
国内外同一学科领域间的研究滞后性分析
——以数据挖掘领域为例
2021-07-17 14:59谭春辉熊梦媛
情报学报 2021年6期
谭春辉,熊梦媛
(华中师范大学信息管理学院,武汉 430079)
1 引言
“滞后性”常被用于描述一个现象与另一密切相关现象相对而言的落后迟延状态[1],并引发了相关学者对于滞后性测度的探索。Lee等[2]利用时间滞后模型,测度研发投入强度对制药公司绩效的滞后影响。Hwang等[3]利用余弦相似度算法,识别发明与专利间的滞后关系,以确定技术路径识别中专利转化、引用带来的时滞问题。Zhang等[4]采用格兰杰因果检验,构建向量自回归模型,算出了中国直接投资对“金砖国”经济增长的影响平均滞后8年。Sato等[5]使用固定效应模型证明,老人体育锻炼参与度与医疗费用的具有2~3年滞后期的负相关性。倪渊[6]利用阿尔蒙多项式,来测算高校科研系统投入产出的滞后性。吴丹丹等[7]运用相关性和回归分析,发现研发投入对于企业价值的影响存在4年的滞后效应。刘自强等[8]利用自回归分布滞后模型(auto-regressive distributed lag model,ARDL模型),分析基金项目和学术论文主题的扩散滞后效应,发现基金项目主题对论文主题显著影响的滞后期为2年(滞后相关系数为2.027888)。董奋义等[9]利用复相关系数与显著性检验,计算我国农业科技投入与产出之间的滞后期,并利用BC2模型和熵权法计算出滞后影响系数。从上述研究结果可以看出,对于滞后性测度,通常基于相关数据,建立与所涉领域、数据类型相对应的模型、算法或公式,测算出滞后期与滞后系数,这为本文的研究提供了方法指导与支持。
虽然从研究人员数量、文章数量、论文被引率以及影响因子等核心科研评价指标上来看,国内学术界的发展欣欣向荣,但在有些学科领域内,相较于国外而言,国内研究成果的内容和数量方面均存在着一定的滞后性。对于国内外共同学科领域的研究成果及进展,已有大量学者以期刊论文为基础,或者从内容分析的视角[10],或者从共词分析的视角[11-13],或者从词频统计的视角[14-15],或者从主题识别的视角[16-17],或者从多维指标的视角[18-20],做了较多的比较研究,并认为国内外在某些特定学科领域的研究存在一定的差异性,且主观认为国内研究相较于国外研究而言也存在一定的落后性。事物发展的过程中常常存在着滞后性,同一学科领域由于在不同地区受到经济、政治、文化等诸多因素影响,其发展水平也呈现一定的滞后性现象。但是,如何从时间的维度来确定同一学科领域研究成果数量或研究成果内容上的相对滞后性,目前现有研究并没有给出解决方案。
针对这种现象,探究一种具有普遍适用性的国内外同一学科领域研究间的滞后性测度方法,有助于揭示学科领域的发展现状、实现横向对比、明确学科发展水平,为科研人员和科技政策制定者提供参考与指导,切实把论文写在祖国的大地上,把科研成果应用在实现我国现代化的伟大事业中。
期刊论文是科学研究成果的主要表现形式和载体,论文的发表数量和主题在一定程度上反映出某学科领域的科学研究水平、研究热点和研究内容。因此,本文选取国内外核心期刊论文数据作为语料,分别代表国内某学科领域的研究成果和国外某学科领域的研究成果,并从两个维度对国内外同一学科领域间研究的滞后性进行分析:一是采用潜在狄利克雷分布(latent Dirichlet allocation,LDA)主题模型进行主题抽取,并结合相似度,计算测度国内外同一学科领域研究主题层面的滞后性,揭示该学科领域研究的滞后方向和滞后期;二是采用ARDL模型对国内外核心期刊发文量构成的时间序列进行建模分析,测度国内外同一学科领域间研究成果数量层面的滞后性,以得出显著滞后方向和滞后期。以数据挖掘领域为例,验证本文所提出的国内外同一学科领域间的研究滞后性测度方法与步骤。
2 同一学科领域间研究滞后性的测度
