
基于互联网平台的城市通勤优化方案设计
2021-07-16 10:07万思伟洪懿琳
科学技术创新 2021年19期
万思伟 洪懿琳
(长安大学,陕西 西安 710064)
1 研究背景
1.1 通勤时段拥堵状况不容乐观
通勤,指人们往返于家和工作地点的过程,是一种短时间内相对稳定的出行活动。近年来,随着人口的增长、城市化的推进,人们的出行需求日益增加,而现有的道路交通基础设施的增长速度远远跟不上交通需求的增长速度,导致交通拥堵、出行困难等问题愈发凸显。尤其在上下班等高峰时段,大量“上班族”集中出行,加剧了拥堵的严重性。以北京为例,据资料统计,目前北京的早高峰从7 点提前到6 点40 分左右,并一直持续至9 点30 分[1],长期的交通拥堵不仅会降低个人的生活质量,对促进环境保护、社会经济发展等更是一项巨大的阻碍。
1.2 客运市场转型迫在眉睫
目前,国内经济已进入新常态发展,交通运输行业也逐步走向新的变革。在长途运输方面,当前中国高铁里程数位居全球第一,高速铁路以其快速、舒适的优势成为多数中长途旅客的优先选择;在短途运输方面,地铁、轻轨等公共交通迅速崛起,此类大、中运量的公共交通工具以其准时、运量大的优势占据了大部分市区内的乘客流量。由此可见,以公路运输为主的传统客运正逐渐被其它交通运输方式所替代,如何充分发挥道路运输“门到门”的优势是客运市场转型亟待解决的问题。
2 通勤优化方案设计
针对上文提出的问题,我们在“定制公交”理念的基础上,提出一种新的通勤优化方案,借助互联网平台利用旅游公司、客运站以及巴士公司等运输企业的空闲车辆在上下班时间运输通勤旅客,以达到缓解通勤时段公共交通流量突增的目的。本方案的设计思路如图1 所示。
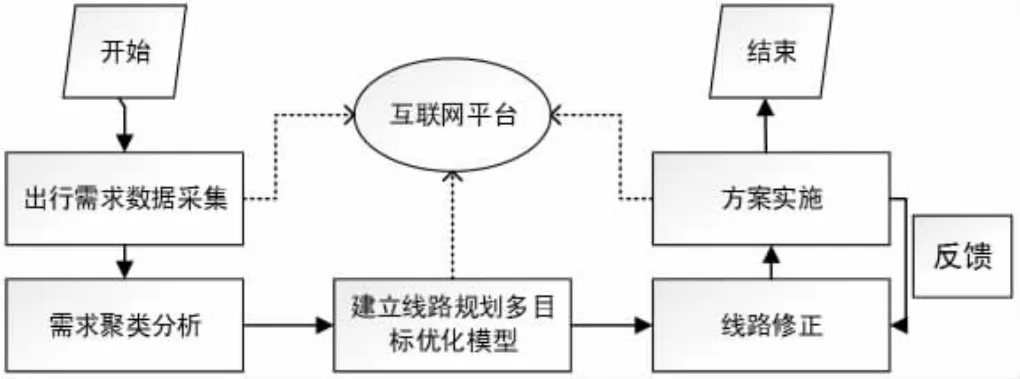
图1 通勤优化方案设计思路
2.1 信息收集及处理
利用互联网平台整合收集信息,可以分为收集目标旅客信息和运输车辆及驾驶员信息两个方面。
2.1.1 目标旅客信息
我们通过利用交通卡大数据来识别具有出行特征的通勤出行者。李娜等人在2020 年就有对公交IC 卡的数据进行深度挖掘,利用关联规则算法以及聚类分析等方法,根据出行OD 点到达频次等出行特性指标来准确筛选出具有通勤特征的出行者[2]。
2.1.2 运输车辆及驾驶人信息
城市中客运运输车辆及驾驶人的管理分布形式分为企业集中管理的车辆及驾驶人和离散的车辆及驾驶人。根据不同类型车辆及驾驶人信息收集途径不同的特点,前者利用互联网平台数据接口进行各个运输企业间的运输车辆及驾驶人员的动态数据共享,以寻求车辆的最大利用率,后者则利用小程序等移动客户端来进行数据的收集。
2.2 信息整合
互联网平台是一种将各个部分的信息资源进行整合的数据资源平台。其本身不产生数据,而是通过数据链接的方式将各个系统的数据资源进行整合,以提高对数据的利用率。我们将各个运输企业的车辆管理系统以及离散的运输车辆及驾驶人进行整合,安排通勤高峰时段空闲的车辆进行运输任务,提高运输车辆的利用率并缓解城市公共交通网络的客流压力。
2.3 路线设计
2.3.1 交通小区划分
2.3.1.1 概述
交通小区划分是指将具有类似交通特性以及区位特征的地区划分到相同的小区,使大量的微观交通源转化为少量的宏观交通源,从而在有限数量的独立空间中将大量无序的个体聚集在一起,形成交通特征分析的基本单元,进而降低交通网络的流量分析和交通预测的难度。交通小区的划分是设计运行线路的第一步,通过交通小区划分研究各个交通小区之间的出行特征,以便进行交通路线设计。
2.3.1.2 Mean Shift 聚类算法
本文根据出行者的OD 点所在地区的交通特性以及区位特征,利用Mean Shift 聚类算法将O 点和D 点分别进行交通小区的划分。
Mean Shift 聚类算法(均值偏移算法)实质是一种质心偏移的迭代算法,在二维坐标系中,计算以初始点为圆心,半径为R的圆的初始范围内的质心,并将该质心作为下一点,进行多次迭代直至质心不再移动,其质心与其一定半径范围内的点形成一簇。(图2)

