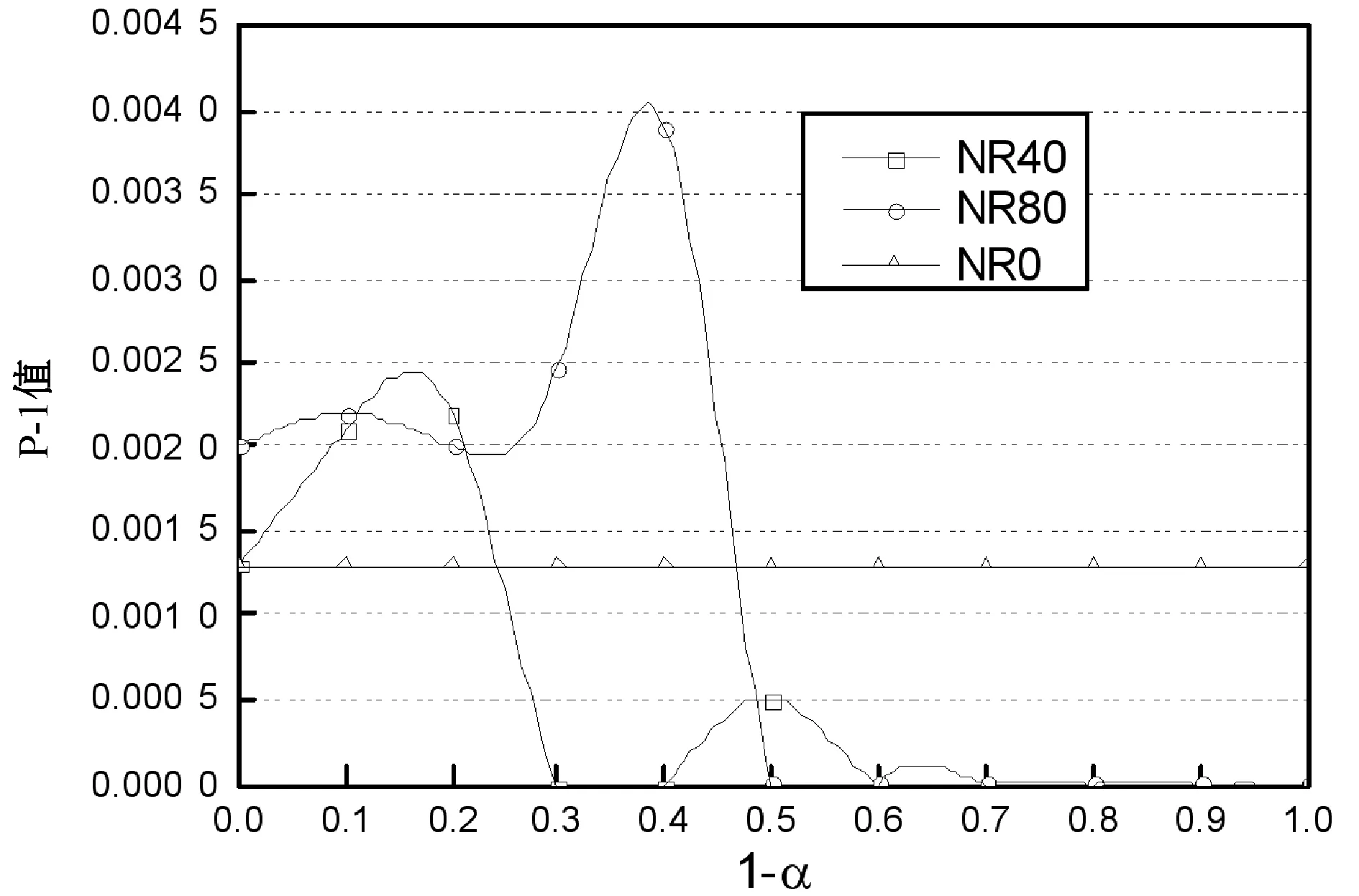
(a) P-1精度结果
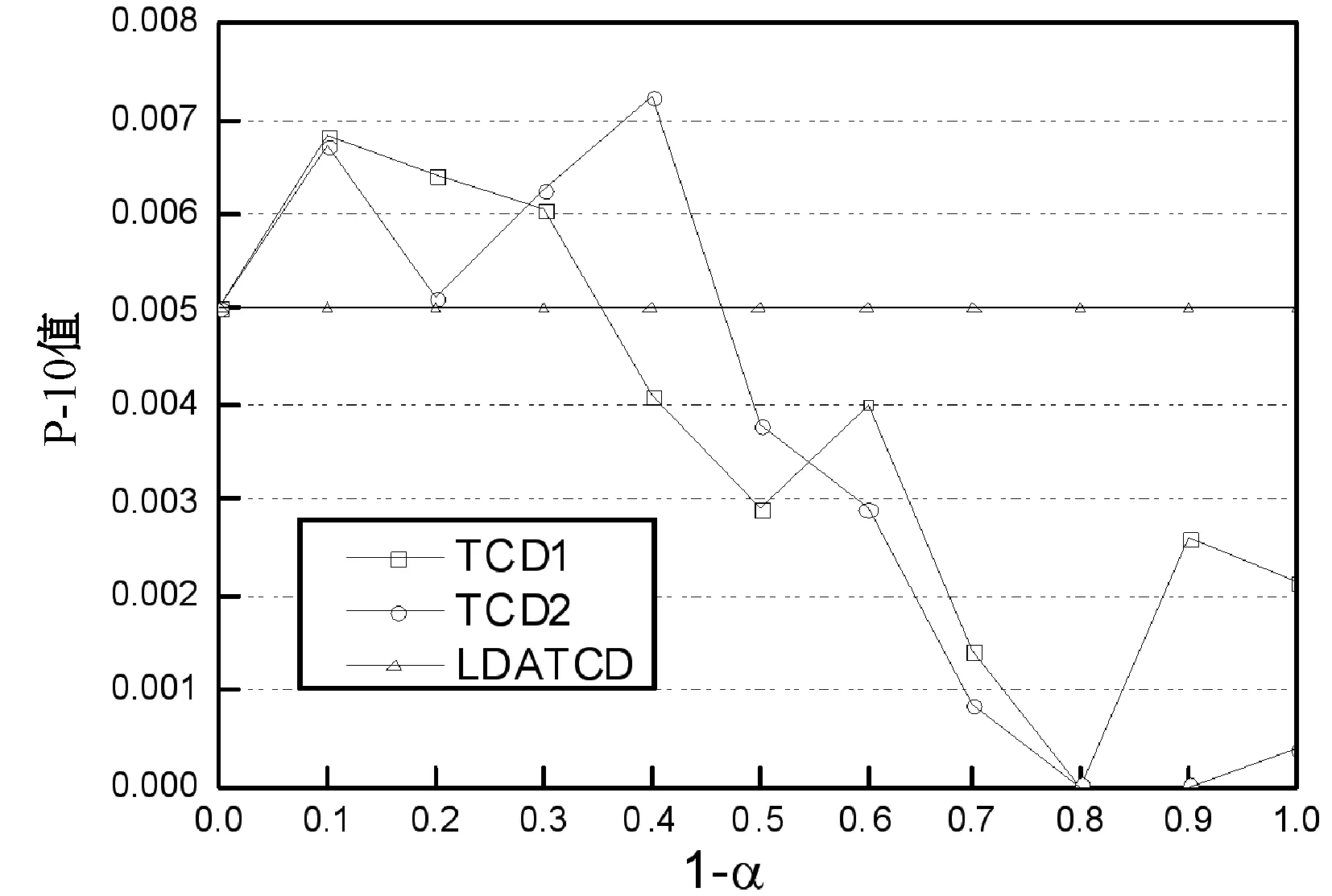
(b) P-10精度结果
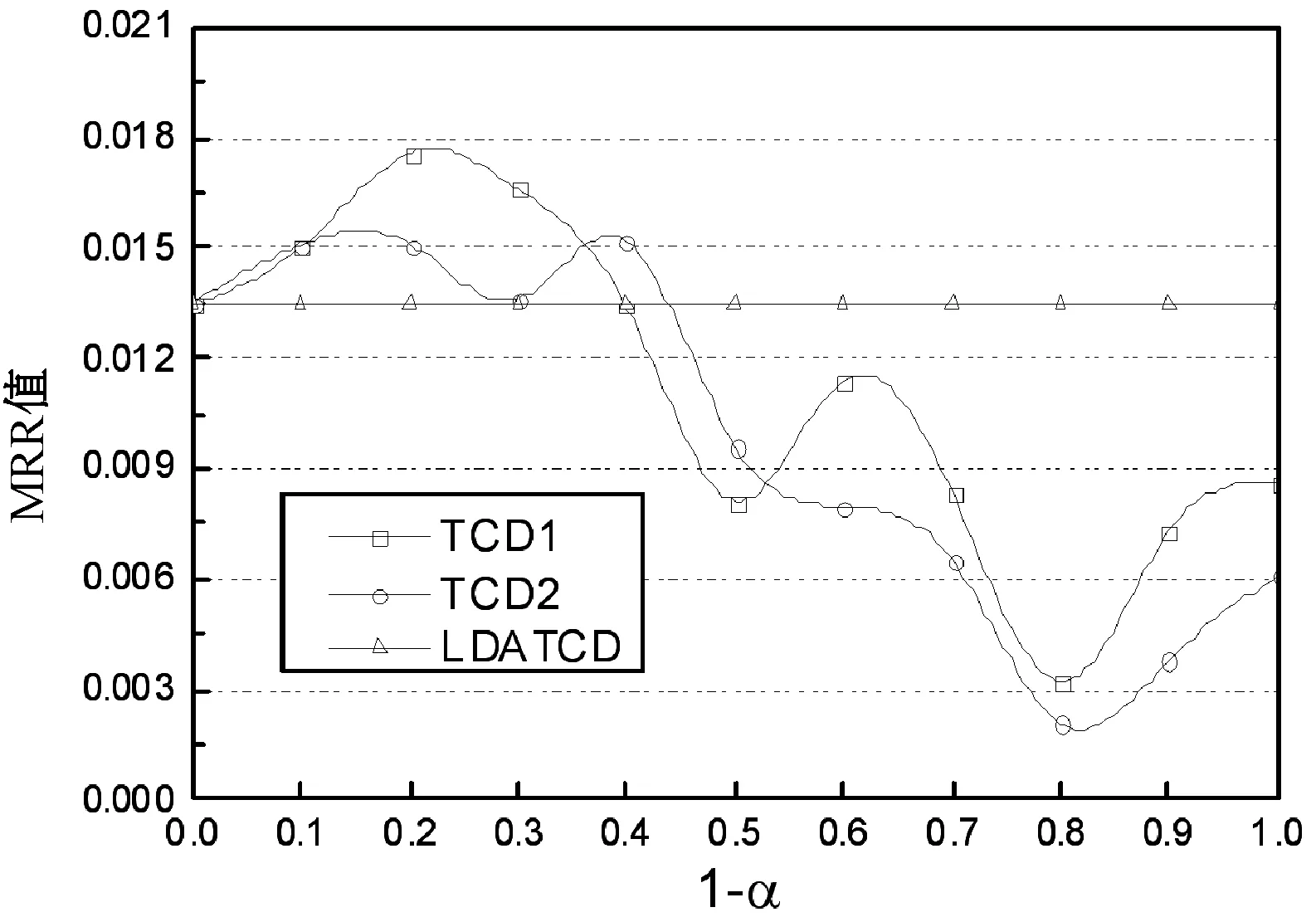
(c) MRR的实验结果图5 新闻推荐的平均实验结果
5 结 语
本文使用嵌入学习方法学习用户的时域行为,使用嵌入学习方法学习社交网络拓扑的结构信息。然后,利用核映射方法将用户表示向量映射至低维空间,从而提高相似性计算的效率。基于新浪微博的新闻推荐实验结果表明,引入用户时域行为能够增强推荐系统的性能,并且采用神经网络嵌入学习的效果好于传统基于概率的表示方法。
由于图上随机游走和神经网络嵌入学习的时间复杂度较高,因此本文方法仅支持以天为单位的应用场景,如新闻应用和音乐播放器的“每日推荐”等。本文方法难以支持推荐频率高、演化速度快的应用场景,未来将对图上随机游走和神经网络嵌入学习进行优化,在时间效率和推荐精度之间实现平衡。
猜你喜欢
花火彩版B(2020年5期)2020-09-10
销售与市场·渠道版(2020年2期)2020-03-17
销售与管理(2019年10期)2019-12-06
现代家电(2019年4期)2019-06-12
电子技术与软件工程(2016年23期)2017-03-06
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年13期)2016-06-29
电脑知识与技术(2016年12期)2016-06-14
销售与市场·渠道版(2016年1期)2016-02-23