2.1 主题滞后性的测度
2.1.1 测度假设
对于国内外同一学科领域,相关的基础理论技术主要源自国外,至今已形成一定的基础框架和应用场景。近年来,国内对于国外理论和技术也有较多的借鉴与发展,在研究内容层面上,国内外研究主题必然有一定的相似性。因此,本文假设该学科领域的国内研究主题可能存在一定的滞后性,即该学科领域的国外研究主题作为影响方,该学科领域的国内研究主题作为被影响方,那么影响方对被影响方施加影响,被影响方在一段时间后才接受这种影响,研究主题的出现存在时间上的先后关系,从而产生了滞后效应。
为了测度国内外同一学科领域间研究主题的滞后性,本文基于同一学科领域的国内外核心期刊论文数据,建立了LDA主题模型,分别得到国内外的研究主题内容,基于主题相似度得到两者的内容相似性,并利用桑基图对国内外研究主题在不同时间片之间的相似度关联与大小进行可视化,从而直观地判定滞后方向和滞后期。
2.1.2 文本预处理
测度研究主题滞后性,需要对国内外期刊论文数据进行主题抽取。为了保证主题抽取的合理性、完整性和规范性,在主题抽取之前需要进行文本预处理,其具体方法和步骤如下:
(1)预先定义领域词典,该词典由学科领域关键词和相关专业词汇构成,作为保留词汇提高分词效果。将虚词与符号等设定为停用词表,以去除停用词;将具有相同语义的词语(即同义词)进行合并,以改善后期相似度计算的效果。
(2)使用Python与Excel对文本进行初步处理,将选取的国内外文献信息按时间片分别建立文档。调用Jieba中文分词组件,并默认使用精确模式,对每条文摘进行切分。其后每一条题注都形成一个由词语元素组成的列表,从而得到初步处理后的语料库。
(3)基于词袋模型,采用构建词典的方法,汇总文档的全部词汇并去重;然后,为语料库中的每一个词赋予(序号、特征值)的索引,以便将其运用到主题模型中。由于LDA模型是基于词频进行统计的模型,此处特征值取词频。
(4)根据所构建的词典和语料,为每个时间片中每一条文献信息的构成词在词典中查找对应索引,作为其特征进行表示。一行代表一条文献信息,每一行信息中的词都以索引来进行特征表示,即每一条文献信息由若干个索引组成,则语料转化为LDA建模可接受的输入格式。
2.1.3 主题抽取
为了有效揭示主题词之间以及与原文本的潜在关系,本文采用LDA主题模型进行主题提取,这是一类基于词袋模型的无监督机器学习的文本挖掘方法,也是一种生成联合概率分布的生成式概率主题模型[21]。其区别于预估条件概率分布的判别式模型,不需要预先进行人工标记,就可从初始文档中挖掘出潜在主题。LDA模型是以词袋模型为前提的三层贝叶斯模型,相较于普通的共词分析等词频统计方法,LDA模型能够规避同词异义、同义多词等歧义性问题。LDA模型吸收了降维与文档生成思想并进行发展,其基本原理如图1所示。
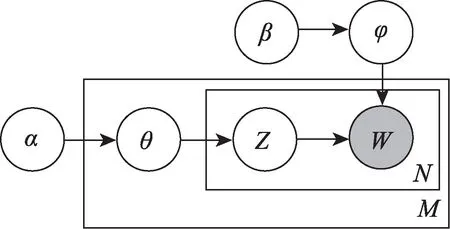
图1 LDA模型原理图[21]
LDA模型假设一篇文档是由多个主题组成的,且每篇文档的生成方式如下。首先,需要从全局的泊松分布中选取一个文档长度为N~Poission(β);其次,取样生成该文档在主题上的狄利克雷分布θ~Dir(α);再次,为该长度为N的文档中的每一个词语生成一个主题zmn~Multinomial(θm),并取样生成主题在词语上的分布为φzmn~Dir(β);最后,从以z和φ共同为参数的多项式分布中确定一个词wmn~Multinomial(φzmn)。整个模型的联合分布为

本文主要采用Gibbs采样算法求解,得到全局的主题Z的分布和词语W的分布。
作为无监督机器学习,需要事先确定3个超参数:α、β、k(最优主题数)。α、β选取一般默认值[22],最优主题数k则通过困惑度(perplexity)计算确定。困惑度是一种对语言概率模型的优劣进行评价,并协助进行参数改进的有效方法,其以信息理论为基础,对概率分布或模型的不确定性(信息熵)进行计算,将其运用于LDA模型中,计算公式为