图2 Mean Shift 聚类算法示意图
在划分交通小区时,我们不考虑空间的Z 轴坐标,选择在二维平面进行交通小区的聚合。则聚类算法的基本的向量推导过程如下:
我们将每个出行者作为独立的出行点,则对于给定的二维空间R2中的n 个出行点xi(i=1,2,…,n),其对该二维平面任意一个x 点的Mean Shift 二维向量的基本形式为:

其中,Sh指的是一个半径为h 的二维平面区域。Sh的定义为:
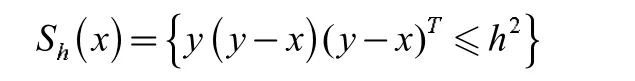
张宁等人在2011 年利用Logit 模型对轨道交通站点步行换乘接驳进行了建模研究,计算出在其研究的A 站周围居民可接受的步行折算范围为882 米[3]。因此,我们将这个可接受步行范围作为Mean Shift 聚类算法初始的Sh区域的半径。
该二维向量在Sh的区域内,每一个点对x 的贡献是一样的,但实际上却相反:这种贡献与到每一个点之间的距离相关,对于不同的样本,其贡献程度也是不一样的。因此,我们在Mean Shift 的基本向量形式中引入核函数和样本权重,来增加其聚类的真实程度,得到改进后的Mean Shift 向量形式:

其中,G(x)是单位的核函数,用于比较出行点之间的特征。W(xi)是每一个出行点的权重。H 是核函数的一个2×2 矩阵,称为带宽矩阵,其形式如下:

Mean Shift 聚类算法目标是将Sh的中心往出行点密度增加的方向偏移,则其概率密度Mh(x)的梯度方向是其密度增加较快的方向。利用该特点进行偏移向量的求解,令
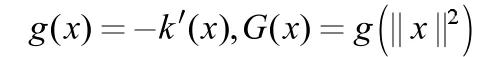
得到:
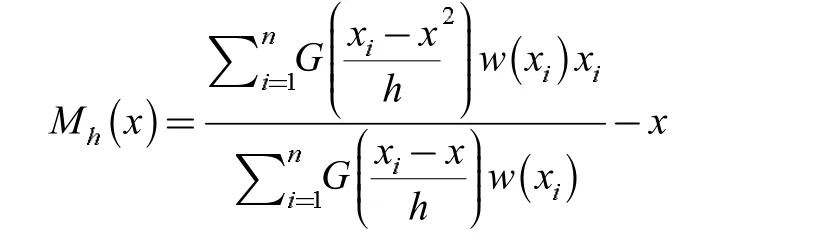
通过上式计算出下一个偏移的质心,并重复上述的过程,直到
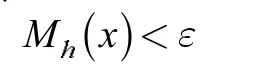
式中,ε 为质心偏移的最低阈值。当Mh(x)满足上式时,其说明在可接受最低阈值下质心偏移完成。依据聚类后的范围,对出行者进行划分,形成交通小区,选择距离该交通小区质心最近的公交车站作为该交通小区的出行点。
2.3.2 路线规划
陈汐等人在2020 年研究多区域通勤定制公交的线路时,提出多区域通勤公交线路设计模型,以乘客出行成本和运营成本作为多目标优化模型的优化目标,运用两阶段启发式算法计算出Pareto 解集,得出初始规划线路[4]。我们基于其思路进行通勤公交的线路设计,将交通小区分为居住区与工作区,并根据出行需求量排序,选择较大出行量的交通小区作为线路中的中枢站点,采用多目标优化模型,以出行者出行成本最小化、运营成本最小化、交通小区的出行需求量最大化为原则进行线路的安排。
我们先做出假设:
(1)每辆车在路线上仅安排运行一次;
(2)上车点乘客只能上车,下车点乘客只能下车。
马继飞等人将通勤公交线路[6]定义为:
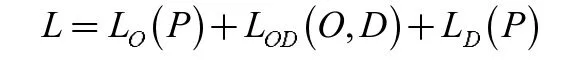
式中,LO(P)为上车点线路的路程,LOD(O,D)为上车点与下车点间的路程,LD(P)为下车点线路的路程。用时间来量化出行者的的出行成本,其包括车辆行驶时间和停车时间,停车时间包括到站停车时间和路段拥堵的延迟时间,则每位乘客的出行成本:
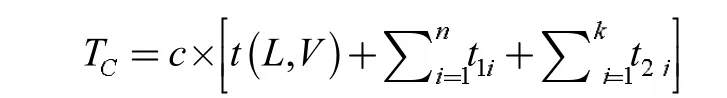
式中,c 为单位时间成本,t(L,V)为车辆的行驶时间,t1i为第i 个站点的停车时间,t2j为第j 条路段的平均拥堵时间。其中:

式中,V 为线路的设计速度。
每辆车的运行成本:
式中,E 为车辆的每单位所消耗的费用,Y 为其车辆每班次所需的维护费用。
其最后的求解目标是使乘客的时间成本与车辆的运行成本最小化:

最后利用多目标优化的遗传的NSGA-II 算法求解多目标优化模型,得出通勤公交的最佳路线。
2.3.3 路线修正
线路的修正主要包括两方面:
一方面考虑到陈汐等人的线路规划模型在线路方面仅利用“最短路”的算法来降低出行者的出行成本,而忽略了通勤高峰时期可能因交通引导管理不善导致“最短路”交通量过大而引起道路拥堵等的问题,我们选择利用高德等提供实时交通数据的企业所公布的信息,对上步所计算出的路线进行修正,避开在通勤高峰时段拥堵概率较大的路段,以减少出行者的出行时间。
另一方面,我们周期性地收集已运行线路上的交通出行数据,重新进行聚类分析,周期性修正交通小区,以减少线路运营成本,提高线路的经济性。
3 结论
近年来,公交优先理念推广迅速,但由于公共交通系统的发展一般滞后于城市的发展,大面积推行公共交通优先易造成公共交通网络运输压力增大,尤其是在通勤的高峰时段,车内环境拥挤、准点率低、运输效率低等现象经常发生。基于目前客运市场逐渐萎缩的情况,本方案整合通勤时段空闲的客运班车、旅游大巴等车辆信息,专注通勤、周期性更新线路、进行资源再分配,以缓解公共交通网络中的运输压力,进而促进客运市场的转型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化·教与学(2019年5期)2019-06-06
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
汽车实用技术(2017年20期)2017-10-24
互联网天地(2016年1期)2016-05-04
专用汽车(2016年4期)2016-03-01
专用汽车(2016年1期)2016-03-01