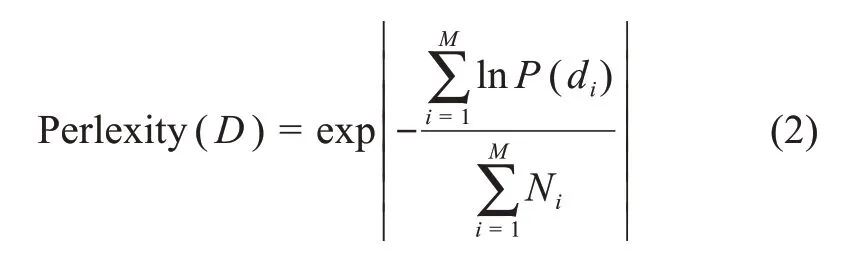
其意义表明文档d从属的主题的不确定性,因此,理论上困惑度越小,说明模型性能越优;困惑度最低,或是拐点处对应的k就为最佳主题数。
2.1.4 构建主题相似度矩阵
通过LDA模型抽取主题及其关键词,不同时间片下的主题间的相似度也不尽相同。为了计量不同时间片下主题内容的相似性,本文通过余弦相似度对不同时间片间主题的相似度进行求解,并构建主题相似度矩阵。
余弦相似度是以向量空间中两个向量构成的夹角的余弦值(cosine),作为两个被向量化表示的个体差异度的衡量标准。在二维向量空间中,假设两个二维 向量:a向量 为(x1,y1),b向量为(x2,y2),那么余弦定理可表示为

同理,将向量从二维空间拓展至n维空间,将上述的向量a、b假定为n维向量,则上述公式仍然成立:
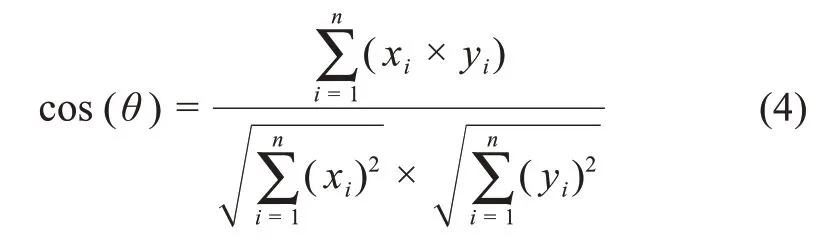
余弦值越接近于1,则两个向量越相似。将词语集形式的主题和内容转换成可用于计算的向量,计算出国内外各个时间片间研究主题内容的余弦相似度,从而得到相似度矩阵。
2.1.5 主题滞后性判定
主题滞后性判定可从两个方向来进行分析:滞后方向和滞后期。
(1)利用桑基图利于展现对象间联系以及信息量流动的特征[23],本文将每个主题的时间片作为对象,构建国内外期刊论文主题间的联系,再基于相似度矩阵信息,按滞后的正向与反向影响方向,分别绘制国外研究主题对国内研究主题的滞后影响强度、国内研究主题对国外研究主题的滞后影响强度两个桑基图,相似度大小代表了滞后影响强度的大小,通过对比得出最显著的滞后影响强度,可以确定最显著滞后方向和滞后强度。
(2)为进一步确定主题滞后期,本文分别统计不同固定时间片间隔的主题相似度,并将其算术平均值作为各个滞后期的滞后系数,滞后系数最高的滞后期,则判定为显著滞后期。
2.2 数量滞后性的测度
2.2.1 测度假设
一般而言,对于国内外同一学科领域,国内的研究论文数量在绝大多数学科领域可能都处于数量偏少的一方。那么两者的数量变化在时间序列上有没有一定的关联呢?本文假设该学科领域的国内研究论文数量可能存在一定的滞后性,即该学科领域的国外研究论文数量构成的时间序列作为因变量序列,该学科领域的国内研究论文数量构成的时间序列作自变量序列,分析两个变量之间的滞后关系,能够发掘出潜在的滞后效应。
为了测度国内外同一学科领域研究论文数量的滞后性,本文将基于同一学科领域的国内外核心期刊论文数量构成两个时间序列,利用ARDL模型实现论文数量滞后性的分析,判定数量层面的滞后方向、滞后期以及对应的滞后系数。
2.2.2 测度模型选择
ARDL模型是一种基于时间序列研究滞后效应的数理统计模型。相关研究表明,ARDL模型能够准确地计量两个或多个序列间的滞后关系[24-25],且在小样本中具备稳健性;在变量样本不大的情况下,ARDL模型的估计结果也具有足够的稳健性[26]。因此,ARDL模型适用于本文涉及的小样本期刊发文量的情况。ARDL模型的主要思想是通过边界检验法确定变量之间是否存在协整关系,并在此基础上估计变量之间的相关系数。该模型最初是由Charemza等[27]提出的,后经Pesaran等[28]完善和推广,作为检验变量之间协整关系的方法而受到学者的欢迎。ARDL模型中的滞后变量(lagged variable)是指对于自变量的变化,因变量的变化需要一定的滞后时间段才可以显现的变量,含有该变量的模型称为滞后变量模型。如果一个回归模型在此基础上还包含内生变量的滞后项,则称其为自回归分布滞后模型。本文通过国内外期刊发文量序列构成的因变量序列及其滞后变量序列进行ARDL模型建模,若能进行有效建模,一方面,可验证上述假设中的国内研究论文数量滞后性的存在;另一方面,可得到回归模型中最显著正相关系数及其所在的滞后变量序列,进而确定最显著滞后期。
2.2.3 数据预检验
ARDL模型所需的数据应为平稳时间序列且同阶单整的时间序列,因此需要对各个时间序列分别进行平稳性检验,可通过单位根检验(unit root test)确定两个变量是否平稳,排除伪回归现象,若不平稳则需要通过一阶差分处理,再检测其是否能达到平稳状态。只有两列数据为同阶单整且不超过1,才能够进行下一步的协整性检验。本文采用ADF(augmented dickey-fuller test)进 行 单 位 根 检验[29]。ADF检验的初始假设为:若序列存在单位根,则序列非平稳。当检验结果接受零假设时,则说明原序列存在单位根,为非平稳序列;当拒绝零假设时,则说明原序列不存在单位根,为平稳序列。
协整性检验是为了防止时间序列间存在伪回归关系,从而判定变量间是否具有长期稳定关系,只有排除伪回归关系,才能通过ARDL模型探测滞后关系[30]。本文使用Johansen法检验的自变量与因变量之间的协整关系,来验证各个变量之间的长期稳定关系,确定最优的滞后阶数,以及各变量间的影响方向。
2.2.4 构建ARDL模型
根据同一学科领域国内论文数量滞后于国外论文数量的假设,本文将国外论文数量和国内论文数量构成的时间序列数据分别作为因变量EN(影响方)与自变量CN(受影响方)。设定初始构建模型形式为
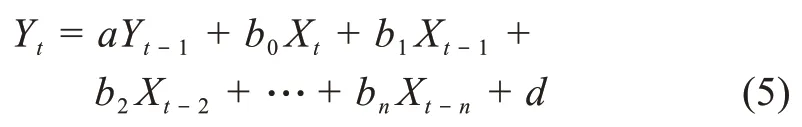
其中,Yt为序列EN每年国外期刊发文量;Xt为序列CN每年国内期刊发文量;a、b分别为Yt、Xt不同滞后阶数的系数;d为随机误差量(the stochastic error)。确定性部分是由关于自变量函数组成的部分,其参数项的确定取决于滞后项数确定。在此滞后项按AⅠC(Akaike information criterion)标准自动选取。
建模后,首先,通过模型参数估计的实际值、拟合值和残差初步判断模型拟合效果。然后,采用Q检验法绘制残差自相关和偏自相关系图,确定模型残差序列是否为白噪声序列,其中,白噪音序列的残差需为零均值,且有稳定的常方差。如果在模型评估中残差序列为白噪音序列,那么说明模型提取了所有数据中的可预测部分,剩下的部分为不可估计的随机误差部分。若剩余部分为白噪音序列,则表明模型拟合效果好,不需要进一步修改。
2.2.5 数量滞后性判定
如果构建的ARDL模型可通过评估,且模型拟合效果良好,那么该模型可在AⅠC标准下,确定为最佳模型。根据最佳模型中的最显著回归系数以及其对应的滞后项来确定滞后期,并确定滞后影响关系和滞后影响系数。
3 数据挖掘研究滞后性实证分析
3.1 数据来源
数据挖掘是典型的国内外学者都在研究的同一学科领域。本文选取数据挖掘领域的国内外期刊论文作为数据来源,按照上文所述的测度方法与过程,进行主题滞后性和数量滞后性的实证分析。
为了保证文献来源的权威性,数据来源于核心期刊文献,不包括学位论文、会议论文等,数据采集的时间段为1996—2019年(国内数据挖掘领域的第一篇论文发表于1996年),2002年以前论文因数量较少汇总为同一时间片,其后的17年则按年划分时间片,共18个时间片。数据采集时间为2020年1月18日—20日。
国内文献源为中国知网(China National KnowledgeⅠnfrastructure,CNKⅠ),为了保证文献的权威性与代表性,载体类型设定为期刊,来源类别包括SCⅠ来源期刊、EⅠ来源期刊、核心期刊、CSSCⅠ(Chinese Social Sciences CitationⅠndex)和CSCD(Chinese Science Citation Database),使用专业检索,设定检索式为“SU=数据挖掘”,其中“SU”表示主题。在检索结果中选择“中文文献”,然后下载全记录文献信息,并以Excel格式批量导出,筛去标题标注为“英文”的文献、会议通知、简报、广告、重复以及不完整的文献记录,收集总计11484条文献全记录。同时,收集每一个时间片的文献发表数量。
国外文献来源于WoS(Web of Science),采用高级检索,确定检索式为TS=“data mining”,其中“TS”表示主题,文献类型是“Article”,语种限定为“English”,索引包括SCⅠ-EXPANDED、SSCⅠ和A&HCⅠ。下载全记录文献信息,并以Excel格式批量导出,筛去会议通知、简报、广告、重复以及不完整的文献记录,收集总计20733条文献全记录。同时,收集每一个时间片的文献发表数量。
3.2 主题滞后性分析
本节将对所收集到的数据挖掘领域国内外期刊论文主题进行滞后性分析,通过LDA模型进行主题抽取,计算不同时间片间主题内容的相似度,确定滞后方向和显著滞后期。
3.2.1 语料来源
为了避免直接采用关键词带来的颗粒度较粗、内容过少、主题提取效果差强人意等问题,而文摘又可以拓展领域潜在研究主题的联系,国内期刊论文选取摘要配合关键词作为模型的语料来源。国外期刊论文由于提供关键词和扩展关键词,信息已经较为完备,为避免分词以及词干提取导致的专业术语拆散以及语义缺失等问题,本文直接将上述两者作为国外期刊的语料来源。
3.2.2 主题抽取
按文本预处理的步骤对语料进行筛选、分词、去停用词、保留专业词汇、同义词替换以及特征选择,生成符合LDA模型输入格式的词典与语料,然后按照LDA模型的抽取规范进行主题抽取。
首先,采用开源的gensim包构建主题模型估计参数。超参数确定为α=0.37、β=0.02。通过求解Gibbs采样算法求解一个时间片内所有文档潜在概率θ,φ的分布。最优主题数k的确定则是通过分别对国内期刊(CN)和国外期刊(EN)18个时间片的困惑度按公式(2)进行求解,分别取得均值并形成折线图,如图2所示。
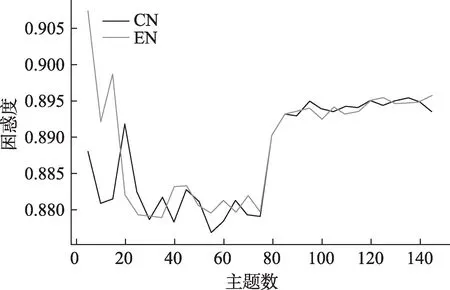
图2 困惑度计算结果
由图2可知,随着主题数设置的增加,模型困惑度前期有明显下降,这说明模型性能较好,能够有效地实现主题的判别,理论上应取对应困惑度较低的k值,但语料库不大的情况下,主题数较多可能会导致过拟合现象,因此,取第一个拐点对应的k值,国内外平均取为25个。
国内外期刊论文主题抽取结果举例如表1和表2所示。

表1 国内期刊数据挖掘领域2019主题举例
LDA模型的参数确定后进行主题提取,生成主题-词分布文档,命名为“topic_words.csv”。其中包括提取出的所有主题(由词构成)以及主题下的关键词及其概率,每一主题的关键词的数量显示限定为Top-30(排名30位以后的词概率过低,参考价值较低),将该类文档用于主题内容揭示。
3.2.3 主题相似度矩阵
基于相似度进行对比分析,需要保证领域数据的全面性才能实现特征的完全揭示,因此,本文将全部抽取的国内外期刊论文主题作为计算对象。同时,国外主题信息通过谷歌翻译和人工调整统一转换为对应的中文专业用语。
从18个时间片下的国内外期刊论文中各抽取450个主题,每两个时间片对其主题内容按照公式(4)进行余弦相似度计算。作为不同时期之间相互影响程度的量化指标,相似度越高,则说明联系越强。通过两两时间片的全组合计算,可得到相似度矩阵,如表3所示。
矩阵的整体分布特征为:从左上至右下的数值逐渐变大,说明随时间的推移,国内外期刊论文研究主题的相似度逐渐变大,研究内容的共性逐渐加强。由此可见,随着数据挖掘领域的发展不断完善以及国际交流的加深,该领域的主题更具有统一性。

表2 国外期刊数据挖掘领域2019年主题举例
表3 相似度矩阵
3.2.4 主题滞后的方向与强度
基于JavaScript语言的前端技术D3,本文将相似度矩阵信息分别按滞后的正向影响与反向影响,绘制国外期刊论文主题对国内期刊论文主题滞后影响强度桑基图、国内期刊论文主题对国外期刊论文主题滞后影响强度桑基图(图3)。在图3中,将国内外期刊论文研究主题的不同时间片用元素块表示,灰线连接这些主题上具有相似度的时间片(元素块),表示主题产生能量的流动方向;元素块后的标签值(“[]”内的数值)表示所有与之有相似关系的相似度的总和(数据来源于表3,保留一位小数),且和元素块大小呈正比,连线的宽度代表相似度的大小;“from”列表示为影响方,“to”列表示滞后方。
由图3可知,主题滞后影响联系强度分布基本符合主题演化规律,时期间隔越远的主题相似度越低,影响强度越小。随着时间的推移,连线的宽度变大,这也体现了国内外期刊论文研究主题相似度不断加大,侧面体现了该领域成熟度的加强,国内外研究路径日趋同一和明晰。
综合来看,图3中的两张图分别代表两个滞后方向,左图为国外期刊论文主题对国内期刊论文主题的影响,图中所有元素块值总和为62.66;右图为国内期刊论文主题对国外期刊论文主题的影响,图中所有元素块值总和为57.76。元素块数值总和越大,说明该滞后方向越显著。由总和可知,左图所示滞后方向更显著。

图3 滞后影响强度桑基图
由于每个元素块对应有联结的时间片数不一致,比较单个元素块值不能直观地判断影响度最大的时间片,因此,需要计算每个时间片影响方与滞后方的平均相似度(表4)。结果表明,从影响方视角来看,2007年国外期刊论文主题对国内期刊论文主题相似的平均数最大,约为0.40,表明该年份的国外期刊论文主题与其后出现的国内期刊论文主题相似度高,也就是说,该年份的国外期刊论文主题对国内期刊论文主题的影响度较高。从滞后方视角来看,2008年国内期刊论文主题对国外期刊论文主题相似度的平均数最大,为0.43,受影响的程度最大。从内容分析角度来看,国内数据挖掘领域的研究在2008年后更多的对国外相关理论技术进行了引入与优化的发展。

表4 2002—2019年影响方与滞后方的相似度平均数
综上可知,数据挖掘领域的主题影响方向可基本确定为国外研究影响国内研究,即国内研究主题对应国外研究主题的发展具有一定的滞后性。
3.2.5 主题滞后期判别
滞后效应的分析需要计算两个固定影响方向、间隔固定时期的主题信息之间的相似度,相似度最大的间隔时期就是该影响方向下的滞后期。为了直观地对比不同方向滞后水平差异,并判别出最显著滞后期,本文基于实际情况,设定最大可滞后9期。根据相似度矩阵的数据(见表3),计算出每个滞后期内涉及的所有时期相似度的平均数,作为该滞后期的滞后比例系数。以横轴为划分的滞后期,以纵轴为相似度平均水平,根据正、反向影响方向,做出滞后系数折线图(考虑滞后情况仅展现滞后9期内的结果),如图4所示。

图4 滞后系数图
由图4可知,国内期刊论文研究主题内容滞后于国外期刊论文研究主题,滞后3~5期的滞后比例系数较高,滞后3期的系数达到最大值(0.386),滞后效应最为显著,此后的滞后性加速减弱,滞后关系也逐渐淡化。因此,国外期刊论文研究主题对国内期刊论文研究主题影响的最显著滞后期为3年,即当前国外期刊论文研究主题对3年后国内期刊论文研究主题的影响强度最大,受到滞后影响的主题比例约为38.6%。
3.3 数量滞后性分析
本节运用ARDL模型,探究1996—2019年国内外数据挖掘领域的论文发表量在时间维度上的分布情况以及两者之间的滞后性关系,从数量层面印证并量化计算国内外同一学科领域研究的滞后性。
3.3.1 构建时间序列
时间序列,是指基于时间片的时序关系形成发文量数值的时间序列,数据挖掘领域国内期刊发表量CN与国外期刊发表量EN为两时间序列,两者具体数据如表5所示。

表5 1996—2019年国内外期刊发文数量(单位:篇)
将其绘制于x轴表示年份、y轴表示发表论文数量的坐标轴上,构成了国内外期刊发文量趋势对比折线图(图5)。
3.3.2 平稳性检验
本文运用Eviews 9.0计量经济学软件,采用ADF检验方法,对CN序列进行平稳性检验,结果如图6所示。
由图6中的检验结果可知,在原始时间序列下,无截距项(Ⅰntercept)与趋势项(Trend)(存在趋势项则非平稳),CN的P值(Prob.)在1%、5%、10%的显著性水平下均无法通过平稳性检验,因此,均不能拒绝序列有单位根的假设,存在单位根则为非平稳序列。因此,需要将原始时间序列CN进行一次差分,并添加截距项,得到一阶差分后的D(CN)序列,如图7所示。
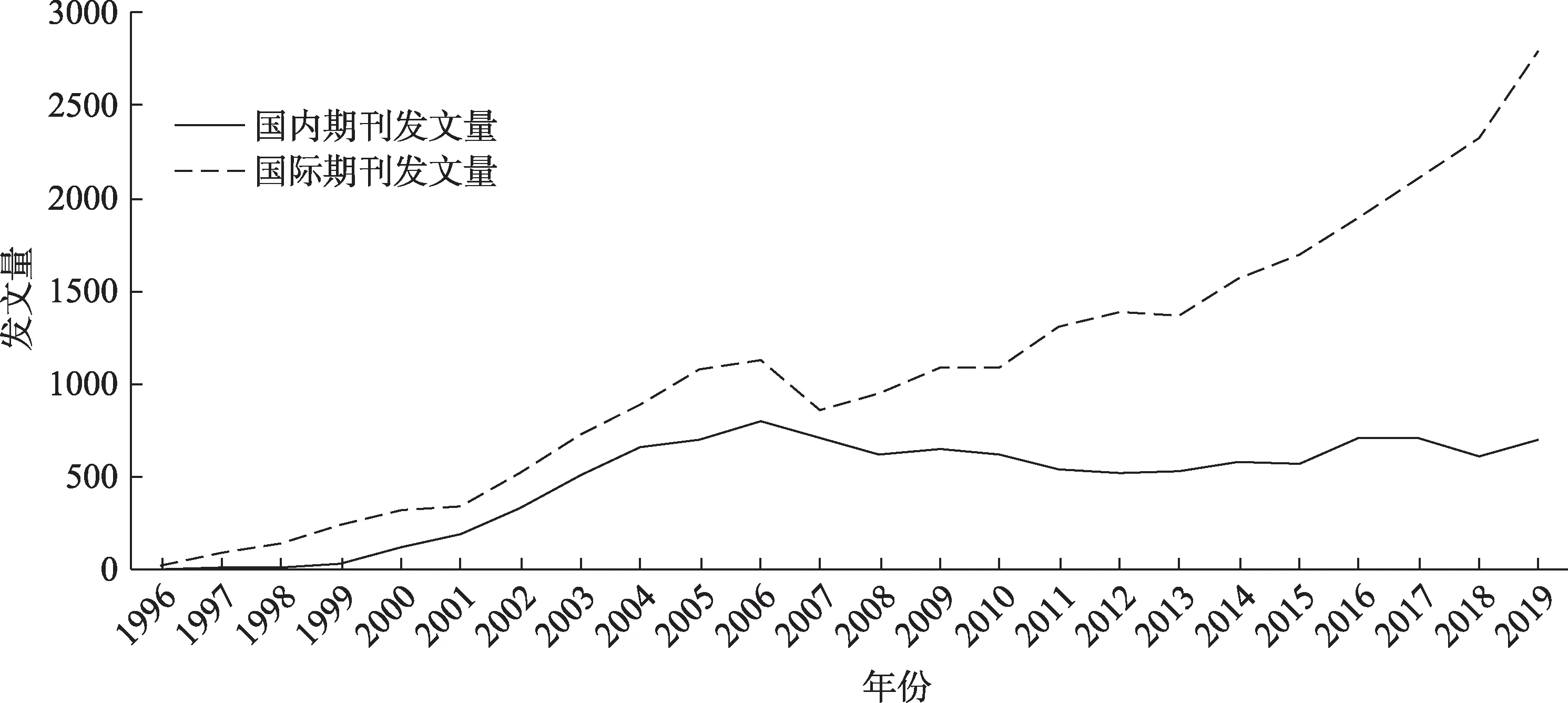
图5 国内外期刊发文量趋势对比折线图(单位:篇)

图6 CN单位根检验结果

图7 D(CN)单位根检验结果
D(CN)的ADF统计量在置信区间取10%时,3种显著性水平下P值均小于10%,说明在10%的置信区间内,一阶差分后的时间序列数据CN拒绝了序列有单位根的假设,序列平稳,则可以判断D(CN)为平稳时间序列,即一阶单整时间序列,记为CN-Ⅰ(1)。
同样地,运用Eviews 9.0计量经济学软件,采用ADF检验方法,对EN序列进行平稳性检验,检验结果如图8所示。

图8 EN单位根检验结果
从图8检验结果可知,与时间序列CN类似,原始时间序列EN的ADF统计量绝对值均低于三个标准值,P值大于10%的显著性水平,均不能拒绝序列有单位根的假设,则为非平稳序列。差分一次为一阶序列D(EN)后,P值处于10%的置信区间内,需拒绝零假设,不存在单位根,则序列平稳(图9)。因此,判断D(EN)为平稳时间序列,称为一阶单整时间序列,记为EN-Ⅰ(1)。
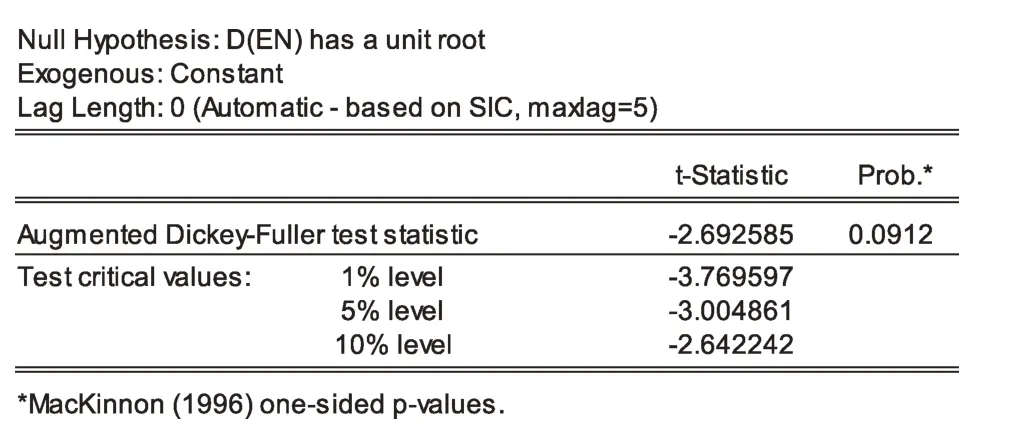
图9 D(EN)单位根检验结果
3.3.3 协整性检验
经过平稳性检验之后可知,CN-Ⅰ(1)、EN-Ⅰ(1)这两个序列均是一阶单整,符合建立协整检验的前提条件,因此,可以继续对一阶差分后的D(CN)与D(EN)进行协整性检验。
由于协整关系对滞后阶数的选择非常敏感,因此,首先建立VAR模型(图10),以确定最优滞后阶数。由图10可以看出,符合最多滞后选取标准(criteria)的滞后阶数为5(相关指标含有3个*),因此,可以确定最优滞后阶数为5。
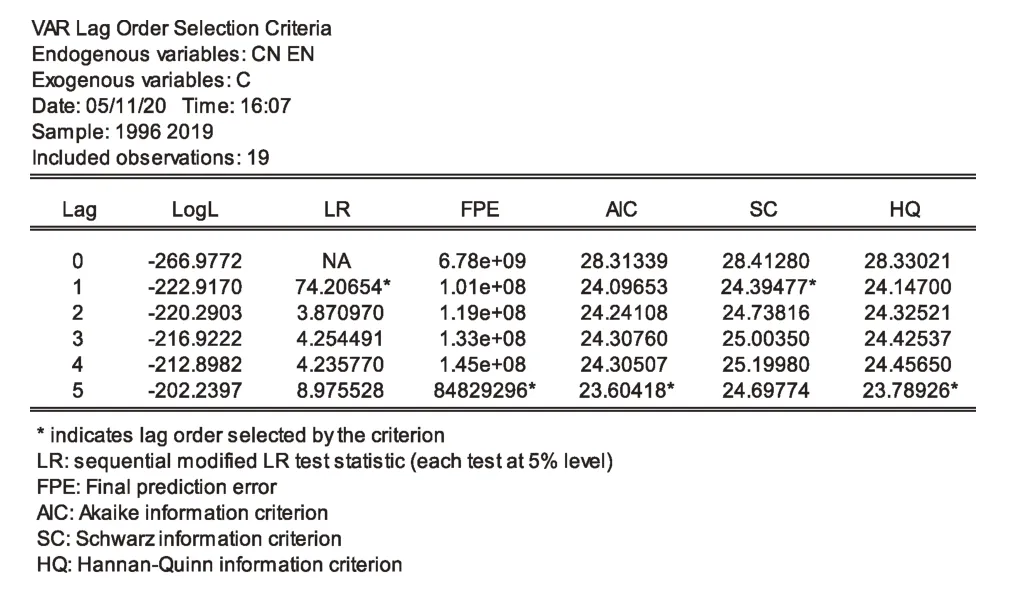
图10 VAR模型
然后,进行Johansen协整检验,包含时间趋势项,检验结果如图11所示。
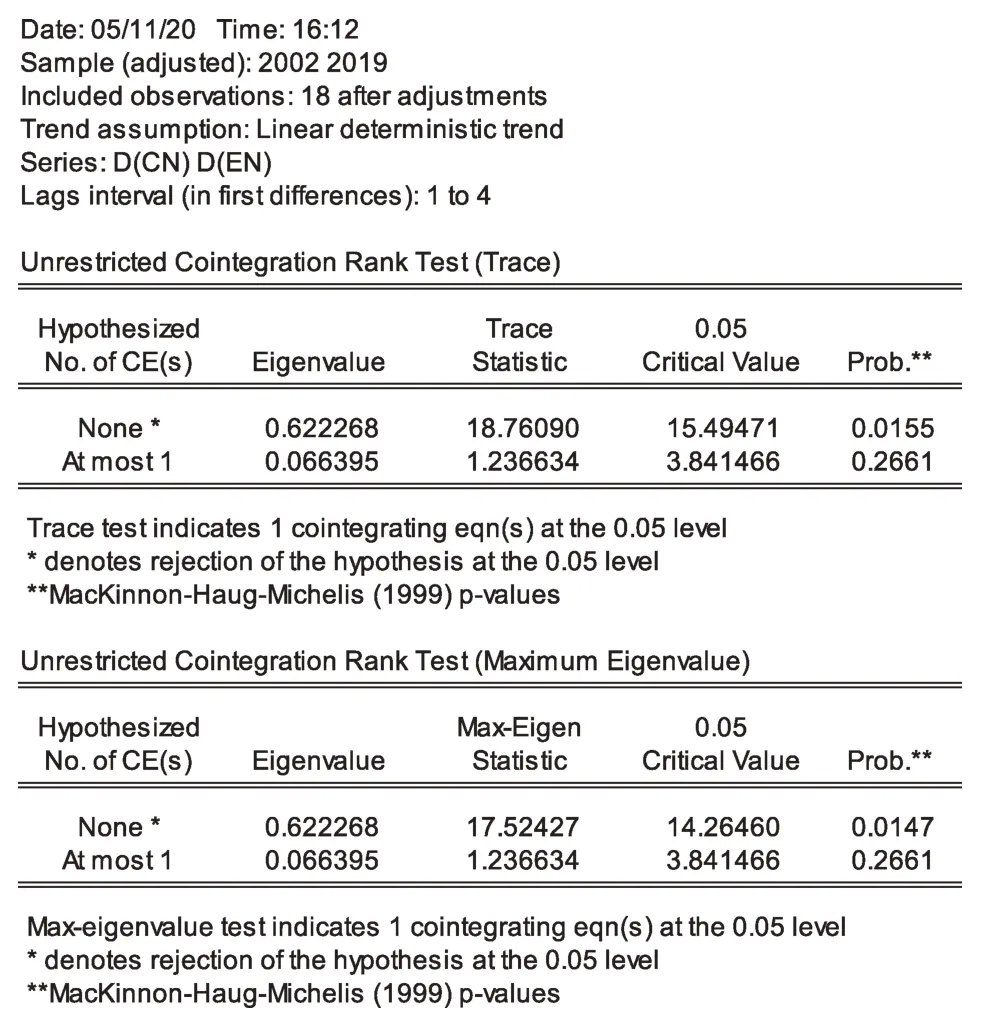
图11 D(CN)与D(EN)协整检验结果
由图11可以得出,在迹统计量(trace statistics)以及最大根统计量(max-eigen statistics)检验中,判别显著性水平为5%的情况下,第一个P值小于5%的显著性水平,接受协整关系不存在的第一原假设;第二个P值大于5%显著性水平,拒绝至多一个协整方程的第二原假设。这可说明D(CN)与D(EN)之间存在一个协整关系。
综上所述,数据挖掘领域国外期刊论文发表数与国内期刊论文发表数的年度数据均具有时间序列平稳性且一阶单整,并且两者之间存在唯一协整关系,即国外期刊发文量与国内期刊发文量具有长期稳定的关系,符合构建ARDL模型的数据要求。
3.3.4 ARDL建模
根据前面确定的EN与CN分别为因变量与自变量以及初始构建模型形式,见公式(5),构建ARDL模型,经Eviews 9.0运算后相关系数如图12所示。

图12 ARDL建模结果
从图12可知,在AⅠC标准下,选择的模型为ARDL(1,6)在滞后期为5时,D(CN(-5))的系数(coefficient)的相比其他滞后系数有最大正向取值,且P值小于5%,说明滞后项D(CN(-5))对D(EN)具有最显著的正向影响。因此,回归模型可写为

在此前或后滞后项的滞后系数均为负且不显著,不予考虑。D(CN(-5))的滞后系数表明滞后影响系数为1.431913,实际意义为数据挖掘领域国外期刊发文量对于国内发表量的显著影响具有5年的滞后期。
构建ARDL模型后,需对模型进行评估来判断模型的拟合效果。从图12的参数估计结果,可以直观判断该模型R2数值与F统计量(F-statistic)均较高,表明模型显著性较高。从图13中参数估计的实际值(actual value)、拟合值(fitted value)、残差(residual)的可视化结果来看,残差分布围绕零上下波动,基本不具备明显趋势与可预测性,且实际值与拟合值波动差别小,初步说明残差具有随机性,且模型拟合效果好。
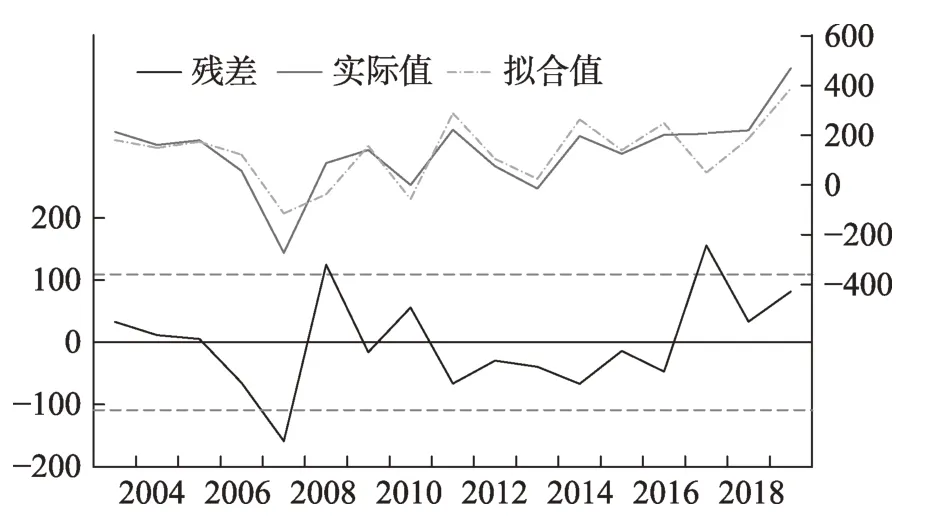
图13 实际值、拟合值、残差序列图
采用Q值检验法,得出残差自相关和偏自相关系图,如图14所示。P值均大于5%的置信区间(若P值均较低,则残差中可能还存在自相关关系),Q值增大趋势明显且数值大,AC(自相关系数)与PAC(偏自相关系数)分布差别显著,可以确定模型残差序列为白噪声序列,说明已有模型拟合效果良好,可以停止建模。

图14 残差自相关和偏自相关图
3.3.5 数量滞后性判定
本文得出的ARDL模型能够可靠地探测数据挖掘领域国内外期刊论文发表数量上的影响滞后关系,国外期刊发文量对国内期刊发文量具有长期的影响关系,且滞后期为5年,滞后影响系数为1.431913。
4 结论
在同一学科领域内,国内外学者们的研究水平与层次存在差异,并在某种程度上表现为一定的滞后性。本文基于国内外核心期刊的学科领域研究论文主题和数量滞后性测度方法与步骤的基础上,选取了1996—2019年间数据挖掘领域的国内外核心期刊论文进行了滞后性实证分析,研究结果表明,本文所设计的方法可有效揭示该领域在国内外核心期刊论文的滞后方向、滞后期,并得出以下结论:
(1)在数据挖掘领域,本文通过论文主题滞后性的分析发现,国内外研究主题的共性逐渐增强,滞后方向为国内期刊论文主题滞后于国外期刊论文主题,最显著滞后期为3年,受到滞后影响的主题比重约为38.6%。在2007年,国外期刊论文主题对国内期刊论文主题综合影响程度较大;2008年,国内期刊论文主题受国外期刊论文主题的影响最大。
(2)在数据挖掘领域,本文通过论文数量滞后性的分析发现,滞后方向为国内期刊论文数量滞后于国外期刊论文数量,其滞后期为5年。同时,国内外期刊发文量之间存在相互影响的关系,滞后影响系数为1.431913。
研究结果表明,本文所提出的国内外同一学科领域滞后性测度的方法与步骤,在一定程度上弥补了已有的对科研滞后性研究缺乏定量方法的不足,且对于其他科学研究领域的滞后性测度也具有普遍的适用性。然而,本文也存在一些不足,例如,在实证分析中,仅以“数据挖掘”作为主题来检索期刊论文文献,没有采用与数据挖掘相关的词汇,从而导致检索结果不全面;仅对国内外期刊论文进行实证分析,而没有考虑学术会议论文,这在一定程度上代表不了学科领域真实的水平;从主题维度进行的数据挖掘领域滞后性实证分析还可进一步细化,如将数据挖掘领域划分为理论与应用维度来进行滞后性对比,实现多维度分析。
猜你喜欢
军事运筹与系统工程(2022年1期)2022-11-15
质量安全与检验检测(2022年2期)2022-11-13
九江学院学报(自然科学版)(2022年2期)2022-07-02
体育科技文献通报(2022年5期)2022-06-05
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
地理教育(2018年6期)2018-07-12
电子技术与软件工程(2016年24期)2017-02-23
合作经济与科技(2016年24期)2016-12-07
中国市场(2016年32期)2016-12-06
